
『论文笔记』Exploiting Visual Semantic Reasoning for Video-Text Retrieval
https://arxiv.org/pdf/2006.08889.pdf
关键问题:
视频文本检索领域没有重视帧内语义的信息进行帧级别的特征提取,本文利用帧内语义来推进帧级别的特征提取。
Previous works have been devoted to representing videos by directly encoding from frame-level features.
关键在于:利用目标检测来确定帧内对象及其之间的相关建图,利用GCN得到进行帧特征提取。
After sampling frames, our model detects frame regions by bottom-up attention [Anderson et al., 2018] and extract region features. In this way, each frame can be represented by several regions. Specifically, the bottom-up attention module is implemented with Faster RCNN [Ren et al., 2015] pre-trained on Visual Genome [Krishna et al., 2017], an image region relation annotated dataset.
除此之外作者在GCN中引入随机游走策略(统计量),加强了推理能力。
The random walks are a rule for vertices to access their neighbors. The transition probability is determined by the weights of edges.
方法介绍:
We utilize the bottom-up attention model to generate frame regions and extract features from frames (Sec. 3.1).
For the regions, we construct a graph to model semantic correlations (Sec. 3.2).
Subsequently, we do semantic reasoning between these regions by leveraging random walk rule based Graph Convolutional Networks (GCN) to generate region features with relation information (Sec. 3.3).
Finally, video and text features are generated, and the whole model is trained with common space learning (Sec. 3.4).
对某帧内的对象相关度(semantic relations),计算公式如下,其中每一帧提取n个对象,每个对象使用d维特征(pool5):
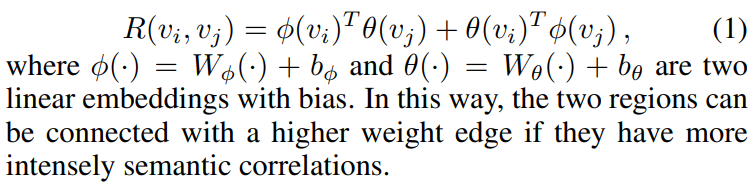
图卷积部分公式太多,没太整明白,看原文吧。



相似度计算采取了3元组损失:

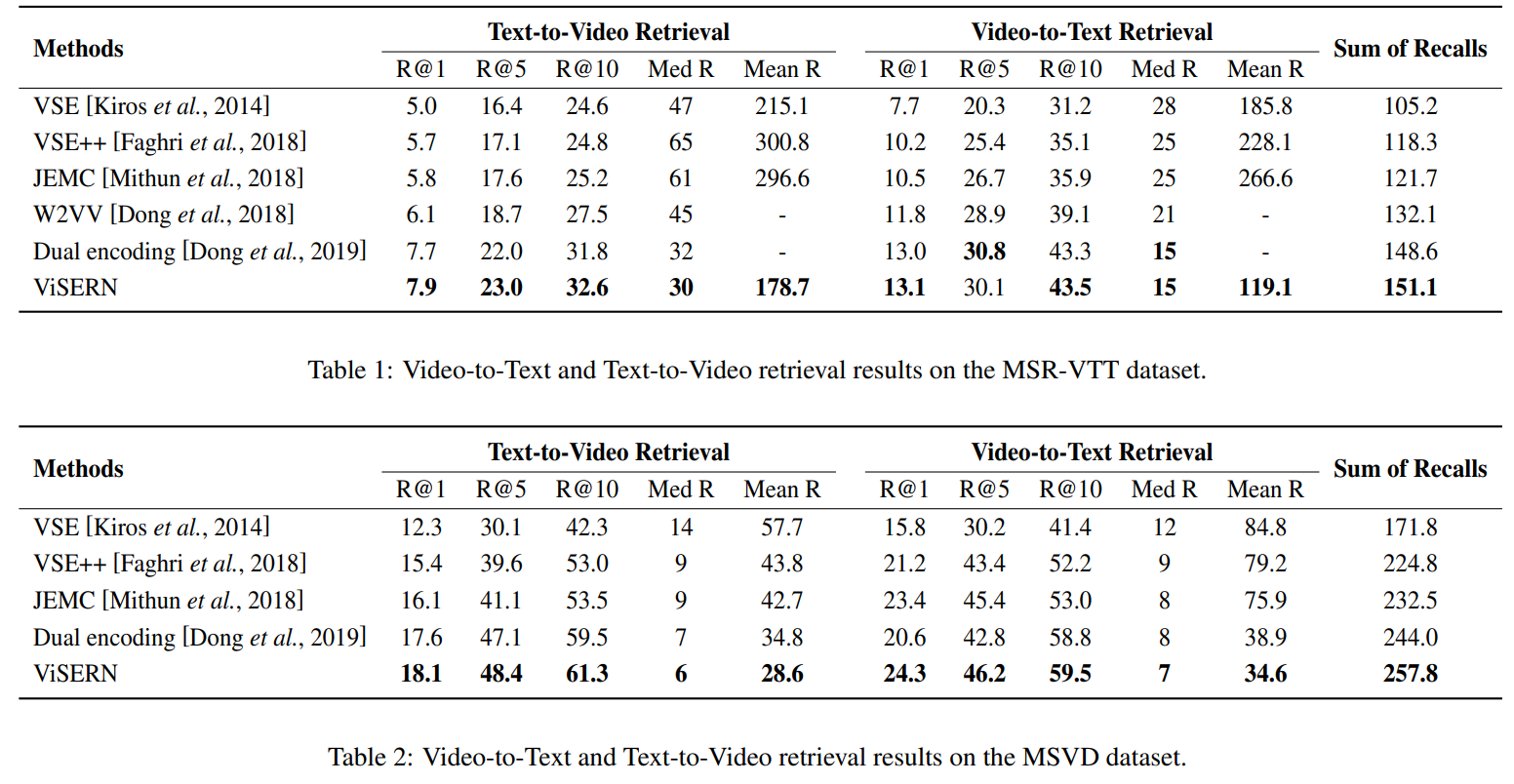
实验效果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号