top命令输出结果详解
其他相关
JVM调优实战 - deyang - 博客园
命令Linux\MySQL\Java - deyang - 博客园
top命令输出:
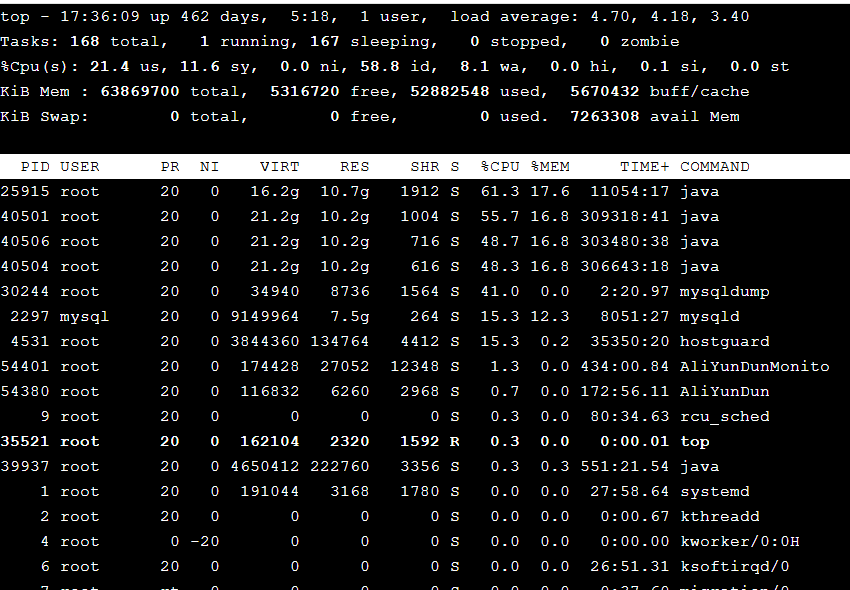
显示界面说明
top 界面分为两部分:系统概览区域和进程列表区域。
1. 系统概览区域
第一行:系统运行时间和负载
top - 15:30:45 up 10 days, 3:22, 2 users, load average: 0.15, 0.10, 0.05
15:30:45:当前时间up 10 days, 3:22:系统已运行时间2 users:当前登录用户数load average:系统1分钟、5分钟、15分钟的平均负载 【系统负载(Load Average):单位时间内处于可运行/不可中断状态的进程平均数】,对于单核CPU,1.00表示满负荷。对于多核CPU(例如8核),负载达到8.00才表示满负荷。数值低于1.00通常表示系统很空闲。
第二行:任务统计
Tasks: 120 total, 2 running, 118 sleeping, 0 stopped, 0 zombie
- 总进程数、运行中、休眠中、已停止和僵尸进程数量
第三行:CPU 使用情况
%Cpu(s): 5.3 us, 1.2 sy, 0.0 ni, 93.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
us:用户空间占用CPU百分比sy:内核空间占用CPU百分比ni:用户进程空间内改变过优先级的进程占用CPU百分比id:空闲CPU百分比wa:等待IO的CPU时间百分比hi:硬件中断占用百分比si:软件中断占用百分比st:虚拟机偷取时间百分比
第四、五行:内存使用
MiB Mem : 7856.8 total, 1024.2 free, 4096.0 used, 2736.6 buff/cache
MiB Swap: 2048.0 total, 2048.0 free, 0.0 used. 3248.8 avail Mem
-
物理内存和交换分区的总量、空闲量、使用量和缓存
-
进一步验证了核心公式:
total = used + free + buff/cache63869700 (total) = 5316720 (free) + 52882548 (used) + 5670432 (buff/cache)
2. 进程列表区域
默认显示的列:
PID:进程IDUSER:进程所有者PR:进程优先级NI:nice值(负值表示高优先级,正值表示低优先级)VIRT:进程使用的虚拟内存总量(KB)RES:进程使用的、未被换出的物理内存大小(KB)SHR:共享内存大小(KB)S:进程状态(D=不可中断,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸)%CPU:上次更新到现在的CPU时间占用百分比%MEM:进程使用的物理内存百分比TIME+:进程使用的CPU时间总计(1/100秒)COMMAND:命令名/命令行
常用交互命令
在 top 运行时可以输入以下命令:
排序控制
P:按CPU使用率排序(默认)M:按内存使用率排序T:按时间/累计时间排序N:按PID排序R:反向排序
显示控制
l:切换显示平均负载和启动时间t:切换显示进程和CPU状态信息m:切换显示内存信息1:展开显示各CPU核心的统计数据
进程控制
k:终止进程(输入PID)r:重新设置进程的nice值
刷新控制
d或s:改变刷新间隔(秒)Space:立即刷新显示q:退出top
命令行选项
top -d 5 # 设置刷新间隔为5秒
top -p 1234 # 仅监视PID为1234的进程
top -u username # 仅监视指定用户的进程
top -n 2 # 刷新2次后退出
top -b # 批处理模式,输出到文件
top -H # 显示线程而不是进程
top -c # 显示完整命令路径
实用技巧
- 查找高CPU进程:运行
top后按P键 - 查找高内存进程:运行
top后按M键 - 监控特定用户:
top -u username - 保存top输出:
top -b -n 1 > top.log - 显示完整命令:运行
top后按c键 - 显示线程:运行
top后按H键
top 是系统管理员和开发人员诊断性能问题的重要工具,熟练掌握它可以快速定位系统资源瓶颈。
系统级 CPU 使用率和进程级 CPU 使用率
在 top 命令中,第三行的 CPU 使用情况(%Cpu(s)) 和 进程列表区域的 %CPU 有密切关联,但代表的含义不同:
1. 第三行的 %Cpu(s)(系统级 CPU 使用率)
这一行显示的是 整个系统 的 CPU 使用情况,按不同的 CPU 时间类型 划分:
%Cpu(s): 5.3 us, 1.2 sy, 0.0 ni, 93.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
us(user):用户空间进程占用的 CPU 百分比(普通应用程序)。sy(system):内核空间占用的 CPU 百分比(系统调用、中断等)。ni(nice):低优先级(nice调整过)的用户进程占用的 CPU。id(idle):CPU 空闲百分比。wa(iowait):CPU 等待 I/O 操作的百分比(磁盘、网络等阻塞)。hi(hardware interrupt):硬件中断占用的 CPU。si(software interrupt):软件中断占用的 CPU。st(steal time):虚拟机被 Hypervisor 偷走的 CPU 时间(仅虚拟化环境)。
这些值的总和是 100%,表示整个 CPU 的使用情况。
2. 进程列表的 %CPU(进程级 CPU 使用率)
在进程列表中,%CPU 表示 单个进程占用的 CPU 百分比:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1234 root 20 0 500000 20000 5000 R 25.0 1.2 0:10.25 python3
%CPU:该进程 占用 CPU 的时间比例,计算方式:- 单核 CPU:如果某个进程占满 1 个核心,
%CPU会显示100%。 - 多核 CPU:如果某个进程占满 1 个核心(如 4 核 CPU),
%CPU可能显示100%(表示占用了 1 个核心的 100%),但 总和可以超过 100%(如 400% 表示占满 4 个核心)。
- 单核 CPU:如果某个进程占满 1 个核心,
3. 两者的关系
| 对比项 | 第三行 %Cpu(s) |
进程 %CPU |
|---|---|---|
| 范围 | 整个系统的 CPU 使用情况 | 单个进程的 CPU 占用 |
| 计算方式 | 所有 CPU 核心的汇总(总和 100%) | 单个进程占用的 CPU 时间比例(可以超过 100%) |
| 示例 | us=30%(所有用户进程占 30%) |
python3 %CPU=50%(该进程占 50% CPU 时间) |
关键区别
- 第三行
%Cpu(s)是 全局视角,告诉你 CPU 被哪些类型的任务占用(用户、内核、I/O 等)。 - 进程
%CPU是 单个进程视角,告诉你某个进程具体占用了多少 CPU 资源。
如何结合使用?
- 如果
us(用户空间 CPU)很高 → 查看哪些进程%CPU高(按P排序)。 - 如果
sy(系统 CPU)很高 → 可能是内核任务或频繁系统调用(如kworker进程)。 - 如果
wa(I/O 等待)很高 → 检查磁盘或网络 I/O 瓶颈(iotop辅助分析)。
总结
%Cpu(s)= 整个系统的 CPU 使用分布(按任务类型划分)。%CPU= 单个进程的 CPU 占用率(可以超过 100%,在多核系统上)。- 两者结合 可以更精准地分析 CPU 瓶颈来源。
如果你发现系统 CPU 使用率高(如 us=80%),可以按 P 排序进程,找出 %CPU 最高的进程进行优化。
CPU 使用总和"安全范围"
在 Linux 系统中,%Cpu(s) 的整体使用情况没有一个绝对的"安全范围",因为不同应用场景对 CPU 的负载容忍度不同。但我们可以根据经验给出一般性建议:
1. 通用参考标准(非生产环境)
| CPU 使用分类 | 建议关注阈值 | 可能的影响 |
|---|---|---|
us(用户进程) |
< 70% | 正常应用运算,过高可能导致响应变慢 |
sy(系统进程) |
< 20% | 过高可能预示内核瓶颈(如频繁系统调用) |
wa(I/O 等待) |
< 5% | 过高说明磁盘/网络是瓶颈(检查 iostat) |
id(空闲) |
> 20% | 剩余 CPU 资源缓冲,低于此值可能压力大 |
总和参考:
- 短期峰值:允许 100%(如突发计算任务)。
- 长期负载:建议平均 ≤ 70%~80%(留出余量应对突发请求)。
2. 生产环境关键建议
(1) 不同类型服务的关注点
- CPU 密集型服务(如科学计算、AI训练):
- 允许
us长期较高(如 80%~90%),但需监控是否影响其他服务。
- 允许
- I/O 密集型服务(如数据库、Web服务器):
- 重点监控
wa(应 < 10%),高wa可能需优化磁盘或网络。
- 重点监控
- 低延迟敏感服务(如金融交易):
- 控制
us+sy< 60%,避免调度延迟。
- 控制
(2) 多核 CPU 的注意事项
- 如果系统有 N 个逻辑核心:
- 单个进程的
%CPU可能达到100% × N(如 8 核 CPU 上 800%)。 - 全局
%Cpu(s)仍以 100% 为基准(所有核心的均值)。
- 单个进程的
3. 异常情况判断
以下情况需要警惕:
us长期 > 90%
→ 应用层可能需优化代码或扩容。sy长期 > 30%
→ 检查内核态开销(如系统调用频繁、上下文切换cs过高)。wa> 10%
→ 使用iostat -x 1查看磁盘利用率(%util)。id< 10% 且负载高
→ 系统已过载,需扩容或优化。
4. 如何动态监控?
- 结合
load average(平均负载):- 如果 1 分钟负载 > CPU 核心数,且
id低,说明 CPU 饱和。 - 示例:4 核 CPU 负载 > 4 需关注。
- 如果 1 分钟负载 > CPU 核心数,且
- 使用
vmstat 1:- 查看
r(运行队列长度)和cs(上下文切换次数)。
- 查看
- 长期趋势分析:
- 通过
sar -u记录历史数据,观察峰值规律。
- 通过
总结
- 安全范围:长期平均
us+sy≤ 70%~80%,id≥ 20%。 - 核心原则:
- 留出余量应对突发流量。
- 关注
wa和sy的异常增长。 - 结合负载和核心数综合判断。
如果系统长期接近 100%,即使未报错,也应考虑优化或扩容!
显示每个 CPU 核心情况
在 top 命令中,按下 1(数字键1)可以 展开显示每个 CPU 核心的详细使用情况,而默认情况下 top 显示的是 所有 CPU 核心的汇总数据。它们之间的关系如下:
1. 默认视图(汇总所有 CPU 核心)
示例:
%Cpu(s): 8.3 us, 2.1 sy, 0.0 ni, 89.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
- 这个数据是 所有 CPU 核心的平均值。
- 例如,如果系统有 4 个 CPU 核心,
8.3% us表示:- 所有核心 的用户态 CPU 使用率 平均为 8.3%。
- 但 不代表每个核心都是 8.3%,可能有的核心 20%,有的核心 0%。
2. 按下 1 后(显示每个 CPU 核心的独立数据)
示例(4 核 CPU 系统):
%Cpu0 : 15.0 us, 3.0 sy, 0.0 ni, 82.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 5.0 us, 1.0 sy, 0.0 ni, 94.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 10.0 us, 2.0 sy, 0.0 ni, 88.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 3.0 us, 2.0 sy, 0.0 ni, 95.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu0、%Cpu1、%Cpu2、%Cpu3分别代表 每个 CPU 核心的独立使用情况。- 默认的汇总数据(
%Cpu(s))是这些值的平均值:us(用户态)平均值 =(15.0 + 5.0 + 10.0 + 3.0) / 4 = 8.25 ≈ 8.3(与默认视图一致)id(空闲)平均值 =(82.0 + 94.0 + 88.0 + 95.0) / 4 = 89.75 ≈ 89.6(与默认视图一致)
3. 关键关系
| 对比项 | 默认视图(%Cpu(s)) |
按下 1 后的视图(%Cpu0、%Cpu1...) |
|---|---|---|
| 数据来源 | 所有 CPU 核心的平均值 | 每个 CPU 核心的独立数据 |
| 计算方式 | 所有核心的 us、sy、id 等取平均 |
每个核心单独统计 |
| 适用场景 | 快速查看整体 CPU 负载 | 分析 CPU 负载是否均衡 |
4. 实际应用场景
(1) CPU 负载不均衡
- 如果 某个核心的
us很高(如%Cpu0: 90% us),但其他核心很低(如%Cpu1: 10% us):- 可能是 单线程应用 只跑在一个核心上。
- 也可能是 CPU 亲和性(affinity)设置问题,导致任务未均匀分配。
(2) 判断 CPU 瓶颈
- 默认视图
%Cpu(s): 80% us:- 如果 每个核心的
us都接近 80% → 所有核心均满载,需扩容 CPU。 - 如果 只有 1 个核心
us=80%,其他核心us=20%→ 单线程瓶颈,需优化并行度。
- 如果 每个核心的
(3) 监控多核 CPU 的利用率
- 理想情况:所有核心的负载接近平均值(均衡分布)。
- 异常情况:某个核心长期 100%,其他核心空闲 → 可能存在 CPU 亲和性问题 或 单线程任务阻塞。
5. 如何进一步分析?
taskset:查看或设置进程的 CPU 亲和性(绑定到特定核心)。mpstat -P ALL 1:实时监控每个 CPU 核心的使用情况(类似top按1的效果)。pidstat -t -p <PID> 1:查看某个进程的线程在哪些 CPU 核心上运行。
总结
- 默认
%Cpu(s)是所有 CPU 核心的平均值。 - 按下
1可查看每个核心的独立数据,帮助判断 CPU 负载是否均衡。 - 如果某个核心长期高负载,而其他核心空闲,可能是单线程任务或 CPU 亲和性问题,需要优化任务分配。
通过对比 默认视图 和 单核视图,可以更精准地定位 CPU 性能瓶颈!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号