分库分表全面总结
目录
分库分表全面总结
分库分表的本质
分库分表是将单一数据库或表拆分为多个数据库或表,以提升系统性能的手段;分库分表主要用于解决单库单表数据量过大、并发压力高、存储瓶颈等问题。
空间换时间:通过增加存储架构的复杂度,换取性能和扩展性的提升。
分库分表方式
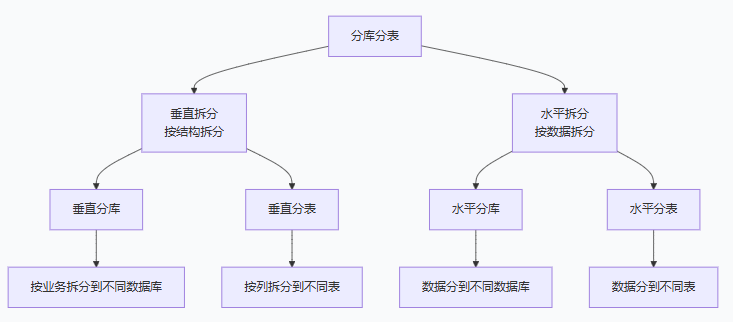
示例1:垂直分库(按业务拆分到不同数据库)
-- 原来的综合业务数据库
CREATE DATABASE ecommerce;
USE ecommerce;
CREATE TABLE users (...); -- 用户表
CREATE TABLE products (...); -- 商品表
CREATE TABLE orders (...); -- 订单表
CREATE TABLE payments (...); -- 支付表
CREATE TABLE logs (...); -- 日志表
-- 垂直分库后
CREATE DATABASE user_db; -- 用户相关数据库
USE user_db;
CREATE TABLE users (...);
CREATE TABLE user_profiles (...);
CREATE DATABASE product_db; -- 商品相关数据库
USE product_db;
CREATE TABLE products (...);
CREATE TABLE categories (...);
CREATE DATABASE order_db; -- 订单相关数据库
USE order_db;
CREATE TABLE orders (...);
CREATE TABLE order_items (...);
示例2:垂直分表(按列拆分到不同表)
-- 原来的用户大宽表
CREATE TABLE users (
id BIGINT PRIMARY KEY,
username VARCHAR(50),
password VARCHAR(100),
email VARCHAR(100),
phone VARCHAR(20),
address TEXT,
avatar_url VARCHAR(200),
bio TEXT,
created_at DATETIME,
updated_at DATETIME,
last_login DATETIME,
login_count INT
);
-- 垂直分表后(热点冷数据分离)
-- 热点表:经常查询的字段
CREATE TABLE user_base (
id BIGINT PRIMARY KEY,
username VARCHAR(50),
password VARCHAR(100),
email VARCHAR(100),
created_at DATETIME,
updated_at DATETIME,
INDEX idx_username (username),
INDEX idx_email (email)
);
-- 冷数据表:不常查询的字段
CREATE TABLE user_detail (
user_id BIGINT PRIMARY KEY,
phone VARCHAR(20),
address TEXT,
avatar_url VARCHAR(200),
bio TEXT,
last_login DATETIME,
login_count INT
);
示例3:水平分库(数据分布到不同数据库的同名表)
-- 原来的单库单表
CREATE DATABASE main_db;
USE main_db;
CREATE TABLE orders (
order_id BIGINT PRIMARY KEY,
user_id BIGINT,
amount DECIMAL(10,2),
status VARCHAR(20)
);
-- 水平分库后(按用户ID分库)
-- 数据库1(用户ID为偶数的订单)
CREATE DATABASE order_db_0;
USE order_db_0;
CREATE TABLE orders (...); -- 存储user_id%2=0的订单
-- 数据库2(用户ID为奇数的订单)
CREATE DATABASE order_db_1;
USE order_db_1;
CREATE TABLE orders (...); -- 存储user_id%2=1的订单
示例4:水平分表(数据分布到同库的不同表)
-- 原来的单表
CREATE TABLE order_2023 (
order_id BIGINT PRIMARY KEY,
user_id BIGINT,
amount DECIMAL(10,2),
order_date DATE
);
-- 水平分表后(按月分表)
CREATE TABLE order_202301 (...); -- 2023年1月订单
CREATE TABLE order_202302 (...); -- 2023年2月订单
CREATE TABLE order_202303 (...); -- 2023年3月订单
-- ... 以此类推
历史演进

实际案例:电商系统演进
# 阶段1:单库单表(初创期)
database: ecommerce
tables:
- users
- products
- orders
- payments
- logs
# 阶段2:读写分离(用户增长)
master: ecommerce_master
slaves:
- ecommerce_slave1
- ecommerce_slave2
# 阶段3:垂直分库(业务复杂化)
databases:
user_db: # 用户服务
tables: [users, user_profiles]
product_db: # 商品服务
tables: [products, categories, brands]
order_db: # 订单服务
tables: [orders, order_items]
payment_db: # 支付服务
tables: [payments, refunds]
# 阶段4:水平分表(单表数据量大)
order_db:
tables:
- orders_0 # user_id%4=0
- orders_1 # user_id%4=1
- orders_2 # user_id%4=2
- orders_3 # user_id%4=3
# 阶段5:水平分库分表(海量数据)
order_db_0: # 数据库分片0
tables: [orders_00, orders_01]
order_db_1: # 数据库分片1
tables: [orders_10, orders_11]
选择指南(超简单版)
问:业务模块太多,互相影响?
答:用【垂直分库】✅
问:表字段太多,有的常用有的不常用?
答:用【垂直分表】✅
问:单张表数据太多,查询太慢?
答:用【水平分表】✅
问:单个数据库服务器撑不住了?
答:用【水平分库】✅
问:上面问题都有?
答:先垂直再水平,一步步来!
一句话记忆口诀
垂直分库:不同业务不同库(按功能分)
垂直分表:冷热字段分开存(按频率分)
水平分表:数据太多分开放(按数据分)
水平分库:机器不够加机器(按机器分)
记住:垂直是"分类",水平是"分堆"
MySQL的分库分表和redis的分库分表
所有分库分表,无论MySQL还是Redis,终极目标就是:突破单机限制!
MySQL的"分库分表":是真的把数据库拆分成多个物理上独立的部分,每个部分都是完整的数据库实例。
Redis的"分库分表":是一个容易引起误解的说法。Redis的:
-
"分库"(SELECT 0-15)更像命名空间隔离
额外知识点:
Redis默认:1个实例 = 16个抽屉(0-15),不同抽屉的东西完全独立!就像是16个数据库。
- Redis抽屉的实现原理 = 16个完全独立的dict哈希表 + 客户端db指针切换
- 就像16个独立的HashMap,SELECT只是告诉Redis:"现在用第几个HashMap"
如果不选:所有数据都默认放在第0个抽屉(db0)
要换抽屉:用
select 数字命令切换 -
"分表"(Cluster分片)是数据分布策略
它们只是恰巧用了相似的词汇,但解决的问题、实现方式、设计理念完全不同。
简单说:
- MySQL分库分表:是"真刀真枪"的数据库拆分
- Redis分库分表:是"巧立名目"的缓存隔离
Redis简单分库分表实例
方案一:最简分库(按业务隔离)
核心思想:存数据时,程序自己来判断放到对应的redis库里(这个库可以是不同的redis服务,也可以是同一个redis服务的"抽屉"(db=0 , 1 ,2...))
import redis
# 创建不同业务的Redis连接
# 虽然物理上是一个Redis,但逻辑上用不同db号隔离
# DB 0:用户缓存
user_redis = redis.Redis(host='localhost', port=6379, db=0) # 第0个抽屉
# DB 1:商品缓存
product_redis = redis.Redis(host='localhost', port=6379, db=1) # 第1个抽屉
# DB 2:订单缓存
order_redis = redis.Redis(host='localhost', port=6379, db=2) # 第2个抽屉
# 使用示例
# 存用户数据到DB 0
user_redis.set('user:1001', '张三')
# 存商品数据到DB 1
product_redis.set('product:2001', 'iPhone15')
# 它们互不干扰
print(user_redis.get('product:2001')) # None,因为DB 0里没有这个key
print(product_redis.get('product:2001')) # b'iPhone15',在DB 1里
# 可以单独清空某个业务
# user_redis.flushdb() # 只清空用户缓存,不影响商品和订单
java实现
import redis.clients.jedis.Jedis;
public class CorrectRedisSharding {
public static void main(String[] args) {
// 先创建连接,再select数据库
Jedis userJedis = new Jedis("localhost", 6379, 2000); // timeout=2000ms
userJedis.select(0); // 选择db0
Jedis productJedis = new Jedis("localhost", 6379, 2000);
productJedis.select(1); // 选择db1
// 使用
userJedis.set("user:1001", "张三");
productJedis.set("product:5001", "iPhone");
System.out.println("用户数据: " + userJedis.get("user:1001"));
System.out.println("商品数据: " + productJedis.get("product:5001"));
userJedis.close();
productJedis.close();
}
}
方案二:最简单分表(按Key前缀+取模)
核心思想:存数据时,根据规则选择对应的Redis实例
Redis分表 = 存数据时根据规则选Redis + 取数据时用同样规则找回去
# 核心思想:存数据时,根据规则选择对应的Redis
# ↓ 规则计算
key = "user:1001" → 规则计算 → 选择 Redis实例2
↓
# 存到对应的Redis
redis_2.set("user:1001", "张三的数据")
# 取数据时,用同样的规则找回去
key = "user:1001" → 规则计算 → 还是 Redis实例2
↓
redis_2.get("user:1001") # 拿到数据!
import redis
import hashlib
# 准备3个Redis实例(可以是3台服务器或3个端口)
redis_nodes = [
redis.Redis(host='localhost', port=6379, db=0), # 分片0
redis.Redis(host='localhost', port=6380, db=0), # 分片1
redis.Redis(host='localhost', port=6381, db=0), # 分片2
]
def get_shard(key, shard_count=3):
"""计算key应该去哪个分片"""
# 简单取模算法
hash_value = hashlib.md5(key.encode()).hexdigest()
shard_index = int(hash_value, 16) % shard_count
return redis_nodes[shard_index]
# 使用示例
# 存用户数据,自动分散到不同分片
users = [
('user:1001', '张三'),
('user:1002', '李四'),
('user:1003', '王五'),
('user:1004', '赵六'),
]
for user_id, name in users:
shard = get_shard(user_id) # 自动选择分片
shard.set(user_id, name)
print(f"{user_id} 存储到分片 {redis_nodes.index(shard)}")
# 取数据时也要用同样的算法
user_id = 'user:1002'
shard = get_shard(user_id)
print(f"{user_id} 的数据是: {shard.get(user_id)}")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号