tornado五:tornado.web.RequestHandler请求与响应
一、请求
http://www.baidu.com:8080/path1/path2/file.html?a=1&b=2#abc
客户端请求流程:查询本地hosts文件,如果没有主机名www.baidu.com对应的ip,从cdn服务器查义主机名对应的ip,找到,则访问到服务器。再根据路径和文件名,访问到/path1/path2/file.html文件;查询参数为:a=1&b=2,锚为abc。浏览器接收到此文件以后,显示在浏览上。
tornado.web.RequestHandler的作用:
1.利用HTTP协议向服务器传递参数。
其传递参数的方式有:
- 提取uri的特定部分
-
- 示例:网址如http://127.0.0.1/liuyf/aaa/bb/c,http://127.0.0.1/liuyf为固定部分,路径/aaa/bb/c为可变部分。要实现此功能,需要提取uri部分作为参数。
# 路由1: (r'/liuyf/(\w+)/(\w+)/(\w+)', index.LiuyfHandler) # 路由2: (r'/liuyf/(?P<p1>\w+)/(?P<p3>\w+)/(?P<p2>\w+)', index.LiuyfHandler), # 两种路由方式都可匹配下面的视图函数 # handler: class LiuyfHandler(RequestHandler):
# 接收uri参数, 在get、post等请求函数的参数中接收。 def get(self, h1, h2, h3, *args, **kwargs): print h1,h2,h3 self.write('这是liuyf')
- 示例:网址如http://127.0.0.1/liuyf/aaa/bb/c,http://127.0.0.1/liuyf为固定部分,路径/aaa/bb/c为可变部分。要实现此功能,需要提取uri部分作为参数。
-
- 查询字符串,get方式传递参数
- 网址:http://127.0.0.1/zhangmy?a=1&b=2&c=3
# 路由一样: (r'/zhangmy', index.ZhangmyHandler) #Handler: class ZhangmyHandler(RequestHandler): def get(self,*args, **kwargs): # get_argument方法的原型:self.get_argument(name, default=ARG_DEFAULT, strip=True) # name:从get请求参数字符串中返回指定参数的值。如果出现多个同名参数,这个方法会返回最后一个值。 # default:设置未传的name参数的默认值。如果name未传,default也未设置,会抛出tornado.web.MissingArgument异常 # strip:表示是否过滤掉参数值的左右空白字符,默认为True。通常情况下不需要空格字符,但是在搜索等情况下需要空格。 a = self.get_query_argument("a") b = self.get_query_argument("b") c = self.get_query_argument("c") print "*"+a+"*","*"+b+"*","*"+c+"*" self.write('这是zhangmy')
- 网址:http://127.0.0.1/zhangmy?a=1&a=2&a=3
class ZhangmyHandler(RequestHandler): def get(self,*args, **kwargs): # 如果有多个同名参数,使用get_argument会获取到最后一个值。 # 如果想要多个值都获取,要使用get_arguments,返回列表。 # get_arguments方法的原型:self.get_argument(name, strip=True) a = self.get_query_arguments("a") print "*"+a+"*" self.write('这是zhangmy')
- 网址:http://127.0.0.1/zhangmy?a=1&b=2&c=3
- 请求体携带数据,post方式传递参数
- 示例:
- 1.创建路由
(r'/mylike', index.MyLikeHandler)
- 2.创建一个提交数据的页面
-
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>select my like</title> </head> <body> <form action="/mylike" method="post"> 姓名:<input type="text" name="name"/> <hr/> 密码:<input type="password" name="passwd"/> <hr/> 爱好: <input type="checkbox" value="power" name="mylike">权利 <input type="checkbox" value="money" name="mylike">金钱 <input type="checkbox" value="book" name="mylike">书 <input type="submit" value="登陆"> </form> </body> </html>
在post请求,提交数据之前:自动使用get方法返回上面的页面。页面渲染使用self.render(模板)。
#Handler: class MyLikeHandler(RequestHandler): def get(self, *args, **kwargs): # 返回模板 self.render("postfile.html")
- 处理post请求参数:
class MyLikeHandler(RequestHandler): def get(self, *args, **kwargs): # 返回模板 self.render("postfile.html") def post(self, *args, **kwargs): # 接收post参数 # 1.使用get_body_argument,原型为: # self.get_body_argument(name, default=ARG_ARGUMENT, strip=True) # 2.如果存在多个同名参数,想取所有值,使用get_body_arguments,返回列表,原型为: # self.get_body_arguments(name, strip=True) name = self.get_body_argument("name") passwd = self.get_body_argument("passwd") likeList = self.get_body_arguments("like") print name, passwd, likeList self.write("提交成功!")
- 既可以获取get请求,也可以获取post请求的参数
- get_argument(name, default=ARG_DEFAULT, strip=True)和get_arguments(name, default=ARG_DEFAULT, strip=True)既可以获取get请求参数,也可以获取post请求参数。以上面的示例为例:
class MyLikeHandler(RequestHandler): def get(self, *args, **kwargs): # 返回模板 self.render("postfile.html") def post(self, *args, **kwargs): # 同时接收get和post参数 # 1.使用get_argument,原型为: # self.getargument(name, default=ARG_ARGUMENT, strip=True) # 2.如果存在多个同名参数,想取所有值,使用get_arguments,返回列表,原型为: # self.get_arguments(name, strip=True) a_list = self.get_arguments("a") b = self.get_argument("b") c = self.get_argument("c") name = self.get_argument("name") passwd = self.get_argument("passwd") likeList = self.get_arguments("like") print name, passwd, likeList self.write("提交成功!")
以上的缺点,不能区分是get还是post的参数;优点,可以同时获取get和post的参数。
- get_argument(name, default=ARG_DEFAULT, strip=True)和get_arguments(name, default=ARG_DEFAULT, strip=True)既可以获取get请求参数,也可以获取post请求参数。以上面的示例为例:
- 在http报文的头中增加自定义的字段:略
2.request对象--请求对象
作用:存储了关于请求的相关信息。
它拥有的属性:
method:是HTTP请求的方式
host:被请求的服务器名称
uri:请求的完整资源地址,包括路径和get查询参数部分:/path1/path2/file.html?a=1&b=2
path:请求的路径部分:/path1/path2
query:请求参数部分:a=1&b=2
version:使用的HTTP版本
headers:请求的协议头,是一个字典类型
body:请求体的数据,post请求才有请求体。
remote_ip:客户端的ip
files:用户上传的文件,是一字典类型
#路由 ('r/haha', index.HahaHandler), # 视图处理Handler class HahaHandler(RequestHandler): def get(self, *args, **kwargs): print self.request.method print self.request.uri print self.request.path print self.request.query print self.request.version print self.request.headers print self.request.body print self.request.remote_ip print self.request.files
3.tornador.httputil.HTTPFile对象:是接收到的文件对象,每上传一个文件,生成一个文件对象。
当上传文件的时侯,才有此文件对象。
此文件对象的属性:
- filename:文件的实际名字
- body属性:文件的数据实体,即数据内容
- content_type:文件的类型
上传文件的过程:
1).get展示页面;
2).post请求上传文件;
3).在服务器上创建一个同名同类型文件;
4).将tornador.httputil.HTTPFile对象的body内容写入服务器上的同名文件。
创建一个上传文件的页面:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>上传文件</title> </head> <body> <form method="post" action="/linqx" enctype="multipart/form-data"> <input type="file" name="file"> <input type="file" name="file"> <input type="file" name="img"> <input type="submit" value="上传"> </form> </body> </html>
创建上传文件的路由:
(r'/linqx', index.UpfileHandler)
视图函数Handler:
class UpFileHandler(RequestHandler): def get(self, *args, **kwargs): # 展示上传文件的页面 self.render("upfile.html") def post(self, *args, **kwargs): filesDict = self.request.files # files 就是tornador.httputil.HTTPFile对象 print filesDict
# 最外层字典的key是html文件中的input标签的name的值,可以为任意值。 """{"file": [{ "filename": "a.txt", "body": b"this is content.........", "content_type": "text/plain" }, { "filename": "b.txt", "body": b"this is b's content.........", "content_type": "text/plain" },], "img":[{ "filename": "图片.png", "body": b"weradfs342r.........", "content_type":"image/png" },], }""" # 将文件写入到服务器上 import os import config for inputname in filesDict: fileArr = filesDict[inputname] for fileObj in fileArr: filePath = os.path.join(config.BASE_DIRS, 'upfile/' + inputname) with open(filePath, 'wb') as f: f.write(fileObj.body) self.write("上传文件成功!")
二、响应
响应中的方法,也在RequestHandler对象中。
带有self的方法,是RequestHandler已实现的方法,是实例方法,直接使用。
未带self的方法,是RequestHandler未实现的方法,需要我们重写的方法,如果有需要。
1.self.wirte:
原型self.wirte(chunk)。
作用:将chunk数据写到输出缓冲区,对应的响应socket将缓冲区的数据返回给浏览器。
缓冲区刷新条件:1.程序结束;2.手动刷新;3.缓冲区满了;遇到/n
2.self.finish(chunck=None),默认chunk为None
作用:刷新缓冲区,并关闭当次请求通道。
因此,self.finish()后面的self.write('asdf')内容虽然会写入到缓冲区,但是请求通道已关闭,不会返回给用户,没有意义了。
3.利用self.wirte('.....')写json,返回给ajax,是动态的刷新给的。如,浏览器向下拖动的数据,是后来加载的。
返回json数据给浏览器方式一,手动转换数据为json字符串:
# json ('r/json1', index.Json1Handler)
class Json1Handler(RequestHandler): def get(self, *args, **kwargs): per = { "name": "haha", "age": 23, "heigh": 175, "weight":70 } import json jsonStr = json.dumps(per) self.write(jsonStr)
返回json数据给浏览器方式二:
self.writer(),默认会转换为json字符串返回。
class Json1Handler(RequestHandler): def get(self, *args, **kwargs): per = { "name": "haha", "age": 23, "heigh": 175, "weight":70 } self.write(per)
区别:方式一手动序列化时,返回的headers中的content_type为application/html;
方式二使用write自动序列化时,返回的headers中的content_type为application/json;
因此,希望返回json数据时,使用第二种方式self.write自动序列化。
4.self.set_header设置响应头(Response Headers)
作用:如,手动设置一个名为username,值为xxxx的响应头字段
参数:name,字段名称;value字段值
示例:将3中的第一种方式的content_type改为application/json;charset=UTF-8
class Json1Handler(RequestHandler): def get(self, *args, **kwargs): per = { "name": "haha", "age": 23, "heigh": 175, "weight":70 } import json jsonStr = json.dumps(per) self.set_header("Content-Type", "application/json;charset=UTF-8") self.set_header("heihei", "heihei's value") self.write(jsonStr)
5.set_default_headers()设置响应头
通常,要修改响应头,重写此方法,而不是在随处任写;在此方法中,调用self.set_header()去设置响应头。
作用:此方法,在进入HTTP响应处理之前调用,可以重写该 方法来预先设置响应头。
注意:如果在多处,写了self.set_header()方法;后调用的方法会覆盖先调用的方法。
class HeaderHandler(RequestHandler): def set_default_headers(self): self.set_header("Content-Type", "application/json;charset=UTF-8") self.set_header("heihei", "1") def get(self, *args, **kwargs): self.set_header("heihei", "2") self.write("test set_header")
6.self.set_status(status_code, reason=None)设置响应状态码
作用:为响应设置状态码
参数:status_code,状态码值,为int整型;reason,描述状态码的词组,string类型。
如果reason的值为None,则状态码必须为系统定义的值。
1).使用已有的(系统定义的)状态码:
class StatusHandler(RequestHandler): def get(self, *args, **kwargs): self.set_status(404) self.write('sdaf.........')
2).使用自定义的状态码:
此时,reason不能为None,否则将抛出异常。
class StatusHandler(RequestHandler): def get(self, *args, **kwargs): self.set_status(999, "who?") self.write('sdaf.........')
7.self.redirect(url)重定向
作用:重定向到url网址
# 重定向 (r'/redirect', index.RedirectHandler), class RedirectHandler(RequestHandler): def get(self, *args, **kwargs): self.redirect("/")
8.self.send_error(status_code=500, **kwargs): 用以抛出错误状态码
作用:抛出HTTP错误状态码,默认为500。抛出错误后tornado会调用writer_error()方法进行处理,并返回给浏览器错误界面。
9.write_error(status_code, **kwargs):用来处理抛出的错误
作用:用来处理send_error抛出的错误信息,并并返回给浏览器错误界面。同上面的方法一起使用。
# 路由 # 错误处理 #iserror?flag=2,假设flag为0为错误 (r'/iserror', index.ErrorHandler) # Handler class ErrorHandler(RequestHandler): def write_error(self, status_code, **kwargs): if status_code == 500: self.set_status(500) # 或者返回自定义的页面 self.write("服务器内部错误") elif status_code == 404: self.set_status(404) self.write("资源不存在") else: self.set_status(999, "what") self.write("未知错误") def get(self, *args, **kwargs): flag = self.get_query_argument("flag") if flag == '0': self.send_error(500) self.write("your are right!")
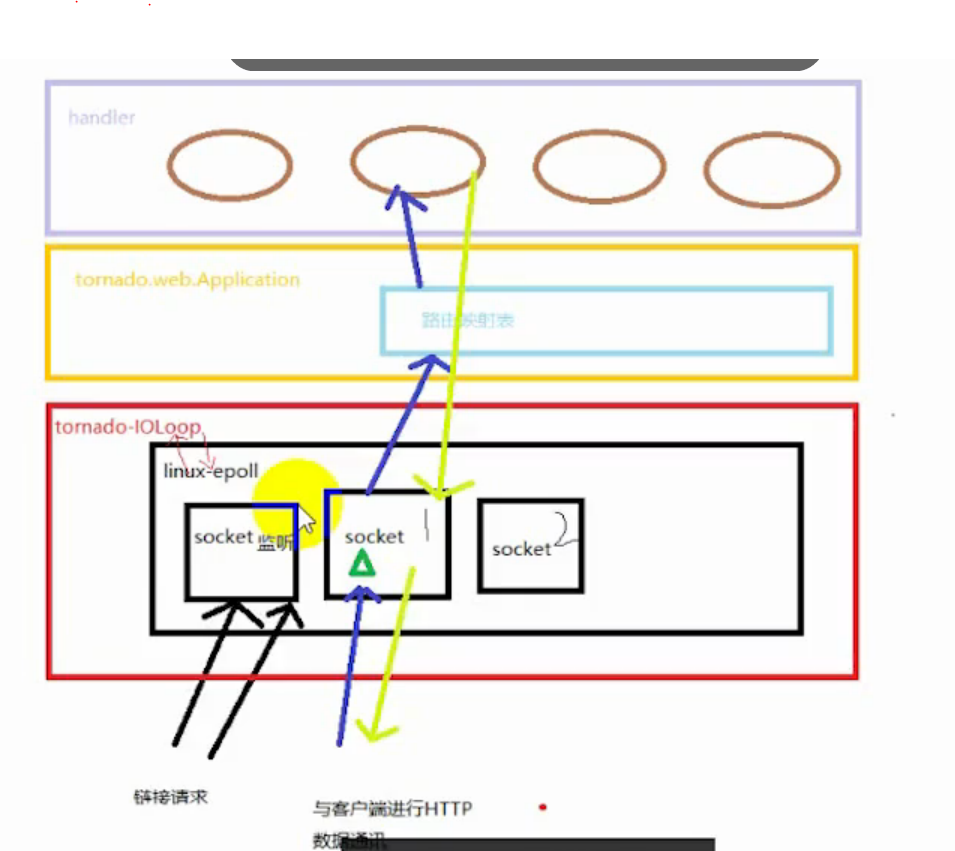
三、请求与响应流程
红色边框:tornado-IOLoop
黑色边框:linux服务器范围:
- 当tornado httpserver服务器创建成功以后,linux服务器为http服务器创建socket,创建后将socket交给linux服务器管理,负责监听客户端的请求。
- tornado-IOLoop死循环,与linux-epoll交互,询问,是否有新的请求到来。
- 当有客户端请求到来时,linux服务器为每个客户端创建一个独立的socket,如socket1,socket2。
- 并交由tornado处理
蓝色箭头:请求流程
每个客户端请求,使用独立的套接字,如socket1。沿着蓝色箭头,经过socket1,经路由Application处理,交给视图处理函数Handler处理。同步。
黄色箭头:响应流程
Handler收到请求并处理后,沿着黄色箭头,异步返回给客户端响应套接字socket1缓冲区,socket1刷新缓冲区数据返回给浏览器。
posted on 2018-07-28 11:44 myworldworld 阅读(6673) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号