记录一次缓存系统的优化过程
系统介绍:
之前线上跑着一个索引系统,该索引系统主要功能将数据库的数据取出来构建成一个大的反向索引对象,存储在本地cache中,然后供业务方进行查询使用。该系统主要分为两大模块,一个为controller,一个为server。controller主要负责数据的更新操作,当数据更新后,广播消息通知server并发送一个版本号newVersion(假设为newVersion=10)。server收到消息后,会获取Redis的当前索引对应的版本号curVersion,如果newVersion>curVersion,那么则说明需要重建索引,就会先加锁(避免多台同时构建),然后加载数据并构建索引,再将索引对象以及最新的版本号存储到redis,更新本地cache中的索引对象,最后释放锁,如果加锁失败(说明有其他的机器在构建索引了),则等待一段时间之后再重新获取curVersion并newVersion比较。当newVersion<=curVersion,则直接从缓存中加载索引,更新到本地cache中
问题:
某天忽然有一台server服务器出现了OOM异常,感觉很奇怪,通过使用jmap导出了堆信息,并通过MAT分析发现,索引上有两个对象引用的大小是一样的,查看代码发现,原来在构建索引对象时,为了使用方便,将一个对象赋值给了两个引用,这种方式,在内存中是占用一份数据的大小,不会有问题。然后序列化之后,再反序列化回来,就不是同一个对象了,在内存中就会占用两份数据,这样就会导致数据大小扩大了许多
改进:
找到了问题,就很好处理了,将重复的那个引用去掉,内存占用立马少了600多M
继续改进:
由于索引数据中的很多字符串相同的,都是城市名字,但是对象从redis中取出来是通过反序列化实现的,无法使用inter()的方法来减少内存的占用。后来在网上查到如果是G1垃圾收集器的话,可以使用-XX:+UseStringDeduplication来进行字符串排重,以下是排重后的效果图,大概可以看出char数组由原来的429M减少到了82M多,注意UseStringDeduplication只会减少char数组的量
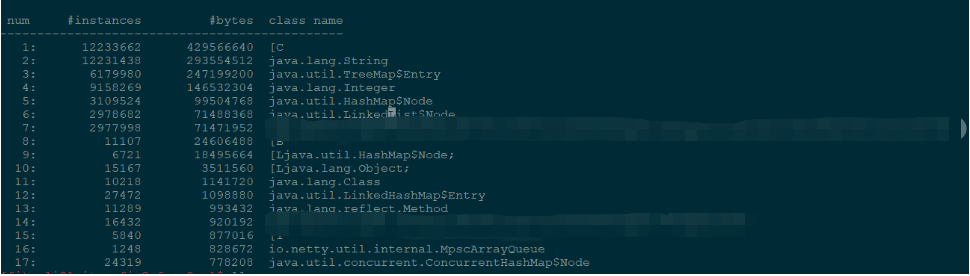
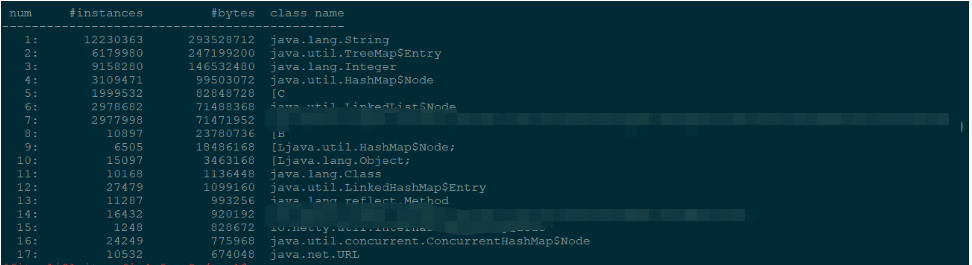
关于-XX:+UseStringDeduplication
在应用程序启动期间传递此JVM参数时,JVM将尝试在垃圾收集过程中消除重复的字符串。在垃圾收集过程中,JVM会检查内存中的所有对象,因此作为该过程的一部分,它会尝试识别它们中的重复字符串并尝试消除它。
'-XX:+ UseStringDeduplication'消除了较长时间内存在的重复字符串,对JavaWeb应用程序进行的真实案例研究,当使用'-XX:+ UseStringDeduplication'时,该应用程序没有显示任何内存缓解。但是,如果您的应用程序有很多缓存,那么'-XX:+ UseStringDeduplication'可能是有价值的(因为缓存对象通常往往是长期存在的对象)
'-XX:+ UseStringDeduplication'不会消除重复的字符串对象本身。它只替换了底层的char []。对String对象进行重复数据删除在概念上只是对value字段的重新赋值,即aString.value = anotherString.value。
注意:改参数只支持JDK8U20之后,垃圾收集是G1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号