
elasticsearch深度分页问题
elasticsearch专栏:https://www.cnblogs.com/hello-shf/category/1550315.html
一、深度分页方式from + size
es 默认采用的分页方式是 from+ size 的形式,在深度分页的情况下,这种使用方式效率是非常低的,比如我们执行如下查询
1 GET /student/student/_search 2 { 3 "query":{ 4 "match_all": {} 5 }, 6 "from":5000, 7 "size":10 8 }
意味着 es 需要在各个分片上匹配排序并得到5010条数据,协调节点拿到这些数据再进行排序等处理,然后结果集中取最后10条数据返回。
我们会发现这样的深度分页将会使得效率非常低,因为我只需要查询10条数据,而es则需要执行from+size条数据然后处理后返回。
其次:es为了性能,限制了我们分页的深度,es目前支持的最大的 max_result_window = 10000;也就是说我们不能分页到10000条数据以上。
例如:
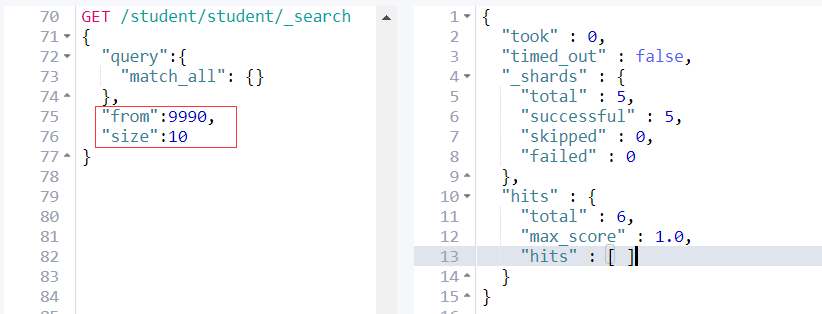
from + size <= 10000所以这个分页深度依然能够执行。
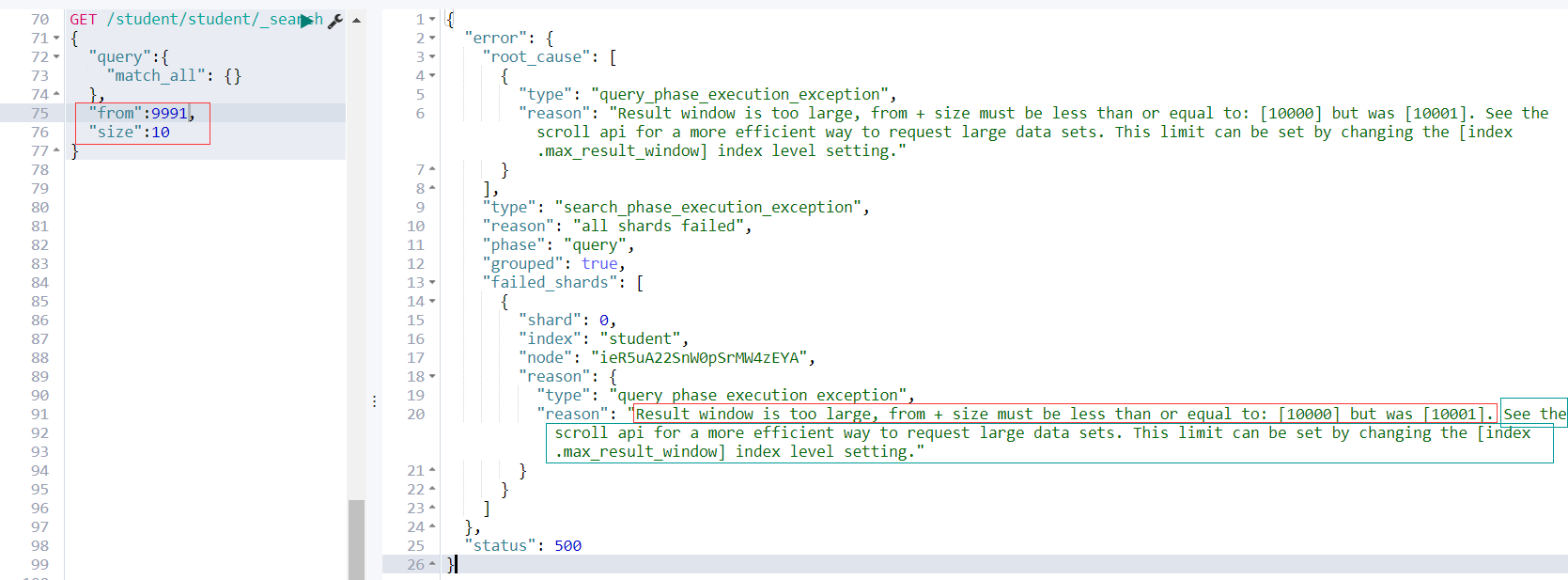
继续看上图,当size + from > 10000;es查询失败,并且提示
Result window is too large, from + size must be less than or equal to: [10000] but was [10001]
接下来看还有一个很重要的提示
See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting
有关请求大数据集的更有效方法,请参阅滚动api。这个限制可以通过改变[索引]来设置。哦呵,原来es给我们提供了另外的一个API scroll。难道这个 scroll 能解决深度分页问题?
二、深度分页之scroll
在es中如果我们分页要请求大数据集或者一次请求要获取较大的数据集,scroll都是一个非常好的解决方案。
使用scroll滚动搜索,可以先搜索一批数据,然后下次再搜索一批数据,以此类推,直到搜索出全部的数据来scroll搜索会在第一次搜索的时候,保存一个当时的视图快照,之后只会基于该旧的视图快照提供数据搜索,如果这个期间数据变更,是不会让用户看到的。每次发送scroll请求,我们还需要指定一个scroll参数,指定一个时间窗口,每次搜索请求只要在这个时间窗口内能完成就可以了。
一个滚屏搜索允许我们做一个初始阶段搜索并且持续批量从Elasticsearch里拉取结果直到没有结果剩下。这有点像传统数据库里的cursors(游标)。
滚屏搜索会及时制作快照。这个快照不会包含任何在初始阶段搜索请求后对index做的修改。它通过将旧的数据文件保存在手边,所以可以保护index的样子看起来像搜索开始时的样子。这样将使得我们无法得到用户最近的更新行为。
scroll的使用很简单
执行如下curl,每次请求两条。可以定制 scroll = 5m意味着该窗口过期时间为5分钟。
1 GET /student/student/_search?scroll=5m 2 { 3 "query": { 4 "match_all": {} 5 }, 6 "size": 2 7 }
1 { 2 "_scroll_id" : "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAC0YFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtGRZpZVI1dUEyMlNuVzBwU3JNVzR6RVlBAAAAAAAALRsWaWVSNXVBMjJTblcwcFNyTVc0ekVZQQAAAAAAAC0aFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtHBZpZVI1dUEyMlNuVzBwU3JNVzR6RVlB", 3 "took" : 0, 4 "timed_out" : false, 5 "_shards" : { 6 "total" : 5, 7 "successful" : 5, 8 "skipped" : 0, 9 "failed" : 0 10 }, 11 "hits" : { 12 "total" : 6, 13 "max_score" : 1.0, 14 "hits" : [ 15 { 16 "_index" : "student", 17 "_type" : "student", 18 "_id" : "5", 19 "_score" : 1.0, 20 "_source" : { 21 "name" : "fucheng", 22 "age" : 23, 23 "class" : "2-3" 24 } 25 }, 26 { 27 "_index" : "student", 28 "_type" : "student", 29 "_id" : "2", 30 "_score" : 1.0, 31 "_source" : { 32 "name" : "xiaoming", 33 "age" : 25, 34 "class" : "2-1" 35 } 36 } 37 ] 38 } 39 }
在返回结果中,有一个很重要的
_scroll_id
在后面的请求中我们都要带着这个 scroll_id 去请求。
现在student这个索引中共有6条数据,id分别为 1, 2, 3, 4, 5, 6。当我们使用 scroll 查询第4次的时候,返回结果应该为kong。这时我们就知道已经结果集已经匹配完了。
继续执行3次结果如下三图所示。
1 GET /_search/scroll 2 { 3 "scroll":"5m", 4 "scroll_id":"DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAC0YFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtGRZpZVI1dUEyMlNuVzBwU3JNVzR6RVlBAAAAAAAALRsWaWVSNXVBMjJTblcwcFNyTVc0ekVZQQAAAAAAAC0aFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtHBZpZVI1dUEyMlNuVzBwU3JNVzR6RVlB" 5 }
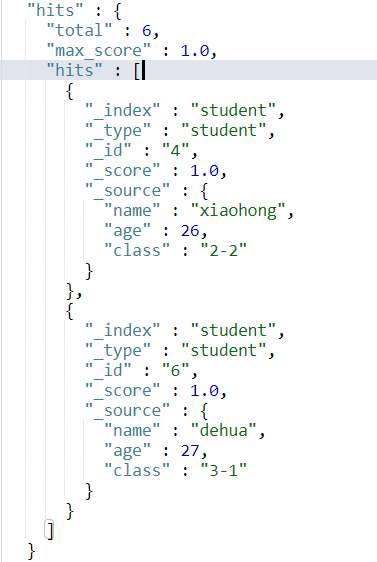

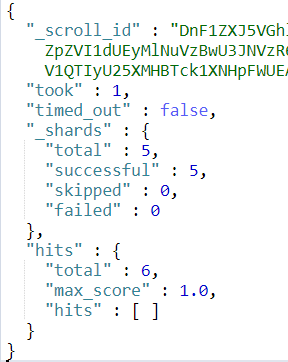
由结果集我们可以发现最终确实分别得到了正确的结果集,并且正确的终止了scroll。
三、search_after
from + size的分页方式虽然是最灵活的分页方式,但是当分页深度达到一定程度将会产生深度分页的问题。scroll能够解决深度分页的问题,但是其无法实现实时查询,即当scroll_id生成后无法查询到之后数据的变更,因为其底层原理是生成数据的快照。这时 search_after应运而生。其是在es-5.X之后才提供的。
search_after 是一种假分页方式,根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。为了找到每一页最后一条数据,每个文档必须有一个全局唯一值,官方推荐使用 _uid 作为全局唯一值,但是只要能表示其唯一性就可以。
为了演示,我们需要给上文中的student索引增加一个uid字段表示其唯一性。
执行如下查询:
1 GET /student/student/_search 2 { 3 "query":{ 4 "match_all": {} 5 }, 6 "size":2, 7 "sort":[ 8 { 9 "uid": "desc" 10 } 11 ] 12 }
结果集:


{ "took" : 1, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : 6, "max_score" : null, "hits" : [ { "_index" : "student", "_type" : "student", "_id" : "6", "_score" : null, "_source" : { "uid" : 1006, "name" : "dehua", "age" : 27, "class" : "3-1" }, "sort" : [ 1006 ] }, { "_index" : "student", "_type" : "student", "_id" : "5", "_score" : null, "_source" : { "uid" : 1005, "name" : "fucheng", "age" : 23, "class" : "2-3" }, "sort" : [ 1005 ] } ] } }
下一次分页,需要将上述分页结果集的最后一条数据的值带上。
1 GET /student/student/_search 2 { 3 "query":{ 4 "match_all": {} 5 }, 6 "size":2, 7 "search_after":[1005], 8 "sort":[ 9 { 10 "uid": "desc" 11 } 12 ] 13 }
这样我们就使用search_after方式实现了分页查询。
四、三种分页方式比较
| 分页方式 | 性能 | 优点 | 缺点 | 场景 |
| from + size | 低 | 灵活性好,实现简单 | 深度分页问题 | 数据量比较小,能容忍深度分页问题 |
| scroll | 中 | 解决了深度分页问题 |
无法反应数据的实时性(快照版本) 维护成本高,需要维护一个 scroll_id |
海量数据的导出(比如笔者刚遇到的将es中20w的数据导入到excel) 需要查询海量结果集的数据 |
| search_after | 高 |
性能最好 不存在深度分页问题 能够反映数据的实时变更 |
实现复杂,需要有一个全局唯一的字段 连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结果 |
海量数据的分页 |
参考文献:
《elasticsearch-权威指南》
如有错误的地方还请留言指正。
原创不易,转载请注明原文地址:https://www.cnblogs.com/hello-shf/p/11543453.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号