编译原理

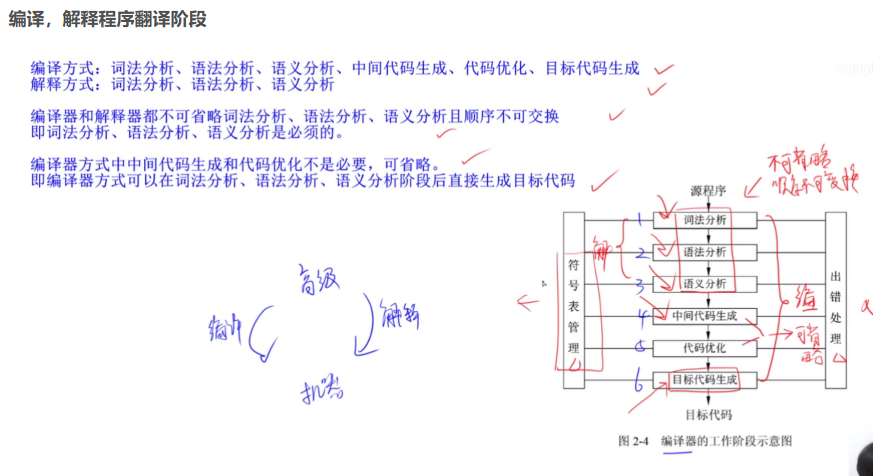
编译过程的五个主要阶段如下:
- 词法分析(Lexical Analysis)
- 将源代码分解为词法单元(Token)(如关键字、标识符、运算符等)。
- 移除空白字符、注释等无关内容。
- 工具示例:词法分析器(Lexer)。
- 语法分析(Syntax Analysis)
- 根据语法规则检查词法单元的组合是否合法,生成抽象语法树(AST)。
- 报告语法错误(如缺少分号、括号不匹配等)。
- 工具示例:语法分析器(Parser)。
- 语义分析(Semantic Analysis)
- 检查程序语义的正确性(如类型匹配、变量声明、作用域规则)。
- 填充符号表(Symbol Table),标注AST的类型信息。
- 示例:发现
int a = "hello";这类类型不匹配错误。
- 中间代码生成(Intermediate Code Generation)
- 将AST转换为与机器无关的中间表示(IR)(如三地址码、LLVM IR)。
- 目的:便于后续优化和跨平台移植。
- 代码优化与目标代码生成
- 代码优化:对IR进行优化(如删除冗余代码、循环优化)。
- 目标代码生成:将IR转换为目标机器代码(汇编或二进制)。
- 最终生成可执行文件或库。
补充说明
- 前端:阶段1~4通常称为编译器前端(与语言相关)。
- 后端:代码优化和目标代码生成属于后端(与机器相关)。
- 现代编译器(如GCC、Clang)可能包含更复杂的多阶段优化流程。
例如,a = b + c 的编译流程:
- 词法分析 → Tokens:
[a, =, b, +, c] - 语法分析 → AST:
Assignment(a, Addition(b, c)) - 语义分析 → 确认变量类型合法
- 中间代码 →
t1 = b + c; a = t1 - 目标代码 → 生成对应的汇编指令(如
mov,add)。
在编译过程的每个阶段,编译器会检测不同类型的错误。以下是各阶段的典型错误示例:
1. 词法分析阶段错误
错误类型:非法字符或不符合词法规则的符号。
示例:
-
未闭合的字符串:
printf("Hello); // 缺少右引号 -
非法标识符(如以数字开头):
123var = 10 # Python变量名不能以数字开头 -
不支持的运算符:
a = 1 @ 2; // '@' 在C语言中不是有效运算符
2. 语法分析阶段错误
错误类型:代码结构不符合语法规则。
示例:
-
缺少分号(C/Java类语言):
int x = 10 // 缺少分号 -
括号不匹配:
if (a > b: # 缺少右括号 -
错误的循环结构:
for (let i = 0; i < 10; i++ { // 缺少右括号
3. 语义分析阶段错误
错误类型:代码逻辑违反语言规范(类型、作用域等)。
示例:
-
类型不匹配:
int a = "hello"; // 字符串无法赋给整型 -
未声明的变量:
x = 5; // 变量x未定义 -
作用域错误:
def foo(): y = 10 print(y) # y是foo()的局部变量,外部不可访问
4. 中间代码生成阶段错误
错误类型:通常由前序阶段错误引发,或优化冲突。
示例:
-
不可达代码(优化时可能报错):
return 0; System.out.println("Unreachable"); // 无法执行的代码 -
中间表示生成失败(如AST转换IR时的逻辑冲突)。
5. 代码优化与目标代码生成阶段错误
错误类型:平台相关错误或优化导致的意外行为。
示例:
-
寄存器分配失败(目标机器资源不足)。
-
优化后的代码行为异常(如过度优化删除必要代码):
// 编译器优化可能移除未使用的变量 int debug_flag = 1; // 若未被引用,可能被优化掉
其他常见错误关联
-
链接阶段错误(不属于编译阶段,但常被混淆):
// 声明但未定义函数 void foo(); int main() { foo(); } // 链接时报错:undefined reference
总结:
- 前端错误(词法/语法/语义)更直观,如拼写、结构错误。
- 后端错误(优化/目标代码)通常与硬件或编译器实现相关。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号