改善python的91个建议(五):性能剖析与优化
第 8 章 性能剖析与优化
建议 79:了解代码优化的基本原则
代码优化是指在不改变程序运行结果的前提下使得程序运行的效率更高,优化的代码意味着代运行速度更快或者占用的资源更少。
-
优先保证代码是可工作的。
-
权衡优化的代价。
-
定义性能指标,集中力量解决首要问题。
-
不要忽略可读性。
建议 80:借助性能优化工具
常见的性能优化工具有 Psyco、Pypy 和 cPython 等。
-
Psyco:Psyco 是一个 just-in-time 的编译器,它能够在不改变源代码的情况下提高一定的性能,Psyco 将操作编译成部分优化的机器码,其操作分成三个不同的级别,有“运行时”、“编译时”和“虚拟时”变量,并根据需要提高和降低变量的级别。运行时变量只是常规 Python 解释器处理的原始字节码和对象结构。一旦 Psyco 将操作编译成机器码,那么编译时变量就会在机器寄存器和可直接访问的内存位置中表示。同时 Python 能高速缓存已编译的机器码以备以后重用,这样能节省一点时间。但 Psyco 也有其缺点,其本身所占内存较大。2012 年 Psyco 项目停止维护并正式结束,由 Pypy 所接替。
-
Pypy:Python 的动态编译器,是 Psyco 的后继项目。其目的是,做到 Psyco 没有做到的动态编译。Pypy 的实现分为两部分,第一部分“用 Python 实现的 Python”,实际上它是使用一个名为 RPython 的 Python 子集实现的,Pypy 能够将 Python 代码转成 C、.NET、Java 等语言和平台的代码;第二部分 Pypy 集成了一种编译 rPython 的即时(JIT)编译器,和许多编译器、解释器不同,这种编译器不关心 Python 代码的词法分析和语法树,所以它直接利用 Python 语言的 Code Object(Python 字节码的表示)。Pypy 直接分析 Python 代码所对应的字节码,这些字节码既不是以字符形式也不是以某种二进制格式保存在文件中。
建议 81:利用 cProfile 定位性能瓶颈
程序性能影响往往符合 80/20 法则,即 20% 的代码的运行时间占用了 80% 的总运行时间。
profile 是 Python 的标准库,可以统计程序里每一个函数的运行时间,并且提供了多样化的报表,而 cProfile 则是它的 C 实现版本,剖析过程本身需要消耗的资源更少。所以在 Python3 中,cProfile 代替了 profile,成为默认的性能剖析模块。
def foo():
sum = 0
for i in range(100):
sum += i
return sum
if __name__ == "__main__":
import cProfile
cProfile.run("foo()")
4 function calls in 0.000 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 <ipython-input-1-e5d41600b11d>:1(foo)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 {built-in method builtins.exec}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' obje
除了用这种方式,cProfile 还可以直接用 Python 解释器调用 cProfile 模块来剖析 Python 程序,如在命令行输入 python -m cProfile prof1.py结果和调用cProfile.run()一样。
cProfile 的统计结果分为 ncalls、tottime、percall、cumtime、percall、filename:lineno(function) 等若干列。
统计项意义ncalls函数的被调用次数tottime函数总计运行时间,不含调用的函数运行时间percall函数运行一次的平均时间,等于 tottime/ncallscumtime函数总计运行时间,含调用的函数运行时间percall函数运行一次的平均时间,等于 cumtime/ncallsfilename:lineno(function)函数所在的文件名、函数的行号、函数名
通常情况下,cProfile 的输出都直接输出到命令行,而且默认是按照文件名排序输出的。cProfile 简单地支持了一些需求,可以在 cProfile.run() 函数里再提供一个实参,就是保存输出的文件名。同样,在命令行参数里,也可以加多一个参数,用来保存 cProfile 的输出。
cProfile 解决了我们的对程序执行性能剖析的需求,但还有一个需求:以多种形式查看报表以便快速定位瓶颈。我们可以通过 pstats 模块的另一个类 Stats 来解决。Stats 的构造函数接受一个参数——就是 cProfile 的输出文件名。Status 提供了对 cProfile 输出结果进行排序、输出控制等功能。我们可以修改前文的程序:
if __name__ == "__main__": import cProfile cProfile.run("foo()", "prof.txt") import pstats p = pstats.Stats("prof.txt") p.sort_stats("time").print_stats()
Stats 有若干个函数,这些函数组合能输出不同的 cProfile 报表,功能非常强大,下面简单介绍一些:
函数函数的作用strip_dirs()用以除去文件名前面的路径信息add(filename,[...])把 profile 的输出文件加入 Stats 实例中统计dump_stats(filename)把 Stats 的统计结果保存到文件sort_stats(key, [...])把最重要的一个函数,用以排序 profile 的输出reverse_order()把 Stats 实例里的数据反序重排print_stats([restriction,...])把 Stats 报表输出到 stdoutprint_callers([restriction,...])输出调用了指定的函数的相关信息print_callees([restriction,...])输出指定的函数调用过的函数的相关信息
这里最重要的函数就是 sort_stats 和 print_stats,通过这两个函数我们几乎可以用适当的形式浏览所有的信息了。下面是详细介绍:
-
sort_stats() 接收一个或者多个字符串参数,如 time、name 等,表明要根据哪一列来排序。比如可以通过用 time 为 key 来排序得知最消耗时间的函数;也可以通过 cumtime 来排序,获知总消耗时间最多的函数。
参数意义ncalls被调用次数cumulative函数运行的总时间file文件名module模块名pcalls简单统计调用line行号name函数名nflName、file、linestdname标准函数名time函数内部运行时间 -
print_stats 输出最后一次调用 sort_stats 之后得到的报表。print_stats 有多个可选参数,用以筛选输出的数据。print_stats 的参数可以是数字也可以是 Perl 风格的正则表达式。
下面举一些例子:
# 将 stats 里的内容取前面 10%,# 将 stats 里的内容取前面 10%,然后再将包含 "foo:" 这个字符串的结果输出 print_stats(".1", "foo:") # 将 stats 里的包含 "foo:" 字符串的内容的前 10% 输出 print_stats("foo:", ".1") # 将 stats 里前 10 条数据输出 print_stats(10) # profile 输出结果的时候相当于如下调用了 Stats 的函数 p.strip_dirs().sort_stats(-1).print_stats()
-
其中,sort_stats 函数的参数是 -1,这是为了与旧版本兼容而保留的。sort_stats 可以接受 -1、0、1、2 之一,这 4 个数分贝对应 "stdname"、"calls"、"time" 和 "cumulative"。但如果你使用了数字为参数,那么 pstats 只按照第一个参数进行排序,其他参数将被忽略。
除了编程接口外,pstats 还提供了友好的命令行交互环境,在命令行执行 python -m pstats 就可以进入交互环境,在交互环境里可以使用 read 或 add 指令读入或加载剖析结果文件, stats 指令用以查看报表,callees 和 callers 指令用以查看特定函数的被调用者和调用者。
如果我们想测试向 list 中添加一个元素需要多少时间,可以使用 timeit 模块:
class Timer([stmt="pass"[, setup="pass"[, timer=<time function>]]])-
stmt 参数是字符串形式的一个代码段,这个代码段将被评测运行时间;
-
setup 参数用以设置 stmt 的运行环境;
-
timer 可以由用户使用自定义精度的计时函数。
timeit.Timer 有 3 个成员函数:
-
timeit([number=1000000]) :timeit() 执行一次 Timer 构造函数中的 setup 语句之后,就重复执行 number 次 stmt 语句,然后返回总计运行消耗的时间;
-
repeat([repeat=3[, number=1000000]]) :repeat() 函数以 number 为参数调用 timeit 函数 repeat 次,并返回总计运行消耗的时间;
-
print_exc([file=None]) :print_exec() 函数以代替标准的 tracback,原因在于 print_exec() 会输出错行的源代码。
除了可以使用 timeit 的编程接口外,也可以在命令行里使用 timeit,非常方便:
python -m timeit [-n N] [-r N] [-s S] [-t] [-c] [-h] [statement ...]其中参数的定义如下:
-
-n N/--number=N,statement 语句执行的次数
-
-r N/--repeat=N,重复多少次调用 timeit(),默认为 3
-
-s S/--setup=S,用以设置 statement 执行环境的语句,默认为 "pass"
-
-t/--time,计时函数,除了 Windows 平台外默认使用 time.time() 函数
-
-c/--clock,计时函数,Windows 平台默认使用 time.clock() 函数
-
-v/--verbose,输出更大精度的计时数值
-
-h/--help,简单的使用帮助
厉害:
python -m timeit "[].append(1)" 10000000 loops, best of 3: 0.116 usec per loop建议 82:使用 memory_profiler 和 objgraph 剖析内存使用
Python 还提供了一些工具可以用来查看内存的使用情况以及追踪内存泄漏(如 memory_profiler、objgraph、cProfile、PySizer 及 Heapy 等),或者可视化地显示对象之间的引用(如 objgraph),从而为发现内存问题提供更直接的证据。我们来看看memory_profiler、objgraph两个工具的使用。
-
memory_profiler:在需要进行内存分析的代码之前用 @profile 进行装饰,然后运行命令 python -m memory_profiler 文件名 ,便可以输出每一行代码的内存使用以及增长情况。
-
Objgraph:
-
安装:pip install objgraph
-
功能分类:
-
统计,如 objgraph.count(typename[, objects]) 表示根据传入的参数显示被 gc 跟踪的对象的数目;objgraph.show_most_common_types([limit=10, objects]) 表示显示常用类型对应的对象的数目
-
定位和过滤对象,如 objgraph.by_type(typename[, objects]) 表示根据传入的参数显示被 gc 跟踪的对象信息;objgraph.at(addr) 表示根据给定的地址返回对象
-
遍历和显示对象图。如 objgraph.show_refs(objs[, max_depth=3, extra_ignore=(), filter=None, too_many=10, highlight=None, filename=None, extra_info=None, refcounts=False]) 表示从对象 objs 开始显示对象引用关系图;objgraph.show_backrefs(objs[, max_depth=3, extra_ignore=(), filter=None, too_many=10, highlight=None, filename=None, extra_info=None, refcounts=False]) 表示显示以 objs 的引用作为结束的对象关系图。
-
-
例子:
-
生成对象x的引用关系图:
>>> import objgraph >>> x = ['a', '1', [2, 3]] >>> objgraph.show_refs([x], filename="test.png")-
显示常用类型不同类型对象的数目,限制输出前3行:
>>> objgraph.show_most_common_types(limit=3) wrapper_descriptor 1031 function 975 builtin_function_or_method 615 -
-
建议 83:努力降低算法复杂度
时间复杂度:
O(1) < O(log * n) < O(n) < O(n log n) < O(n^2) < O(c^n) < O(n!) < O(n^n)
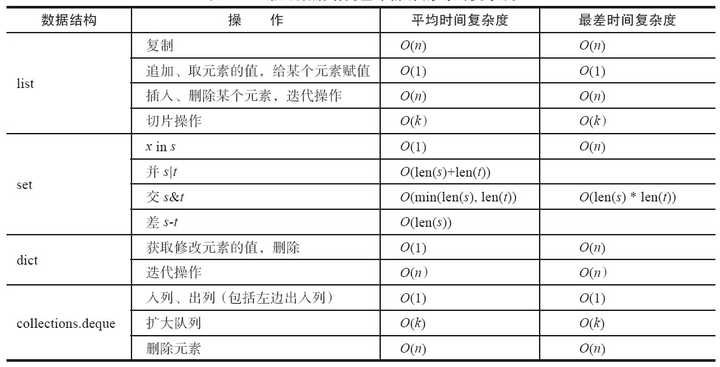
常见数据结构基本操作时间复杂度:
![]()
建议 84:掌握循环优化的基本技巧
循环的优化应遵循的原则是尽量减少循环过程中的计算量,多重循环的情形下尽量将内层的计算提到上一层。 1.减少循环内部的计算: # 每次循环都要重新计算 for i in range(iter): d = math.sqrt(y) j += i * d # 高效率 d = math.sqrt(y) for i in range(iter): j += i * d 2.将显式循环改为隐式循环:n * (n + 1) / 2,不必使用for循环计算,但要注意可读性 3.在循环中尽量引用局部变量,在命名空间中局部变量优先搜索,因此局部变量的查询会比全局变量要快,当在循环中需要多次引用某一个变量的时候,尽量将其转换为局部变量:
# 示例一 x = [10, 34, 56, 78] def f(x): for i in range(len(x)): x[i] = math.sin(x[i]) return x # 示例二 def g(x): loc_sin = math.sin for i in range(len(x)): x[i] = loc_sin(x[i]) return x # 示例二比示例一性能更佳
-
4.关注内层嵌套循环,尽量将内层循环的计算往上层移:
# 示例一 for i in range(len(v1)): for j in range(len(v2)): x = v1[i] + v2[j] # 示例二 for i in range(len(v1)): v1i = v1[i] for j in range(len(v2)): x = v1i + v2[j]
建议 85:使用生成器提高效率
放一张图来理解,来自这里
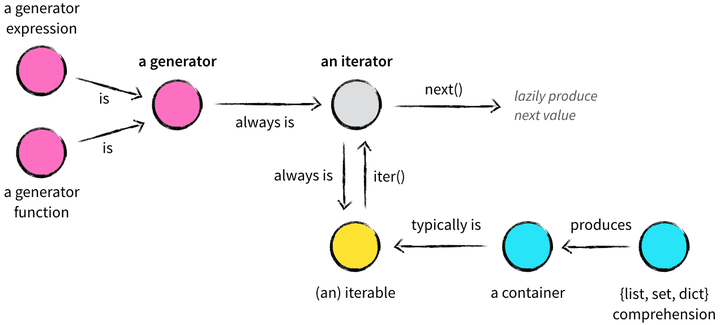
实际上当需要在循环过程中依次处理一个序列中的元素的时候,就应该考虑生成器。
当解释器执行遇到 yield 的时候,函数会自动返回 yield 语句之后的表达式的值。不过与 return 不同的是,yield 语句在返回的同时会保存所有的局部变量以及现场信息,以便在迭代器调用 next() 或 send() 方法的时候还原,而不是直接交给垃圾回收器(return() 方法返回后这些信息会被垃圾回收器处理)。
这样就能够保证对生成器的每一次迭代都会返回一个元素,而不是一次性在内存中生成所有的元素。自 Python2.5 开始,yield 语句变为表达式,可以直接将其值赋给其他变量。
生成器的优点总体来说有如下几条:
-
生成器提供了一种更为便利的产生迭代器的方式,用户一般不需要自己实现 __iter__ 和 next 方法,它默认返回一个迭代器
-
代码更为简洁优雅
-
充分利用了延迟评估(Lazy evaluation)的特性,仅在需要的时候才产生对应的元素,而不是一次生成所有的元素,从而节省了内存空间,提高了效率,理论上无限循环成为了可能
-
使得协同程序更为容易实现。协同程序是有多个进入点,可以挂起恢复的函数,这基本就是 yield 的工作方式。Python2.5 之后生成器的功能更完善,加入了 send()、close() 和 throw() 方法。其中 send() 不仅可以传递值给 yield 语句,而且能够恢复生成器,因此生成器能大大简化协同程序的实现。
建议 86:使用不同的数据结构优化性能
如果 Python 中的查找、排序算法已经优化到极限,比如sort()使用 key 参数比使用cmp参数性能更高;那么首先应该考虑使用不同的数据结构优化性能。
list,它的内存管理类似 C++ 的 std::vector,即预先分配一定数量的”车位“,当预分配的内存用完时,又继续往里面插入元素,会启动新一轮的内存分配。
list 对象会根据内存增长算法申请一块更大的内存,然后将原有的所有元素拷贝过去,销毁之前的内存,再插入新元素。当删除元素时,也是类似,删除后发现已用空间比预分配空间的一半还少时,list 会另外申请一块小内存,再做一次元素拷贝,然后销毁原有的大内存。可见,如果 list 对象经常有元素数量的“巨变”,比如增加、删除得很频繁,那么应当考虑使用 deque。
deque 就是双端队列,同时具备栈和队列的特性,能够提供在两端插入和删除时复杂度为 O(1) 的操作。相对于 list,它最大的优势在于内存管理方面。如果不熟悉 C++ 的 std::deque,可以把 deque 想象为多个 list 连在一起,它的每一个 list 也可以存储多个元素。它的优势在于插入时,已有空间已经用完,那么它会申请一个新的内存空间来容纳新的元素,并将其与已有的其他内存空间串接起来,从而避免元素拷贝;在删除元素时也类似,无需移动元素。所以当元素数量巨变时,它的性能比 list 要好上许多倍。
对于 list 这种序列容器来说,除了 pop(0) 和 insert(0, v) 这种插入操作非常耗时之外,查找一元素是否在其中,也是 O(n) 的线性复杂度。在 C 语言中,标准库函数 bsearch() 能够通过二分查找算法在有序队列中快速查找是否存在某一元素。在 Python 中,对保持 list 对象有序以及在有序队列中查找元素有非常好的支持,这是通过标准库 bisect 来实现的。
bisect 并没有实现一种新的“数据结构”,其实它是用来维护“有序列表”的一组函数,可以兼容所有能够随机存取的序列容器,比如 list。它可使在有序列表中查找某一元素变得非常简单。
def index(a, x):
i = bisect_left(a, x)
if i != len(a) and a[i] == x:
return i
raise ValueError
保持列表有序需要付出额外的维护工作,但如果业务需要在元素较多的列表中频繁查找某些元素是否存在或者需要频繁地有序访问这些元素,使用 bisect 则相当值得。
对于序列容器,除了插入、删除、查找之外,还有一种很常见的需求是获取其中的极大值或极小值元素,比如在查找最短路径的A*算法中就需要在Open表中快速找到预估值最小的元素。这时候,可以使用 heapq 模块。类似 bisect,heapq 也是维护列表的一组函数,其中 heapify() 的作用是把一个序列容器转化为一个堆。
In [1]: import heapq
In [2]: import random
In [3]: alist = [random.randint(0, 100) for i in range(10)]
In [4]: alist
Out[4]: [62, 72, 18, 55, 86, 26, 88, 21, 4, 97]
In [5]: heapq.heapify(alist)
In [6]: alist
Out[6]: [4, 21, 18, 55, 86, 26, 88, 72, 62, 97]
可以看到,转化为堆后,alist 的第一个元素 alist[0] 是整个列表中最小的元素,heapq 将保证这一点,从而保证从列表中获取最小值元素的时间复杂度是 O(1)。
In [7]: heapq.heappop(alist)
Out[7]: 4
In [8]: alist
Out[8]: [18, 21, 26, 55, 86, 97, 88, 72, 62]
除了通过 heapify() 函数将一个列表转换为堆之外,也可以通过 heappush()、heappop() 函数插入、删除元素,针对常见的先插入新元素再获取最小元素、先获取最小元素再插入新元素的需求,还有 heappushpop(heap, item) 和 heapreplace(heap, item) 函数可以快速完成。另外可以看出,每次元素增减之后的序列变化很大,所以千万不要乱用 heapq,以免带来性能问题。
heapq 还有 3 个通用函数值得介绍,其中 merge() 能够把多个有序列表归并为一个有序列表(返回迭代器,不占用内存),而 nlargest() 和 nsmallest() 类似于 C++ 中的 std::nth_element(),能够返回无序列表中最大或最小的 n 个元素,并且性能比 sorted(iterable, key=key)[:n] 要高。
除了对容器的操作可能会出现性能问题外,容器中存储的元素也有很大的优化空间,这是因为在很多业务中,容器存储的元素往往是同一类型的,比如都是整数,而且整数的取值范围也确定,此时就可以用 array 优化程序性能。
array 实例化的时候需要指定其存储的元素类型,如c,表示存储的每个人元素都相当于C语言中的 char 类型,占用内存大小为 1 字节。
以下是正文:
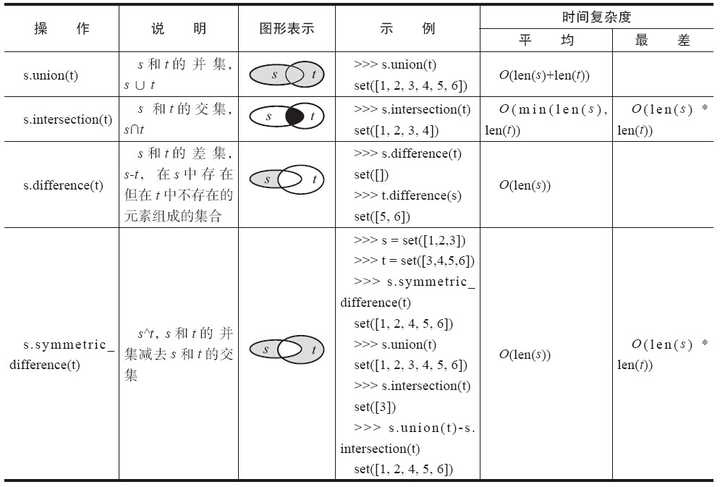
建议 87:充分利用 set 的优势
Python 中集合是通过 Hash 算法实现的无序不重复的元素集。
我们来做一些测试:
$ python -m timeit -n 1000 "[x for x in range(1000) if x in range(600, 1000)]"
1000 loops, best of 3: 6.44 msec per loop
$ python -m timeit -n 1000 "set(range(100)).intersection(range(60, 100))"
1000 loops, best of 3: 9.18 usec per loop
实际上 set 的 union、intersection、difference 等操作要比 list 的迭代要快。因此如果涉及求 list 交集、并集或者差等问题可以转换为 set 来操作。
建议 88:使用 multiprocess 克服 GIL 的缺陷
多进程 Multiprocess 是 Python 中的多进程管理包,在 Python2.6 版本中引进的,主要用来帮助处理进程的创建以及它们之间的通信和相互协调。它主要解决了两个问题:一是尽量缩小平台之间的差异,提供高层次的 API 从而使得使用者忽略底层 IPC 的问题;二是提供对复杂对象的共享支持,支持本地和远程并发。
类 Process 是 multiprocess 中较为重要的一个类,用户创建进程,其构造函数如下:
Process([group[, target[, name[, args[, kwargs]]]]])
其中,参数 target 表示可调用对象;args 表示调用对象的位置参数元组;kwargs 表示调用对象的字典;name 为进程的名称;group 一般设置为 None。该类提供的方法与属性基本上与 threading.Thread 一致,包括 is_alive()、join([timeout])、run()、start()、terminate()、daemon(要通过 start() 设置)、exitcode、name、pid 等。
不同于线程,每个进程都有其独立的地址空间,进程间的数据空间也相互独立,因此进程之间数据的共享和传递不如线程来得方便。庆幸的是 multiprocess 模块中都提供了相应的机制:如进程间同步操作原语 Lock、Event、Condition、Semaphore,传统的管道通信机制 pipe 以及队列 Queue,用于共享资源的 multiprocess.Value 和 multiprocess.Array 以及 Manager 等。
Multiprocessing 模块在使用上需要注意以下几个要点:
-
进程之间的的通信优先考虑 Pipe 和 Queue,而不是 Lock、Event、Condition、Semaphore 等同步原语。进程中的类 Queue 使用 pipe 和一些 locks、semaphores 原语来实现,是进程安全的。该类的构造函数返回一个进程的共享队列,其支持的方法和线程中的 Queue 基本类似,除了方法 task_done()和 join() 是在其子类 JoinableQueue 中实现的以外。需要注意的是,由于底层使用 pipe 来实现,使用 Queue 进行进程之间的通信的时候,传输的对象必须是可以序列化的,否则 put 操作会导致 PicklingError。此外,为了提供 put 方法的超时控制,Queue 并不是直接将对象写到管道中而是先写到一个本地的缓存中,再将其从缓存中放入 pipe 中,内部有个专门的线程 feeder 负责这项工作。由于 feeder 的存在,Queue 还提供了以下特殊方法来处理进程退出时缓存中仍然存在数据的问题。
-
close():表明不再存放数据到 queue 中。一旦所有缓冲的数据刷新到管道,后台线程将退出。
-
join_thread():一般在 close 方法之后使用,它会阻止直到后台线程退出,确保所有缓冲区中的数据已经刷新到管道中。
-
cancel_join_thread():需要立即退出当前进程,而无需等待排队的数据刷新到底层管道的时候可以使用该方法,表明无须阻止到后台进程的退出。
Multiprocessing 中还有个 SimpleQueue 队列,它是实现了锁机制的 pipe,内部去掉了 buffer,但没有提供 put 和 get 的超时处理,两个动作都是阻塞的。
除了 multiprocessing.Queue 之外,另一种很重要的通信方式是 multiprocessing.Pipe。它的构造函数为 multiprocess.Pipe([duplex]),其中 duplex 默认为 True,表示为双向管道,否则为单向。它返回一个 Connection 对象的组(conn1, conn2),分别表示管道的两端。Pipe 不支持进程安全,因此当有多个进程同时对管道的一端进行读操作或者写操作的时候可能会导致数据丢失或者损坏。因此在进程通信的时候,如果是超过 2 个以上的线程,可以使用 queue,但对于两个进程之间的通信而言 Pipe 性能更快。
from multiprocessing import Process, Pipe, Queue import time def reader_pipe(pipe): output_p, input_p = pipe # 返回管道的两端 inout_p.close() while True: try: msg = output_p.recv() # 从 pipe 中读取消息 except EOFError: break def writer_pipe(count, input_p): # 写消息到管道中 for i in range(0, count): input_p.send(i) # 发送消息 def reader_queue(queue): # 利用队列来发送消息 while True: msg = queue.get() # 从队列中获取元素 if msg == "DONE": break def writer_queue(count, queue): for ii in range(0, count): queue.put(ii) # 放入消息队列中 queue.put("DONE") if __name__ == "__main__": print("testing for pipe:") for count in [10 ** 3, 10 ** 4, 10 ** 5]: output_p, input_p = Pipe() reader_p = Process(target=reader_pipe, args=((output_p, input_p),)) reader_p.start() # 启动进程 output_p.close() _start = time.time() writer_pipe(count, input_p) # 写消息到管道中 input_p.close() reader_p.join() # 等待进程处理完毕 print("Sending {} numbers to Pipe() took {} seconds".format(count, (time.time() - _start))) print("testsing for queue:") for count in [10 ** 3, 10 ** 4, 10 ** 5]: queue = Queue() # 利用 queue 进行通信 reader_p = Process(target=reader_queue, args=((queue),)) reader_p.daemon = True reader_p.start() _start = time.time() writer_queue(count, queue) # 写消息到 queue 中 reader_p.join() print("Seding {} numbers to Queue() took {} seconds".format(count, (time.time() - _start)))上面代码分别用来测试两个多线程的情况下使用 pipe 和 queue 进行通信发送相同数据的时候的性能,从函数输出可以看出,pipe 所消耗的时间较小,性能更好。
-
-
尽量避免资源共享。相比于线程,进程之间资源共享的开销较大,因此要尽量避免资源共享。但如果不可避免,可以通过 multiprocessing.Value 和 multiprocessing.Array 或者 multiprocessing.sharedctpyes 来实现内存共享,也可以通过服务器进程管理器 Manager() 来实现数据和状态的共享。这两种方式各有优势,总体来说共享内存的方式更快,效率更高,但服务器进程管理器 Manager() 使用起来更为方便,并且支持本地和远程内存共享。
# 示例一 import time from multiprocessing import Process, Value def func(val): # 多个进程同时修改 val for i in range(10): time.sleep(0.1) val.value += 1 if __name__ == "__main__": v = Value("i", 0) # 使用 value 来共享内存 processList = [Process(target=func, args=(v,)) for i in range(10)] for p in processList: p.start() for p in processList: p.join() print v.value # 修改 func 函数,真正控制同步访问 def func(val): for i in range(10): time.sleep(0.1) with val.get_lock(): # 仍然需要使用 get_lock 方法来获取锁对象 val.value += 1 # 示例二 import multiprocessing def f(ns): ns.x.append(1) ns.y.append("a") if __name__ == "__main__": manager = multiprocessing.Manager() ns = manager.Namespace() ns.x = [] # manager 内部包括可变对象 ns.y = [] print("before process operation: {}".format(ns)) p = multiprocessing.Process(target=f, args=(ns,)) p.start() p.join() print("after process operation {}".format(ns)) # 修改根本不会生效 # 修改 import multiprocessing def f(ns, x, y): x.append(1) y.append("a") ns.x = x # 将可变对象也作为参数传入 ns.y = y if __name__ == "__main__": manager = multiprocessing.Manager() ns = manager.Namespace() ns.x = [] # manager 内部包括可变对象 ns.y = [] print("before process operation: {}".format(ns)) p = multiprocessing.Process(target=f, args=(ns, ns.x, ns.y)) p.start() p.join() print("after process operation {}".format(ns)) -
注意平台之间的差异。由于 Linux 平台使用 fork() 来创建进程,因此父进程中所有的资源,如数据结构、打开的文件或者数据库的连接都会在子进程中共享,而 Windows 平台中父子进程相对独立,因此为了更好地保持平台的兼容性,最好能够将相关资源对象作为子进程的构造函数的参数传递进去。要避免如下方式:
f = None def child(f): # do something if __name__ == "__main__": f = open(filename, mode) p = Process(target=child) p.start() p.join() # 推荐的方式 def child(f): print(f) if __name__ == "__main__": f = open(filename, mode) p = Process(target=child, args=(f, )) # 将资源对象作为构造函数参数传入 p.start() p.join()需要注意的是,Linux 平台上 multiprocessing 的实现是基于 C 库中的 fork(),所有子进程与父进程的数据是完全相同,因此父进程中所有的资源,如数据结构、打开的文件或者数据库的连接都会在子进程中共享。但 Windows 平台上由于没有 fork() 函数,父子进程相对独立,因此保持了平台的兼容性,最好在脚本中加上 if __name__ == "__main__" 的判断,这样可以避免出现 RuntimeError 或者死锁。
-
尽量避免使用 terminate() 方式终止进程,并且确保 pool.map 中传入的参数是可以序列化的。
import multiprocessing def unwrap_self_f(*args, **kwargs): return calculate.f(*args, **kwargs) # 返回一个对象 class calculate(object): def f(self, x): return x * x def run(self): p = multiprocessing.Pool() return p.map(unwrap_self_f, zip([self] * 3, [1, 2, 3])) if __name__ == "__main__": c1 = calculate() print(c1.run())
建议 89:使用线程池提高效率
我们知道线程的生命周期分为 5 个状态:创建、就绪、运行、阻塞和终止。自线程创建到终止,线程便不断在运行、就绪和阻塞这 3 个状态之间转换直至销毁。而真正占有 CPU 的只有运行、创建和销毁这 3 个状态。一个线程的运行时间由此可以分为 3 部分:线程的启动时间(Ts)、线程体的运行时间(Tr)以及线程的销毁时间(Td)。在多线程处理的情境中,如果线程不能够被重用,就意味着每次创建都需要经过启动、销毁和运行这 3 个过程。这必然会增加系统的相应时间,降低效率。而线程体的运行时间 Tr 不可控制,在这种情况下要提高线程运行的效率,线程池便是一个解决方案。
线程池通过实现创建多个能够执行任务的线程放入池中,所要执行的任务通常被安排在队列中。通常情况下,需要处理的任务比线程的数目要多,线程执行完当前任务后,会从队列中取下一个任务,直到所有的任务已经完成。
由于线程预先被创建并放入线程池中,同时处理完当前任务之后并不销毁而是被安排处理下一个任务,因此能够避免多次创建线程,从而节省线程创建和销毁的开销,带来更好的性能和系统稳定性。线程池技术适合处理突发性大量请求或者需要大量线程来完成任务、但任务实际处理时间较短的应用场景,它能有效避免由于系统中创建线程过多而导致的系统性能负载过大、响应过慢等问题。
Python 中利用线程池有两种解决方案:一是自己实现线程池模式,二是使用线程池模块。
先来看一个线程池模式的简单实现:线程池代码
本段代码偏长,编辑到知乎上始终无法保存,只好贴我的博客地址,各位可转到博客去看。
自行实现线程,需要定义一个 Worker 处理工作请求,定义 WorkerManager 来进行线程池的管理和创建,它包含一个工作请求队列和执行结果队列,具体的下载工作通过 download_file 方法实现。
相比自己实现的线程池模型,使用现成的线程池模块往往更简单。Python 中线程池模块的下载地址。该模块提供了以下基本类和方法:
-
threadpool.ThreadPool:线程池类,主要的作用是用来分派任务请求和收集运行结果。主要有以下方法:
-
__init__(self, num_workers, q_size=0, resq_size=0, poll_timeout=5):建立线程池,并启动对应 num_workers 的线程;q_size 表示任务请求队列的大小,resq_size 表示存放运行结果队列的大小。
-
createWorkers(self, num_workers, poll_timeout=5):将 num_workers 数量对应的线程加入线程池中。
-
dismissWorkers(self, num_workers, do_join=False):告诉 num_workers 数量的工作线程当执行完当前任务后退出
-
joinAllDismissedWorkers(self):在设置为退出的线程上执行 Thread.join
-
putRequest(self, request, block=True, timeout=None):将工作请求放入队列中
-
poll(self, block=False):处理任务队列中新的请求wait(self):阻塞用于等待所有执行结果。注意当所有执行结果返回后,线程池内部的线程并没有销毁,而是在等待新的任务。因此,wait() 之后仍然可以再次调用 pool.putRequests()往其中添加任务
-
-
threadpool.WorkRequest:包含有具体执行方法的工作请求类
-
threadpool.WorkerThread:处理任务的工作线程,主要有 run() 方法以及 dismiss() 方法。
-
makeRequests(callable_, args_list, callback=None, exec_callback=_handle_thread_exception):主要函数,作用是创建具有相同的执行函数但参数不同的一系列工作请求。
再来看一个线程池实现的例子:
import urllib2
import os
import time
import threadpool
def download_file(url):
print("begin download {}".format(url ))
urlhandler = urllib2.urlopen(url)
fname = os.path.basename(url) + ".html"
with open(fname, "wb") as f:
while True:
chunk = urlhandler.read(1024)
if not chunk:
break
f.write(chunk)
urls = ["http://wiki.python.org/moni/WebProgramming",
"https://www.createspace.com/3611970",
"http://wiki.python.org/moin/Documention"]
pool_size = 2
pool = threadpool.ThreadPool(pool_size) # 创建线程池,大小为 2
requests = threadpool.makrRequests(download_file, urls) # 创建工作请求
[pool.putRequest(req) for req in requests]
print("putting request to pool")
pool.putRequest(threadpool.WorkRequest(download_file, args=["http://chrisarndt.de/projects/threadpool/api/",])) # 将具体的请求放入线程池
pool.putRequest(threadpool.WorkRequest(download_file, args=["https://pypi.python.org/pypi/threadpool",]))
pool.poll() # 处理任务队列中的新的请求
pool.wait()
print("destory all threads before exist")
pool.dismissWorkers(pool_size, do_join=True) # 完成后退出
建议 90:使用 C/C++ 模块扩展高性能
Python 具有良好的可扩展性,利用 Python 提供的 API,如宏、类型、函数等,可以让 Python 方便地进行 C/C++ 扩展,从而获得较优的执行性能。所有这些 API 却包含在 Python.h 的头文件中,在编写 C 代码的时候引入该头文件即可。
来看一个简单的例子:
1、先用 C 实现相关函数,实现素数判断,也可以直接使用 C 语言实现相关函数功能后再使用 Python 进行包装。
#include "Python.h"
static PyObject * pr_isprime(PyObject, *self, PyObject * args) {
int n, num;
if (!PyArg_ParseTuple(args, "i", &num)) // 解析参数
return NULL;
if (num < 1) {
return Py_BuildValue("i", 0); // C 类型的数据结构转换成 Python 对象
}
n = num - 1;
while (n > 1) {
if (num % n == 0) {
return Py_BuildValue("i", 0);
n--;
}
}
return Py_BuildValue("i", 1);
}
static PyMethodDef PrMethods[] = {
{"isPrime", pr_isprime, METH_VARARGS, "check if an input number is prime or not."},
{NULL, NULL, 0, NULL}
};
void initpr(void) {
(void) Py_InitModule("pr", PrMethods);
}
上面的代码包含以下 3 部分:
-
导出函数:C 模块对外暴露的接口函数 pr_isprime,带有 self 和 args 两个参数,其中参数 args 中包含了 Python 解释器要传递给 C 函数的所有参数,通常使用函数 PyArg_ParseTuple() 来获得这些参数值
-
初始化函数:以便 Python 解释器能够对模块进行正确的初始化,初始化时要以 init 开头,如 initp
-
方法列表:提供给外部的 Python 程序使用的一个 C 模块函数名称映射表 PrMethods。它是一个 PyMethodDef 结构体,其中成员依次表示方法名、导出函数、参数传递方式和方法描述。看下面的例子:
struct PyMethodDef {
char * m1_name; // 方法名
PyCFunction m1_meth; // 导出函数
int m1_flags; // 参数传递方法
char * m1_doc; // 方法描述
}
参数传递方法一般设置为 METH_VARARGS,如果想传入关键字参数,则可以将其与 METH_KEYWORDS 进行或运算。若不想接受任何参数,则可以将其设置为 METH_NOARGS。该结构体必须与 {NULL, NULL, 0, NULL} 所表示的一条空记录来结尾。
2、编写 setup.py 脚本。
from distutils.core import setup, Extension
module = Extension("pr", sources=["testextend.c"])
setup(name="Pr test", version="1.0", ext_modules=[module])
3、使用 python setup.py build 进行编译,系统会在当前目录下生成一个 build 子目录,里面包含 pr.so 和 pr.o 文件。
4、将生成的文件 py.so 复制到 Python 的 site_packages 目录下,或者将 pr.so 所在目录的路径添加到 sys.path 中,就可以使用 C 扩展的模块了。
更多关于 C 模块扩展的内容请读者参考 。
建议 91:使用 Cython 编写扩展模块
Python-API 让大家可以方便地使用 C/C++ 编写扩展模块,从而通过重写应用中的瓶颈代码获得性能提升。但是,这种方式仍然有几个问题:
-
掌握 C/C++ 编程语言、工具链有巨大的学习成本
-
即便是 C/C++ 熟手,重写代码也有非常多的工作,比如编写特定数据结构、算法的 C/C++ 版本,费时费力还容易出错
所以整个 Python 社区都在努力实现一个 ”编译器“,它可以把 Python 代码直接编译成等价的 C/C++ 代码,从而获得性能提升,如 Pyrex、Py2C 和 Cython 等。而从 Pyrex 发展而来的 Cython 是其中的集大成者。
Cython 通过给 Python 代码增加类型声明和直接调用 C 函数,使得从 Python 代码中转换的 C 代码能够有非常高的执行效率。它的优势在于它几乎支持全部 Python 特性,也就是说,基本上所有的 Python 代码都是有效的 Cython 代码,这使得将 Cython 技术引入项目的成本降到最低。除此之外,Cython 支持使用 decorator 语法声明类型,甚至支持专门的类型声明文件,以使原有的 Python 代码能够继续保持独立,这些特性都使得它得到广泛应用,比如 PyAMF、PyYAML 等库都使用它编写自己的高效率版本。
# 安装
$ pip install -U cython
# 生成 .c 文件
$ cython arithmetic.py
# 提交编译器
$ gcc -shared -pthread -fPIC -fwrapv -02 -Wall -fno-strict-aliasing -I /usr/include/python2.7 -o arithmetic.so arithmetic.c
# 这时生成了 arithmetic.so 文件
# 我们就可以像 import 普通模块一样使用它
每一次都需要编译、等待有点麻烦,所以 Cython 很体贴地提供了无需显式编译的方案:pyximport。只要将原有的 Python 代码后缀名从 .py 改为 .pyx 即可。
$ cp arithmetic.py arithmetic.pyx
$ cd ~
$ python
>>> import pyximport; pyximport.install()
>>> import arithmetic
>>> arithmetic.__file__
从 __file__ 属性可以看出,这个 .pyx 文件已经被编译链接为共享库了,pyximport 的确方便啊!
接下来我们看看 Cython 是如何提升性能的。
在 GIS 中,经常需要计算地球表面上两点之间的距离:
import math
def great_circle(lon1, lat1, lon2, lat2):
radius = 3956 # miles
x = math.pi / 180.0
a = (90.0 - lat1) * (x)
b = (90.0 - lat2) * (x)
theta = (lon2 - lon1) * (x)
c = math.acos(math.cos(a) * math.cos(b)) + (math.sin(a) * math.sin(b) * math.cos(theta))
return radius * c
接下来尝试 Cython 进行改写:
import math
def great_circle(float lon1, float lat1, float lon2, float lat2):
cdef float radius = 3956.0
cdef float pi = 3.14159265
cdef float x = pi / 180.0
cdef float a, b, theta, c
a = (90.0 - lat1) * (x)
b = (90.0 - lat2) * (x)
theta = (lon2 - lon1) * (x)
c = math.acos(math.cos(a) * math.cos(b)) + (math.sin(a) * math.sin(b) * math.cos(theta))
return radius * c
通过给 great_circle 函数的参数、中间变量增加类型声明,Cython 代码业务逻辑代码一行没改。使用 timeit 库可以测定提速将近 2 成,说明类型声明对性能提升非常有帮助。这时候,还有一个性能瓶颈,调用的 math 库是一个 Python 库,性能较差,可以直接调用 C 函数来解决:
cdef extern from "math.h":
float cosf(float theta)
float sinf(float theta)
float acosf(float theta)
def greate_circle(float lon1, float lat1, float lon2, float lat2):
cdef float radius = 3956.0
cdef float pi = 3.14159265
cdef float x = pi / 180.0
cdef float a, b, theta, c
a = (90.0 - lat1) * (x)
b = (90.0 - lat2) * (x)
theta = (lon2 - lon1) * (x)
c = acosf((cosf(a) * cosf(b)) + (sinf(a) * sinf(b) * cosf(theta)))
return radius * c
Cython 使用 cdef extern from 语法,将 math.h 这个 C 语言库头文件里声明的 cofs、sinf、acosf 等函数导入代码中。因为减少了 Python 函数调用和调用时产生的类型转换开销,使用 timeit 测试这个版本的代码性能提升了 5 倍有余。
通过这个例子,可以掌握 Cython 的两大技能:类型声明和直接调用 C 函数。比起直接使用 C/C++ 编写扩展模块,使用 Cython 的方法方便得多。
除了使用 Cython 编写扩展模块提升性能之外,Cython 也可以用来把之前编写的 C/C++ 代码封装成 .so 模块给 Python 调用(类似 boost.python/SWIG 的功能),Cython 社区已经开发了许多自动化工具。
如果觉得可以推荐大家去阅读原书,《编写高质量代码 改善 Python 程序的 91 个建议》
同时给大家推荐两本 Python 进阶书籍,也是我正在啃读的:
- Python 核心编程(第三版)
- Fluent Python (只找到英文版,读起来很吃力,但收获很大!)
posted on 2014-04-11 19:54 myworldworld 阅读(558) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号