线程池
线程池
JUC线程池: FutureTask详解 | Java 全栈知识体系
JUC线程池: ThreadPoolExecutor详解 | Java 全栈知识体系
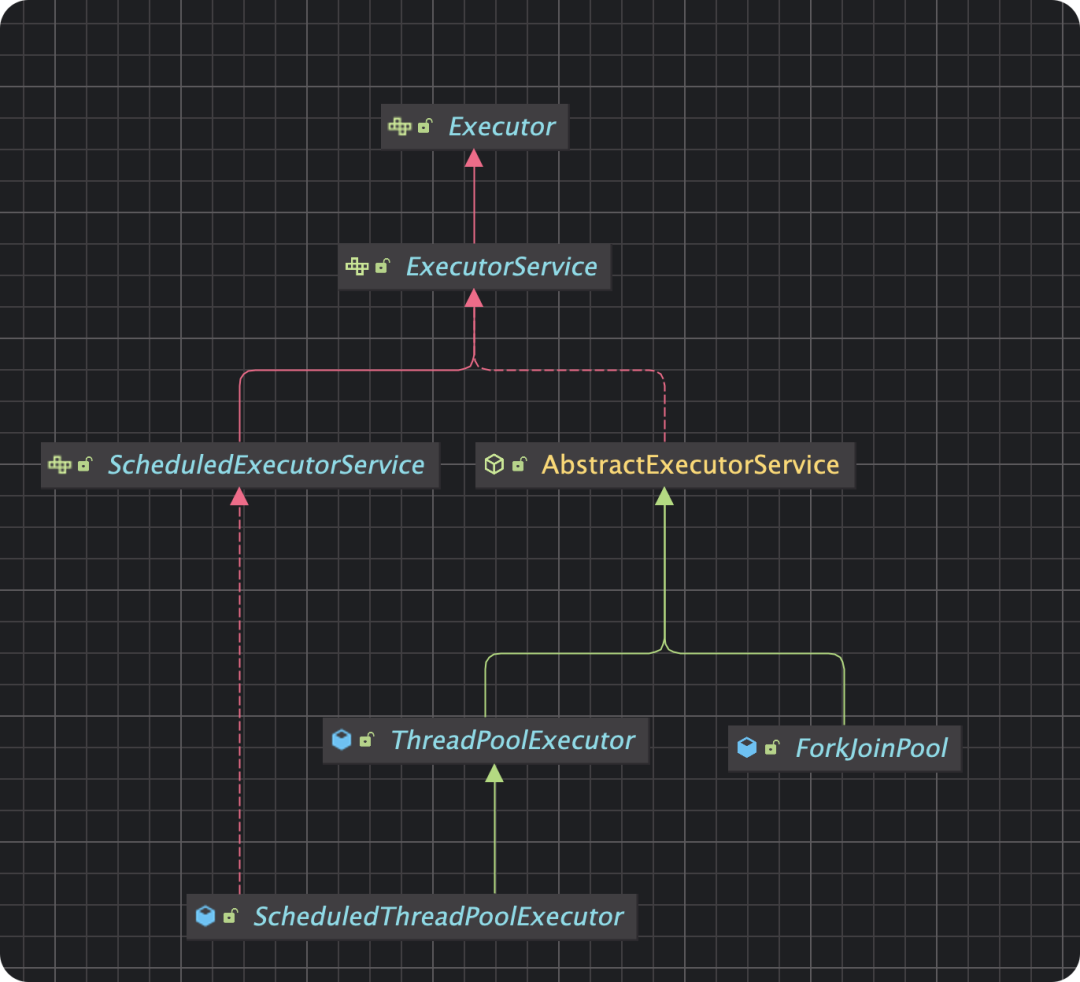
Executor (接口)
│
├── ExecutorService (接口)
│ │
│ ├── ThreadPoolExecutor (标准实现)
│ │ ├── ScheduledThreadPoolExecutor (定时任务扩展)
│ │
│ └── ForkJoinPool (分治任务专用)
│
└── Executors (工具类)
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
}
核心参数
- corePoolSize (核心线程数)
- 线程池中始终保持存活的线程数量
- 即使这些线程处于空闲状态也不会被回收
- 默认情况下,核心线程在初始时是懒加载的(可通过
prestartAllCoreThreads提前启动)
- maximumPoolSize (最大线程数)
- 线程池允许创建的最大线程数量
- 当工作队列满时,线程池会创建新线程直到达到此最大值
- keepAliveTime (线程空闲时间)
- 非核心线程的空闲存活时间
- 当线程空闲时间超过此值且当前线程数大于corePoolSize时,多余线程会被回收
- 单位通常为TimeUnit.SECONDS/MILLISECONDS等
- unit (时间单位)
- keepAliveTime的时间单位
- 如TimeUnit.SECONDS、TimeUnit.MILLISECONDS等
- workQueue (工作队列)
- 用于保存等待执行的任务的阻塞队列
- 常见实现:
ArrayBlockingQueue:有界队列LinkedBlockingQueue:无界队列(默认Integer.MAX_VALUE)SynchronousQueue:不存储元素的队列PriorityBlockingQueue:带优先级的队列
- threadFactory (线程工厂)
- 用于创建新线程的工厂
- 可以自定义线程名称、优先级、守护状态等
- 默认使用
Executors.defaultThreadFactory()
- handler (拒绝策略)
- 当线程池和工作队列都饱和时的处理策略
- 内置策略:
AbortPolicy(默认):抛出RejectedExecutionExceptionCallerRunsPolicy:由调用者线程执行该任务DiscardPolicy:直接丢弃任务DiscardOldestPolicy:丢弃队列中最老的任务并重试
线程池工作流程
- 提交任务时,如果当前线程数 < corePoolSize,创建新线程执行任务
- 如果线程数 ≥ corePoolSize,将任务放入workQueue
- 如果队列已满且线程数 < maximumPoolSize,创建新线程执行任务
- 如果队列已满且线程数 = maximumPoolSize,执行拒绝策略
补充:execute执行时,数量不满足核心线程时,就去addWorker了。所以有任务来时,不管有无空闲核心线程,只要核心线程数量不足,就会创建新的核心线程。
- 当提交一个新任务时,线程池首先检查当前线程数量是否小于 corePoolSize。
- 如果是,不管有没有空闲线程,都会调用 addWorker 创建一个新的核心线程来执行任务。
- 这是线程池初始化阶段常见的行为,用于快速启动足够的核心线程。
- 一旦线程数达到 corePoolSize:
- 新任务会被放入任务队列中等待空闲线程。
- 此时不会创建新线程,而是复用已有核心线程。
📌 总结:
在线程池初始阶段,即使有空闲线程,只要线程数未达到 corePoolSize,新任务仍然会触发创建新的核心线程,直到达到 corePoolSize 为止。源代码证明:
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); int c = ctl.get(); // 如果当前运行线程数小于核心线程数,尝试创建新线程执行任务。 if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true)) return; c = ctl.get(); } // 如果任务队列未满且任务入队成功,则再次检查线程池状态,必要时回滚或创建新线程。 if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false); } // 如果入队失败,则尝试创建非核心线程执行任务,失败则拒绝任务。 else if (!addWorker(command, false)) reject(command); }
线程池提交任务
执行无返回值任务:
execute()是Executor接口的核心方法,在ThreadPoolExecutor中的实现如下:
executor.execute(() -> {
// 执行的任务代码
System.out.println("Task running in " + Thread.currentThread().getName());
});
提交有返回值任务:
submit()是ExecutorService接口的方法,在AbstractExecutorService中的实现
Future<String> future = executor.submit(() -> {
// 执行的任务代码
return "Task result";
});
// 获取结果(会阻塞)
try {
String result = future.get(5, TimeUnit.SECONDS);
System.out.println("Result: " + result);
} catch (TimeoutException e) {
System.err.println("Task timed out");
} catch (Exception e) {
e.printStackTrace();
}
执行流程对比
execute()流程:
调用execute()
→ 尝试创建线程或加入队列
→ 线程执行Runnable.run()
→ 异常直接抛出
submit()流程:
调用submit()
→ 包装为FutureTask
→ 调用execute(FutureTask)
→ FutureTask.run()执行
→ 捕获异常/保存结果
→ 返回Future对象
→ Future.get()可获取结果或异常
这种实现方式使得submit()能够提供更丰富的功能,包括结果返回和异常捕获,而execute()则提供了更轻量级的任务提交方式。
ScheduledThreadPool (定时任务线程池):
ScheduledThreadPoolExecutor特有的方法
// 延迟执行一次
schedule(Runnable command, long delay, TimeUnit unit)
schedule(Callable<V> callable, long delay, TimeUnit unit)
// 固定频率执行:按照指定的时间间隔(period)执行,不考虑任务实际执行时间
scheduleAtFixedRate()
// 固定延迟执行:保证任务执行完成后再等待指定延迟时间
scheduleWithFixedDelay()
重写的submit方法:在ScheduledThreadPoolExecutor中,submit()实际上是立即执行的任务(相当于延迟为0的调度任务)
// ScheduledThreadPoolExecutor中的实现
public Future<?> submit(Runnable task) {
return schedule(task, 0, NANOSECONDS);
}
public <T> Future<T> submit(Callable<T> task) {
return schedule(task, 0, NANOSECONDS);
}
任务包装方式
普通线程池:
- 将任务包装为
FutureTask
ScheduledThreadPool:
- 将任务包装为
ScheduledFutureTask(FutureTask的子类)
ScheduledFutureTask增加了:
- 任务序列号(用于相同时间任务的排序)
- 下次执行时间
- 执行周期
实现细节对比
普通线程池的submit():
// ThreadPoolExecutor使用AbstractExecutorService的实现
public Future<?> submit(Runnable task) {
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
ScheduledThreadPool的submit():
// ScheduledThreadPoolExecutor的实现
public Future<?> submit(Runnable task) {
return schedule(task, 0, NANOSECONDS);
}
public ScheduledFuture<?> schedule(Runnable command,
long delay,
TimeUnit unit) {
// 包装为ScheduledFutureTask
RunnableScheduledFuture<?> t = decorateTask(command,
new ScheduledFutureTask<Void>(command, null,
triggerTime(delay, unit)));
// 延迟执行
delayedExecute(t);
return t;
}
使用建议
- 如果需要立即执行的任务:
- 两者
submit()行为相同 - 但ScheduledThreadPool的开销稍大
- 两者
- 如果需要定时/延迟任务:
- 只能使用ScheduledThreadPool
- 使用
schedule()系列方法
- 如果只有普通任务:
- 使用普通线程池效率更高
- ScheduledThreadPool的队列管理更复杂
性能考虑
- ScheduledThreadPool的
DelayedWorkQueue操作时间复杂度为O(log n) - 普通线程池的
LinkedBlockingQueue操作通常是O(1) - 对于大量即时任务,普通线程池性能更好
总结:ScheduledThreadPoolExecutor的submit()方法虽然接口与普通线程池相同,但底层实现是针对定时任务优化的,在不需要定时功能时,使用普通线程池更为高效。
执行细节说明
JUC线程池: FutureTask详解 | Java 全栈知识体系
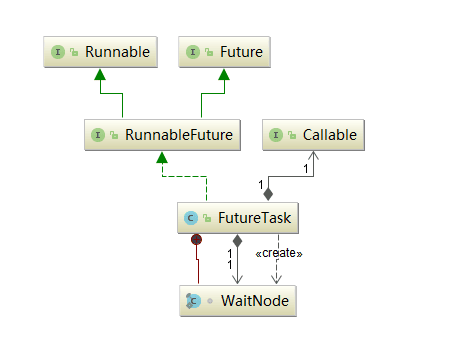
可以看到,FutureTask实现了RunnableFuture接口,则RunnableFuture接口继承了Runnable接口和Future接口,所以FutureTask既能当做一个Runnable直接被Thread执行,也能作为Future用来得到Callable的计算结果。
// 执行execute时,传入Runnable
public interface Executor {
void execute(Runnable command);
}
// FutureTask既能当做一个Runnable直接被执行,也能作为Future用来得到计算结果
// 执行submit时,传入Runnable,但是里面会创建FutureTas,然后再执行execute,并且返回RunnableFuture
public abstract class AbstractExecutorService implements ExecutorService {
// 创建FutureTas时,会给组合的Callable赋值
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW; // ensure visibility of callable
}
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
}
// 个人总结:
// execute执行Runnable,不会有返回值
// submit执行的是封装的FutureTask(本质还是Runnable,里面有Callable,里面有返回值outcome),执行FutureTask的run方法时,执行里面的Callable的run方法,然后把其执行结果的返回值,赋值给自己的结果outcome。使用future.get时就可以获取执行结果了
// callable的run方法
public void run() {
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
set(result);
}
} finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}
// 个人总结: callable会实现call方法,返回值result,会设置到结果里,get就能获取了
线程池的常见类型
Java中常见的线程池类型主要包括以下几种:
-
FixedThreadPool(固定大小线程池)
- 线程数量固定,即使有空闲线程,也不会被回收。
- 适用于负载较重的服务器,能够控制并发线程的数量。避免过多线程导致资源耗尽。
-
CachedThreadPool(缓存线程池)
- 线程数量不固定,根据需要动态创建线程,空闲线程会被回收。
- 适用于执行大量短期异步任务的情况。能够根据需要动态调整线程数量,减少线程创建和销毁的开销。
-
ScheduledThreadPool(定时任务线程池)
- 支持定时及周期性任务执行。
- 适用于需要按照特定时间间隔执行任务的场景。如定时清理缓存、定时发送邮件等。
-
SingleThreadExecutor(单线程线程池)
- 只有一个线程,所有任务按顺序执行。
- 适用于需要保证任务顺序执行的场景。如数据库操作、文件读写等。
-
ForkJoinPool(工作窃取线程池)
- 用于执行Fork/Join框架的任务,适用于分割任务并行执行的场景。
这几种线程池为什么要采取不一样的队列?比如 newFixedThreadPool 为什么采取LinkedBlockingQueue ,而 newCachedThreadPool 又为什么采取SynchronousQueue ?
因为 newFixedThreadPool 线程数量有限,他又不想丢失任务,只能采取无界队列,而newCachedThreadPool 的话本身自带int最大值个线程数,所以没必要用无界队列,他的宗旨就是我有线程能处理,不需要队列。
Java通过Executors工具类提供了几种常用的线程池创建方式,每种类型针对不同的使用场景进行了优化。以下是主要的线程池类型及其特点:
1. FixedThreadPool (固定大小线程池)
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(int nThreads);
特点:
- 固定数量的线程(核心线程数=最大线程数)
- 使用无界队列(
LinkedBlockingQueue) - 空闲线程不会被回收
- 适合负载较重的服务器场景
注意事项:
- 任务堆积可能导致OOM(OutOfMemoryError)
- 适用于已知并发量且需要限制资源的场景
2. CachedThreadPool (缓存线程池)
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
特点:
- 线程数几乎无限制(最大为Integer.MAX_VALUE)
- 使用
SynchronousQueue(不存储元素的队列) - 空闲线程60秒后会被回收
- 适合大量短生命周期的异步任务
注意事项:
- 可能创建过多线程导致系统资源耗尽
- 适用于执行很多短期异步任务的环境
3. SingleThreadExecutor (单线程线程池)
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
特点:
- 只有一个工作线程
- 使用无界队列
- 保证任务按提交顺序执行
- 适合需要顺序执行任务的场景
注意事项:
- 任务堆积可能导致OOM
- 适用于需要保证任务顺序性的场景
4. ScheduledThreadPool (定时任务线程池)
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(int corePoolSize);
特点:
- 专门用于定时/周期性任务
- 使用
DelayedWorkQueue延迟队列 - 可以设置初始延迟和间隔时间
常用方法:
-
schedule():延迟执行一次 -
scheduleAtFixedRate():固定频率执行 -
scheduleWithFixedDelay():固定延迟执行 -
关键区别对比表
特性 scheduleAtFixedRate scheduleWithFixedDelay 触发时机 固定频率:按照指定的时间间隔(period)执行,不考虑任务实际执行时间 固定延迟:保证任务执行完成后再等待指定延迟时间 时间计算基准 上一次开始时间 + period 上一次结束时间 + delay 任务超时影响 会追赶执行(可能并发) 会顺延(保证间隔) 适用场景 需要严格周期性的任务 需要保证执行间隔的任务 任务重叠 可能发生任务重叠执行 不会重叠 系统负载影响 高负载时可能导致任务堆积 高负载时会自动延长周期 -
scheduleAtFixedRate在任务超时且线程不足时的处理机制- 当任务执行时间超过period且线程不足时,不会创建新线程(即使线程池未达最大线程数)
- 后续任务会被放入延迟队列(DelayedWorkQueue)等待
- 当前任务完成后,线程会从队列中取出最近到期的任务执行
- 如果长期存在线程不足,队列会不断积压,最终可能导致OOM(使用无界队列时)
5. WorkStealingPool (工作窃取线程池)
ExecutorService workStealingPool = Executors.newWorkStealingPool();
// 或指定并行度
ExecutorService workStealingPool = Executors.newWorkStealingPool(int parallelism);
特点:
- Java 8+引入
- 基于ForkJoinPool实现
- 使用工作窃取(work-stealing)算法提高并行度
- 默认并行度为CPU核心数
适用场景:
- 适合处理大量可以分解的任务
- 特别适合递归任务(如分治算法)
6. ForkJoinPool (分治线程池)
ForkJoinPool forkJoinPool = new ForkJoinPool();
// 或指定并行度
ForkJoinPool forkJoinPool = new ForkJoinPool(int parallelism);
特点:
- 专为分治算法设计
- 每个线程有自己的工作队列
- 使用工作窃取算法平衡负载
- 适合递归分解的任务
不推荐使用Executors创建线程池的原因
虽然Executors使用方便,但在生产环境中不推荐直接使用,因为:
FixedThreadPool和SingleThreadExecutor使用无界队列,可能导致OOMCachedThreadPool允许创建过多线程,可能导致系统资源耗尽
推荐做法:
// 手动创建ThreadPoolExecutor,明确所有参数
ThreadPoolExecutor executor = new ThreadPoolExecutor(
corePoolSize,
maximumPoolSize,
keepAliveTime,
unit,
workQueue,
threadFactory,
handler
);
线程池选择指南
| 线程池类型 | 适用场景 | 风险点 |
|---|---|---|
| FixedThreadPool | 已知并发量,需要限制资源 | 无界队列可能OOM |
| CachedThreadPool | 大量短生命周期异步任务 | 可能创建过多线程 |
| SingleThreadExecutor | 需要顺序执行任务 | 无界队列可能OOM |
| ScheduledThreadPool | 定时/周期性任务 | - |
| WorkStealingPool | 可分解的并行任务 | Java 8+ |
| ForkJoinPool | 递归/分治任务 | 需要特定任务类型 |
在实际开发中,应根据具体业务场景选择合适的线程池类型,并仔细配置各项参数。
线程池配置最佳实践建议
- 根据任务类型选择合适队列:
- CPU密集型:较小队列 + 较大线程池
- IO密集型:较大队列 + 较小线程池
- 合理设置核心参数:
- CPU核心数:Runtime.getRuntime().availableProcessors()
- 计算公式参考:
- CPU密集型:主要消耗CPU计算资源的任务,大部分时间都在进行计算、逻辑处理等CPU操作
- 建议corePoolSize = CPU核心数 + 1(避免过多线程导致频繁上下文切换)
- 使用有界队列(防止内存溢出)
- 较小的队列容量(因为任务应该尽快被线程执行)
- IO密集型:主要时间花费在等待IO操作上的任务,CPU计算时间相对较少,经常需要等待
- 建议corePoolSize = CPU核心数 * 2 ,【当然也有个很牛X的计算公式:线程数=CPU核数 *(1+平均等待时间/平均工作时间)】
- 可以使用较大的队列(因为线程经常被阻塞)
- 考虑使用SynchronousQueue(避免任务堆积)
- CPU密集型:主要消耗CPU计算资源的任务,大部分时间都在进行计算、逻辑处理等CPU操作
- 生产环境建议直接使用ThreadPoolExecutor构造方法,而非Executors工具类,以避免资源耗尽风险。
CPU密集型和IO密集型任务详解
CPU密集型任务 (CPU-bound)
定义:
- 主要消耗CPU计算资源的任务
- 大部分时间都在进行计算、逻辑处理等CPU操作
特点:
- 执行速度取决于CPU的计算能力
- 很少或几乎没有IO等待(如磁盘/网络操作)
- 线程通常保持运行状态,不会主动让出CPU
典型例子:
- 复杂的数学计算(如素数计算、矩阵运算)
- 视频编码/解码
- 3D图形渲染
- 数据压缩/解压
- 机器学习模型训练
线程池配置建议:
- 线程数 ≈ CPU核心数 + 1(避免过多线程导致频繁上下文切换)
- CPU核心数确保所有CPU核心满载(100%利用率)
- +1:作为补偿线程(Coverage Thread),用于处理以下情况:
- 线程因页错误(Page Fault)等短暂阻塞
- 操作系统后台任务占用少量CPU
- 超线程(Hyper-Threading)的物理核心争用
- 为什么不是更多线程?:
- 上下文切换开销
- 缓存局部性破坏:频繁切换线程会导致CPU缓存(L1/L2/L3)失效
- 内存占用:每个Java线程默认占用 1MB栈内存(可通过
-Xss调整)
- 使用有界队列(防止内存溢出)
- 较小的队列容量(因为任务应该尽快被线程执行)
// CPU密集型配置示例
int corePoolSize = Runtime.getRuntime().availableProcessors() + 1;
ThreadPoolExecutor cpuIntensivePool = new ThreadPoolExecutor(
corePoolSize,
corePoolSize, // 最大线程数=核心线程数
0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(100) // 中等大小队列
);
IO密集型任务 (IO-bound)
定义:
- 主要时间花费在等待IO操作上的任务
- CPU计算时间相对较少
特点:
- 经常需要等待(如数据库查询、网络请求、文件读写)
- 线程经常处于阻塞状态(不占用CPU)
- 可以通过增加并发数来提高吞吐量
典型例子:
- 网络请求处理(如HTTP API调用)
- 数据库操作
- 文件读写
- 远程服务调用
- Web页面渲染(等待模板和数据)
线程池配置建议:
- 线程数 ≈ CPU核心数 * (1 + 平均等待时间/平均计算时间)
- 更多的线程弥补线程阻塞导致的资源闲置
- 现代操作系统通过线程切换实现并发:
- 当线程A阻塞时,CPU立即切换到可运行的线程B
- 更多线程 ⇒ 更高概率存在可运行线程
- 并发吞吐量提升。示例:处理HTTP请求
- 单线程:每秒处理 1000ms/(10ms+500ms) ≈ 1.96个请求
- 100线程:理论可达 196个请求/秒(理想情况)
- 实践中常用:CPU核心数 * 2 到 CPU核心数 * 5
- 可以使用较大的队列(因为线程经常被阻塞)
- 考虑使用SynchronousQueue(避免任务堆积)
// IO密集型配置示例
int corePoolSize = Runtime.getRuntime().availableProcessors() * 2;
ThreadPoolExecutor ioIntensivePool = new ThreadPoolExecutor(
corePoolSize,
corePoolSize * 2, // 更大的最大线程数
60L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(500) // 较大队列
);
混合型任务
实际应用中,很多任务既包含CPU计算也包含IO操作:
配置策略:
- 拆分为CPU和IO两部分,分别使用不同线程池
- 按主导类型配置:
- 如果CPU计算占主导:偏向CPU密集型配置
- 如果IO等待占主导:偏向IO密集型配置
监控与调优
-
使用工具监控:
- CPU使用率
- 线程状态(运行/阻塞比例)
- 队列堆积情况
-
动态调整:
executor.setCorePoolSize(newSize); executor.setMaximumPoolSize(newSize);
理解任务类型差异可以帮助您构建更高效的并发系统,避免资源浪费或性能瓶颈。
附加-线程池有哪些提交任务的方式
| 方法 | 返回值 | 特点 | 适用场景 |
|---|---|---|---|
execute() |
void | 异步执行,无返回值 | 简单的后台任务 |
submit() |
Future | 可获取执行结果 | 需要获取结果或处理异常 |
invokeAll() |
List |
批量提交,等待所有完成 | 并行处理多个任务并收集结果 |
invokeAny() |
任意类型 | 返回最先完成的结果 | 多个方式获取同一资源(如冗余服务) |
schedule() |
ScheduledFuture | 延迟执行 | 定时任务 |
scheduleAtFixedRate() |
ScheduledFuture | 固定频率执行 | 周期性任务(不关心执行时间) |
scheduleWithFixedDelay() |
ScheduledFuture | 固定延迟执行 | 周期性任务(需要等待上次完成) |
附加-线程池策略完全总结
线程池基础策略对比
两种核心基础线程池策略对比
策略1:队列缓冲(有界队列)
// 固定大小线程池的策略:队列缓冲
ThreadPoolExecutor fixed = new ThreadPoolExecutor(
10, 100, 60, SECONDS,
new LinkedBlockingQueue<>(100) // 有界队列:缓冲任务
);
// 流量控制逻辑:
// 1. 核心线程10个先处理
// 2. 任务积累到队列里(最多100个)
// 3. 队列满了才创建新线程(最大到100)
// 4. 线程和队列都满了 → 执行拒绝策略
策略2:立即扩容(无队列)
// 缓存线程池的策略:立即扩容
ThreadPoolExecutor cached = new ThreadPoolExecutor(
0, Integer.MAX_VALUE, 60, SECONDS,
new SynchronousQueue<>() // 无缓冲队列
);
// 流量控制逻辑:
// 1. 来一个任务,没有空闲线程就立即创建新线程
// 2. 不缓冲任务,直接交给线程执行
// 3. 线程数无上限(理论上)
设计哲学不同:
// 固定线程池的设计目标:稳定性优先
// - 控制资源使用
// - 平滑流量峰值
// - 可预测的性能
// 缓存线程池的设计目标:吞吐量优先
// - 最大限度并行
// - 零延迟执行
// - 适合短期突发任务
两种特殊线程池策略
1. 定时策略(ScheduledThreadPoolExecutor专用)
- 队列:DelayedWorkQueue(内部实现)
- 特点:任务按执行时间排序
- 用于:定时任务、周期任务
2. 工作窃取策略(ForkJoinPool专用)
- 原理:每个线程有自己的队列,空闲线程偷其他线程的任务
- 特点:自动负载均衡
- 用于:递归分解的任务(如并行计算)
线程池的完整策略维度
线程池策略 = 队列策略 × 扩容策略 × 拒绝策略
队列策略对比
| 队列类型 | 容量 | 特点 | 适用策略 | 线程池示例 |
|---|---|---|---|---|
| SynchronousQueue | 0 | 直接传递,不存储 | 立即扩容 | CachedThreadPool |
| 无界LinkedBlockingQueue | Integer.MAX_VALUE | 无限缓冲,可能OOM | 队列缓冲 | FixedThreadPool |
| 有界LinkedBlockingQueue | 自定义(如100) | 有限缓冲,安全 | 队列缓冲 | 生产环境推荐 |
| PriorityBlockingQueue | 无界/有界 | 按优先级出队 | 优先级处理 | 自定义优先级池 |
| ArrayBlockingQueue | 固定 | 数组实现,FIFO严格 | 队列缓冲 | 需要严格顺序 |
| DelayedWorkQueue | 无容量限制 | 延迟队列 | 定时任务线程池专用 | ScheduledThreadPoolExecutor |
| LinkedTransferQueue | 无界 | 转移队列 | 生产-消费者优化 |
特性 ArrayBlockingQueue LinkedBlockingQueue SynchronousQueue PriorityBlockingQueue 数据结构 数组 链表 无 堆数组 容量 固定有界 可选有界 0 无界 锁机制 单锁 双锁分离 CAS/Transferer 单锁 排序 FIFO FIFO 可选公平/非公平 优先级 内存 预分配 动态分配 无 动态分配 吞吐量 中等 高 高(直接传递) 中等
扩容策略对比
| 扩容策略 | 核心线程 | 最大线程 | 触发条件 | 适用场景 |
|---|---|---|---|---|
| 立即扩容 | 0 | Integer.MAX_VALUE | 有任务立即创建 | 突发短期任务 |
| 队列缓冲后扩容 | N(如10) | M(如50) | 队列满了才扩容 | 稳定持续负载 |
| 固定不扩容 | N | N(核心=最大) | 永不扩容 | 资源严格限制 |
| 预热扩容 | N | M | 启动时提前创建(executor.prestartAllCoreThreads()) |
避免首次延迟 |
| 动态扩容 | 运行时调整参数executor.setCorePoolSize(20) |
拒绝策略对比
| 拒绝策略 | 行为 | 优点 | 缺点 | 推荐场景 |
|---|---|---|---|---|
| AbortPolicy(默认) | 抛出RejectedExecutionException | 快速失败,易于发现 | 用户体验差 | 测试环境 |
| CallerRunsPolicy | 由调用线程执行任务 | 简单降级,永不丢弃 | 可能阻塞调用线程 | 生产推荐 |
| DiscardPolicy | 静默丢弃新任务 | 不抛异常 | 任务丢失无感知 | 可丢失场景 |
| DiscardOldestPolicy | 丢弃队列头任务,执行新任务 | 尝试执行最新任务 | 可能丢弃重要任务 | 实时性要求高 |
总结
实战选择指南(按场景选)
| 应用场景 | 推荐线程池类型 | 队列类型 | 核心/最大线程 | 拒绝策略 | 关键配置 |
|---|---|---|---|---|---|
| Web服务器 | FixedThreadPool变体 | 有界LinkedBlockingQueue | 50/200 | CallerRunsPolicy | 队列大小1000 |
| 批量文件处理 | CachedThreadPool | SynchronousQueue | 0/MAX | CallerRunsPolicy | 空闲60秒回收 |
| 定时任务调度 | ScheduledThreadPool | DelayedWorkQueue | 固定大小 | AbortPolicy | 根据任务数定大小 |
| 并行计算 | ForkJoinPool | 工作窃取队列 | 并行度=CPU核数 | 默认 | 无队列概念 |
| 消息队列消费 | FixedThreadPool | 有界LinkedBlockingQueue | 消费者数量 | DiscardPolicy | 队列大小适量 |
| 数据库批量操作 | 自定义分批池 | 有界队列+分批逻辑 | 10/20 | CallerRunsPolicy | 批大小100,超时50ms |
线程池就三件事:
1. 任务来了放哪? → 四种队列选一个
2. 线程不够怎么办?→ 三种扩容选一个
3. 队列满了怎么办?→ 四种拒绝选一个
两个特殊:
1. 定时任务 → 用 ScheduledThreadPoolExecutor
2. 分治计算 → 用 ForkJoinPool
最常用的就这两个,生产中95%的用例:
// 场景1:处理Web请求(稳定负载)
ThreadPoolExecutor executor1 = new ThreadPoolExecutor(
50, 200, 60L, SECONDS,
new LinkedBlockingQueue<>(1000),
new ThreadPoolExecutor.CallerRunsPolicy()
);
// 场景2:处理批量任务(突发负载)
ExecutorService executor2 = Executors.newCachedThreadPool();
// 用完记得 shutdown()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号