redis缓存穿透和缓存雪崩
缓存穿透
原因
例子:
- 用户查询数据,如果缓存中没有数据,就会去数据库中查询,然后再加入缓存中,之后的请求就可以在缓存中查询了;
- 如果用户在查询的时候,使用非法请求,每次查询到的都是数据库中没有的数据,这样就无法存入缓存之中了;
- 这样就会导致,如果用户连续发送这种数据库中根本不存在值的查询,这种请求上千上万次,这种不经过缓存而直接请求数据库,就被称为缓存穿透。
解决方案
空对象也设置缓存
实例:
不为空才放入缓存之中(这样有可能会造成缓存穿透)
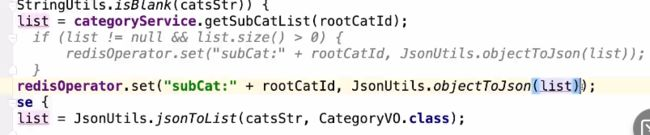
不管是否为空,都将其放入缓存
(为防止占用过多无效key占用存储,为这种类型的key设置一个过期时间 [5-10分钟])
为空的key设置过期时间,不为空的key设置永久存在
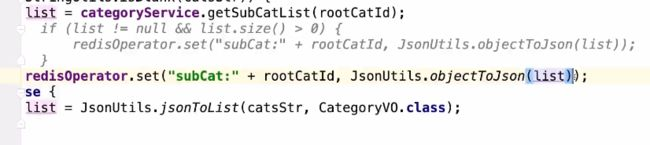
就算将来这种key的值会有值了, 如果后续该id的数据实际新增了,set方法是会去覆盖的,所以无需担心
布隆过滤器
相当于在Redis前加了一层过滤器,用户请求去查询数据,如果缓存中和数据库中都没有数据,
那么布隆过滤器中也必定没有,这样请求经过过滤器得知数据库中没有数据,那么请求就不会访问缓存和数据库了;

将key 存放在 二进制数组中,一个二进制单位可以存放一个或者多个key,这种方式查询起来key是否存在是非常快且迅速的; (1就是存在 key的二进制单位,0就是一个key都没存放)
但是尽量不要用,因为存在缺陷:
- 如果删除了数据库和redis中的数据,但是布隆过滤器中的数据是没法删除的,因为一个二进制单位中可能绑定有多个key,没法达到修改二进制单位为0而达到删除效果; 可以判断某个数据一定不存在,不能判断某个数据key存在, 因为算法hash原因,不同的数据key放在同一个位置;
- 布隆过滤器存在误判的概念,二进制数组越大,误差率越低;有1%的误判率;
- 使用布隆过滤器,代码复杂度会增大, 维护难度会增大,(维护一个集合,这个集合中存在很多的key)
- 集群和分布式环境下,布隆过滤器需要和redis结合使用,数据需要保存到redis中,保证各个节点都要可用;
布隆过滤器原理
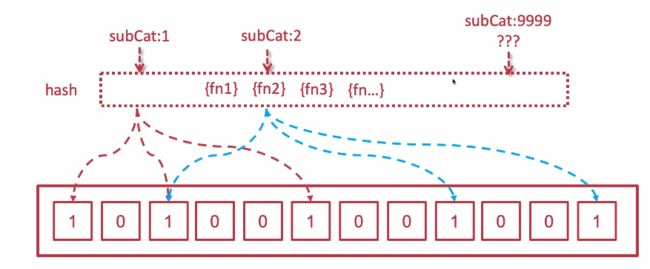
根据存储对象的key值计算出来的hash,找出存放的位置,例如subCat1的key值,计算出来的hash,存放到上图红色虚线所指的位置,当他再被请求到的时候,对应key计算出的hash值如果也指向的 二进制 数都是 1 ;
那么大致可以判断,这个key值的对象是在数据库或者缓存中有值的;
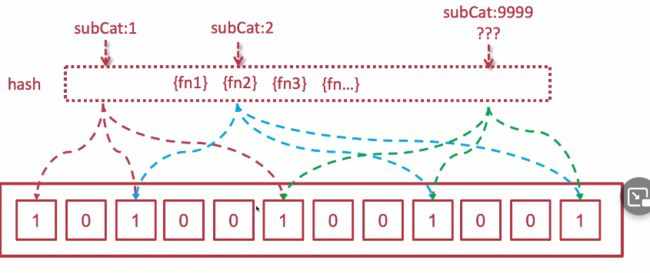
出现误判:
可能这个key对应对象在 数据库或者缓存中其实不存在,但是计算出来的key的hash,所指向的二进制数,是被其他key修改过的二进制数,且全部都刚好为1; 这种情况就是误判的情况
(见上图绿色虚线)
判断某一个键值 一定不存在,布隆过滤器可以判断
但是判断一定存在,可能会出现误判的情况;
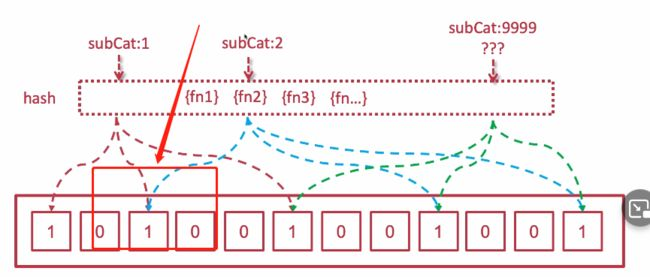
为什么布隆过滤器无法删除
删除需要把对应key的hash 所对应的 二进制数都变为0;
但是这个二进制数有可能不止是这个key的hash所独有的,见上图箭头所指;
你如果单个删除了subcat1,修改全部二进制为0,那么subcat2也在布隆过滤器中不存在了;
假如不需要某个数据了,redis/数据库中做逻辑/物理删除,布隆过滤器id都会存在,下次查询还是存在,无法删除
应用
邮件/短信里面拦截一些黑名单,google浏览器拦截病毒/非法网站
预热,现有的数据会先全量放到布隆过滤器中;
由于布隆过滤器无法删除(就没保证数据实时性),像redis会需要定时调度删除去拉取最新数据;且由于有误判率,对数据正确性要求很高的应用无法使用
缓存雪崩
原因
某个时间点大面积的key缓存失效,刚好又有很大的流量涌入,所有的请求都打在数据库,数据库的压力就非常大可能会宕机。
缓存雪崩没有好的解决方案,重在预防发生雪崩。
预防方案:
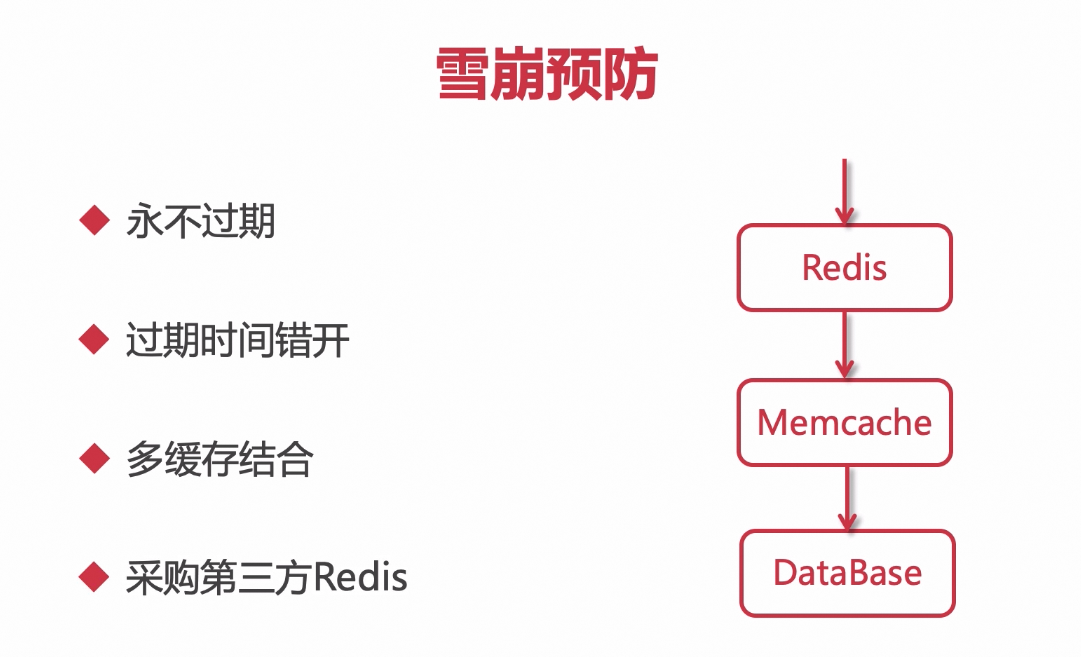
- 永不过期,需要更新数据的话,采用手动过期;有些数据不存储在数据库中,可以设置有效时间,比如验证码;其他一些数据,第一次需要经过数据库查询的就设置为永不过期,后期可以手动的进行过期删除;
- 过期时间错开 初始化缓存的时间错开,前后隔几分钟
- 每次服务器重启初始化的时候,大量的数据加载到缓存中,其中也包括这些设置了过期时间的缓存;
- 如果每种类型的数据过期时间都设置一样的话,有可能会导致过期时间一到,大面积key失效,造成雪崩
- 使用可以给每种key都设置成不同的过期时间,尽量避开同一时间大量缓存key失效;
- 多种缓存结合 相当于在其他缓存中备份,但过期时间更长
- 采购第三方Redis 购买高可用的redis主从备份;自己的redis有运维的成本,误操作导致集群挂掉;
redis高可用
限流降级
数据预热

 浙公网安备 33010602011771号
浙公网安备 33010602011771号