Perfetto笔记-1-Perfetto官方文档翻译-1-Trace Analysis-1-PerfettoSQL
基于 kernel-5.4
PerfettoSQL有两部分,这里是第一部分:
(1) Trace Analysis / PerfettoSQL: https://perfetto.dev/docs/analysis/perfetto-sql-getting-started
(2) Advanced Trace Analysis / PerfettoSQL Prelude: https://perfetto.dev/docs/analysis/sql-tables#slice 这个里面有讲解各个表之间的关系和各个表中的字段
perfetto文档:https://perfetto.dev/docs/
本文翻译起始位置:https://perfetto.dev/docs/analysis/getting-started
一、Getting Start
1. Trace Analysis Overview
本页面是您进入 Perfetto trace 分析世界的入口。它概述了可用于从trace中提取有意义信息的各种工具和概念,引导您从交互式探索逐步过渡到大规模自动化分析。
2. The Challenge: Making Sense of Raw Traces
trace数据中的事件经过优化,以实现快速、低开销的记录。因此,需要对跟踪数据进行大量处理才能从中提取有意义的信息。此外,许多仍在使用的旧格式也需要跟踪分析工具的支持,这进一步加剧了数据处理的复杂性。
3. The Solution: The Trace Processor and PerfettoSQL
Perfetto 所有跟踪分析的核心是跟踪处理器(Trace Processor),这是一个 C++ 库,它解决了跟踪数据的复杂性。它负责解析、结构化和查询跟踪数据等繁重工作。####
跟踪处理器抽象了底层跟踪格式,并通过 PerfettoSQL(一种 SQL 方言)公开数据。PerfettoSQL 允许您像查询数据库一样查询跟踪内容。####
跟踪处理器负责:
(1) 解析Trace:接收各种跟踪格式,包括 Perfetto、ftrace 和 Chrome JSON。
(2) 结构化数据:将原始跟踪数据转换为结构化格式。
(3) 公开查询接口:提供用于查询结构化数据的 PerfettoSQL 接口。
(4) 捆绑标准库:包含 PerfettoSQL 标准库,以便进行开箱即用的分析。
4. The Trace Analysis Workflow
Perfetto 提供了一套灵活的工具集,这些工具可以相互叠加,以满足不同的分析需求。典型的工作流程是从广泛的交互式探索逐步过渡到精细的自动化分析。
(1) 交互式探索:首先,使用 Perfetto 用户界面或 trace_processor shell 以交互方式探索您的跟踪数据。这非常适合进行临时调查、调试以及了解跟踪数据。
(2) 程序化分析:在更好地理解跟踪数据之后,您可以使用适用于 Python 和 C++ 的 Trace Processor 库来自动化查询并构建更复杂的分析流程。####
(3) 大规模分析:为了构建稳健的自动化分析流程,推荐使用跟踪摘要。它允许您为分析定义稳定、结构化的输出,使其非常适合大规模的性能监控和回归检测。
5. Where to Go Next
学习语言:PerfettoSQL
在深入了解工具之前,最好先掌握 PerfettoSQL 的基础知识。
PerfettoSQL 入门:学习 PerfettoSQL 的核心概念以及如何编写查询。//https://perfetto.dev/docs/analysis/perfetto-sql-getting-started
PerfettoSQL 语法:了解 Perfetto 支持的 SQL 语法,包括用于创建函数、表和视图的特殊功能。//https://perfetto.dev/docs/analysis/perfetto-sql-syntax
标准库:探索标准库中丰富的模块,用于分析 CPU 使用率、内存和功耗等常见场景。//https://perfetto.dev/docs/analysis/stdlib-docs
6. Explore the Tools
熟悉 PerfettoSQL 的基础知识后,您可以探索使用跟踪处理器 (Trace Processor) 的不同方式。
跟踪处理器(C++):学习如何使用交互式 shell 和底层 C++ 库。 //https://perfetto.dev/docs/analysis/trace-processor
跟踪处理器(Python):利用 Python API 将跟踪分析与丰富的数据科学和可视化生态系统相结合。//https://perfetto.dev/docs/analysis/trace-processor-python
7. Automate Your Analysis
对于大规模或自动化分析,推荐使用跟踪摘要方法。
跟踪摘要:了解如何定义和运行摘要,以从跟踪数据生成一致且结构化的 protobuf 输出。//https://perfetto.dev/docs/analysis/trace-summary
二、PerfettoSQL
1. Getting Started with PerfettoSQL
PerfettoSQL 是 Perfetto 中trace分析的基础。它是一种 SQL 方言,允许您像查询数据库一样查询trace内容。本页介绍使用 PerfettoSQL 进行trace查询的核心概念,并提供编写查询的指南。
1.1 Overview of Trace Querying
Perfetto 用户界面是一个强大的可视化分析工具,提供调用堆栈(call stacks)####、时间线视图(timeline )、线程跟踪(thread tracks)和切片(slices)等功能。此外,它还包含一个强大的 SQL 查询语言 (PerfettoSQL),该语言由查询引擎 (TraceProcessor) 解释执行,从而允许您以可编程方式提取数据。
虽然用户界面功能强大,可用于各种分析,但用户也可以在 Perfetto 用户界面中编写和执行查询,以实现多种目的,例如:
(1) 从trace中提取性能数据。
(2) 创建自定义可视化(Debug tracks)以执行更复杂的分析。
(3) 创建派生指标。
(4) 使用数据驱动逻辑识别性能瓶颈。
除了 Perfetto 用户界面之外,您还可以使用 Python Trace Processor API 或 C++ Trace Processor 以编程方式查询跟踪。
//https://perfetto.dev/docs/analysis/trace-processor-python
//https://perfetto.dev/docs/analysis/trace-processor
Perfetto 还支持通过批量跟踪处理器(Batch Trace Processor)进行批量trace分析。该系统的一个关键优势是查询可重用性:用于单个跟踪的相同 PerfettoSQL 查询无需修改即可应用于大型数据集。
//https://perfetto.dev/docs/analysis/batch-trace-processor
1.2 Core Concepts
在编写查询之前,了解 Perfetto 如何构建跟踪数据的基本概念非常重要。
1.2.1 Events
从最广义的角度来看,一个trace就是一系列带有时间戳的“事件(events)”。事件可以关联元数据和上下文信息,从而可以对其进行解释和分析。时间戳以纳秒为单位;具体数值取决于 TraceConfig 中选择的时钟(`clock`)。
//https://cs.android.com/android/platform/superproject/main/+/main:external/perfetto/protos/perfetto/config/trace_config.proto;l=114;drc=c74c8cf69e20d7b3261fb8c5ab4d057e8badce3e
事件是跟踪处理器的基础,分为两种类型:切片(slices)和计数器(counters)。
(1) Slices

一个切片(slice)指的是一段时间段,其中包含描述该时间段内发生情况的数据。切片的一些示例包括:
a. 为每个 CPU 调度切片
b. Android 上的 Atrace 切片
c. Chrome 的用户空间切片
(2) Counters
![]()
计数器是一个随时间变化的连续值。计数器的一些示例包括:
a. 每个 CPU 核心的 CPU 频率
b. RSS 内存事件(包括来自内核的事件和从 /proc/stats 轮询的事件)
c. Android 的 atrace 计数器事件
d. Chrome 计数器事件
1.2.2 Tracks
一个轨道(track)是同一类型且具有相同关联上下文的事件的命名分区(可理解为集合吗)。例如:
a. 调度切片为每个 CPU 创建一个轨道。
b. 同步用户空间切片为每个发出事件的线程创建一个轨道。
c. 异步用户空间切片为每个连接一组异步事件的“cookie”创建一个轨道。
理解轨道最直观的方式是想象它们在用户界面中的绘制方式;如果所有事件都在同一行,则它们属于同一轨道(track)####。例如,CPU5 的所有调度事件都在同一轨道上:
![]()
根据event类型和关联上下文,tracks可以分为多种类型。例如:
a. 全局tracks不关联任何上下文,包含切片(slices)。
b. Thread tracks关联到单个线程,包含切片(slices)。
c. Counter tracks 不关联任何上下文,包含计数器。
d. CPU counter tracks关联到单个CPU,包含计数器。
1.2.3 Thread and process identifiers
在跟踪的上下文中,线程和进程的处理需要特别注意;线程和进程的标识符(例如 Android/macOS/Linux 中的 pid/tgid 和 tid)在跟踪过程中可能会被操作系统重复使用。这意味着在跟踪处理器中查询表时,它们不能作为唯一标识符。
为了解决这个问题,跟踪处理器使用 utid(唯一 tid)来标识线程,使用 upid(唯一 pid)来标识进程。所有对线程和进程的引用(例如 CPU 调度数据、线程跟踪)都使用 utid 和 upid,而不是系统标识符####。
1.2.4 Querying traces in the Perfetto UI
现在您已经了解了核心概念,可以开始编写查询了。
Perfetto 提供了一个 SQL 自由格式多行文本输入界面,直接集成在用户界面中,用于执行自由格式查询。访问方式如下:
(1) 在 Perfetto 用户界面(Perfetto UI)中打开一个跟踪。//https://ui.perfetto.dev/
(2) 点击导航栏中的"Query (SQL)"选项卡(见下图)。
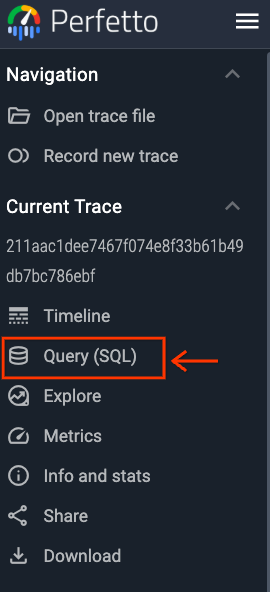
选择此选项卡后,将显示查询用户界面,您可以自由编写 PerfettoSQL 查询,它允许您编写查询、显示查询结果和查询历史记录,如下图所示。
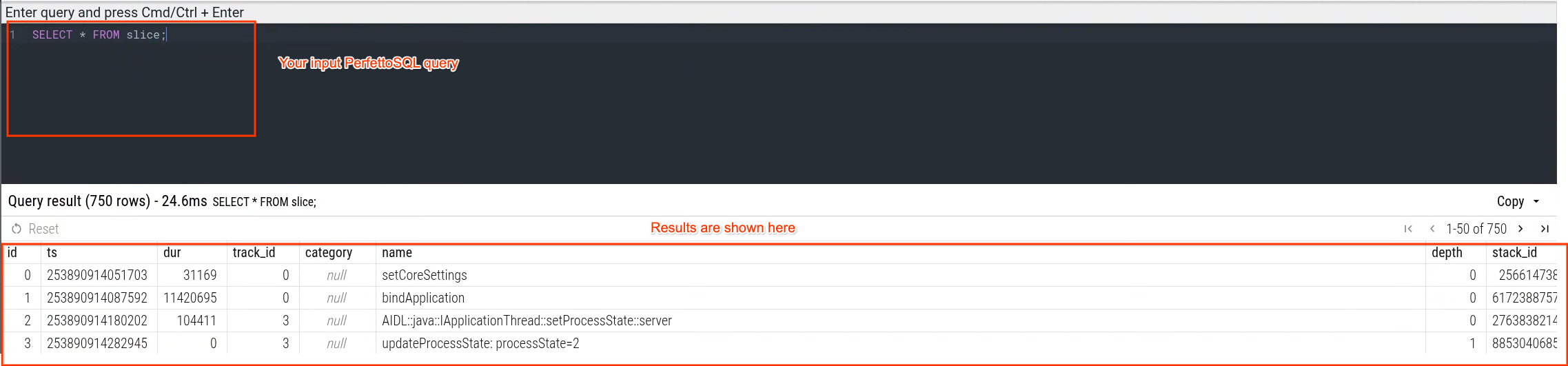
(3) 在查询界面区域输入查询语句,然后按 Ctrl+Enter(或 Cmd+Enter)执行。
执行后,查询结果将显示在同一窗口中。
如果您对查询方式和查询内容有一定的了解,这种查询方法非常有用。
要了解如何编写查询语句,请参阅语法指南(Syntax guide);要查找可用的表、模块、函数等,请参阅标准库( Standard Library)。
//https://perfetto.dev/docs/analysis/perfetto-sql-syntax
//https://perfetto.dev/docs/analysis/stdlib-docs
很多时候,将查询结果转换为调试轨道(tracks )以便在用户界面中执行复杂的分析会很有用。我们建议读者查看调试轨道(Debug Tracks),了解更多相关信息。
//https://perfetto.dev/docs/analysis/debug-tracks
1.2.5 Example: Executing a basic query
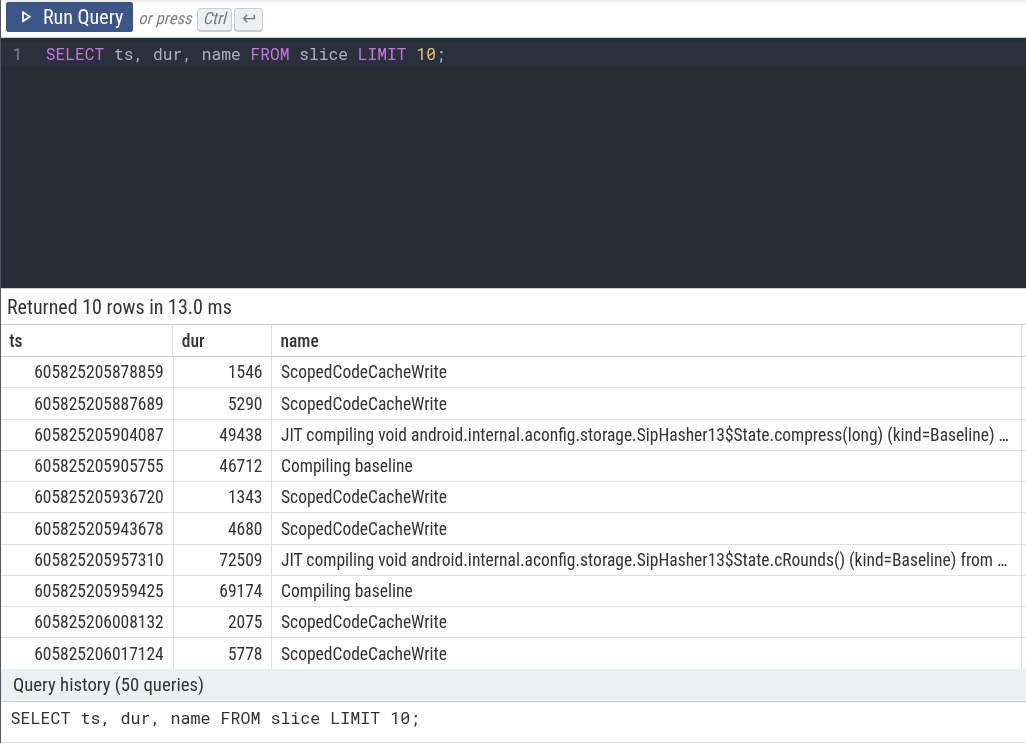
浏览跟踪记录最简单的方法是从原始表中进行选择。例如,要查看跟踪记录中的前 10 个切片(slices ),可以运行以下命令:
SELECT ts, dur, name FROM slice LIMIT 10;
您可以通过在 PerfettoSQL 查询 UI 中单击“Run Query”来编写和执行查询,以下是跟踪中的一个示例。
1.2.6 Getting More Context with JOINs
在跟踪处理器中查询表时,一个常见的问题是:“如何获取切片的进程或线程?”。更一般地说,这个问题是“如何获取事件的上下文?”。
在跟踪处理器中,与一个轨道(track)中所有跟踪事件(event)关联的任何上下文都存储在相应的 track 表中。
例如,要获取发出 measure 切片(slice)的任何线程的 utid,可以使用以下方法:
SELECT utid FROM slice JOIN thread_track ON thread_track.id = slice.track_id WHERE slice.name = 'measure'
注:slice表中的track_id应该就是对应轨道的id,就是 thread_track 表中的id。slice表中并没有utid, utid只在 thread_track 表中。
注: 此SQL脚本应该可以这么理解,先从 slice 表中选出 name='measure' 的行的所有内容,然后与 thread_track 表在行上取交集,行上取交集的条件是 slice 表中的 track_id 与 thread_track 表中的 id 相等,然后在列上取并集,将 thread_track 表中选出行的所有列并在 slice 表的右边,同名的条目会加上"_1"后缀,如 thread_track 表中的 name 变为 name_1, 为了避免同名冲突 select 后面最好写为 <表名>.<条目名>。然后从列并集中取出 utid 这一个条目。
类似地,要获取 mem.swap 计数器大于 1000 的任何进程的 upid,
SELECT upid FROM counter JOIN process_counter_track ON process_counter_track.id = counter.track_id WHERE process_counter_track.name = 'mem.swap' AND value > 1000
1.2.7 Thread and process tables
获取 utid 和 upid 虽然是朝着正确方向迈出的一步,但用户通常需要的是原始的线程 tid、pid 以及进程/线程名。
thread 表和 process 表分别将 utid 和 upid 映射到线程和进程。例如,要查找 utid 为 10 的线程,可以使用以下方法:
SELECT tid, name FROM thread WHERE utid = 10
thread 表和 process 表也可以直接与关联的跟踪表连接(joined),从而直接从切片(slice)或计数器(counter)跳转到有关进程和线程的信息。
例如,要获取发出 measure slice 的所有线程的列表:
SELECT thread.name AS thread_name FROM slice JOIN thread_track ON slice.track_id = thread_track.id JOIN thread USING(utid) //等效 JOIN thread ON thread_track.utid = thread.utid WHERE slice.name = 'measure' GROUP BY thread_name
注: USING 是两个表有同名成员,使用这个同名成员进行匹配的简写方法。JOIN table_A 表后, 表的名字可以认为就是 table_A 了。
此时列条目的排列顺序是 <slice> <thread_track> <thread>. ####
使用 GROUP BY 但是没有指定多条数据是累加还是累减,实测取的是第一条(行)数据。
1.3 Simplifying Queries with the Standard Library
虽然始终可以通过连接原始表从头开始编写查询,但 PerfettoSQL 提供了一个丰富的预构建 Standard Library ,以简化常见的分析任务。
//https://perfetto.dev/docs/analysis/stdlib-docs
要使用标准库中的模块,您需要使用 `INCLUDE PERFETTO MODULE` 语句导入它。例如,您可以不直接连接(join)线程和进程,而是使用 `slices.with_context` 模块:
INCLUDE PERFETTO MODULE slices.with_context; SELECT thread_name, process_name, name, ts, dur FROM thread_or_process_slice;
导入后,您可以在查询中使用模块提供的表和函数。有关可用模块的更多信息,请参 Standard Library documentation。
//https://perfetto.dev/docs/analysis/stdlib-docs
有关 INCLUDE PERFETTO MODULE 语句和其他 PerfettoSQL 功能的更多详细信息,请参阅 PerfettoSQL Syntax 文档。
//https://perfetto.dev/docs/analysis/perfetto-sql-syntax
1.4 Advanced Querying
对于需要超越标准库或构建自己的抽象层的用户,PerfettoSQL 提供了几个高级功能。
1.4.1 Helper functions
辅助函数是 C++ 中内置的函数,可以减少 SQL 中需要编写的样板代码量。
Extract args
EXTRACT_ARG 是一个辅助函数,用于从 args 表中检索事件的属性(例如,slice 或 counter)。
它接受一个 arg_set_id 和一个 key 作为输入,并返回在 args 表中查找到的值。
例如,要检索 ftrace_event 表中 sched_switch 事件的 prev_comm 字段。
SELECT EXTRACT_ARG(arg_set_id, 'prev_comm') FROM ftrace_event WHERE name = 'sched_switch'
在后台,上述查询会被解析成以下内容:
SELECT ( SELECT string_value FROM args WHERE key = 'prev_comm' AND args.arg_set_id = raw.arg_set_id ) FROM ftrace_event WHERE name = 'sched_switch'
注: 实测这个执行不成功。
1.4.2 Operator tables
通常情况下,SQL 查询足以从跟踪处理器中检索数据。但有时,某些结构难以用纯 SQL 表达。
在这种情况下,跟踪处理器提供了特殊的“运算符表”,这些表在 C++ 中解决了特定问题,同时还提供了一个可供查询使用的 SQL 接口。
(1) Span join
Span join 是一个自定义运算符表,用于计算两个表或视图中时间跨度的交集。这里的“跨度”指的是表/视图(table/view)中包含“ts”(时间戳)和“dur”(持续时间)列的行。
可以选择性地指定一个列(称为分区),该列在计算交集之前将每个表中的行划分为不同的分区。
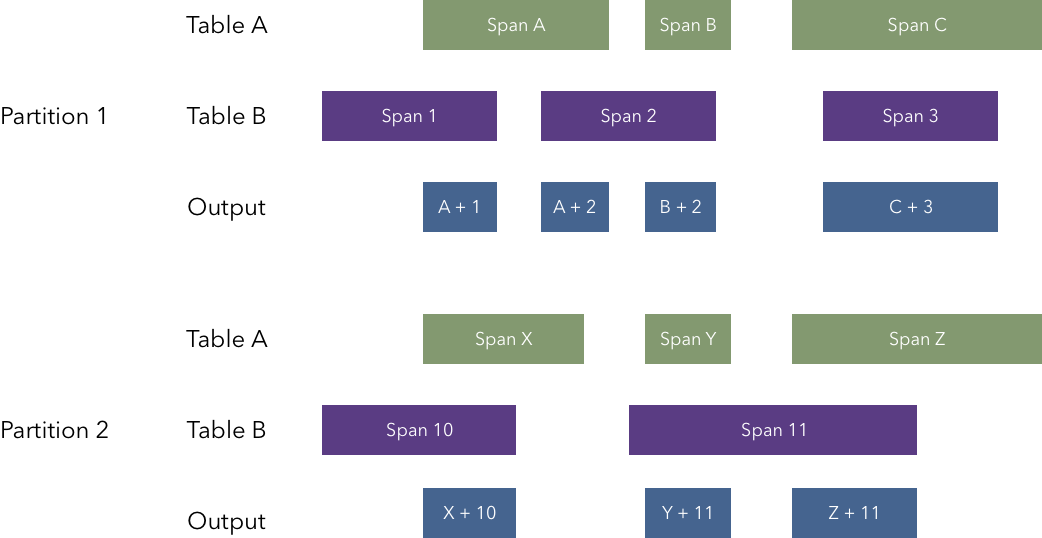
脚本:
-- Get all the scheduling slices CREATE VIEW sp_sched AS SELECT ts, dur, cpu, utid FROM sched; -- Get all the cpu frequency slices CREATE VIEW sp_frequency AS SELECT ts, lead(ts) OVER (PARTITION BY track_id ORDER BY ts) - ts as dur, cpu, value as freq FROM counter JOIN cpu_counter_track ON counter.track_id = cpu_counter_track.id WHERE cpu_counter_track.name = 'cpufreq'; -- Create the span joined table which combines cpu frequency with -- scheduling slices. CREATE VIRTUAL TABLE sched_with_frequency USING SPAN_JOIN(sp_sched PARTITIONED cpu, sp_frequency PARTITIONED cpu); -- This span joined table can be queried as normal and has the columns from both -- tables. SELECT ts, dur, cpu, utid, freq FROM sched_with_frequency;
注: 上述四个表都查询不到数据。
注意:分区可以只在两个表中指定,也可以只在其中一个表中指定,或者同时在两个表中都指定。如果同时在两个表中都指定了分区,则每个表中必须使用相同的列名。
警告:span joined表的一个重要限制是,同一分区中同一表的跨度不能重叠。出于性能考虑,跨度连接不会尝试检测并报错;而是会静默地生成错误的行。
警告:分区必须是整数。重要的是,不支持字符串分区;请注意,可以通过对字符串列应用哈希函数将字符串转换为整数。
还支持左连接(left join)和外连接(outer join);两者的功能与 SQL 中的左连接和外连接类似。
-- Left table partitioned + right table unpartitioned. CREATE VIRTUAL TABLE left_join USING SPAN_LEFT_JOIN(table_a PARTITIONED a, table_b); -- Both tables unpartitioned. CREATE VIRTUAL TABLE outer_join USING SPAN_OUTER_JOIN(table_x, table_y);
注: 这两个都都执行不成功。
注意:如果分区表为空,且属于以下情况之一,则存在一些微妙之处:
a) 外连接的一部分;
b) 左连接的右侧。
在这种情况下,即使另一个表非空,也不会生成任何切片。考虑到跨度连接在实践中的使用方式,我们认为这种方法最为自然。
(2) Ancestor slice
ancestor_slice 是一个自定义运算符表,它接收 slice表的id列,并计算同一轨道(track)上所有直接位于该 id 之上的切片(即,给定一个切片 id,它将返回所有通过 parent_id 列找到的顶层切片(深度 = 0))。
//https://perfetto.dev/docs/analysis/sql-tables#slice
返回的格式与 slice表 相同。
//https://perfetto.dev/docs/analysis/sql-tables#slice
例如,以下代码根据一组感兴趣的切片(slice)查找顶层切片。
CREATE VIEW interesting_slices AS SELECT id, ts, dur, track_id FROM slice WHERE name LIKE "%interesting slice name%"; SELECT * FROM interesting_slices LEFT JOIN ancestor_slice(interesting_slices.id) AS ancestor ON ancestor.depth = 0
注: 什么也没查到,还报错了。
(3) Ancestor slice by stack
`ancestor_slice_by_stack` 是一个自定义运算符表,它接受 slice表的`stack_id`列,并查找所有具有该 `stack_id` 的切片ids。然后,对于每个id,它计算所有祖先切片,类似于 `ancestor_slice` 的操作。
//https://perfetto.dev/docs/analysis/sql-tables#slice
//https://perfetto.dev/docs/analysis/trace-processor#ancestor-slice
返回的格式与 slice table 表相同。
//https://perfetto.dev/docs/analysis/sql-tables#slice
例如,以下代码查找具有给定名称的所有切片的顶层切片。
CREATE VIEW interesting_stack_ids AS SELECT stack_id FROM slice WHERE name LIKE "%interesting slice name%"; SELECT * FROM interesting_stack_ids LEFT JOIN ancestor_slice_by_stack(interesting_stack_ids.stack_id) AS ancestor ON ancestor.depth = 0
注: 实测报错了
(4) Descendant slice
descendant_slice 是一个自定义运算符表,它接收 slice table的id列,并计算同一轨道(track)上嵌套在该 id 下的所有切片(即,在同一时间帧的同一轨道上,深度大于给定切片深度的所有切片)。
//https://perfetto.dev/docs/analysis/sql-tables#slice
返回的格式与 slice table 相同。
//https://perfetto.dev/docs/analysis/sql-tables#slice
例如,以下代码查找每个目标切片下的切片数量。
CREATE VIEW interesting_slices AS SELECT id, ts, dur, track_id FROM slice WHERE name LIKE "%interesting slice name%"; SELECT * ( SELECT COUNT(*) AS total_descendants FROM descendant_slice(interesting_slice.id) ) FROM interesting_slices
注: 实测报错了。
(5) Descendant slice by stack
`descendant_slice_by_stack` 是一个自定义运算符表,它接收切片表(alice table)的 `stack_id` 列,并查找所有具有该 `stack_id` 的切片id。然后,对于每个id,它计算所有子切片,类似于 `descendant_slice` 的操作。
//https://perfetto.dev/docs/analysis/sql-tables#slice
//https://perfetto.dev/docs/analysis/trace-processor#descendant-slice
返回的格式与切片表相同。
//https://perfetto.dev/docs/analysis/sql-tables#slice
例如,以下代码查找具有给定名称的所有切片的下一级子切片。
CREATE VIEW interesting_stacks AS SELECT stack_id, depth FROM slice WHERE name LIKE "%interesting slice name%"; SELECT * FROM interesting_stacks LEFT JOIN descendant_slice_by_stack(interesting_stacks.stack_id) AS descendant ON descendant.depth = interesting_stacks.depth + 1
注:实测,也是报错的。
(6) Connected/Following/Preceding flows
DIRECTLY_CONNECTED_FLOW、FOLLOWING_FLOW 和 PRECEDING_FLOW 是自定义运算符表,它们接受 slice table's id 列,并收集流表(flow table)中所有与给定起始切片直接或间接连接的条目。
DIRECTLY_CONNECTED_FLOW(start_slice_id) - 包含流表(flow table )中所有存在于以下任何链中的条目:flow[0] -> flow[1] -> ... -> flow[n],其中 flow[i].slice_out = flow[i+1].slice_in 且 flow[0].slice_out = start_slice_id 或 start_slice_id = flow[n].slice_in。
注意:与后续/前置流函数不同,此函数在从切片搜索流时不会包含连接到祖先或后代的流。它仅包含直接连接链中的切片。
FOLLOWING_FLOW(start_slice_id) - 包含从给定切片递归追踪到其入点切片以及从已到达切片追踪到其子切片的所有流。返回表包含流表中所有符合以下任何链式关系的条目:flow[0] -> flow[1] -> ... -> flow[n],其中 flow[i+1].slice_out IN DESCENDANT_SLICE(flow[i].slice_in) OR flow[i+1].slice_out = flow[i].slice_in 且 flow[0].slice_out IN DESCENDANT_SLICE(start_slice_id) OR flow[0].slice_out = start_slice_id。
PRECEDING_FLOW(start_slice_id) - 包含从给定切片递归追踪到其入点切片以及从已到达切片追踪到其父切片的所有流。返回表包含流表中所有存在于任何类型链中的条目:flow[n] -> flow[n-1] -> ... -> flow[0],其中 flow[i].slice_in IN ANCESTOR_SLICE(flow[i+1].slice_out) OR flow[i].slice_in = flow[i+1].slice_out and flow[0].slice_in IN ANCESTOR_SLICE(start_slice_id) OR flow[0].slice_in = start_slice_id。
--number of following flows for each slice
SELECT (SELECT COUNT(*) FROM FOLLOWING_FLOW(slice_id)) as following FROM slice;
注: 实测一运行,卡死了。
1.5 Next Steps
现在您已经对 PerfettoSQL 有了基本的了解,可以探索以下主题以加深理解:
PerfettoSQL Syntax:了解 Perfetto 支持的 SQL 语法,包括创建函数、表和视图的特殊功能。
//https://perfetto.dev/docs/analysis/perfetto-sql-syntax
Standard Library:探索标准库中丰富的模块,用于分析常见的场景,例如 CPU 使用率、内存和功耗。
//https://perfetto.dev/docs/analysis/stdlib-docs
Trace Processor (C++):学习如何使用交互式 shell 和底层 C++ 库。
//https://perfetto.dev/docs/analysis/trace-processor
Trace Processor (Python):利用 Python API 将跟踪分析与丰富的数据科学和可视化生态系统相结合。
//https://perfetto.dev/docs/analysis/trace-processor-python
2. PerfettoSQL standard library
本页面介绍了 PerfettoSQL 标准库。
2.1 Introduction
PerfettoSQL 标准库是一个包含表(tables)、视图(views)、函数(functions )和宏(macros)的存储库,由领域专家贡献,旨在简化跟踪查询。其设计深受 Python、C++ 和 Java 等语言的标准库启发。
该标准库的部分用途包括:
(1) 提供一种共享常用查询的方式,无需复制/粘贴大量 SQL 代码。
(2) 提高跟踪数据公开的抽象级别。标准库中的许多模块将底层跟踪概念(例如切片、跟踪)转换为开发人员可能更熟悉的概念,例如 Android 开发人员可能更熟悉的:应用启动、Binder 事务等。
标准库模块可以通过以下方式包含:
-- Include all tables/views/functions from the android.startup.startups -- module in the standard library. INCLUDE PERFETTO MODULE android.startup.startups; -- Use the android_startups table defined in the android.startup.startups -- module. SELECT * FROM android_startups;
注: 实测,啥也没查询到
Prelude 是一个特殊的模块,会自动包含在内。它包含一些通用的关键辅助表、视图和函数。
有关导入模块的更多信息,请参阅 INCLUDE PERFETTO MODULE 语句的语法文档。
2.2 Tags
点击标签按类别筛选模块:
android app-lifecycle chrome cpu gpu input ipc linux memory metadata performance power scheduling startup trace ui utilities virtualization
注:选中与不选中有啥区别?没看懂。
2.3 Package: prelude
2.3.1 Views/Tables
2.3.1.1 perf_sample.
来自 traced_perf 分析器的样本。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID 此性能样本的唯一标识符。 ts TIMESTAMP 样本的时间戳。 utid JOINID(thread.id) 被采样线程。 cpu LONG 被采样线程运行的核心。 cpu_mode STRING 被采样线程的执行状态(用户空间/内核空间)。 callsite_id JOINID(stack_profile_callsite.id) 如果设置,则表示已展开被采样线程的调用堆栈。 unwind_error STRING 如果设置,则表示此样本的展开过程中遇到错误。此类样本仍然通过 callsite_id 引用尽力而为的结果,并在展开停止的位置添加一个合成错误帧。 perf_session_id JOINID(perf_session.id) 区分来自不同分析流(即多个数据源)的样本。 ------------------------------------------------------------------------------
注: select * from perf_sample 查询结果为空。
2.3.1.2 counter
计数器是在解析trace数据期间放入轨道(tracks)中的值。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID 计数器值的唯一标识符 ts TIMESTAMP 获取计数器值的时间 track_id JOINID(track.id) 此计数器值所属的track value DOUBLE 值 arg_set_id ARGSETID 关于计数器值的附加信息 ------------------------------------------------------------------------------
注:select * from counter 是有值的。
2.3.1.3 slice
包含用户空间切片,用于描述跟踪期间线程正在执行的操作。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID 切片的 ID。 ts TIMESTAMP 切片开始的时间戳,单位为纳秒。实际值取决于 TraceConfig 中选择的 primary_trace_clock。这通常是设备启动后单调计数器的值,因此仅在跟踪上下文中有意义。 dur DURATION 切片的持续时间,单位为纳秒。 track_id JOINID(track.id) 此切片所在的track的ID。 category STRING 切片的“类别”。如果此切片源自 track_event,则此列包含发出的类别。否则,它可能为空(少数例外情况除外)。 name STRING 切片的名称,描述切片期间发生的情况。 depth LONG 切片在当前切片堆栈中的深度。 parent_id JOINID(slice.id) 此切片的父切片(即直接祖先切片)的 ID。 arg_set_id ARGSETID 参数集关联到此切片的ID。 thread_ts TIMESTAMP 切片开始时的线程时间戳。仅当启用了 track_event 的线程时间戳收集时,此列才会填充。 thread_dur DURATION 此切片使用的线程时间。仅当启用了 track_event 的线程时间戳收集时,此列才会填充。 thread_instruction_count LONG 切片开始时 CPU 指令计数器的值。仅当启用了 track_event 的线程指令收集时,此列才会填充。 thread_instruction_delta LONG 切片开始和结束时 CPU 指令计数器值的变化量。仅当启用了 track_event 的线程指令收集时,此列才会填充。 cat STRING category的别名。 slice_id JOINID(slice.id) id的别名。 ------------------------------------------------------------------------------
注:select * from slice 是有值的。
2.3.1.4 instant
包含来自用户空间的即时事件,这些事件指示某一时刻发生的事情。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ ts TIMESTAMP 时间戳 事件发生的时间戳。 track_id JOINID(track.id) 此事件发生的轨道 ID。 name STRING 事件发生的名称。名称描述事件发生期间发生的事情。 arg_set_id ARGSETID 与此事件关联的参数集的 ID。 ------------------------------------------------------------------------------
注:select * from instant 是有值的。name列比如 "binder transaction async", "binder async rcv", "IRQ (arch_timer)", "NET_RX", "RCU"等。
2.3.1.5 slices
slice 表的别名
------------------------------------------------------------------------------ Column Type Description ------------------------------------------------------------------------------ id JOINID(slice.id) Alias of slice.id. ts TIMESTAMP Alias of slice.ts. dur DURATION Alias of slice.dur. track_id OINID(track.id) Alias of slice.track_id. category STRING Alias of slice.category. name STRING Alias of slice.name. depth LONG Alias of slice.depth. parent_id JOINID(slice.id) Alias of slice.parent_id. arg_set_id ARGSETID Alias of slice.arg_set_id. thread_ts TIMESTAMP Alias of slice.thread_ts. thread_dur DURATION Alias of slice.thread_dur. thread_instruction_count LONG Alias of slice.thread_instruction_count. thread_instruction_delta LONG lias of slice.thread_instruction_delta. cat STRING Alias of slice.cat. slice_id JOINID(slice.id) Alias of slice.slice_id. ------------------------------------------------------------------------------
注: slices 表是 slice 表的别名,实测其内容是一样的。
2.3.1.6 thread
包含跟踪过程中看到的线程信息。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID 线程的id, 建议使用 utid。 utid ID 唯一线程id。此id与操作系统线程tid 不同。这是一个与每个线程关联的单调递增数字。操作系统线程tid不能用作主键,因为大多数内核会回收 tid 和 pid。 tid LONG 此线程的操作系统tid。注意:此tid 在跟踪的整个生命周期内并非唯一,因此不能用作主键,请改用 utid。 name STRING 线程的名称。可以从多个来源获取(例如 ftrace、/proc 抓取、跟踪事件等)。 start_ts TIMESTAMP 此线程的开始时间戳(如果已知)。在大多数情况下为 null,除非启用了线程创建事件(例如 Linux/Android 上的 task_newtask ftrace 事件)。 end_ts TIMESTAMP 此线程的结束时间戳(如果已知). 大多数情况下为空,除非启用了线程销毁事件(例如 Linux/Android 上的 sched_process_free ftrace 事件)。 upid JOINID(process.id) 承载此线程的进程。 is_main_thread BOOL 布尔值,指示此线程是否为进程中的主线程。 is_idle BOOL 布尔值,指示此线程是否为内核空闲线程。 machine_id LONG 机器标识符,远程机器上的线程非空。 arg_set_id ARGSETID 此线程的额外参数。 ------------------------------------------------------------------------------
2.3.1.7 process
包含跟踪过程中观察到的进程信息.
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID 进程的ID。建议使用 upid。 upid JOINID(process.id) 唯一进程id。此id与操作系统进程pid 不同。这是一个与每个进程关联的单调递增数字。操作系统进程pid不能用作主键,因为大多数内核会循环使用 tid 和 pid。 pid LONG 此进程的操作系统pid。注意:此pid 在跟踪的整个生命周期内并非唯一,因此不能用作主键。请改用upid。 name STRING 进程的名称。可以从多个来源获取(例如 ftrace、/proc 抓取、跟踪事件等)。 start_ts TIMESTAMP 此进程的开始时间戳(如果已知)。在大多数情况下为 null,除非启用了进程创建事件(例如 Linux/Android 上的 task_newtask ftrace 事件)。 end_ts TIMESTAMP 此进程的结束时间戳(如果已知). 大多数情况下为空,除非启用了进程销毁事件(例如,Linux/Android 上的 sched_process_free ftrace 事件)。 parent_upid JOINID(process.id) 导致此进程生成的进程的 UID。 uid LONG 进程的 Unix 用户 ID。 android_appid LONG 此进程的 Android 应用 ID。 android_user_id LONG 此进程的 Android 用户 ID。 cmdline STRING 此进程的 /proc/cmdline。 arg_set_id ARGSETID 此进程的额外参数。 machine_id LONG 机器标识符,远程机器上的进程非空。 ------------------------------------------------------------------------------
2.3.1.8 args
允许向其他强类型表添加元数据的任意键值对
视图允许添加元数据到其他强类型表中,从而创建任意键值对。注意:对于给定的行,int_value、string_value 和 real_value 中只有一个非空。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID arg表内的 ID。 arg_set_id ARGSETID 单个参数集的 ID。 flat_key STRING 参数的“扁平键”:这是不带任何数组索引的键。 key STRING 参数的键。 int_value LONG 参数的整数值。 string_value STRING 参数的字符串值。 real_value DOUBLE 参数的双精度浮点数值。 value_type STRING 参数值的类型。可以是 'int'、'uint'、'string'、'real'、'pointer'、'bool' 或 'json' 之一。 display_value STRING 参数的人类可读格式化值。 ------------------------------------------------------------------------------
2.3.1.9 perf_session
包含跟踪中的 Linux perf 会话。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id LONG 性能会话 ID。建议使用 perf_session_id。 perf_session_id LONG 性能会话 ID。 cmdline STRING 用于收集数据的命令行。 ------------------------------------------------------------------------------
注: select * from perf_session 查询是没有值的。
2.3.1.10 android_logs
查看 Android logcat 日志条目。注意:此表未按时间戳排序。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID 日志对应的表行。 ts TIMESTAMP 日志条目的时间戳。 utid JOINID(thread.id) 写入日志条目的线程。 prio LONG 日志优先级。3=调试,4=信息,5=警告,6=错误。 tag STRING 日志条目的标签。 msg STRING 日志条目的内容。 ------------------------------------------------------------------------------
注: select * from android_logs 查询是没有值的,是空表。
2.3.1.11 track
track是跟踪处理器中的一个基本概念,它代表了相同类型且具有相同上下文的事件的“时间线”。有关更详细的解释和示例,请参阅 https://perfetto.dev/docs/analysis/trace-processor#tracks。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID 此轨道的唯一标识符。与 |track_id| 相同,建议使用 |track_id|。 name STRING 轨道的名称;某些类型的轨道(例如线程轨道)可以为空。 type STRING 轨道的类型指示轨道包含的数据类型。每个轨道都由类型和一组维度组合唯一标识:类型允许在整个轨道集合中标识具有相同数据类型的轨道集合,而维度允许区分该集合中的不同轨道。 dimension_arg_set_id ARGSETID 用于唯一标识给定类型中轨道的维度。与 args 表连接或使用 EXTRACT_ARG 辅助函数展开 args。 parent_id JOINID(track.id) 此轨道的“父”轨道。仅当使用 Perfetto 的 track_event API 创建的轨道不为空时才为空。 source_arg_set_id ARGSETID 包含轨道额外信息的通用键值对。可与 args 表连接,或使用 EXTRACT_ARG 辅助函数展开 args。 machine_id LONG 机器标识符,远程机器上的轨道非空。 track_group_id LONG 一个不透明键,指示此轨道属于一组“概念上”相同的轨道。跟踪处理器中的轨道不允许事件重叠,以便于分析(例如,SQL 窗口函数、SPAN JOIN 和其他类似运算符)。但是,在可视化设置(例如,用户界面)中,这种区别无关紧要,所有具有相同 track_group_id 的轨道都应合并为一个逻辑上的“用户界面轨道”。 ------------------------------------------------------------------------------
注: 其 name 条目如 "Irq Cpu 7", "FramebufferSurface", "SoftIrq Cpu 6"
2.3.1.12 thread_track
与单个线程关联的轨道。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID(track.id) 此thread track的唯一标识符。 name STRING track的名称。 type STRING track的类型指示跟踪包含的数据类型。 每个跟踪都由类型和一组维度组合唯一标识:类型允许在整个跟踪集合中识别具有相同数据类型的一组跟踪,而维度允许区分该集合中的不同跟踪。 parent_id JOINID(track.id) 此track的“父”轨道。仅当使用 Perfetto 的 track_event API 创建的tracks不为空时才为真。 source_arg_set_id ARGSETID 此跟踪的参数, 用于存储有关此track在跟踪中的“来源”的信息。例如:此track是否源自 atrace、Chrome 跟踪点等。 machine_id LONG 机器标识符,对于远程计算机上的跟踪,此值不为空。 utid JOINID(thread.id) 此跟踪关联的 utid。 ------------------------------------------------------------------------------
注: select * from thread_track 看只有 id type utid 字段有值,其它都为null.
2.3.1.13 process_track
与单个进程关联的轨道
------------------------------------------------------------------------------ 列 类型 描述 ------------------------------------------------------------------------------ id ID(track.id) 此process track的唯一标识符。 name STRING track的名称。 type STRING track 的类型指示跟踪包含的数据类型。 每个track 都由类型和一组维度组合唯一标识:类型允许在整个track 集合中标识具有相同数据类型的一组跟踪,而维度允许区分该集合中的不同跟踪。 parent_id JOINID(track.id) 此track 的“父”track 。仅当使用 Perfetto 的 track_event API 创建的跟踪不为空时才为空。 source_arg_set_id ARGSETID 此跟踪的参数, 用于存储有关此跟踪在跟踪中的“来源”的信息。例如:此跟踪是否源自 atrace、Chrome 跟踪点等。 machine_id LONG 机器标识符,对于远程计算机上的跟踪,此值不为空。 upid JOINID(process.id) 此跟踪关联的 upid。 ------------------------------------------------------------------------------
2.3.1.14 cpu_track
与单个 CPU 关联的轨道.
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID(track.id) 此cpu track的唯一标识符。 name STRING 跟踪的名称。 type STRING track的类型指示track包含的数据类型. 每个track都由类型和一组维度组合唯一标识:类型允许在整个跟踪集合中识别具有相同数据类型的一组跟踪,而维度允许区分该集合中的不同跟踪。 parent_id JOINID(track.id) 此track的“父”track。仅当使用 Perfetto 的 track_event API 创建的跟踪才不为空。 source_arg_set_id ARGSETID 此track的参数, 用于存储有关此track在track中的“来源”的信息。例如:此track是否源自 atrace、Chrome 跟踪点等。 machine_id LONG 机器标识符,对于远程计算机上的track,此值不为空。 cpu LONG track关联的 CPU。 ------------------------------------------------------------------------------
注: select * from cpu_track 看 name 字段包含 "Irq Cpu 1", "SoftIrq Cpu 0", type 字段包含 "cpu_irq", "cpu_softirq", cpu 字段0-7.
2.3.1.15 gpu_track
包含与 GPU 松散关联的track的表.
注意:此表已弃用,因为它与其他表的设计不一致(例如,缺少 GPU 列,混杂了许多几乎无关的track)。请直接使用 track 表。
注: select * from gpu_track 查全是空。
2.3.1.16 ftrace_event
此视图包含trace中的所有 ftrace 事件。此表仅用于调试目的,不应在生产环境中使用(例如指标、标准库等)。另请注意,如果已禁用原始 ftrace 解析,则此表可能为空。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID 此 ftrace 事件的唯一标识符。 ts TIMESTAMP 此事件的时间戳。 name STRING ftrace 事件名称。 cpu LONG 此事件触发的 CPU(仅在单机跟踪中有效)。对于多机跟踪,请使用 ucpu 连接 cpu 表以获取每台机器的 CPU 标识符。 utid JOINID(thread.id) 此事件触发的线程。 arg_set_id ARGSETID 与此事件关联的键值对集合。 common_flags LONG 此事件的 ftrace 事件标志。目前仅针对 sched_waking 事件发出。 ucpu LONG 此事件触发的唯一 CPU 标识符。 ------------------------------------------------------------------------------
2.3.1.17 raw
此表已弃用。请改用包含相同行的 ftrace_event 表;此表只是一个(命名不当的)别名。
2.3.1.18 frame_slice
在 Android 上查看包含图形帧事件的表。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID(slice.id) slice.id 的别名。 ts TIMESTAMP slice.ts 的别名。 dur DURATION slice.dur 的别名。 track_id JOINID(track.id) slice.track_id 的别名。 category STRING slice.category 的别名。 name STRING slice.name 的别名。 depth LONG slice.depth 的别名。 parent_id JOINID(frame_slice.id) slice.parent_id 的别名。 arg_set_id LONG slice.arg_set_id 的别名。 layer_name STRING 此切片所在的图形层的名称。 frame_number LONG 此切片关联的帧号。 queue_to_acquire_time LONG 此缓冲区和图层从排队到获取的时间间隔。 acquire_to_latch_time LONG 此缓冲区和图层从获取到锁存的时间间隔。 latch_to_present_time LONG 此缓冲区和层从闩锁到呈现之间的时间。 ------------------------------------------------------------------------------
注: select * from frame_slice 查询结果全为空。
2.3.1.19 gpu_slice
在 Android 上查看包含图形帧事件的表。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID(slice.id) slice.id 的别名。 ts TIMESTAMP slice.ts 的别名。 dur DUR 持续时间 slice.dur 的别名。 track_id JOINID(track.id) slice.track_id 的别名。 category STRING slice.category 的别名。 name STRING slice.name 的别名。 depth LONG slice.depth 的别名。 parent_id JOINID(frame_slice.id) slice.parent_id 的别名。 arg_set_id LONG slice.arg_set_id 的别名。 context_id LONG 上下文 ID。 render_target LONG 渲染目标 ID。 render_target_name STRING 渲染目标的名称。 render_pass LONG 渲染通道 ID。 render_pass_name STRING 渲染通道的名称。 command_buffer LONG 命令缓冲区 ID。 command_buffer_name STRING 命令缓冲区的名称。 frame_id LONG 帧 ID。 submission_id LONG 提交 ID。 hw_queue_id LONG 硬件队列 ID。 upid JOINID(process.id) 进程 ID。 render_subpasses STRING 渲染子通道。 ------------------------------------------------------------------------------
注: select * from gpu_slice 查到的结果全是空。
2.3.1.20 expected_frame_timeline_slice
此表包含有关display帧或surface帧的预期时间表的信息。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID(slice.id) slice.id 的别名。 ts TIMESTAMP slice.ts 的别名。 dur DUR 持续时间 slice.dur 的别名。 track_id JOINID(track.id) slice.track_id 的别名。 category STRING slice.category 的别名。 name STRING slice.name 的别名。 depth LONG slice.depth 的别名。 parent_id JOINID(frame_slice.id) slice.parent_id 的别名。 arg_set_id LONG slice.arg_set_id 的别名。 display_frame_token LONG 显示帧标记(垂直同步 ID)。 surface_frame_token LONG 表面帧标记(垂直同步 ID),如果是显示帧则为 null。 upid JOINID(process.id) 生成表面帧的应用程序的唯一进程 ID。 layer_name STRING 如果这是一个表面帧,则为图层名称。 ------------------------------------------------------------------------------
注: select * from expected_frame_timeline_slice 看 layer_name 条目都是 "TX-com.XXX".
2.3.1.21 actual_frame_timeline_slice
此表包含有关显示帧(display frame)或表面帧(surface frame)性能的实际时间表和附加分析的信息。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID(slice.id) slice.id 的别名。 ts TIMESTAMP slice.ts 的别名。 dur DUR 持续时间 slice.dur 的别名。 track_id JOINID(track.id) slice.track_id 的别名。 category STRING slice.category 的别名。 name STRING slice.name 的别名。 depth LONG slice.depth 的别名。 parent_id JOINID(frame_slice.id) slice.parent_id 的别名。 arg_set_id LONG slice.arg_set_id 的别名。 display_frame_token LONG 显示帧标记(垂直同步 ID)。 upid JOINID(process.id) Surface 帧标记(垂直同步 ID),如果是显示帧则为 null。 surface_frame_token LONG 生成 Surface 帧的应用程序的唯一进程 ID。 layer_name STRING 如果是表面帧,则为图层名称。 present_type STRING 帧的当前状态(例如:准时/提前/延迟)。 on_time_finish LONG 帧是否准时完成。 gpu_composition LONG 帧是否使用 GPU 合成。 jank_type STRING 如果存在卡顿,则指定此帧的卡顿类型;如果没有卡顿,则为 none。 jank_severity_type STRING 卡顿的严重程度:如果没有卡顿,则为 none。 prediction_type STRING 帧的预测类型(例如:有效/过期)。 jank_tag STRING 基于卡顿类型的卡顿标签,用于切片可视化。 jank_tag_experimental STRING 基于卡顿类型的卡顿标签(实验性),用于切片可视化。 ------------------------------------------------------------------------------
2.3.1.22 heap_graph_class
用于存储 ART 堆图中的类信息。它表示堆中存在的 Java/Kotlin 类,包括它们的名称、继承关系和加载上下文。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID 此堆图类的唯一标识符。 name STRING (可能已混淆)类的名称。 deobfuscated_name STRING 如果类名已混淆且提供了反混淆映射,则为反混淆后的名称。 location STRING 包含该类的 APK/Dex/JAR 文件。 superclass_id JOINID(heap_graph_class.id) 此类的父类。 classloader_id LONG 加载此类的类加载器。 kind STRING 类的类型。 ------------------------------------------------------------------------------
注: 使用 select * from heap_graph_class 查询结果全为空。
2.3.1.23 heap_graph_object
查看 Dalvik 堆上的对象。
所有具有相同 (upid, graph_sample_ts) 的行属于同一个转储。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID 此堆图对象的唯一标识符。 upid JOINID(process.id) 目标进程的唯一进程 ID。 graph_sample_ts TIMESTAMP 此转储的时间戳。 self_size LONG 此对象在 Java 堆上使用的大小。 native_size LONG 此对象使用的本地内存的近似值,由 libcore.util.NativeAllocationRegistry.size 报告。 reference_set_id JOINID(heap_graph_reference.reference_set_id) 与 heap_graph_reference 的连接键,其中包含此对象字段中引用的所有对象。 reachable BOOL 此对象是否可从 GC 根访问。如果为 false,则此对象是未回收的垃圾。 heap_type STRING 此对象存储在 ART 堆中的类型(app、zygote、boot image)。 type_id JOINID(heap_graph_class.id) 此对象所属的类。 root_type STRING 如果不为 NULL,则此对象是 GC 根。 root_distance LONG 与根对象的距离。 ------------------------------------------------------------------------------
注: 使用 select * from heap_graph_object 查询结果全为空。
2.3.1.24 heap_graph_reference
查看堆图对象之间的多对多映射。
此映射将具有给定 reference_set_id 的对象与其字段所引用的对象关联起来。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID 此堆图引用的唯一标识符。 reference_set_id JOINID(heap_graph_object.reference_set_id) 指向堆图对象 reference_set_id 的连接键。 owner_id JOINID(heap_graph_object.id) 拥有此 reference_set_id 的对象的 ID。 owned_id JOINID(heap_graph_object.id) 被引用对象的 ID。 field_name STRING 引用对象的字段。例如:Foo.name。 field_type_name STRING 字段的静态类型. 例如:java.lang.String。 deobfuscated_field_name STRING 如果 field_name 已被混淆且提供了反混淆映射,则为反混淆后的名称。 ------------------------------------------------------------------------------
注: 使用 select * from heap_graph_reference 查询结果全为空。
2.3.1.25 memory_snapshot
查看包含内存快照的表。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID 此快照的唯一标识符。 timestamp TIMESTAMP 快照时间。 track_id JOINID(track.id) 此快照的轨道。 detail_level STRING 此快照的详细级别。 ------------------------------------------------------------------------------
注: 使用 select * from memory_snapshot 查询结果全为空。
2.3.1.26 process_memory_snapshot
查看包含进程内存快照的表。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID 此快照的唯一标识符。 snapshot_id JOINID(memory_snapshot.id) 此快照的快照 ID。 upid JOINID(process.id) 此快照的进程 ID。 ------------------------------------------------------------------------------
注: 使用 select * from process_memory_snapshot 查询结果全为空。
2.3.1.27 memory_snapshot_node
查看包含内存快照节点的表。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID 此节点的唯一标识符。 process_snapshot_id JOINID(process_memory_snapshot.id) 此节点的进程快照 ID。 parent_node_id JOINID(memory_snapshot_node.id) 此节点的父节点(可选)。 path STRING 此节点的路径。 size LONG 分配给此节点的内存大小。 effective_size LONG 此节点使用的有效内存大小。 arg_set_id ARGSETID 节点的附加参数集。 ------------------------------------------------------------------------------
注: 使用 select * from memory_snapshot_node 查询结果全为空。
2.3.1.28 memory_snapshot_edge
带有内存快照边缘的表.
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID 此边的唯一标识符。 source_node_id JOINID(memory_snapshot_node.id) 此边的源节点。 target_node_id JOINID(memory_snapshot_node.id) 此边的目标节点。 importance LONG 此边的重要性。 ------------------------------------------------------------------------------
注: 使用 select * from memory_snapshot_edge 查询结果全为空。
2.3.1.29 counter_track
查看包含类似计数器事件的轨道。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID(track.id) 此 CPU counter track 的唯一标识符。 name STRING 跟踪的名称。 parent_id JOINID(track.id) 此track的“父”track。仅当使用 Perfetto 的 track_event API 创建的跟踪不为空时才为真。 type STRING 跟踪的类型指示跟踪包含的数据类型, 如 "cpu_idle", "atrace_counter". 每个跟踪都由类型和一组维度组合唯一标识:类型允许在整个跟踪集合中标识具有相同数据类型的一组跟踪,而维度允许区分该集合中的不同跟踪。 dimension_arg_set_id ARGSETID 用于唯一标识给定类型中跟踪的维度。 source_arg_set_id ARGSETID 此track的参数, 用于存储有关此跟踪在跟踪中的“来源”的信息。例如:此跟踪是否源自 atrace、Chrome 跟踪点等。 machine_id LONG 机器标识符,远程机器上的跟踪非空。 unit STRING 计数器的单位。此列很少填写。 description STRING 此track的描述。仅用于调试目的。 ------------------------------------------------------------------------------
注: 看起来像常规的 systrace_c 就打印到这个表中。
2.3.1.30 cpu_counter_track
包含与 CPU 关联的类似计数器事件的轨道.
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID(track.id) 此 CPU 计数器跟踪的唯一标识符。 name STRING 跟踪名称。 type STRING 跟踪类型指示跟踪包含的数据类型。 每个跟踪都由类型和一组维度组合唯一标识:类型允许在整个跟踪集合中标识具有相同数据类型的一组跟踪,而维度允许区分该集合中的不同跟踪。 parent_id JOINID(track.id) 此跟踪的“父”跟踪。仅当使用 Perfetto 的 track_event API 创建的跟踪不为空时才为空。 source_arg_set_id ARGSETID 此跟踪的参数, 用于存储有关此跟踪在跟踪中的“来源”的信息。例如:此跟踪是否源自 atrace、Chrome 跟踪点等。 machine_id LONG 机器标识符,对于远程计算机上的跟踪,此列不为空。 unit STRING 计数器的单位。此列很少填写。 description STRING 此轨道的描述。仅用于调试目的。 cpu LONG 此音轨关联的 CPU。 ------------------------------------------------------------------------------
注:使用 select * from cpu_counter_track 看,name 字段只有 "cpuidle", type 字段只有 "cpu_idle"
2.3.1.31 gpu_counter_track
表格:包含与 GPU 关联的计数器式事件的跟踪。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID(track.id) 此 GPU 计数器跟踪的唯一标识符。 name STRING 跟踪名称。 type STRING 跟踪类型指示跟踪包含的数据类型。 每个跟踪都由类型和一组维度组合唯一标识:类型允许在整个跟踪集合中识别具有相同数据类型的一组跟踪,而维度允许区分该集合中的不同跟踪。 parent_id JOINID(track.id) 此跟踪的“父”跟踪。仅当使用 Perfetto 的 track_event API 创建的跟踪不为空时才为空。 source_arg_set_id ARGSETID 此跟踪的参数, 用于存储有关此跟踪在跟踪中的“来源”的信息。例如:此跟踪是否源自 atrace、Chrome 跟踪点等。 machine_id LONG 机器标识符,对于远程计算机上的跟踪,此列不为空。 unit STRING 计数器的单位。此列很少填写。 description STRING 此轨道的描述。仅用于调试目的。 gpu_id LONG 此轨道关联的 GPU。 ------------------------------------------------------------------------------
注: 使用 select * from gpu_counter_track 查询结果全为空。
2.3.1.32 process_counter_track
包含与进程相关的计数器式事件的轨道表。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID(track.id) 此进程计数器跟踪的唯一标识符。 name STRING 跟踪的名称。 type STRING 跟踪的类型指示跟踪包含的数据类型。 每个跟踪都由类型和一组维度组合唯一标识:类型允许在整个跟踪集合中识别具有相同数据类型的一组跟踪,而维度允许区分该集合中的不同跟踪。 parent_id JOINID(track.id) 此跟踪的“父”跟踪。仅当使用 Perfetto 的 track_event API 创建的跟踪不为空时才为空。 source_arg_set_id ARGSETID 此跟踪的参数, 用于存储有关此跟踪在跟踪中的“来源”的信息。例如:此跟踪是否源自 atrace、Chrome 跟踪点等。 machine_id LONG 机器标识符,对于远程计算机上的跟踪,此列不为空。 unit STRING 计数器的单位。此列很少填写。 description STRING 此轨道的描述。仅用于调试目的。 upid LONG 此音轨关联的进程的 upid。 ------------------------------------------------------------------------------
注: 使用 select * from process_counter_track 看 name 字段多种多样,type字段全为 atrace_counter, 带 upid 字段。比如SF进程中的 systrace_c 类型的 "NumLayers", "FastPath", "hasClientComposition" 都在这个表中。
2.3.1.33 thread_counter_track
包含与线程关联的计数器状事件的轨道。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID(track.id) 此线程计数器跟踪的唯一标识符。 name STRING 跟踪的名称。 type STRING 跟踪的类型指示跟踪包含的数据类型. 每个跟踪都由类型和一组维度组合唯一标识:类型允许在整个跟踪集合中识别具有相同数据类型的一组跟踪,而维度允许区分该集合中的不同跟踪。 parent_id JOINID(track.id) 此跟踪的“父”跟踪。仅当使用 Perfetto 的 track_event API 创建的跟踪不为空时才为空。 source_arg_set_id JOINID(track.id) 此跟踪的参数, 用于存储有关此跟踪在跟踪中的“来源”的信息。例如:此跟踪是否源自 atrace、Chrome 跟踪点等。 machine_id LONG 机器标识符,对于远程计算机上的跟踪,此列不为空。 unit STRING 计数器的单位。此列很少填写。 description STRING 此轨道的描述。仅用于调试目的。 utid LONG 此轨道关联的线程的 utid。 ------------------------------------------------------------------------------
注: 使用 select * from thread_counter_track 查看全是空。
2.3.1.34 perf_counter_track
表格:从 Linux perf 收集的包含计数器类事件的轨道。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID(track.id) 此线程计数器跟踪的唯一标识符。 name STRING 跟踪的名称。 type STRING 跟踪的类型指示跟踪包含的数据类型. 每个跟踪都由类型和一组维度组合唯一标识:类型允许在整个跟踪集合中识别具有相同数据类型的一组跟踪,而维度允许区分该集合中的不同跟踪。 parent_id JOINID(track.id) 此跟踪的“父”跟踪。仅当使用 Perfetto 的 track_event API 创建的跟踪不为空时才为空。 source_arg_set_id ARGSETID 此跟踪的参数, 用于存储有关此跟踪在跟踪中的“来源”的信息。例如:此跟踪是否源自 atrace、Chrome 跟踪点等。 machine_id LONG 机器标识符,对于远程计算机上的跟踪,此列不为空。 unit STRING 计数器的单位。此列很少填写。 description STRING 此轨道的描述。仅用于调试目的。 perf_session_id LONG 此计数器捕获到的性能会话 ID。 cpu LONG 此计数器关联的 CPU。如果计数器未关联任何 CPU,则可以为 null。 is_timebase BOOL 此计数器是否为会话的采样时间基准。 ------------------------------------------------------------------------------
注: 使用 select * from perf_counter_track 查看全是空。
2.3.1.35 counters
`counter` 表的别名,所有成员和 counter 表都是一样的。
2.3.1.36 cpu
查看包含有关本次跟踪所用设备上 CPU 的信息。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID 此 CPU 的唯一标识符。与 |ucpu| 相同,建议使用 |ucpu|。 ucpu ID 此 CPU 的唯一标识符。对于远程机器,此标识符不等于 |cpu|;对于主机,此标识符等于 |cpu|。 cpu LONG 从 0 开始的 CPU 核心标识符。 cluster_id LONG 集群 ID,同一集群中的 CPU 共享此 ID。 processor STRING 描述此核心的字符串。 machine_id LONG 机器标识符,远程机器上的 CPU 为非空值。 capacity LONG 设备 CPU 的容量,该指标指示设备上 CPU 的相对性能。详情请参阅:https://www.kernel.org/doc/Documentation/devicetree/bindings/arm/cpu-capacity.txt arg_set_id ARGSETID 与此 CPU 关联的额外键值对。 ------------------------------------------------------------------------------
注: 使用 select * from cpu 看 cluster_id 字段竟然全是0.
2.3.1.37 cpu_available_frequencies
查看包含设备上 CPU 能够运行的频率值。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID 此 CPU 频率的唯一标识符。 cpu LONG 此频率对应的 CPU,仅在单机跟踪中有意义。对于多机跟踪,请将 ucpu 列与 CPU 表连接,以获取每台机器的 CPU 标识符。 freq LONG CPU 频率,单位为 kHz。 ucpu LONG 此切片执行所在的 CPU(仅在单机跟踪中有意义)。对于多机跟踪,请将 ucpu 列与 CPU 表连接,以获取每台机器的 CPU 标识符。 ------------------------------------------------------------------------------
注: 上查询结果为空。
2.3.1.38 sched
包含内核线程调度信息的调度切片。当使用 Linux "ftrace" 数据源并启用 "sched/switch" 和 "sched/wakeup*" 事件时,会收集这些切片。
此视图中的每一行在 thread_state 表中始终存在匹配行,且 thread_state.state = 'Running'。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID 此调度切片的唯一标识符。 ts TIMESTAMP 切片开始的时间戳。 dur DURATION 切片的持续时间。 cpu LONG 切片执行所在的 CPU(仅在单机跟踪中有效)。对于多机跟踪,请使用 ucpu 连接 cpu 表以获取每台机器的 CPU 标识符。 utid JOINID(thread.id) 跟踪中线程的唯一 ID。 end_state STRING 表示切片结束时内核线程调度状态的字符串. 字符串中的各个字符含义如下:R(可运行)、S(等待唤醒)、D(处于不可中断睡眠状态)、T(已挂起)、t(正在跟踪)、X(正在退出)、P(已停用)、W(正在唤醒)、I(空闲)、N(不计入平均负载)、K(可通过致命信号唤醒)和 Z(僵尸线程,等待清理)。 priority LONG 线程运行的内核优先级。 ucpu LONG 切片执行所在的唯一 CPU 标识符。 ts_end LONG 旧列,不应再使用。 ------------------------------------------------------------------------------
注: 看起来是running时间的切片大小。
2.3.1.39 sched_slice
此表是 sched 表的别名。建议使用 sched 表代替。
2.3.1.40 thread_state
此表包含跟踪期间系统上每个线程的调度状态。
此表中 |state| = 'Running' 的行,在 sched_slice 表中将有对应的行。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ id ID 此线程状态的唯一标识符。 ts TIMESTAMP 切片开始的时间戳。 dur DURATION 切片的持续时间。 cpu LONG 线程执行所在的 CPU(仅在单机跟踪中有效)。对于多机跟踪,请使用 ucpu 与 cpu 表连接以获取每台机器的 CPU 标识符。 utid JOINID(thread.id) 线程在跟踪中的唯一 ID。 state STRING 线程的调度状态。可以是“Running”或 |sched_slice.end_state| 中描述的任何状态。 io_wait LONG 指示此线程是否因 I/O 而阻塞。 blocked_function STRING 此线程阻塞的内核函数。 waker_utid JOINID(thread.id) 导致此线程被唤醒的线程的唯一线程 ID。 waker_id JOINID(thread_state.id) 导致此线程被唤醒的唯一线程状态 ID。 irq_context LONG 唤醒操作来自中断上下文还是进程上下文。 ucpu LONG 线程执行时使用的唯一 CPU 标识符。 ------------------------------------------------------------------------------
注: select * from thread_state 看,blocked_function 恒为NULL,确认trace event是使能的,但是的确解析不出来。
2.3.1.41 trace_metrics
查看列出跟踪处理器内置的所有指标。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ name 字符串 指标的名称。 ------------------------------------------------------------------------------
2.3.1.42 trace_bounds
查看 `trace_bounds` 表的定义。这些值由跟踪处理器在解析跟踪时填充。建议依赖 `trace_start()` 和 `trace_end()` 函数,而不是直接依赖 `trace_bounds` 表。
------------------------------------------------------------------------------ 列 类型 说明 ------------------------------------------------------------------------------ start_ts TIMESTAMP 跟踪中的第一个时间戳。 end_ts TIMESTAMP 跟踪结束时间戳。 ------------------------------------------------------------------------------
注: 两个脚本查询结果:
select * from trace_bounds start_ts end_ts 6372278321676 6377317999754 select start_ts, end_ts, (end_ts - start_ts)/1e9 as delta_ts from trace_bounds start_ts end_ts delta_ts 6372278321676 6377317999754 5.039678078
delta_ts 值应该可以表示抓取trace的时长。
2.3.2 Functions
(1) trace_start -> TIMESTAMP。
获取跟踪的起始时间。返回时间戳:跟踪的起始时间。
(2) trace_end -> TIMESTAMP。
获取跟踪的结束时间。返回时间戳:跟踪的结束时间。
(3) trace_dur -> DURATION。
获取跟踪的持续时间。返回 DURATION:跟踪的持续时间。
(4) slice_is_ancestor -> BOOL。
给定两个slice ID,返回第一个切片是否是第二个切片的祖先。返回 BOOL:ancestor_id 切片是否是 descendant_id 切片的祖先。
---------------------------------------------- 参数 类型 说明 ---------------------------------------------- ancestor_id LONG 潜在祖先切片的 ID。 descendant_id LONG 潜在后代切片的 ID。 ----------------------------------------------
2.3.3 Macros
(1) cast_int
将 |value| 转换为 INT。返回值:表达式 (Expr)
----------------------------------------------
参数 类型 说明
----------------------------------------------
value 表达式 待转换的查询或子查询。
----------------------------------------------
(2) cast_double
将 |value| 转换为 DOUBLE。返回值:表达式 (Expr)
----------------------------------------------
参数 类型 说明
----------------------------------------------
value 表达式 待转换的查询或子查询。
----------------------------------------------
(3) cast_string
将 |value| 转换为 STRING。返回值:表达式 (Expr)
----------------------------------------------
参数 类型 说明
----------------------------------------------
value 表达式 待转换的查询或子查询。
----------------------------------------------
2.4 Package: chrome
chrome_deliver_android_input_event: DeliverInputEvent 是输入管道的第三步。
chrome_android_input: 收集给定 Android 输入 ID 的输入读取器、输入分发器和 DeliverInputEvent 步骤的信息。
select * from chrome_deliver_android_input_event --no such table
select * from chrome_android_input --no such table
...
2.5 Package: android
...
注: 下面这些指定的表都不存在。
2.6 Package: v8
...
2.7 Package: intervals
...
2.8 Package: counters
...
2.9 Package: linux
...
2.10 Package: pixel
...
2.11 Package: slices
...
2.12 Package: appleos
...
2.13 Package: graphs
...
2.14 Package: sched
...
2.15 Package: export
...
2.16 Package: traced
...
2.17 Package: pkvm
...
2.18 Package: stacks
...
2.19 Package: time
...
3. PerfettoSQL Syntax
本页面介绍了 PerfettoSQL 的语法。PerfettoSQL 是一种 SQL 方言,用于跟踪处理器和其他 Perfetto 分析工具中,以查询跟踪数据。
PerfettoSQL 是 SQLite 实现的 SQL 方言的直接继承者。具体来说,任何在 SQLite 中有效的 SQL 语句在 PerfettoSQL 中也有效。//https://www.sqlite.org/lang.html
然而,仅靠 SQLite 语法是不够的,原因有二:
(1) 它相当基础,例如,它不支持创建函数或宏。
(2) 它无法访问仅在 Perfetto 工具中提供的功能,例如,它无法创建高效的分析表,也无法从 PerfettoSQL 标准库导入模块等。
因此,PerfettoSQL 添加了一些新的语法,以改善编写 SQL 查询的体验。所有这些新增语法都包含关键字 PERFETTO,以明确表明它们仅适用于 PerfettoSQL。
3.1 Including PerfettoSQL modules
`INCLUDE PERFETTO MODULE` 用于导入 PerfettoSQL 模块(例如,来自 PerfettoSQL 标准库)中定义的所有表、视图、函数和宏。//https://perfetto.dev/docs/analysis/stdlib-docs
请注意,此语句的作用更类似于 C++ 中的 `#include` 语句,而不是 Java/Python 中的 `import` 语句。具体来说,模块中的所有对象都将在全局命名空间中可用,而无需使用模块名称进行限定。
示例:
-- Include all tables/views/functions from the android.startup.startups module -- in the standard library. INCLUDE PERFETTO MODULE android.startup.startups; -- Use the android_startups table defined in the android.startup.startups -- module. SELECT * FROM android_startups;
注: 一起运行查询结果为空,有以下条目:
startup_id ts ts_end dur package startup_type
对于交互式开发,密钥可以包含通配符:
-- Include all modules under android/. INCLUDE PERFETTO MODULE android.*; -- Or all stdlib modules: INCLUDE PERFETTO MODULE *; -- However, note, that both patterns are not allowed in stdlib.
注: 运行后啥也不显示。
3.2 Types
PerfettoSQL 支持以下类型,这些类型可用于表和视图模式、函数参数和返回类型:
------------------------------------------------------------------------------
类型 说明
------------------------------------------------------------------------------
LONG 64 位有符号整数
DOUBLE 双精度浮点数
BOOLEAN 布尔值(真/假)
STRING 文本字符串
BYTES 二进制数据
TIMESTAMP 绝对时间戳(纳秒)
DURATION 持续时间(纳秒)
ARGSETID 参数集的标识符。可以通过与 args 表的 arg_set_id 列连接来获取此参数集。
ID 此表的 ID 列。每个表只能有一个 ID 列,其值应唯一且符合 uint32 类型。
JOINID(table.column) 指向给定表的外键引用。表必须存在,且必须有一个名为 column 的 ID 类型列。
ID(table.column) ID 类型的变体,它既是此表的主键,也是指向另一个表的外键引用. 当给定表基于另一个表的行子集(例如,切片)时非常有用。
------------------------------------------------------------------------------
3.3 Defining functions
`CREATE PEFETTO FUNCTION` 允许在 SQL 中定义函数,这些函数可以是标量函数(返回单个值)或表值函数(返回一组行)。其语法与 PostgreSQL 或 Google SQL 中的语法类似:
标量函数(Scalar):`CREATE PERFETTO FUNCTION function_name(arg_list) RETURNS return_type AS sql_select_statement;`
表值函数(Table-valued):`CREATE PERFETTO FUNCTION function_name(arg_list) RETURNS TABLE(column_list) AS sql_select_statement;`
`arg_list` 和 `column_list` 是以逗号分隔的任意数量的 `argument_name` 和 `argument_type` 对的列表。
`sql_select_statement` 应该是一个有效的 SQL 语句,可以使用 `$argument_name` 语法来引用参数值。
示例:
-- Create a scalar function with no arguments. CREATE PERFETTO FUNCTION constant_fn() RETURNS LONG AS SELECT 1; -- Create a scalar function taking two arguments. CREATE PERFETTO FUNCTION add(x LONG, y LONG) RETURNS LONG AS SELECT $x + $y; -- Create a table function with no arguments CREATE PERFETTO FUNCTION constant_tab_fn() RETURNS TABLE(ts LONG, dur LONG) AS SELECT column1 as ts, column2 as dur FROM ( VALUES (100, 10), (200, 20) ); -- Create a table function with one argument CREATE PERFETTO FUNCTION sched_by_utid(utid LONG) RETURNS TABLE(ts LONG, dur LONG, utid LONG) AS SELECT ts, dur, utid FROM sched WHERE utid = $utid;
注: 无论是分开运行还是一起运行,都报错了。
3.4 Creating efficient tables
CREATE PERFETTO TABLE 允许定义针对跟踪分析查询优化的表。这些表比使用 CREATE TABLE 创建的 SQLite 原生表性能更高、内存效率更低。
但请注意,CREATE TABLE 的全部功能集并不支持:
(1) Perfetto 表创建后无法插入数据,且为只读。
(2) Perfetto 表必须使用 SELECT 语句定义和填充数据。它们不能通过列名和类型来定义。
示例:
-- Create a Perfetto table with constant values. CREATE PERFETTO TABLE constant_table AS SELECT column1 as ts, column2 as dur FROM ( VALUES (100, 10), (200, 20) ); -- Create a Perfetto table with a query on another table. CREATE PERFETTO TABLE slice_sub_table AS SELECT * FROM slice WHERE name = 'foo'; 注: 两个运行都报错了。
3.4.1 Schema
Perfetto 表可以有一个可选的显式模式。模式语法与函数参数或函数返回的表相同,即在表名或视图名后用括号括起来的以逗号分隔的(列名,列类型)对列表。
CREATE PERFETTO TABLE foo(x LONG, y STRING) AS
SELECT 1 as x, 'test' as y
3.4.2 Index
CREATE PERFETTO INDEX 命令允许您在 Perfetto 表上创建索引,类似于在 SQLite 数据库中创建索引的方式。这些索引基于特定的列构建,Perfetto 内部会将这些列按排序顺序维护。这意味着,对已建立索引的列(或列组)进行排序操作的速度将显著提升,如同对已排序的列进行操作一样。
注意:索引会占用大量内存,因此只有在需要提升性能时才应使用索引。
注意:索引会被基于索引表创建的视图使用,但不会被任何子表继承,如下面的 SQL 语句所示。
注意:如果查询对表的 id 列(该列是表的主键)进行筛选/连接,则无需添加 Perfetto 索引,因为 Perfetto 表已经针对可从排序中获益的操作进行了特殊的性能优化。
使用示例:
CREATE PERFETTO TABLE foo AS SELECT * FROM slice; -- Creates and stores an index `foo_track` on column `track_id` of table foo. CREATE PERFETTO INDEX foo_track ON foo(track_id); -- Creates or replaces an index created on two columns. It will be used for -- operations on `track_id` and can be used on operations on `name` only if -- there has been an equality constraint on `track_id` too. CREATE OR REPLACE PERFETTO INDEX foo_track_and_name ON foo(track_id, name);
注: 创建表的命令只能执行一次,执行一次后再执行就报错了。但是查到的为0.
现在这两个查询的性能应该截然不同:
-- This doesn't have an index so it will have to linearily scan whole column. SELECT * FROM slice WHERE track_id = 10 AND name > "b"; -- This has an index and can use binary search. SELECT * FROM foo WHERE track_id = 10 AND name > "b"; -- The biggest difference should be noticeable on joins: -- This join: SELECT * FROM slice JOIN track WHERE slice.track_id = track.id; -- will be noticeably slower than this: SELECT * FROM foo JOIN track WHERE slice.track_id = track.id;
索引可以删除:
DROP PERFETTO INDEX foo_track ON foo;
3.5 Creating views with a schema
可以使用 `CREATE PERFETTO VIEW` 创建视图,并可指定一个可选的模式。除了模式之外,它们的行为与常规 SQLite 视图完全相同。
注意:在标准库中,必须对每一列进行文档化,因此必须使用 `CREATE PERFETTO VIEW` 而不是 `CREATE VIEW`。
CREATE PERFETTO VIEW foo(x LONG, y STRING) AS
SELECT 1 as x, 'test' as y
注: 执行报错。
3.6 Defining macros
CREATE PEFETTO MACRO 允许在 SQL 中定义宏。宏的设计灵感来源于 Rust 中的宏。
以下是宏的推荐用法:
将表作为参数传递给类似函数的 SQL 代码片段。
为对性能要求较高的查询定义简单的常量。
宏功能强大,但如果使用不当,也会造成危险,使调试变得极其困难。因此,建议仅在必要时谨慎使用宏,并且仅用于上述推荐用途。
如果只是传递标量 SQL 值,通常首选函数,因为它们更清晰。但是,对于在对性能要求较高的查询中多次使用的简单常量,宏可能更高效,因为它避免了大量函数调用带来的潜在开销。
注意:宏在执行之前会经过预处理步骤进行展开。展开是一个纯粹的语法操作,涉及将宏调用替换为宏定义中的 SQL 标记。
由于宏是语法性的,因此宏中的参数类型和返回类型与函数中使用的类型不同,并且对应于 SQL 解析树的不同部分。以下是支持的类型:
-------------------------------------------------------
类型名称 说明
-------------------------------------------------------
Expr 对应于任何 SQL 标量表达式。
TableOrSubquery 对应于 SQL 表或子查询。
ColumnName 对应于表的列名。
-------------------------------------------------------
例:
-- Create a macro taking no arguments. Note how the returned SQL fragment needs -- to be wrapped in brackets to make it a valid SQL expression. -- -- Note: this is a strongly discouraged use of macros as a simple SQL -- function would also work here. CREATE PERFETTO MACRO constant_macro() RETURNS Expr AS (SELECT 1); -- Using the above macro. Macros are invoked by suffixing their names with !. -- This is similar to how macros are invoked in Rust. SELECT constant_macro!(); -- This causes the following SQL to be actually executed: -- SELECT (SELECT 1); -- A variant of the above. Again, strongly discouraged. CREATE PERFETTO MACRO constant_macro_no_bracket() RETURNS Expr AS 2; -- Using the above macro. SELECT constant_macro_no_bracket!(); -- This causes the following SQL to be actually executed: -- SELECT 2; -- Creating a macro taking a single scalar argument and returning a scalar. -- Note: again this is a strongly discouraged use of macros as functions can -- also do this. CREATE PERFETTO MACRO single_arg_macro(x Expr) RETURNS Expr AS (SELECT $x); SELECT constant_macro!() + single_arg_macro!(100); -- Creating a macro taking both a table and a scalar expression as an argument -- and returning a table. Note again how the returned SQL statement is wrapped -- in brackets to make it a subquery. This allows it to be used anywhere a -- table or subquery is allowed. -- -- Note: if tables are reused multiple times, it's recommended that they be -- "cached" with a common-table expression (CTE) for performance reasons. CREATE PERFETTO MACRO multi_arg_macro(x TableOrSubquery, y Expr) RETURNS TableOrSubquery AS ( SELECT input_tab.input_col + $y FROM $x AS input_tab; )
4. PerfettoSQL Style Guide
本页面提供了一份 Perfetta SQL 编写风格指南,该指南已在 Perfetta SQL 标准库的跟踪处理器中使用。此外,它还提供了有关自动格式化程序的指导。
4.1 Rules
(1) 每行长度不超过 80 个字符。
(2) 函数名、宏名和表/视图名均应使用小写蛇形命名法。
(3) SQL 关键字均应使用大写字母。
(4) 在 SQL 表达式换行时,连接关键字(AND/OR)应放在下一行的开头,而不是上一行的结尾。
4.2 Autoformatter
PerfettoSQL 自带一个自动格式化工具,由 Python 脚本 tools/format_sql.py 实现。这是一个简单的脚本,可以处理任何文件或目录,并自动将代码格式化为符合上述规则。
向标准库贡献代码时,必须运行此脚本。它会在运行 tools/gen_all 时自动执行,而 tools/gen_all 是 Perfetto 标准开发工作流程的一部分。提交前会检查您是否已执行此操作。
自动格式化工具并非完美无缺,经常会遇到一些难以察觉的特殊情况:
(1) 它无法处理复杂表达式中间的注释。建议将注释放在表达式的开头,而不是中间。
(2) 它无法格式化宏调用,因为宏调用在很多情况下语义非常复杂。
5. PerfettoSQL: backwards compatibility
PerfettoSQL 会尽最大努力减少向后不兼容的变更,但有时这种情况不可避免。在我们需要进行此类变更且预计会产生重大影响的情况下,本页面会记录以下内容:
日期/版本(Date/Version):此次变更的日期以及包含此变更的 Perfetto 首个版本发布日期
症状(Symptoms):如果您受到此变更的影响,可能会看到哪些异常行为或错误消息
背景(Context):我们进行此变更的原因,例如,为什么必须向后不兼容?
迁移(Migrations):建议您对 PerfettoSQL 进行哪些更改,以避免受到这些变更的影响。
5.1 Removal of stack_id and parent_stack_id columns from slice table
...
5.2 Change in semantic of type column on track tables
...
select name, type from track where name in ('process_track', 'thread_track') --多个同类型匹配可以这样写
5.3 Removal of type column from all non-track tables
posted on 2026-01-23 21:23 Hello-World3 阅读(226) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号