BU AAOO 第一单元作业总结
🌝🌝第一单元作业总结
写在前面,我之前在写作业的时候一直开了一个md文件记录自己的思路和想法,存在了北航云盘里。后来有一天我的电脑在win10自动更新的魔咒下瘫了,从那个噩梦般的下午开始到第二天中午,我用了整整一天换回了一个重置c盘的电脑。结果发现北航云盘没上传上去?至今不明其因,它存在了2个多星期有充足的时间来上传。现在又重写一遍,内心是崩溃的🙉
我在本文中加了大量的emoji。特此澄清:我不是微商!本文没有恰饭广告!
想啥呢哪有人找你恰饭啊
程序结构🗺
本人三次作业都是在同一个project里迭代,但thanks to Git,我能够时光穿梭、返老还童,去看看我以前代码的青涩模样。那么话不多说,让我们开始《穿越之极品码农》
第一节-幂函数时代
我第一次作业竟然只写了两个类,当时觉得难死了,现在回想起来主要精力都在研究形式化表述以及搭建评测姬
刚刚穿越过来的女主角(雾)花了很长时间才适应这个世界的变化。遇见了IDEA中的java文件图标变成这个样子
)无法生成UML图等问题。这时,一位名为CSDN的暖男伸出了援手。每每遇到棘手的问题,他总是第一个冲在前面(??)终于,我拿到了这个时代的信息。
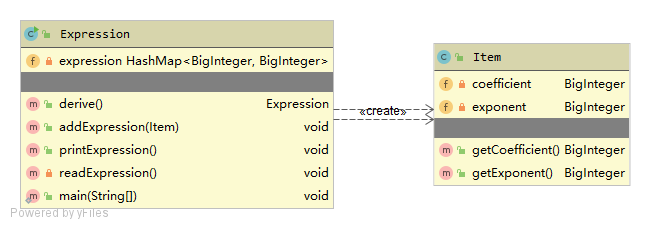
-
Expression类
代表表达式,通过一个HashMap容器装下属的各个项Item
-
Item类
代表项,包含
coefficient,exponent两个属性,顾名思义为系数和指数(这下这俩单词我是再也不怕记不住了)
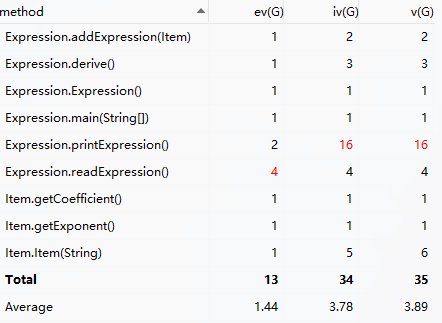
如图,在第一次作业中我的代码复杂度就已经不容乐观了。
- 其中
readExpression复杂度高在于通过复杂正则在字符串中循环find下一个常数或变量。而用两个大正则区分常数和变量。 - 上一步完成后一律传入
Item(String)的构造方法(故该方法复杂度也在前三)。在该方法中,完全靠if (string.contains("x")) {...}来区分常数和变量,完全不具备扩展性,是面向过程的亲儿子👍

从git日记中我们可以回忆出第一次作业真正debug并不多,“用于对拍”等几次commit都是修改了输出方便自己的评测姬对拍。互测开始前,我的评测方法还很简陋。生成测试数据后通过直接改类里的读取方式,并且还是在java里加循环来完成多次评测。于是互测时我就懵了,我不可能改我屋七个人的代码,毕竟大家的实现方法都不一样。
第二节-三角函数时代
biubiubiu!现在我们穿越到了三角函数时代。
突然杀出的三角函数带来了两个主要问题:
- 新的函数类,表现形式与常数和幂函数存在很大的差异
- 新的求导法则。之前仅有幂函数和系数的表达式经过简易处理都可以化为幂函数的求导的和,现在出现了sin(x), cos(x), x^n的乘积的混合求导
原先的方法完全行不通,所以只能重构了🤦♀️
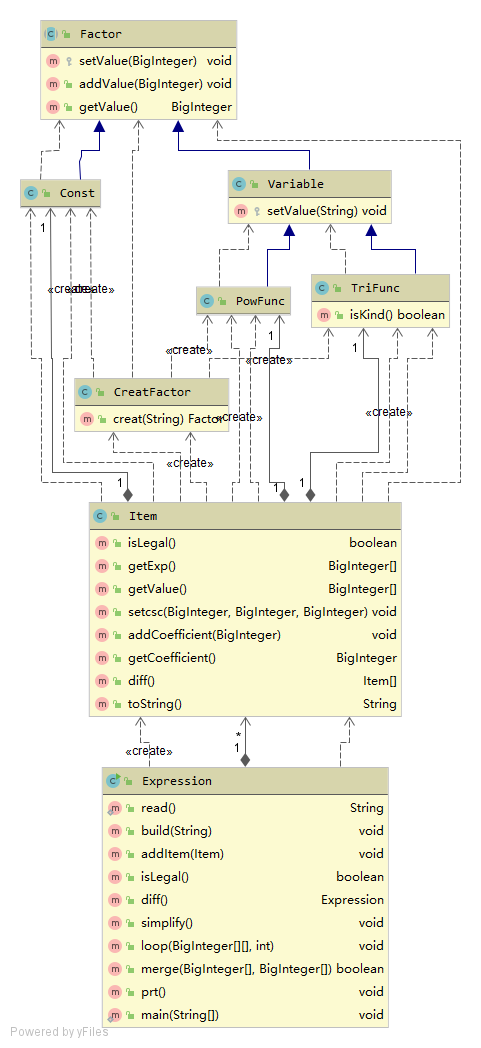
复杂正则不可持续发展,我当时想了好久怎么实现,觉得自己智商真是低到谷底。在自己surface上画了许久,仿佛我的智商已经不支持我仅在大脑中构想实现方法了,不得不付诸笔端。最后终于完成了设计,之后照着设计码代码就相对容易了。
可以看到,这时我已经定义了Factor接口,下继承Const, Variable两类。并且使用工厂模式,将生成的细节交给CreatFactor类完成。Item和Expression意义不变,分别用容器装载Factor和Item,表示相乘关系和相加关系。
解析表达式抛弃之前的复杂正则,采用部分层次化解析。先由Expression找到一项,再交由Item找到其中的因子。(我纠结了很久如何找项,最后没有采用正则,而是采用了如下的算法)Expression在构造方法中遍历字符串寻找下一个+或-。分析形式化表达可知,+或-只会出现在:
- 表达式首
- 项首
- 项间 —— 我们要抓住的东西
- 常数自带符号
- 指数自带符号
以此为依据循环从字符串的第二个字符(默认第一个字符一定属于前一个项)开始查找分割此项及下一项的+或-,并排除上述第三、四种情况。即找到了一个符号,且其前一项不是符号或乘号就能断定从字符串首到这个字符之间就是一个项。
进入项的层次后,前文还可能“剩下”一些正负号,他们在逻辑上应属于“项间”(我把每个项前的正负号划归此项)、“项首”和“常数自带符号”。常数的正负号应交给其自己的层次处理。故我们可以这么看,格式正确的项字串存在<=2个正负号来表征结构。于是我设置了读取<=2个字符并调节项系数正负的代码。
而在此之前,我已经将所有的**转化成了^号,因此剩下“纯净”的项中分割各个因子的就当且仅当是*号(但这样的字符串处理也埋下了潜在的bug,后文会述),使用split()方法就可以得到想要的各个项。但是要注意的一点是,在每次使用split()的时候,都要考虑会不会分出空串!。
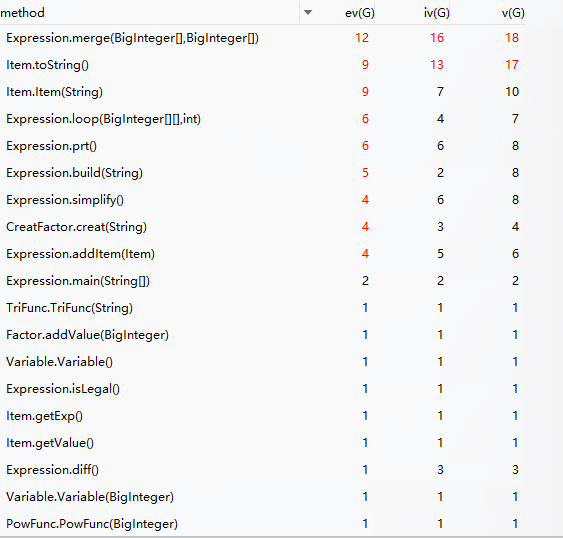
由于方法较多,以上截取了复杂度较高的一部分。可以看到复杂的部分还是在Expression 和Item中,为什么呢?因为在这次作业中我仍没有很好的“权力下放”
写这次作业的过程中我也在自我反思。可以看到我在向面向对象努力转型,但是总觉得我写出的是虚假的面向对象
下图是我PowFunc类(顾名思义,幂函数)的全部代码。继承自Variable类的它只有两个构造方法,
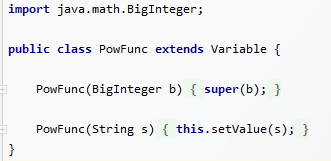
且本质上还是在使用父类的方法。恰好这周的课上老师讲到了这个问题,说的简直就是我本人。诸如求导等应交给具体类的方法,我还是扔给了Expression和Item进行偷鸡处理。因为一个项一定是由 常数 * x^a * sin(x)^b * cos(x)^c 组成,其求导必会生成三个相加的项,并没有交给下层处理。
可以看到,这次作业相比上次有所进步,但仍有不足。是半面向过程半面向对象封建时期💦。
同时仍要说的是一个惨痛的教训。我复杂度遥遥领先的三个方法merge,loop,simplify本质上都是simplify的眼睛胳膊腿。这是我用来简化三角函数的方法,但是由于面向过程(基本上由数组完成)写的远超80行限制,于是绞尽脑汁拆成了三段。总所周知,越优化越可能产生bug,然后我又牺牲了自己的大把青春去挑优化的bug。等我觉得功成就差名就后,交了上去。然后就有了下图

不说了,我先哭会👋
第三次作业-嵌套时代
刚放开第三次作业的时候我电脑崩了,各中酸楚也不说了,好在在周三考试前装回了IDEA。(说到周三考试,我忘了指导视频的存在,开始考试后先是仔细阅读学习了工厂模式,再仔细写代码,然后发现和人家对补全代码的调用完全不兼容,再重写,再发现新IDEA莫名无法调试,最后快到点才交上去,冷却时间的时候想到一个可能的bug,但是已经无济于事了🐷我是真的智商从来没上线过🤦♀️)
这回加了嵌套,起先我盯之前的代码盯了许久也盯不出个名堂,脑子像一团浆糊。后来意识到自己的智商现状,老老实实去写写画画了。也是设计了蛮久,之后照着设计敲代码就顺一些(仿佛找到了低智商群体的自救指南)
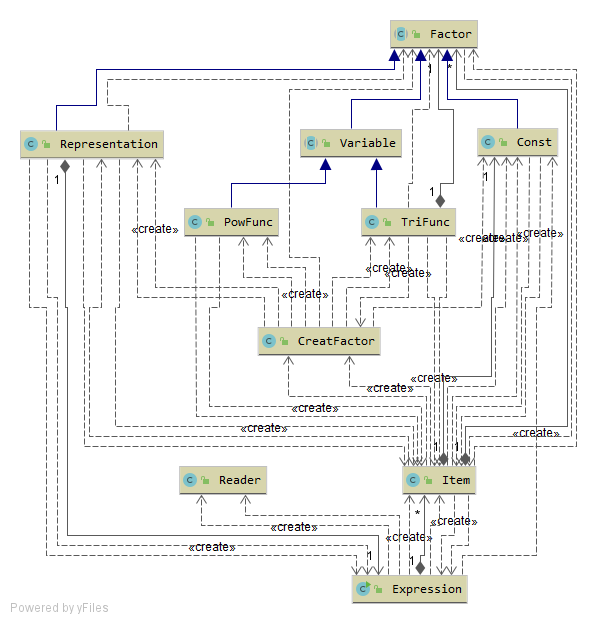
这次是经过权衡最后选择了按照逻辑在“因子”(Factor)中加入“带括号的表达式”(Representation)一种因子,并且将Factor由接口改为抽象类,规定了因子通有的属性和方法(含抽象和非抽象方法)。变量Variable类也降为抽象类。此次虚假的面向过程求导法又行不通了,算是半重构吧。
这次不能像之前一样单纯的遍历查找符号,因为括号中也存在符号,因此设置了括号栈,附加新的条件stack == 0。
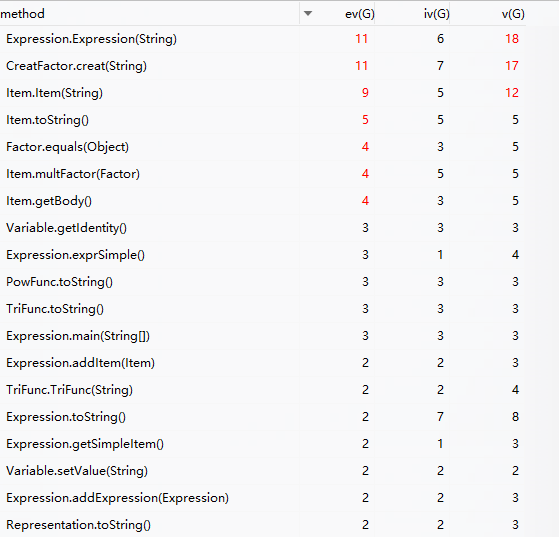
可以看到复杂度高的都是处理字符串的,在读别的同学的代码的过程中看到有人专门封装了处理字符串的方法,值得借鉴。但我的代码如果这么做,也只能是把函数换个地方起个名字,感觉没什么区别,可能还是设计有缺陷?
这次遇到四个主要问题:
-
深浅拷贝
在求导过程中,假设某项含有n个因子,则循环遍历各个因子。每次clone一个该项本身出来,删去(除以)此次的因子,添加(乘以)这个因子的求导表达式。(这个过程出了一堆bug)项的clone主要是遍历各个因子clone,而每个因子都要重写clone。而在克隆的过程中如何保持表示该因子“身份”的字符串不变,这就引出下一个问题。
-
统一规定
起初我没有统一,有些地方采用toString方法,有些采用toBase方法(一个返回身份字符串的方法),有的采用返回传入的字符串。导致这些字符串尽管语义一致,但表达形式不同,在hashmap中被判为不同的项。
一开始我是发现一个bug改一个,后来发现这样不统一隐患太多,于是整体从头梳理了一遍。防止混淆增加了新的方法
toIdentity专管身份字符串(加法中合并同类项),toString专管生成最终合法输出,其余情况不准调用,toBase专管表示底数的字符串(乘法中合并)。还有其他很多细节,所有因子的构造方法传入的都应是处理到什么程度的表达式等等。在做过细致的规定后,细碎的bug消失了!(个人觉得这也是很多童靴被揪出很多bug的原因,不做统一的规定很容易在犄角旮旯出问题)但是!程序中需要这样详细的规定是否本身就是不优雅的表现?目前我也不清楚,水平有限,不知道良好的代码是应该做好统一的规定还是应该规避对规定的依赖?

-
属性混用
(为了凑四字词语的格式起了这么奇怪的一个标题)
如前文所述,我在Factor接口中规定了两个属性value和base。在常数中base无用,value表示其值;在变量中base表示底数,value表示指数;在括号表达式中base表示整个括号表达式(类似底数),value表示指数。这样的混用会出现一些小问题,是代码变得更加复杂,没有很好的封装。感觉是强行面向对象的产物,仔细一想,可能真是因为这样的混用才需要上一点中的繁琐规定防止出错。
-
一口胖子
即一口吃成个大胖子的四字版😂
我在设计的时候代码的整体架构就是自带优化了。比如在创造一个括号表达式项是会检测内容是否可以化简,生成标记,在往项中添加因子是会读取是否可以化简,如果可以则new出一个去掉括号的新的因子添加进去。虽然效果还可以,不会出现tle的情况(而且我只去了个括号竟然强测性能分就都100了助教真友好🙏)。但是感觉可以不要总想着一口吃成个大胖子,下次可以先写出满足功能的代码后再进行扩展式的优化。
第四次作业-回忆时代
对不起我真的不会起标题
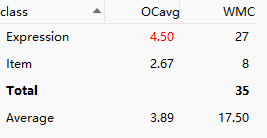
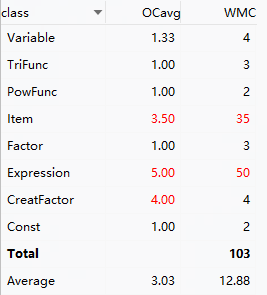
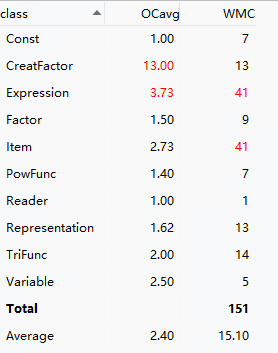
把三次作业的复杂度分析扔一块看看
- 跟大佬比我还是太菜了🤦♀️,红色就没消失过,还是不够面向对象
- 平均复杂度一直在降,分子分母都在激增的同时总值下降应该算是好事
- WMC并没有持续下降,第三次作业嵌套的解决方法设计的确实还不够简洁
BUG簿🐞
第一次强测没问题,第二次第三次都被测出来少判断一个WF🤦♀️而且都是空白符的问题。在强测前被捉到的bug很多,我这种丢三落四的人代码刚出炉的时候千疮百孔。
第一次作业中测过后内心依然忐忑不安,评测姬跑了很久好像没什么问题,最后强测确实没查出什么问题。
第二次作业在中测过了后又陆陆续续查出几个bug(这种bug找出来后总感觉很后怕hhhh)强测还是测出一个垂直制表符。
第三次作业我是周四才开始动手写的,别人debug的时候我还没写利索,所以不想别人在找第几个点有什么坑,因为我知道我这代码绝对不只是第几个点有问题,它肯定到处都是问题!所以没管测试点,对着代码整体修改后再交时这些点也就都过了。但我还是忐忑!又到处找那种手搓的数据一个个测(One Thousand Year Later),又交了三次。但我还是忐忑...后来强测又查出cos(- 1)没判WF。
以上足以说明我这个单元作业在WF判断存在很大漏洞。可想而知我的评测姬只生成合法数据,一方面测不出WF,另一方面反映我从未思考过系统地构造非法数据,因此代码也缺少系统全面的判断WF,这二者应该是相辅相成的。
互测屋🏛
此次作业互测屋体验极佳,以前超爱看《Fate》来着,这些匿名身份一下子勾起了我无限的回忆。
可能因为我总是很忐忑,所以非WF部分测的比较充分,互测的时候没被查出bug来。
然后拿测我自己的东西测他们总能查出bug来🤦♀️(但是下次hack的时候应该记录一下,最后一次因为bug太多,我就总是忘了自己hack过哪些,非同质的漏交了,同质的交了好几次...)
这算是我忐忑的好处吧,但忐忑的坏处也很明显。我一直在测测测,一直不放心,导致关闭中测前基本上只围着OO转(OO老师表示非常开心)效率低且浪费时间。
心得杂技🤹
请阅读本文题目并回答,为什么作者使用杂技而不是杂记?(10分)
答:因为她输入法太笨了。
回答正确!但是作者转念一想,正是这些零零碎碎的知识点与感悟才拼起了一场完美的OO
翻车现场表演,那么这些小知识点不正像一个个上演的杂技一样吗?作者为自己的机智折服了。
通过这次作业主要学习了面向对象的思想、如何使用接口和抽象类、如何合理地利用正则表达式、如何搭建更加完善且自动化的评测姬。
知识上做的不够的地方上文都有详述,与此同时在这个过程中我的效率和心态一直不容乐观。如上文所述,出现了各种各样的“意外”,导致我的心态更崩(其实我本来心态就不怎么好,我总觉得自己蠢得要死,但其实冷静想一想再蠢也没有到要死的地步)。如何自我调节、如何合理规划时间也是要学习的一部分吧。
以上就是全部内容,废话太多,敬请见谅。(看了别人的博客,再看我的,怎么这么羞耻啊???)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号