Hadoop日常运维问题汇总
一:namenode出现missing blocks
日常巡检CDH集群和HDP集群发现有些namenode下有很多missing blocks ,hadoop数据存储单位为块。一块64M,这些Missing大多因为元数据丢失而毁坏,很难恢复。就行硬盘故障一样,需要fsck并且delete。
CDH集群 :Cloudera manager的dashboard----HDFS----NameNode Web UI 如图:
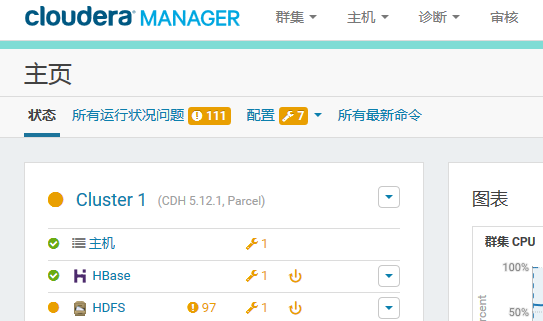 -----
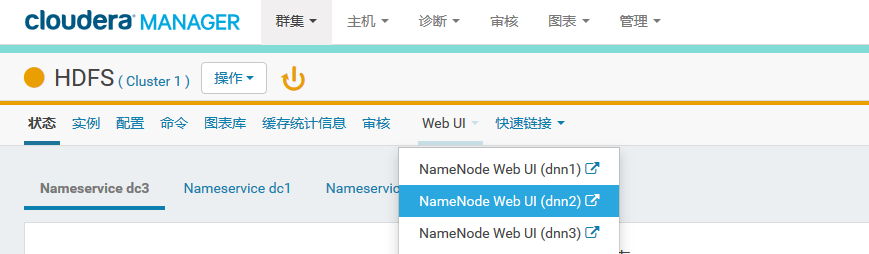
-----
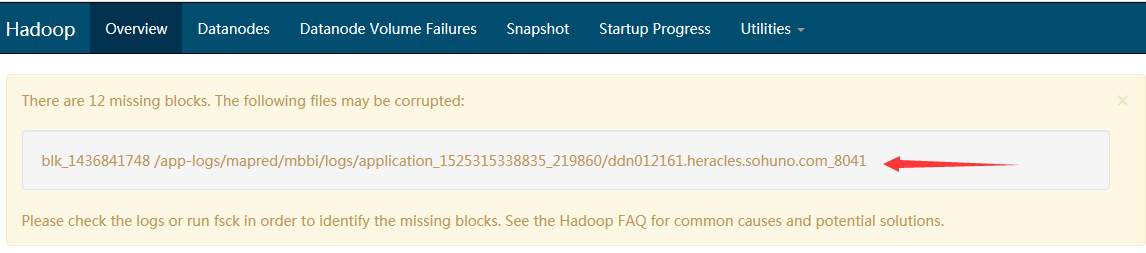
HDP集群:Ambari Server 的dashboard---HDFS Links---NameNode UI 如图
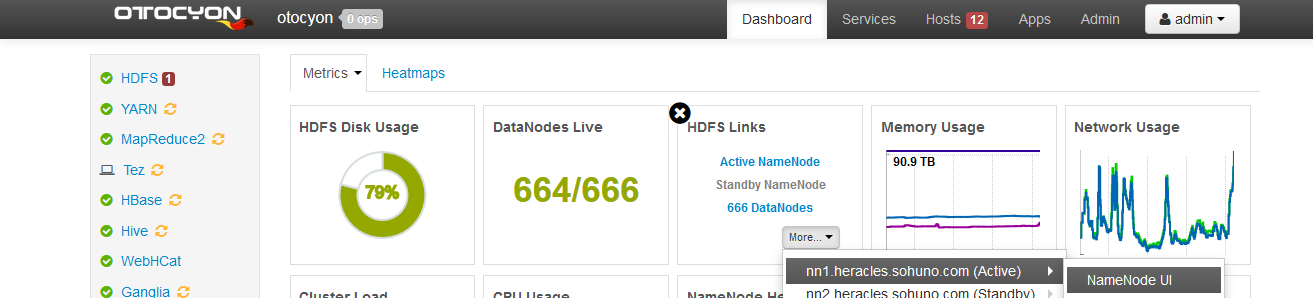
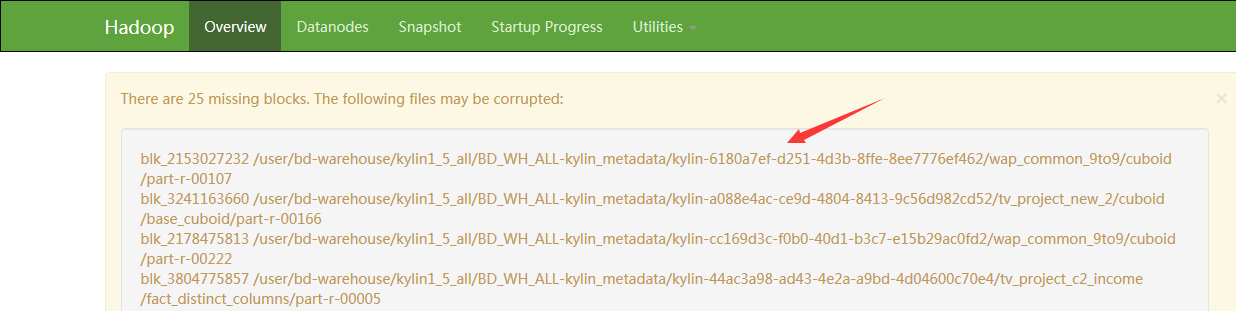
清理Missing blocks步骤:登录到console中控机,su hdfs 切换至hadoop集群管理用户
hdfs fsck /blocks-path/ 查看文件系统cluster,如:
hdfs fsck -fs hdfs://dc(n) /block-path/ 指定集群
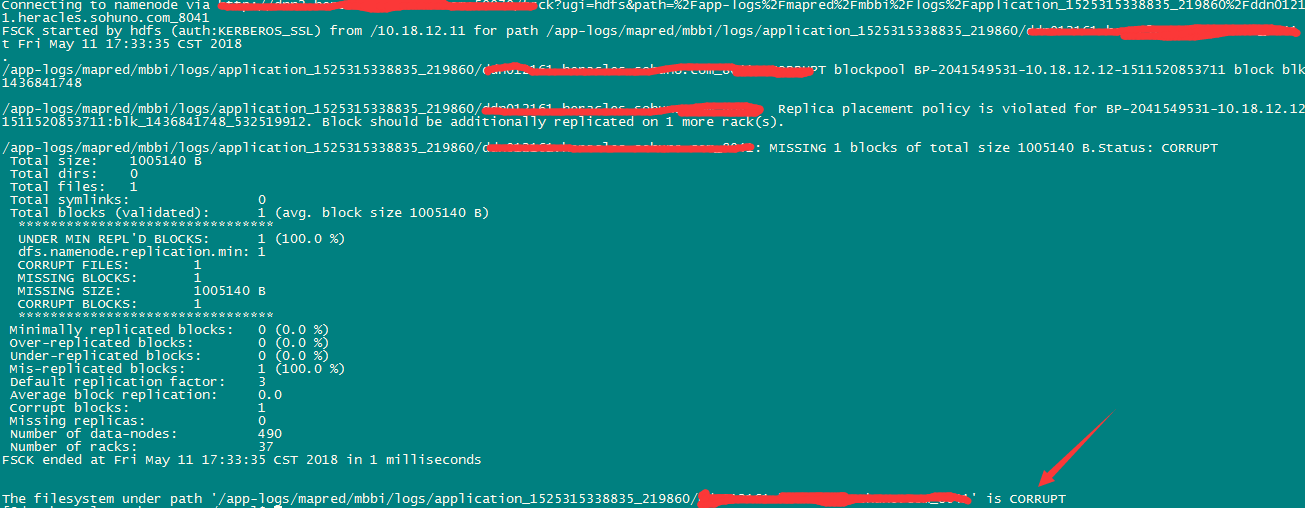
hdfs fsck -fs hdfs://dc /block-path/ -delete 如果上步元数据已损坏,则直接清理。
例: hdfs fsck /app-logs/mapred/mbbi/logs/application_1525315338835_219860/10.11.12.161
hdfs fsck -fs hdfs://dc1 /app-logs/mapred/mbbi/logs/application_1525315338835_219860/10.11.12.161
hdfs fsck -fs hdfs://dc1 /app-logs/mapred/mbbi/logs/application_1525315338835_219860/10.11.12.161 -delete
二: Spark on Yarn 查看任务日志及状态
1、根据application ID查看某个job的日志
yarn logs -applicationId application_1525315338835_7483
2、查看某个job的状态
yarn application -status application_1525315338835_7483
3、kill掉某个job(完全停止该job的执行,如果直接在Web上kill实际还会继续运行)
yarn application -kill application_1525315338835_7483
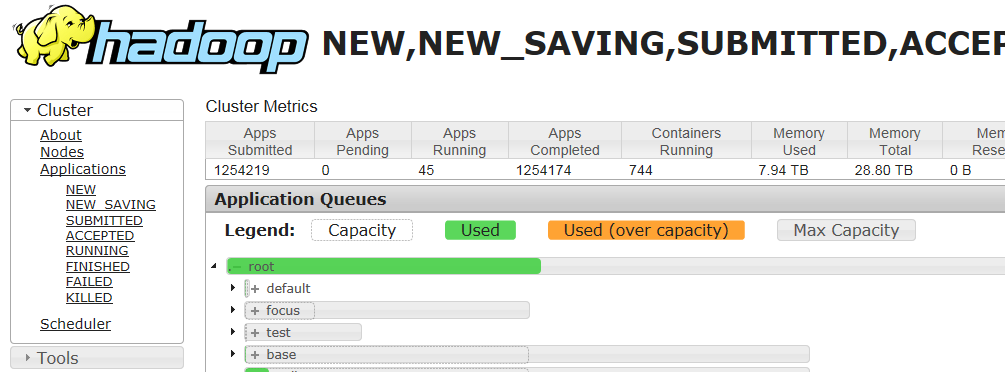
也可以通过 http://ip:8088/cluster/scheduler/ 查看,在此Web界面可通过applicationId查看任务状态和日志。
三:Hadoop集群用户磁盘配额管理
1.hdfs是hadoop集群的管理用户,所以首先应该登陆集群console并且su切换到hdfs用户
2.磁盘配额分为磁盘目录文件数配额和磁盘空间配额。以msns用户、1000000文件数、100T的配额空间为例:
磁盘目录文件数配额:hdfs dfsadmin -setQuota 1000000 /user/msns
磁盘空间配额:hdfs dfsadmin -setSpaceQuota 100t /user/msns
3.查看磁盘已有配额信息:
hadoop fs -count -q /user/msns
文件数限额 可用文件数 空间配额 可用空间 目录数 文件数 总大小 文件/目录名

清空文件数配额:hdfs dfsadmin -clrQuota /user/msns
清空磁盘空间配额:hdfs dfsadmin -clrSpaceQuota /user/msns
***5.注意这里的空间配额是把副本容量也算入的,也就是所我们这里的配额控制的是file_size x replications。即,如果我们要为msns用户设置100T的实际可用空间,副本因子为3(一般为3),那么就需要用上面的命令配置300T的空间配额。文件数配额也类似。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号