
MYSQL20天魔鬼入门训练!
目录
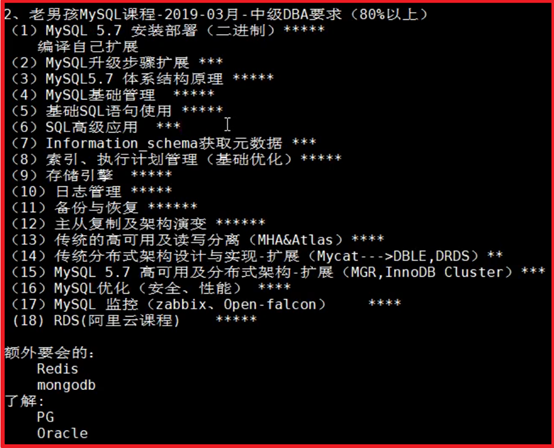
P1- 老男孩MySQL-2019年3月中级DBA必备要求 6
P3- 数据库管理系统-DBMS(RDBMS+NoSQL) 7
P14- MySQL基础管理-权限管理及数据库远程连接 12
P28- MySQL-SQL基础-DML-insert语句 20
P29- MySQL-SQL基础-DML-update、delete语句 20
P30- MySQL-SQL基础-DQL-select语句 20
P31- MySQL-SQL基础-DQL-where语句 21
P32- MySQL-SQL基础-DQL-group by语句 21
P34- MySQL-SQL基础-DQL-order by语句 21
P36- MySQL-SQL基础-DQL-学生管理系统构建 22
P39- MySQL-SQL基础- information_schema视图库(虚拟库) 22
P41- MySQL-SQL基础- show命令基本介绍 24
P65- MySQL-Innodb存储引擎-事务生命周期控制 37
P66- MySQL-Innodb存储引擎-事务的ACID保证 38
P67- MySQL-Innodb存储引擎-Redo前滚功能 39
P78- MySQL-日志管理-binlog日志-查看 44
P79- MySQL-日志管理-binlog日志-截取和恢复 45
P82- MySQL-日志管理-binlog-GTID 46
P85- MySQL-日志管理-binlog-清理、滚动 46
P98- MySQL-物理备份-xtrabackup备份恢复 52
P100- MySQL-物理备份-xtrabackup增量备份 52
P131- MySQL-MHA高可用架构-VIP实现应用透明 70
P132- MySQL-MHA高可用架构-模拟VIP故障恢复 73
P133- MySQL-MHA高可用架构-故障邮件提醒 73
P134- MySQL-MHA高可用架构-Binlog Server 76
P137- MySQL-MHA+Atlas读写分离应用 77
P146- MySQL- Mycat核心特性——分片(水平拆分) 94
P147- MySQL- Mycat核心特性——分片(范围分片) 94
P148- MySQL- Mycat核心特性——分片(取模分片) 95
P149- MySQL- Mycat核心特性——分片(枚举分片) 96
P150- MySQL- Mycat核心特性——全局表(ER分片) 97
P153- MySQL-优化-Top(MEM-IO指标) 101
P169-NoSQL-精通Redis在线查看和修改配置 124
P182-MySQL+ redis-sentinel(哨兵) 131
P183-MySQL+ redis-redis cluster(分布式) 133
P187-MySQL+ redis-多API支持for Python 138
P194-MongDB-复制集RS(ReplicationSet) 149
P198-MongDB-Sharding Cluster 分片集群 153
P201-MongDB-Sharding Cluster 分片使用 159
P203-MongDB-Sharding Cluster-balancer 时间窗口 160
VMware安装centos_7.0
安装及网络配置教程https://www.jianshu.com/p/36d1b411703b
配置IP文件:cd /etc/sysconfig/network-scripts/ è vi ifcfg-eno16777736 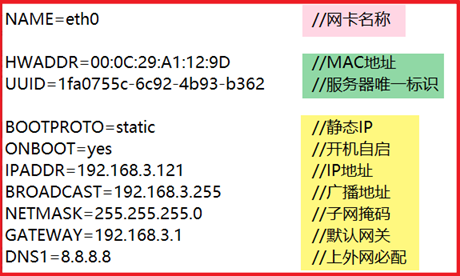
重启网络:systemctl restart network
GRUB_CMDLINE_LINUX列尾添加net.ifnames=0 biosdevname=0
grub2-mkconfig -o /boot/grub2/grub.cfg
mv ifcfg-enoXXXXXXXX ifcfg-eth0
修改ifcfg-eth0里边的NAME,DEVICE的名字都为eth0
hostnamectl set-hostname db01 或 vi /etc/hostname
防火墙常用命令:https://my.oschina.net/hongjiang/blog/3115033
hostnamectl set-hostname db01 或 vi /etc/hostname
#UUID=5a200c8c-d063-4af7-9fc4-41ce7b831bbb
P1- 老男孩MySQL-2019年3月中级DBA必备要求
P2- DBA职业素养
技能:熟悉操作系统、(快速)熟悉公司重点业务、熟悉行业发展趋势(主流数据库)
P3- 数据库管理系统-DBMS(RDBMS+NoSQL)
RDBMS(关系型数据库):适用于存储,关系较复杂、安全级别高的数据
NoSQL(非关系型数据库):适用于存储,高性能存取数据的数据,一般配合RDBMS使用;
RDBMS:MySQL、Oracle、PG、SQL server
P4- MySQL版本选择
Oracle:MySQL官方版(主流版本:5.6.36、5.7.20-2017/9/13)
MySQL官网下载地址: https://downloads.mysql.com/archives/community/
上新环境使用GA(稳定发布版6-12个月之间)
P5- 二进制包安装-配置-启动
清理历史版本MySQL(CentOS_7会预装mariadb需卸载)
rpm -qa|grep -i mariadb
rpm -ev mariadb-libs-5.5.35-3.el7.x86_64 --nodeps
find / -name mariadb (rm-rf)
上传mysql二进制包到/app目录下,解压,改名
mkdir -p /app
tar xf mysql-5.7.20-linux-glibc2.12-x86_64.tar.gz -C /app/mysql
配置环境变量
cd /app/mysql/bin
pwd
/app/mysql/bin
echo 'export PATH=/app/mysql/bin:$PATH'>> /etc/profile
source /etc/profile
查看用户和组,无则创建
cat /etc/group | grep mysql
cat /etc/passwd | grep mysql
userdel -r mysql
useradd mysql
创建数据文件存放目录/data/mysql ,并授权mysql用户管理数据库安装、及数据存放目录
mkdir -p /data/mysql
chown -R mysql.mysql /app/*
chown -R mysql.mysql /data/*
初始化数据(建库)
方法一、初始化不生成密码
[root@linux001 bin]# mysqld --initialize-insecure --user=mysql --basedir=/app/mysql --datadir=/data/mysql
报错:缺少libnuma.so.1,执行yum install -y libaio-devel或yum install -y numactl-devel
[root@linux001 bin]# mysqld --initialize --user=mysql --basedir=/app/mysql --datadir=/data/mysql
2019-11-07T19:26:46.277451Z 0 [Warning] InnoDB: New log files created, LSN=45790
2019-11-07T19:26:46.663357Z 0 [Warning] InnoDB: Creating foreign key constraint system tables.
5.7增加的安全机制:初始化制动生成12为密码,并记录到日志中,过期时间180天
P6- 管理员用户管理及小结
cp mysql.server /etc/init.d/mysqld
Shutting down MySQL.. SUCCESS!
方法二、利用CentOS_7新的命令管理方法启动(同1软件,2种方法不可一起使用)
cat >> /etc/systemd/system/mysqld.service <<EOF
Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.html
ExecStart=/app/mysql/bin/mysqld --defaults-file=/etc/my.cnf
systemctl start/stop/restart/status mysqld
mysqladmin -uroot -p password oldboy123
密码字段不一致,初始化方式不一致,初始化增加密码,启动方式,
P7- MySQL的CS结构及实例
mysql -uroot -poldboy123 -h 192.168.3.122 -P3306
mysql -uroot -poldboy123 -S /tmp/mysql.sock
P8- mysqld的三层结构
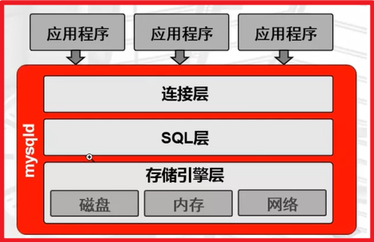
DML:数据操纵语言(select、insert、update、delete)
TC:事务控制(commit、rollback、savepoint)
解析器:对于语句执行前,进行预处理,生成解析树(执行计划),说白了就是
优化器:根据解析器得出的多种执行计划,进行判断,选择最优的执行计划代价
模型,资源(cpu\io\mem)的耗损来评估性能的好坏(重点)
执行器:根据最优的执行计划,执行SQL语句,产生执行结果(存放于磁盘的
提供查询缓存(默认不开启),会使用redis、 tair(淘宝自制)替代查询缓存功能
负责根据SQL层执行的结果,从磁盘中拿取16进制的磁盘数据,交由SQL结构化
P9- MySQL逻辑结构
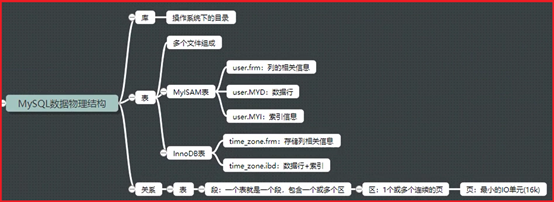
表:表名、表属性、列、列属性(数据类型,约束)、数据行(记录)
库:等于操作系统中的目录(在操作系统中创建和数据库中创建一样)
P10- 库和表的物理存储方式
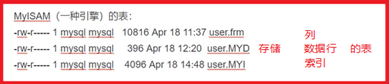

P11- MySQL段、区、页
P12- MySQL基础管理-用户介绍
用户名@'白名单' (白名单:允许访问当前数据库的主机IP)
oldboy@'10.0.0.%' 10网段24位子网掩码的主机
oldboy@'%' 任意主机
oldboy@'192.168.3.122' 指定IP
oldboy@'localhost' 本机
oldboy@'db02' 域名(主机IP的别名)
oldboy@'10.0.0.5%' IP为51-59的主机
oldboy@'10.0.0.0/255.255.254.0' 254网段(非24位子网掩码写法)
P13- MySQL基础管理-用户的增、删、改、查
增:create user oldboy@'localhost' identified by '密码;
查:select user,host,authentication_string from mysql.user;
改:alter user oldboy@'localhost' identified by '新密码';
删:drop user oldboy@'locahost';
P14- MySQL基础管理-权限管理及数据库远程连接
ALL:普通管理员拥有所有权限图:

with grant option:超级管理员所具有权限,可以为其他用户授权,等同于root用户
权限管理操作:创建用户并授权(为同一用户多次授权为累加效果)
grant all on *.* to oldboy@'10.0.0.%' identified by '123';
grant select,insert,update on *.* to oldboy@'10.0.0.%' identified by '123';
grant all on *.* to oldboy@'10.0.0.%' identified by '123' with grant option;
权限回收:revoke drop,delete on *.* from oldboy@'10.0.0.%';
查看权限:show grants for oldboy@'10.0.0.%';
测试:使用Navicat等远程连接工具,连接数据库,测试是否成功(关防火墙)
P15- MySQL基础管理-管理员用户密码丢失处理
关闭数据库服务:systemctl stop mysqld
免验证登录:关闭验证(--skip-grant-tables)、关闭IP登录访问(--skip-networking)
mysqld_safe --skip-grant-tables --skip-networking &
刷新授权表:flush privileges;
修改root用户密码:alter user root@'localhost' identified by '123';
关闭数据库服务并重启:pkill mysqld;systemctl start mysqld
P16- 回顾
P17- MySQL基础管理-连接管理
常用参数:-u -p -S -h -P -e <
本地连接(socket):mysql -uroot -poldboy123 -S /tmp/mysql.sock
远程连接(tcp/ip):mysql -uroot -poldboy123 -h 192.168.3.122 -P3306
免交互执行SQL:mysql -uroot -poldboy123 -e "select * from mysql.user;"
导入SQL脚本:mysql -uroot -poldboy123 <world.sql
P18- MySQL基础管理-初始化配置
多种启动方式图解:
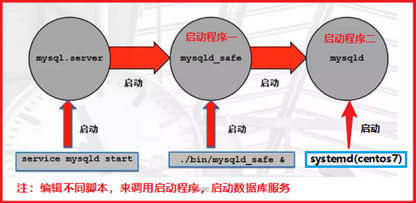
初始化配置作用:控制MySQL的启动,影响到客户端的连接
初始化配置的方法:预编译,配置文件,命令行(仅限于mysqld和mysqld_safe)
查找默认配置文件:mysqld --help --verbose | grep my.cnf
注:启动时加参--default-file=/xxx/my.cnf可指定配置文件(限于命令行启动方式)
P19- MySQL基础管理-初始化配置文件示例说明
配置文件my.cnf中所有参数:统一使用下划线分隔(避免触发历史遗留bug)
客户端标签:[mysql]、[mysqldump]、[client](统称不建议使用)
服务端标签:[mysqld]、[mysqld_safe]、[server](统称不建议使用)
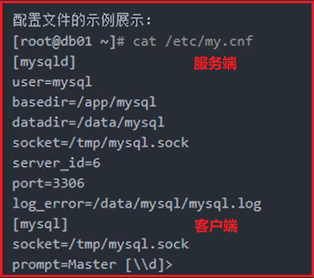
P20- MySQL基础管理-多实例配置
创建多实例安装、数据文件存放目录/data/{3307,3308,3309}/data
[root@linux001 bin]# mkdir -p /data/330{6,7,8}/data
一键创建多实例配置文件(粘贴,回车)
cat > /data/3307/my.cnf <<EOF
[mysqld]
user=mysql
basedir=/app/mysql
datadir=/data/3307/data
server_id=7
port=3307
socket=/data/3307/mysql.sock
log_bin=/data/3307/mysql-bin
[mysql]
socket=/data/3307/mysql.sock
prompt= [\U\\d]>
EOF
cat > /data/3308/my.cnf <<EOF
[mysqld]
user=mysql
basedir=/app/mysql
datadir=/data/3308/data
server_id=8
port=3308
socket=/data/3308/mysql.sock
log_bin=/data/3308/mysql-bin
[mysql]
socket=/data/3308/mysql.sock
prompt= [\U\\d]>
EOF
cat > /data/3309/my.cnf <<EOF
[mysqld]
user=mysql
basedir=/app/mysql
datadir=/data/3309/data
server_id=9
port=3309
socket=/data/3309/mysql.sock
log_bin=/data/3309/mysql-bin
[mysql]
socket=/data/3309/mysql.sock
prompt= [\U\\d]>
EOF
逐一初始化多个实例(将单实例的配置文件改名,等初始化后改回)
mv /etc/my.cnf /etc/my.cnf.d
mysqld --initialize-insecure --user=mysql --datadir=/data/3307/data --basedir=/app/mysql
复制3个启动命令,修改配置文件my.cnf的位置
cd /etc/systemd/system
cp mysqld.service mysqld3307.service
vim mysqld3307.service
--defaults-file=/data/3307/my.cnf
授权mysql用户管理数据库安装、及数据存放目录
chown -R mysql.mysql /data/*
启动>查看>登录>设密码
systemctl start mysqld3307
netstat -lnp | grep 330或ss -lnp | grep 330
mysqladmin -uroot -p -S /data/3307/mysql.sock
mysqladmin -uroot -p password oldboy123 -S /data/3307/mysql.sock
验证多实例
mysql -uroot -poldboy123 -S /data/3307/mysql.sock -e "select @@server_id";
mysql -uroot -poldboy123 -S /data/3308/mysql.sock -e "select @@server_id";
mysql -uroot -poldboy123 -S /data/3309/mysql.sock -e "select @@server_id";
P21- MySQL-SQL应用-SQL基本介绍
SQL介绍:
结构化查询语言
5.7以后符合SQL9.2严格模式
通过sql_mode参数来控制
常用SQL分类:
DDL:数据定义语言(create、alter、drop)
DCL:数据控制语言(grant、revoke、deny)
DML:数据操纵语言(select、insert、update、delete)
TC:事务控制(commit、rollback、savepoint)
P22- MySQL-SQL应用-数据类型介绍
数据类型:
整数:tinyint(0~255) int(10位数)
浮点数:float(4字节-单精度) double(8字节-双精度)
字符类型:char(固长255个字节) varchar(变长65535字节)
enum(枚举-自定义不变值,且按顺序赋予索引,存储时记录索引即可)

时间类型:Datatime(1000年-9999年,不受时区影响)
Timestamp(1970年-2038年,受时区影响)
P23- MySQL-SQL应用-表属性介绍
约束(列):
Primary key(主键):非空唯一
Not null:非空
Unique:唯一
Unsigned:无符号,针对数值类型(非负数)
其他属性(列):
Key:索引
Default:设定默认值
Auto_increment:自增长(默认从1开始,可以设定"起始值"和"自增间隔")
Comment:注释
存储引擎(表):
Inoodb(默认)
字符集(表):
Utf-8
Utf-8mb4
校对规则(表):
大小写是否敏感
_bin大小写敏感、_ci大小写不敏感(默认)
P24- MySQL-SQL基础-DDL建库
建库规范:
库名不能大写
库名不能以数字开头
建库时必须加字符集
库名与业务相关
建库语句:_bin大小写敏感、_ci大小写不敏感(默认)
Create schema school;
Create database school;
Create database school charset utf8;
Create database school charset utf8 collate utf8_bin;
查看支持字符集及校对规则:
Show charset;
Show collation;
P25- MySQL-SQL基础-DDL修改库
删库(生产中禁用):drop database school;
查看建库语句:show create database school;
修改指定库字符集:alter database school charset utf8;
注意:修改字符集,修改后的字符集,一定是原字符集的严格超集
P26- MySQL-SQL基础-DDL建表
建表规范:
表名小写
不能以数字开头
注意字符集和存储引擎
表名和业务相关
选择合适的数据类性
每个列都有注释
每个列设为非空,无法保证非空,以0填充
建表示例:
use school;
create table stu(
id int primary key auto_increment comment '学号',
sname varchar(255) not null comment '姓名',
sage tinyint unsigned not null default 0 comment '年龄',
sgender enum('m','f','n') not null default 'n' comment '性别',
sfz char(18) not null unique comment '身份证',
intime timestamp not null default now() comment '入学时间'
)engine=innodb charset=utf8 comment '学生表';
注:now()函数,可获取录入信息时间
查看建表语句:show create table stu;
创建一个表的副本:create table test like stu;
查看表结构:desc stu;
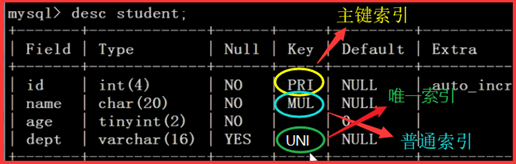
P27- MySQL-SQL基础-删除及修改表定义
删表(生产中禁用):drop table stu;
在线改表会锁表,造成业务影响,需要避开业务高峰期
Pt-osc(在线改表工具//8.0版本以加入该功能,在线改表不再锁表)
alter table stu add qq varchar(20) not null comment 'qq号码';
alter table stu add wechat varchar(64) not null comment '微信' after sname;
alter table stu add num int not null comment '数字' first;
alter table stu modify sname varchar(128) not null;
alter table stu change sgender sg char(1) not null default 'n';
P28- MySQL-SQL基础-DML-insert语句
(2,'lixiao',23,'f','45031',now()),
P29- MySQL-SQL基础-DML-update、delete语句
update stu set sname='zhaosi' where id=2;
伪删除:用update替代delete,保证业务中无法查询到该条数据
添加状态列:alter table stu add state tinyint not null default 1 comment '状态列';
修改需要隐藏列的状态值:update stu set state=0 where id=4;
以默认状态值查询:select * from stu where state=1;
P30- MySQL-SQL基础-DQL-select语句
Show variables like 'server%';
select concat(user,'@',host)from mysql.user;
select group_concat(user,'@',host)from mysql.user;(写成一行)
P31- MySQL-SQL基础-DQL-where语句
where》group by》having》order by》limit
P32- MySQL-SQL基础-DQL-group by语句
最大值max() ;最小值min() ;平均值avg() ;和sum() ;
计数器count() ;列转行group_concat();去重复distinct()
查询各a组下,的最大值b(需要查询的数用函数来计算,group by后的列进行分组)
select a,max(b) from tbname group by a;
P34- MySQL-SQL基础-DQL-order by语句
条件2:having 二次条件过滤不走索引,一般使用临时表解决
order by aa asc排序(desc降序、asc升序)
limit 3 显示前三个;limit 3,5跳过前3个,显示其后5个
查询a列各分类中b的总和,选出总和b>5000的,并降序排列,显示前3位
select a,sum(b) from city group by a having sum(b)>5000 order by sum(b) desc limit 3;
联合查询:查询效率更高,一般会将or\in的语句使用union all 改写,可叠加
union all(查询出的值不去重复) union(查询出的值去重复)
select * from city where District='中国'
select * from city where District='美国'
P36- MySQL-SQL基础-DQL-学生管理系统构建

P37- MySQL-SQL基础-DQL-多表联查

P39- MySQL-SQL基础- information_schema视图库(虚拟库)
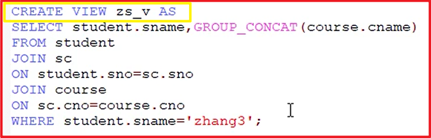
视图就是将常用的固定SQL查询封装后,存于当前库下(create view zs_v AS)
视图本身不存储任何数据,只是方便查询而已,查询视图和表查询一样)
information_schema、performance_schema、sys视图库(虚拟库)
常用表 information_schema .tables;
元数据存储在'基表',是我们没法直接访问,MySQL给我们提供了,DDL、DCL来进行
对元数据修改,提供了information_schema和show的语句查询元数据
desc information_schema.TABLES
SELECT TABLE_CHEMA,GROUP_CONCAT(TABLE_NAME)
SELECT TABLE_SCHEMA,COUNT(TABLE_NAME)
SELECT TABLE_SCHEMA,TABLE_NAME,ENGINE
FROM information_schema.TABLES
SELECT SUM(TABLE_ROWS*AVG_ROW_LENGTH+INDEX_LENGTH)/1024
mysqldump -uroot -poldboy123 world city >/bak/world_city.sql
语句拼接:(有的版本不支持将select导出到文件,需在my.cnf加入
select concat("mysqldump -uroot -poldboy123 ",table_schema," ",table_name,
" >/bak/",table_schema,"_",table_name,".sql")
from information_schema.tables
ALTER TABLE world.ctiy DISCARD TABLESPACE;
SELECT CONCAT("ALTER TABLE ",TABLE_SCHEMA,".",TABLE_NAME,
FROM information_schema.TABLES
INTO OUTFILE '/tmp/discard.sql';
P41- MySQL-SQL基础- show命令基本介绍
show processlist; 查看当前主机所有连接线程
show index from db_name.tb_name; 查看表索引
show engine innodb status \G; 查看innodb引擎相关状态
show slave status \G; 查看主从连接状态信息
show grant for root@'localhost'; 查看用户权限
show relaylog events; 查看从库relay_log时间信息
P42- MySQL-索引及执行计划
B-tree:通过 "根>枝>叶" 三级节点轮询查找(费时)
B+tree:优化了(>、<、>=、<=)判断,如果第一轮遍历结果键符合判断条件,
直接遍历下一个叶子节点(叶子节点支持双向查找),不再重新轮询三级查找(省时)
问题:Select * from test where id=5;
注意:根、枝、叶节点所有值并不是真正的值,而是指向真实数据行的指针(页码)
问题:select * from test where name='张三';
② 聚集索引的叶子节点就是磁盘的数据行所存储的数据页,MySQL是根据聚集索引来组
P46- MySQL-索引及执行计划-索引管理命令
注:同表中不可以有同名索引存在,添加唯一索引时保证数据行唯一性
添加索引:alter table tb_name add index idx_name(name);
删除索引:alter table tb_name drop index idx_name;
增/删主键:alter table t_100w add primary key(id) / drop primary key;
添加唯一索引:alter table tb_name add unique index idx_name(name);
添加联合索引:alter table tb_name add index idx_s_n(sex,name);
添加前缀索引:截取name列前5个字符,且必须为字符串列,不可是数字列
alter table tb_name add index idx(name(5));
https://blog.csdn.net/qq_39082172/article/details/102783155
查找重复数据
select population,count(id) from city group by population having count(id)>1 order by count(id)desc;
P47- MySQL-索引及执行计划-压力测试
压力测试:(用客户端工具(mysqlslap)测试,方便查看)
drop database if exists oldboy;
create database oldboy charset utf8mb4 collate utf8mb4_bin;
create table t_100w(id int,num int,k1 char(2),k2 char(4),dt timestamp);
数据行插入逻辑代码(防止出现换行的异常问题,可在Navicat中执行)
create procedure rand_data(in num int)
'ADzEFGHyIJKxLwMNvBCO9u8tPs7Quq6p54oRnSmTlUk3jViWehfgd2cXbYa1Z0';
str2=concat(substring(str,1+floor(rand()*61),1),substring(str,1+floor(rand()*61),1));
str4=concat(substring(str,1+floor(rand()*61),2),substring(str,1+floor(rand()*61),2));
insert into t_100w values(i,floor(rand()*num),str2,str4,now());
mysqlslap --defaults-file=/data/3307/my.cnf \
--concurrency=100 --iterations=1 --create-schema='oldboy' \
--query="select * from oldboy.t_100w where k2=' IJmT'" engine=innodb \
--number-of-queries=2000 -uroot -poldboy123 -S /data/3307/mysql.sock -verbose

P48- MySQL-索引及执行计划-分析
查询执行计划:desc \ explain select * from t_100w where k2=1234;
all全表扫描: 没建索引、针对辅助索引条件为不等于<>, not in(), like '%aa'
索引列上做函数运算(avg())或普通运算(+-*/)都不走索引
index全索引扫描: 要查询值都建有索引、联合索引中任何一个非最左列作为
例:idx_a_b_c(a,b,c) --> a ab abc(查询条件为 倒序 或没有a的情况)
eq_ref多表联查时,连接条件使用了唯一索引: unique,primary key
filesort文件排序:涉及排序且没走索引,需要将where等值条件和其他涉及
排序列 (order by, group by, distinct)按序做联合索引
注:having后 / where中不等值条件后,默认不走索引;
假设:需要多列建立联合索引,且存在双重判断(having),可建立临时表
创建临时表:create temporary table t_name AS
select * from city where a>1 group by b;
select * from t_name where b>1 order by c>1;
存在非等值判断时,选非等值判断的列为最右列做联合索引,非等值条件后不走索引
P50- MySQL-索引及执行计划-面试案例
① show full processlist; 获取导致慢现象的SQL语句,临时kill该语句
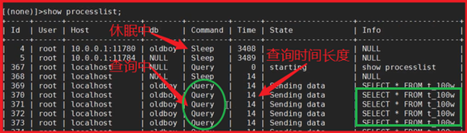
② explain 分析SQL语句的执行计划,有没有使用索引,索引类型情况等
② explain 分析SQL语句的执行计划,有没有使用索引,索引类型情况
P51- MySQL-索引应用规范
查找唯一值多的列:select count(*),count(distinct k1,k2) from t_100w;
③ 为经常需要where、order by、group by、join on的字段建立索引
⑤ 限制索引数量,清理无用索引(占用磁盘空间、修改更新时速度慢、优化器负担重)
⑧ 不使用全文搜索的SQL语句,若结果集超过25%,利用limit、redis等进行优化
在线管理MySQL索引工具percona-toolkit:(自学使用)
https://www.cnblogs.com/zhs0/p/10600318.html
https://www.cnblogs.com/siqi/p/5424330.html
面试题:
有一条SQL语句平时执行很快,突然有一天变得很慢,会是什么原因?
答:
分2种情况:
Select:平时执行很快,证明索引和语句都没有问题;
所以是索引失效,统计数据不真实导致慢
解决方法:删除旧索引,建立新索引
DML:多条语句执行排队等待,出现锁冲突
解决方法:
P52- MySQL-存储引擎
简介:相当于Linux的文件系统
功能:数据读写、数据安全和一致性、提高性能、热备份、自动故障恢复、高可用方面支持
类型:查看支持引擎:show engines;
Oracle官方支持
Innodb:支持事务、行锁、多版本并发控制、故障自动回复、热备、外键
Myisam:不支持事务、表锁、温备、不支持外键
Memory:视图使用
第三方支持
Perconadb:默认xtradb(Innodb增强版)
Mariadb:默认innodb
其他存储引擎支持:共同点-压缩比高、数据插入性能极高;常用于NewSQL和监控
Tokudb
Rocksdb
Myrocks
简历案例:(存储引擎替换)
环境:zabbix_3.2、mariadb_5.5、centos_7.3
现象:zabbix卡的要死,每隔3-4个月,都要重新搭建一遍zabbix,存储空间经常爆满
问题分析:
Zabbix版本老旧
数据库版本老旧
Zabbix数据库500G,存在一个文件里
优化建议及原因:
数据库版本升级到5.7,zabbix升级到4.0
经过测试5.7比5.5性能高2~3倍,新版本各方面都有所提高
存储引擎改为Tokudb
原生态支持Tokudb,Tokudb的数据插入速度和压缩比都要比Innodb高
监控数据库按月份进行切割分区(二次开发zabbix数据保留机制功能,数据库分表)
为了可以truncate每个分区,立即释放空间
关闭binlog和双1(关闭:sync_binlog=1 / innodb_flush_log_at_trx_commit=100)
双1详解:https://www.cnblogs.com/kevingrace/p/10441086.html
减少不必要日志的记录,减少资源消耗
参数调整......
关闭安全性参数,提高性能
优化结果:
监控效果良好
P54- MySQL-存储引擎案例
简历案例:(存储引擎替换)
环境:centos_5.8、mysql_5.0版本、myisam引擎、网站业务(LNMP)、数据量50G左右
现象:业务压力大的时候,非常卡,经历宕机后会有部分数据丢失
问题分析:
Myisam为表级锁,在高并发时会有很高的锁等待
Myisam不支持事务,再断电时可能丢失数据
优化建议及原因:
升级mysql_5.6.10版本
新版本性能更好,支持Innodb,支持事务、行级锁等
迁移所有表到新环境
新环境默认使用Innodb
开启双1参数
保证数据安全性
优化结果:
使用效果良好
P56- MySQL-优化案例
优化案例总结:
经常进行删除操作,需释放磁盘空间
① alter table t_1 engine innodb;
② 导出表数据,创建新表导入表数据
③ optimize table job_execution_log(直接对ibd文件操作,需指定ibd文件名)

将zabbix库中所有表的存储引擎修改为Tokudb
select concat("alter table Zabbix.",table_name,"engine tokudb;")
from information_schema.tables where table_schema='zabbix'
into outfile '/tmp/tokudb.sql';
P57- MySQL-存储引擎-物理结构

P58- MySQL-存储引擎-共享表空间
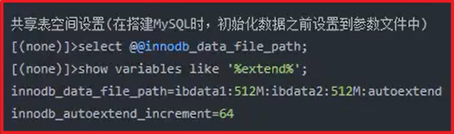
共享表空间:

共享表空间设置:
P59- MySQL-存储引擎-独立表空间
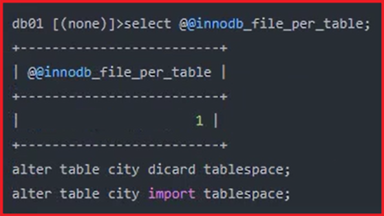
独立表空间:

独立表空间设置:
P59- MySQL-存储引擎-表空间恢复案例
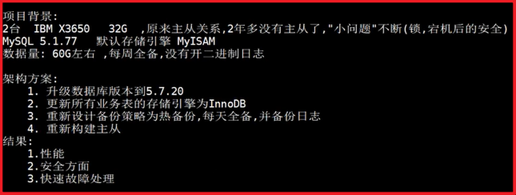
真实案例:
背景情况:开发人员专用(测试服务器)
架构:LNMT(Linux+nginx+mysql+tomcat)
项目管理工具:jira(用于bug追踪)、confluence(内部知识库)
系统环境配置:联想服务器(IBM)、磁盘500G无raid、centos_6.8
数据库环境:mysql_5.6.33、innodb引擎、独立表空间、备份未开启、日志未开启
(测试库:jira、confluence)
问题情况:服务器断电
错误解决方法:fsck重启(危险、仅可以保证启动,容易数据丢失),数据库无法 启动,测试库confluence正常、jira文件丢失
正确解决方案:断电后,启动救援模式,挂载新磁盘克隆磁盘镜像(dd if=/当前磁 盘 of=/ 新磁盘)等待完成后自动停止
求助:
解决jira数据库丢失恢复
检查后发现:无二进制日志、无备份、无主从
解决方法:刻录磁盘镜像,找专业人士进行硬盘修复
解决confluence数据库启动使用
检查后发现:ibd和frm文件存在
解决思路:
在正常库上建立相同表结构的空表
删除空表的ibd文件(alter talbe tb_name discard tablespace;)
复制原表的ibd文件来代替并授权(cp /chown -R mysql.mysql *)
数据库内导入表使ibd可用(alter table tb_name import tablespace;)
select * from 可用
P62- MySQL-第一阶段测试题
1、MySQL服务启动失败,怎么查看原因
答:有日志看日志,没日志直接mysqld启动查看(启动所有异常都会显示出来)
2、case when搜索函数的使用方法
答:https://www.cnblogs.com/zhuyeshen/p/10917397.html
P63- MySQL-存储引擎-表空间迁移
案例实操(基于P59表空间恢复案例)
问题情况:
26日,准备修改数据库文件目录(mysql/data/mysql)下的临时文件大小(ibtmp1),
修改完成后需删除 ibtmp1文件重新生成,但操作失误删除了元数据文件(ibdata1), 数据库启动失败!!
备份情况:
没有20日到当天(26日)的binlog日志
有20日备份(但恢复数据库失败,查看备份文件有多余代码,注释后恢复正常)
有当前数据库文件目录(mysql/data/mysql)备份
虚拟机模拟情况并恢复world数据库:
① 将当前正常库目录转移
mv mysql/ mysql.bak
② 搭建测试环境(创建新库目录>授权>初始化)
mkdir mysql
chown -R mysql.mysql *
mysqld --initialize-insecure --user=mysql --basedir=/app/mysql --datadir=/data/mysql
③ 重启数据库>确认临时库正常(登录)
/etc/init.d/mysqld start
mysql
show databases;
④ 还原历史world数据库(目的:获取表结构)
source /root/world.sql
alter talbe tb_name discard tablespace;
(删除空表的ibd文件,错误:存在外键约束,删除失败!
解决:跳过外键 set foreign_key_checks=0;)
⑤ 恢复
cp / (复制备份的ibd文件到当前库目录)
chown -R mysql.mysql *(授权)
alter table tb_name import tablespace;(数据库内导入表使ibd可用)
select * from 可用
P64- MySQL-Innodb存储引擎-ACID
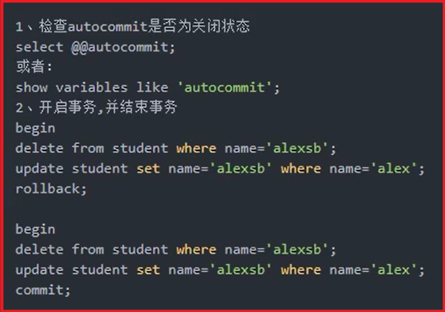
事务的ACID特性
原子性(atomic):
所有语句作为一个单元,全部成功执行或全部取消;不能存在执行一半的状态
一致性(consistent):
如果数据库在事务开始时处于一致状态,则在执行该事务期间将保留一致状态
隔离性(isolated):
事务之间互不影响
持久性(durable):
事务完成后,所做的所有更改都会准确的记录在数据中,所做的更改不会丢失
P65- MySQL-Innodb存储引擎-事务生命周期控制
事务开启
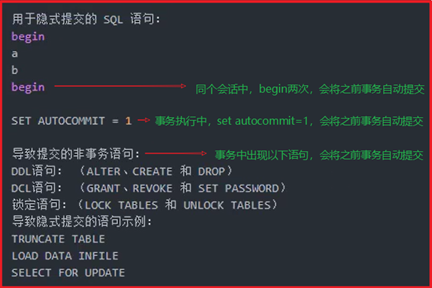
begin:开启事务(在5.5以后的版本,不需手动begin,只需执行一个DML,会自动在 前边添加begin)
事务结束
commit:提交事务(完成一个事务,一旦事务提交成功,就说明具备ACID特性)
rollback:回滚事务(将上一个未提交事务,回滚回去)
事务自动提交策略(autocommit)
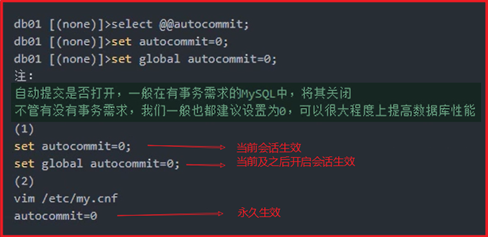
事务隐式提交语句
注:在没有commit,没有aotucommit=1的情况下,出现以下情况依然会提交事务
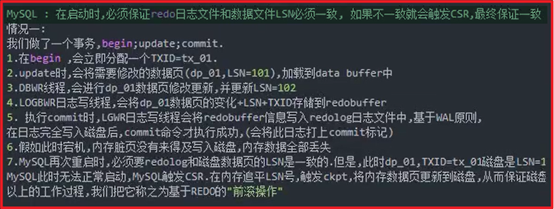
开始事务流程
P66- MySQL-Innodb存储引擎-事务的ACID保证
事务工作流程图:
P67- MySQL-Innodb存储引擎-Redo前滚功能
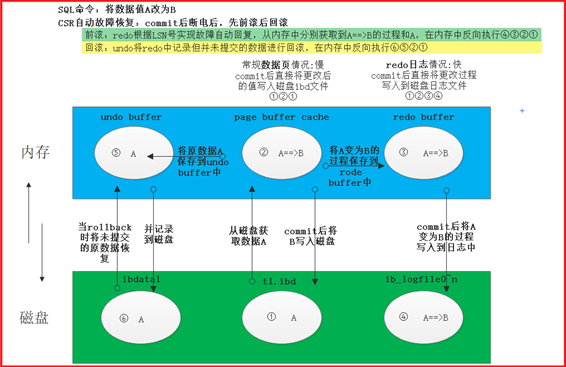
Redo:"重做日志" 事务日志的一种
作用:在事务ACID过程中,实现"D"的快速持久化作用,对于AC也有相应的作用
位置:数据文件存放目录/mysql/data/mysql ==> ib_logfile0、ib_logfile1
基本概念:
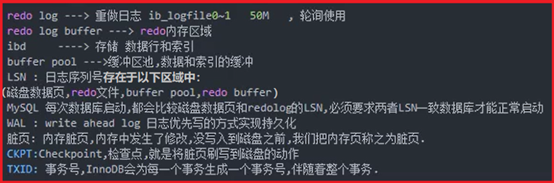
Redo的刷新策略:

MySQL-CSR(自动故障恢复)-redo前滚:
Undo:"重做日志" 事务日志的一种
作用:在事务ACID过程中,实现"A"的一致性作用
位置:数据文件存放目录/mysql/data/mysql ==> ibdata1
实现方法:rollback时,undo将redo中记录但并未提交的数据进行回滚
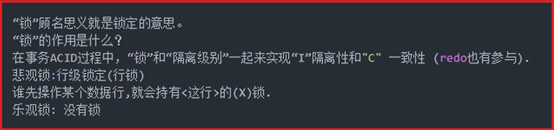
P70- MySQL-Innodb存储引擎-隔离级别
锁:在多事务状态下,存在锁等待,需前一个事务提交后才会执行下一个事务
隔离级别:transaction_isolation= repeatable-read
参数:read-uncommitted, read-committed, repeatable-read, serializable

注:基于并发情况会出现的问题!!
脏读:事务1第二次读取时,读到了事务2未提交的数据。若事务2回滚,则此次读取 数据不存在
不可重复读:事务1第二次查询时,读到了事务2提交的数据。导致事务1前后两次读 取的数据不一致(指数据行值的变化)
幻读:事务1第二次查询时,读到了事务2提交的数据(指数据行数的增减)
补充:在RC级别下,可以减轻GAP+NextLock锁的问题,但是会出现幻读现象,一般在
为了读一致性会在正常select后添加for update语句,但是,请记住执行完一定
要commit,否则容易出现锁等待比较严重
例如:select * from city where id=999 for update;
commit;
P71- MySQL-架构改造项目
P72- MySQL-Innodb存储引擎-核心参数
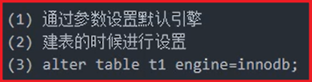
查看存储引擎:

修改存储引擎:
共享表空间:
独立表空间:

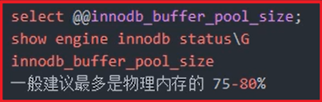
查看缓冲区池:在线更改时单位为:数据页单位,需换算(256MB*1024KB/16KB)
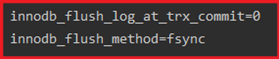
Innodb_flush_log_at_trx_commit(双一标准之一)
作用:主要控制redo刷写策略(innodb将log buffer中的数据写入日志中,并刷新磁盘
的时间点)取值分别为:0、1、2三个

Innodb_fulsh_method=(O_DIRECT, fsync),redo刷写方式
作用:控制了redo buffer和脏页(data buffer)刷写磁盘的方式(刷写磁盘时是否使用
os buffer);

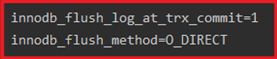
生产必设:Innodb_fulsh_method=O_DIRECT
默认值为:Innodb_fulsh_method= fsync,两个都走os buffer
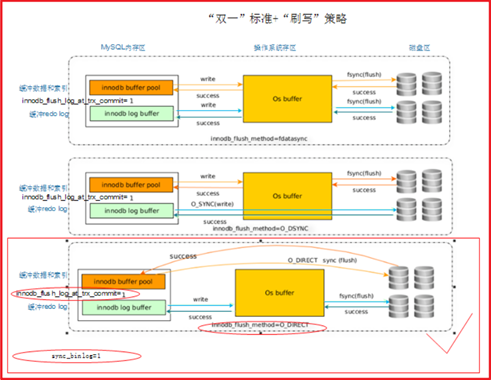
最大安全模式:
最大性能模式:
Redo相关参数设置:

P75- MySQL-日志管理-错误日志
错误日志:记录启动、关闭、日常运行过程中的状态信息、警告、错误(默认是开启存放在
数据路径下的:/数据路径下/hostname.err;建议路径单独存放:log_error
=/tmp/mysql.err)
二进制日志:备份恢复、主从环境(MySQL5.7中:开启log_bin必须设置server_id)
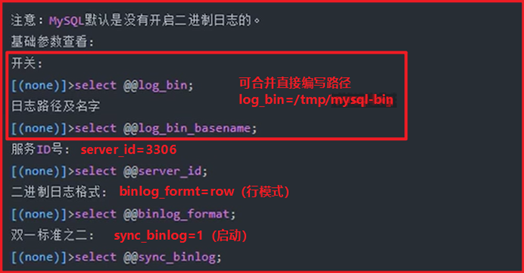
Binlog:是SQL层功能,记录变更SQL语句,不记录查询语句
binlog所记录的SQL语句分类:
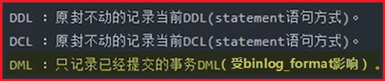
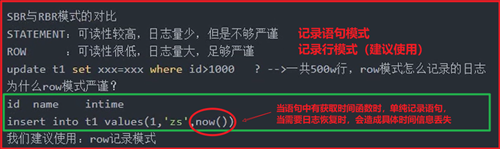
Binlog_format的三个参数:
- statement(5.6默认)SBR(statement based replication):语句模式原封不动的记录当前DML
- ROW(5.7默认值)RBR(ROW based replication):记录数据行的变化(用户看不懂,需要工具分析)
- Mixed(混合)MBR(mixed based replication)模式:以上两种的混合
面试题:
慢查询日志:
P78- MySQL-日志管理-binlog日志-查看
事件(event)简介:
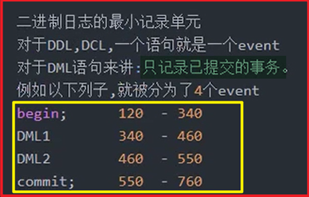
Event的组成:
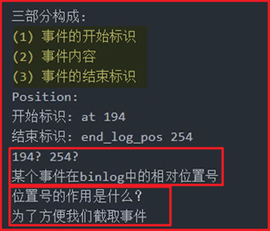
刷新二进制日志:flush logs;
查看所有二进制日志:show binary logs;
查看当前正在使用的二进制日志:show master status;
查看日志事件:show binlog events in 'mysql-bin.00002';
show binlog events in 'mysql-bin.00002' form 145 limit 5;
mysql -e "show binlog events in 'mysql-bin.00002'" | grep drop(只显示drop)
P79- MySQL-日志管理-binlog日志-截取和恢复
查看二进制日志内容:mysqlbinlog mysql-bin.0004
mysqlbinlog mysql-bin.0004 | grep -V SET(不显示SET信息)
mysqlbinlog -d db_name mysql-bin.0004(查看指定库内容)
mysqlbinlog --start-datetime='2019-05-01 17:00:00' --stop-datetime='2019-05-01 18:00:00' mysql-bin.0004(查看指点时间段内容;)
mysqlbinlog --start-position=550 --stop-position=742 mysql-bin.0004 >/bin.sql(已事件标识(at)截取整个事件内容)
查看DML语句基于ROW格式的内容:
mysqlbinlog --base64-output=decode-rows -vv msyql-bin.0004
临时关闭当前会话的binlog日志记录(用于恢复前,不记录恢复时执行的sql脚本):
set sql_log_bin=0;
数据库恢复模拟:(有备份优先使用备份,备份没有的地方用binlog日志补全)
- 建库:create database binlog;
- 使用库:use binlog;
- 建表:create table test(id int,name char(12));
- 插入数据:insert into test values(1,'zhang'),(2,'wang');
- 删表(模拟故障情况):drop database binlog;
- 查看当前使用日志:show master status;
- 查看并记录要恢复的标识点:show binlog events in 'mysql-bin.0004';
- 根据标识点导出sql:mysqlbinlog --start-position=550 --stop-position=742 mysql-bin.0004 >/tmp/test.sql
- 登录数据库:mysql -uroot -p
- 临时关闭当前会话的binlog日志记录:set sql_log_bin=0(避免记录重复日志)
- 恢复:source /tmp/test.sql
- 开启已关闭的当前会话binlog日志记录:set sql_log_bin=1
面试案例:
业务环境:每天全备,有全量的二进制日志;
故障情况:业务中共10个库,其中一个库被误删除
业务需求:需要在其他9个库正常工作的情况下,进行数据恢复
解决方案:在测试库中恢复,再还原到生产库中
- 全备大,故障库小:分别从全备和binlog日志中单独截取出故障库恢复;
- 全备小,故障库大:直接恢复全备和剩余binlog日志
P82- MySQL-日志管理-binlog-GTID
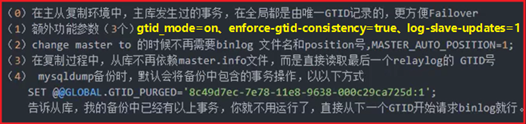
GTID(Global Transaction ID):是对于已提交事务的全局唯一编号;是5.7中的新功能,
即使不开启也会自动生成在binlog中(set @@session.gtid_next='anonymous')
开启方法:添加到my.cnf中, 重启生效后,再进行新操作会显示出GTID号
gtid-mode=on
enforce-gtid-consistency=true

根据GTID号截取binlog日志:(--skip-gtids:为截取的事务生成新的GTID号,
解决幂等性问题(指GTID唯一性,恢复时已存在的GTID事务会自动跳过))
mysqlbinlog --skip-gtids --include-gtids='唯一事务编号' mysql-bin.00005 >/tmp/gtid.sql
P85- MySQL-日志管理-binlog-清理、滚动
Binlog自动清理时间:expire_logs_days=全备周期*2+1(企业建议,空间允许越多越好)
配置最大值:max_binlog_size=100M(建议大小)
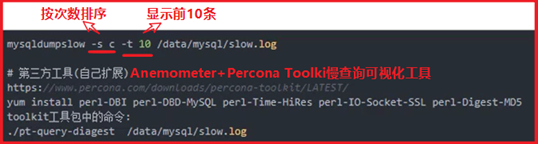
P86- MySQL-日志管理-slowlog-配置

可视化工具:https://blog.51cto.com/13178102/2150513
P88- MySQL-备份恢复的相关职责
P89- MySQL-备份恢复介绍
热备:在数据库正常运行时备份数据,并能够一致性恢复(innodb),对业务影响小
温备:锁表备份,只能查询不能修改(myisam), 影响写入操作
冷备:关闭数据库,在数据库关闭情况下备份数据,数据库不可使用
数据量级:<100G=小型公司 100G~500G=中型公司 >500G=大型公司
mysqldump:mysqldump+binlog(全备+增量)
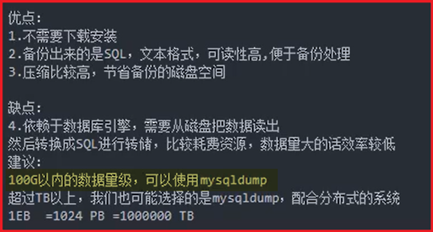
xtrabackup(XBK):xtrabackup+binlog(全备+增量)
mysqldump详细参数:--set-gtid-purged=on(主从时使用)
-A -R -E --triggers --master-data=2 --single-transaction --set-gtid-purged=OFF
--max_allowed_packet=256M(备份传输包大小调整)
本机全备:mysqldump -uroot -p -S /tmp/mysql.sock -A >/all.sql
远程全备:mysqldump -uroot -p -h10.10.0.1 -P3306 -A >/all.sql

获取表结构:sed -e'/./{H;$!d;}' -e 'x;/CREATE TABLE `city`/!d;q' full.sql>t1.sql
获取insert语句:grep -i 'INSERT INTO `city`' full.sql >t2.sql &
获取单库备份:sed -n '/^-- Current Database: `gtid`/,/^-- Current Database: `/p' full.sql > t3.sql
备份多个库:mysqldump -uroot -p -S /tmp/mysql.sock -B db_1 db_2>/db_n.sql
备份单库下多表:mysqldump -uroot -p -S /tmp/mysql.sock db_1 tb_1 tb_2>/db_tb_n.sql
生成分表备份脚本(备份指定库除外的,其他所有库下的所有表;执行脚本:sh dump.sql):
P94- MySQL-故障恢复案例
每天全备、binlog是完整的、模拟白天数据变化、模拟下午两点误删除数据库

找到mysql-bin.000005,截取313到最后的数据
mysqlbinlog --start-position=313 mysql-bin.00005 >/bin.sql
/etc/init.d/mysqld start或systemctl start mysqld
P95- MySQL-企业故障恢复案例
正在运行的网站系统,mysql-5.7.20数据库,数据量50G,日业务量1-5M
每天23:00,计划任务调用mysqldump执行全备脚本(备份和数据不要放在一起)

mysql -uroot -poldboy123 -e "show binlog events in 'mysql-bin.000002'" | tail -100 | grep -i 'drop'

P96- MySQL-物理备份-xtrabackup
使用Rpm包安装(不同版本MySQL对应不同的版本,自行下载)
rpm -ivh percona-xtrabackup-24-2.4.9-1.el6.x86_64.rpm

yum install rsync perl-DBD-MySQL yum install -y perl-Digest-MD5 numactl-devel -y
缺失的libev.so.4()(64bit)包可以到rpm网站下载,然后rpm -ivh xxx.rpm安装
rpm私网:http://rpmfind.net/linux/RPM/index.html(可能会退出,重新进入即可)
然后重新安装rpm -ivh percona-xtrabackup-24-2.4. 9-1.el6.x86_64.rpm
安装完成后执行innobackupex --help、innobackupex -version
https://www.cnblogs.com/diantong/p/11029285.html
https://blog.csdn.net/my_bai/article/details/72915508
使用innobackupex备份需要有my.cnf(默认/etc/my.cnf),没有需--defaults-file=/data/my.cnf指定
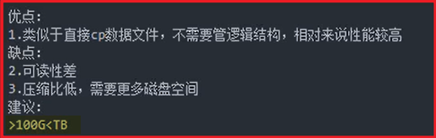
Innodb热备:不锁表,备份数据页同时将备份过程中产生的redo\undo一起备走

P98- MySQL-物理备份-xtrabackup备份恢复
备份:需要在配置文件中指定sock: [client] socket=/tmp/mysql.sock
指定目录名自动创建,不指定自动以日期命名创建目录存放备份文件,.log存放备份日志
innobackupex --user=root --password=oldboy123 /tmp/all &>/tmp/all.log

清空mysql数据存放目录:rm -rf /data/mysql/ *
回滚备份:innobackupex --apply-log /tmp/all
导入备份:innobackupex --copy-back full
授权启动:chown -R mysql.mysql /data/*
P100- MySQL-物理备份-xtrabackup增量备份
对比xtrabackup_checkpoints文件确认增备是否成功!!last_lsn-9仅适用于5.7,5.6正常
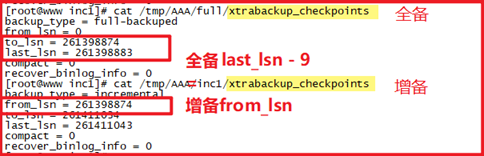

部分备份需要只redo不undo(--redo-only;除了最后一次增量,其他全部要使用)
恢复全备:innobackupex --apply-log --redo-only /tmp/AAA/full/
依次恢复增备到全备:innobackupex --apply-log --redo-only --incremental-dir=/tmp/inc1 /tmp/full/


复制XBK备份文件到目录:cp -a /tmp/full/* /data/mysql/
授权登录:chown -R mysql.mysql /data/*
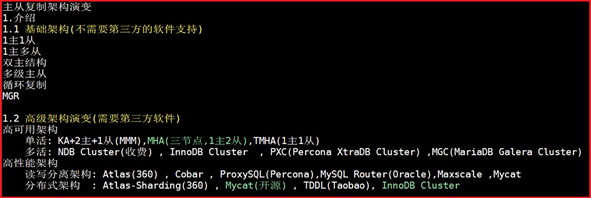
P104- MySQL-主从复制基础

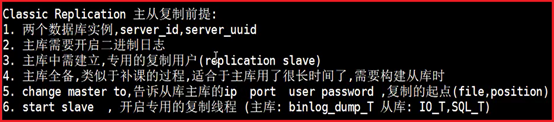
grant replication slave on *.* to rep@'%' identified by '123';
MASTER_LOG_FILE='mysql-bin.000001',
root@localhost (none)>show slave status\G
*************************** 1. row ***************************
##当前slave I/O线程状态
Slave_IO_State: Waiting for master to send event
##主库相关信息
Master_Host: 192.168.1.100
Master_User: mysync
Master_Port: 3306
Master_Log_File: mysql-bin.001822
Read_Master_Log_Pos: 290072815
##从库中继日志应用状态
Relay_Log_File: mysqld-relay-bin.005201
Relay_Log_Pos: 256529594
Master_SSL_Verify_Server_Cert: No
P110- MySQL-主从复制原理
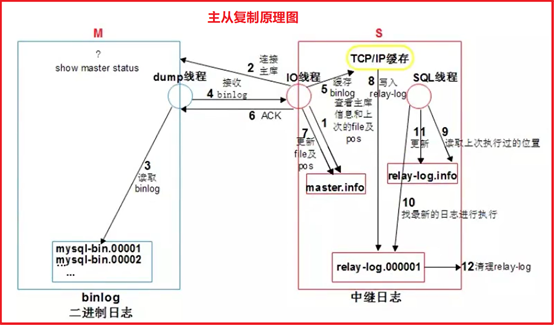
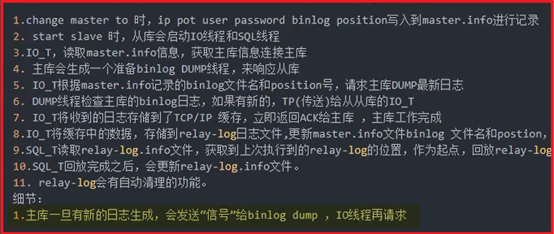
P111- MySQL-主从复制故障
连接数上限:max_connections=1(连接数1,可以连2个)
防火墙或数据库关闭:ERROR 2003: Can't connect to MySQL server on
主库连接数上限:ERROR 1040:Too many connections
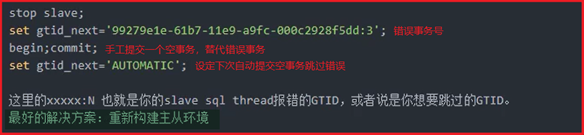
reset slave all;(清空从库change master信息)
P113- MySQL-主从延时-原因解析
P115- MySQL-延时从库-配置及使用思路

P116- MySQL-延时从库-处理逻辑损坏
Relay_Log_File: www-relay-bin.000014
show relaylog events in 'www-relay-bin.000014';

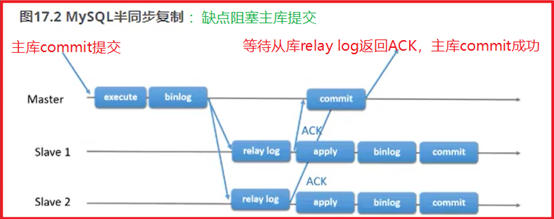
P118- MySQL-半同步主从复制
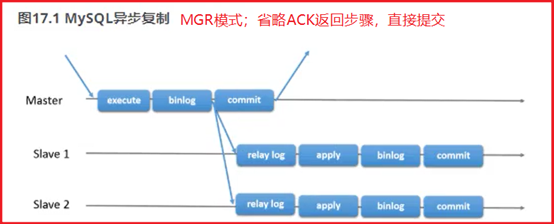
过滤复制:通过设定黑、白名单来控制是否被复制(建议从库按需设定,不适用主库)
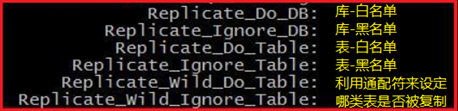 从库:show slave status\G查看;配置文件中,参数小写,多个库需写多行
从库:show slave status\G查看;配置文件中,参数小写,多个库需写多行
P119- MySQL-GTID主从复制-环境准备
主库开启GTID:gtid_mode=on 强一致性:enforce-gtid-consistency=true
强制从库记录主库二进制日志(保证全局唯一):log-slave-updates=1
log_bin=/data/mysql/binlog/mysql-bin
log_bin=/data/mysql/binlog/mysql-bin
log_bin=/data/mysql/binlog/mysql-bin
mysqld --initialize-insecure --user=mysql --basedir=/app/mysql --datadir=/data/mysql/data
P121- MySQL-GTID主从复制-配置搭建

grant replication slave on *.* to rep@'%' identified by '123';
P124- MySQL-主从复制架构演变
P125- MySQL-MHA高可用架构-环境准备
ln -s /app/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
ln -s /app/mysql/bin/mysql /usr/bin/mysql
配置SSH互信:(在主库服务器创建 122 => 123\124 )
添加其他主机连接信息:(yes => root用户登录密码)
scp -r /root/.ssh 192.168.3.123:/root
scp -r /toot/.ssh 192.168.3.124:/root

官网:https://code.google.com/archive/p/mysql-master-ha/
Github:https://github.com/yoshinorim/mha4mysql-manager/wiki/Downloads
安装依赖包:yum install perl-DBD-MySQL -y
安装rpm包:rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm
安装Manager节点:(建议单独准备一台管理服务器,或安装在从库上124)
安装依赖包:yum install -y perl-Config-Tiny perl-Log-Dispatch epel-releaseperl-
Parallel-ForkManager perl-Time-HiRes
安装rpm包:rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm

P126- MySQL-MHA高可用架构-架构搭建
创建MHA专用监控管理用户:(主库创建122,主从环境会自动复制到从库)
grant all privileges on *.* to mha@'%' identified by '123';
创建日志目录:mkdir -p /var/log/mha/app1
manager_log=/var/log/mha/app1/manager
manager_workdir=/var/log/mha/app1
master_binlog_dir=/data/mysql/binlog
masterha_check_ssh --conf=/etc/mha/app1.cnf
验证通过:All SSH connection tests passed successfully.
masterha_check_repl --conf=/etc/mha/app1.cnf
主从状态正常:MySQL Replication Health is OK.
masterha_check_status --conf=/etc/mha/app1.cnf
状态正常:app1 (pid:4649) is running(0:PING_OK), master:192.168.3.122
P128- MySQL-MHA高可用架构-工作原理
多slave数据有差异(gtid、position),按照差异最小化选主
多slave数据无差异(gtid、position),按照配置文件中顺序选主
设定有权重(candidate_master=1),按照权重设定选主:
a. 权重指定slave不得落后master 100兆relay_log,否则权重失效;
b. 除非设定check_repl_delay=0,则会强制权重选主
SSH能连接时,slave对比master的GTID或Position号,立即将缺失的
二进制日志保存到各从节点,并恢复应用(save_binary_logs)
SSH不能连接时,对比从库间的relay_log的差异(apply_diff_relay_logs)
④ Failover(masterha_master_switch):
进行主从切换,对外提供服务;其余从库和新主库重新确立主从关系
P129- MySQL-MHA高可用架构-工具介绍
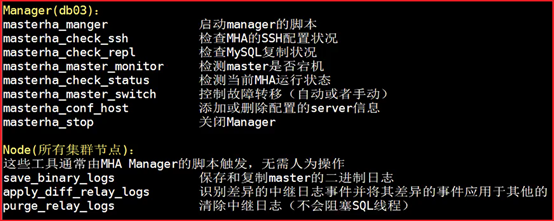

指定slave为权重模式,且不得落后master 100兆relay_log,否则权重失效;
masterha_check_status --conf=/etc/mha/app1.cnf
mha停止工作:app1 is stopped(2:NOT_RUNNING)
进程已退出:[1]+ Done nohup masterha_manager –conf=/etc/mha/
app1.cnf –remove_dead_master_conf --ignore_last_failover < /dev/null >
/var/log/mha/app1/manager.log 2>&1
主库切换成功:Master_Host: 192.168.3.123
② 修复主从:(manager工作日志中可找到change master to 语句)
CHANGE MASTER TO MASTER_HOST='192.168.3.122',MASTER_PORT=3306,
MASTER_AUTO_POSITION=1,MASTER_USER='rep',MASTER_PASSWORD='123';
masterha_check_repl --conf=/etc/mha/app1.cnf
主从状态正常:MySQL Replication Health is OK.
masterha_check_status --conf=/etc/mha/app1.cnf
状态正常:app1 (pid:4649) is running(0:PING_OK), master:192.168.3.122
P131- MySQL-MHA高可用架构-VIP实现应用透明
vim /usr/local/bin/master_ip_failover
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
print "Disabling the VIP on old master: $orig_master_host \n";
elsif ( $command eq "start" ) {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
--orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";

chmod +x /usr/local/bin/master_ip_failover
dos2unix /usr/local/bin/master_ip_failover
master_ip_failover_script=/usr/local/bin/master_ip_failover
注意:第一次配置VIP时,需要在 主库 手工绑定VIP,默认centos7没有ifconfig命
安装ifconfig命令:yum install -y net-tools
绑定VIP:ifconfig eth0:1 192.168.3.120/24 解绑VIP:ifconfig eth0:1 down
生成完成后ifconfig // ip addr可以看到虚拟IP已存在!!
关闭:masterha_stop --conf=/etc/mha/app1.cnf
P132- MySQL-MHA高可用架构-模拟VIP故障恢复
转移成功后VIP会出现在新主机上。。。
P133- MySQL-MHA高可用架构-故障邮件提醒
以下所有脚本都需授予执行权限:(脚本已下载到本地,不知道哪里有问题邮件发送不成功)
chmod +x 脚本名
安装邮件服务器:(sendEmail解压后即可使用)
wget http://caspian.dotconf.net/menu/Software/SendEmail/sendEmail-v1.56.tar.gz -P /
tar xf /sendEmail-v1.56.tar.gz -C /
cp /sendEmail-v1.56/sendEmail /usr/local/bin/
创建手工发送邮件测试脚本:
vim test
#!/bin/bash
/usr/local/bin/sendEmail -o tls=no -f g_lee0916@126.com -t 2387077588@qq.com -s stmp.126.com:25 -xu g_lee0916 -xp ybbhlkg1dddf -u "MHA Waring" -m "YOUR MHA NAY BE FAILOVER" &>/tmp/sendmail.log

创建报警邮件发送脚本:
vim send
#!/usr/bin/perl
## Note: This is a sample script and is not complete. Modify the script based on your environment.
use strict;
use warnings FATAL => 'all';
use Mail::Sender;
use Getopt::Long;
#new_master_host and new_slave_hosts are set only when recovering master succeeded
my ( $dead_master_host, $new_master_host, $new_slave_hosts, $subject, $body );
my $smtp='smtp.126.com';
my $mail_from='g_lee0916@126.com';
my $mail_user='g_lee0916';
my $mail_pass='ybbhlkg1dddf';
my $mail_to='2387077588@qq.com';
#my $mail_to=['to1@qq.com','to2@qq.com'];
GetOptions(
'orig_master_host=s' => \$dead_master_host,
'new_master_host=s' => \$new_master_host,
'new_slave_hosts=s' => \$new_slave_hosts,
'subject=s' => \$subject,
'body=s' => \$body,
);
# Do whatever you want here
mailToContacts($smtp,$mail_from,$mail_user,$mail_pass,$mail_to,$subject,$body);
sub mailToContacts {
my ($smtp, $mail_from, $mail_user, $mail_pass, $mail_to, $subject, $msg ) = @_;
open my $DEBUG, ">/var/log/masterha/app1/mail.log"
or die "Can't open the debug file:$!\n";
my $sender = new Mail::Sender {
ctype => 'text/plain;charset=utf-8',
encoding => 'utf-8',
smtp => $smtp,
from => $mail_from,
auth => 'LOGIN',
TLS_allowed => '0',
authid => $mail_user,
authpwd => $mail_pass,
to => $mail_to,
subject => $subject,
debug => $DEBUG
};
$sender->MailMsg(
{
msg => $msg,
debug => $DEBUG
}
) or print $Mail::Sender::Error;
return 1;
}
exit 0;
添加邮件发送脚本路径到manager配置文件中:
vim /etc/mha/app1.cnf
[server default]
report_script=/usr/local/bin/send
重启manager服务:
关闭:masterha_stop --conf=/etc/mha/app1.cnf
开启:nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover </dev/null> /var/log/mha/app1/manager.log 2>&1 &
模拟故障:
依照P129执行。。。
P134- MySQL-MHA高可用架构-Binlog Server
Binlog server:数据补偿功能,专用存储binlog日志
binlogserver配置:
找一台额外的机器,必须要和原库版本一致,我们直接用的第二个slave(db03)
在manager配置文件中加入参数:
vim /etc/mha/app1.cnf
[binlog1]
no_master=1 #禁止参与选主
hostname=192.168.3.124
master_binlog_dir=/data/mysql/binlogserver
创建相应目录:
mkdir -p /data/mysql/binlogserver
chown -R mysql.mysql /data/*
拉取binlog:binlog号根据同步最慢的从库中Master_Log_File: mysql-bin.000002决定
cd /data/mysql/binlogserver
mysqlbinlog -R --host=192.168.3.122 --user=mha --password=123 --raw --stop-never mysql-bin.000002 &
重启manager服务:
关闭:masterha_stop --conf=/etc/mha/app1.cnf
开启:nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover </dev/null> /var/log/mha/app1/manager.log 2>&1 &
模拟故障:
依照P129执行。。。
重新配置数据补偿功能:
依照P134执行。。。
P136- MySQL-MHA高可用架构-管理员职责
1. 搭建:MHA+VIP+SendReport+BinlogServer
3. 高可用架构的优化
核心是:尽可能降低主从的延时,让MHA花在数据补偿上的时间尽量减少。
5.7 版本,开启GTID模式,开启从库SQL并发复制。
P137- MySQL-MHA+Atlas读写分离应用
Atlas介绍:简单说就是让数据库任何操作都通过Atlas执行,再通过配置达到读写分离
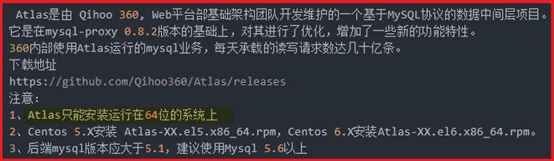
安装配置Atlas:(yum或下载rpm包都可以;这里是下载的rpm包)
yum install -y Atlas*
编辑配置文件:(跳转到mysql-proxy读写分离目录,先把原配置文件注释;在建新的)
cd /usr/local/mysql-proxy/conf
proxy-backend-addresses = 192.168.3.120:3306
proxy-read-only-backend-addresses = 192.168.3.123:3306,192.168.3.124:3306
pwds = rep:3yb5jEku5h4=,mha:3yb5jEku5h4=
log-path = /usr/local/mysql-proxy/log

/usr/local/mysql-proxy/bin/mysql-proxyd test start
mysql -umha -p123 -h192.168.3.120 -P33060
begin;select @@server_id;commit;
制作加密密码:/usr/local/mysql-proxy/bin/encrypt 123
重启服务:/usr/local/mysql-proxy/bin/mysql-proxyd test restart
连接管理端口:mysql -uuser -ppwd -h127.0.0.1 -P2345
查询后端所有节点信息:select * from backends;
动态添加节点:add slave 10.0.0.53:3306;
P139- MySQL-Mycat环境准备
每台创建四个mysql实例:3307 3308 3309 3310
mv /etc/my.cnf /etc/my.cnf.bak
mkdir -p /data/{3307,3308,3309,3310}/data
mysqld --initialize-insecure --user=mysql --datadir=/data/3307/data --basedir=/app/mysql
mysqld --initialize-insecure --user=mysql --datadir=/data/3308/data --basedir=/app/mysql
mysqld --initialize-insecure --user=mysql --datadir=/data/3309/data --basedir=/app/mysql
mysqld --initialize-insecure --user=mysql --datadir=/data/3310/data --basedir=/app/mysql
log-error=/data/3307/mysql.log
log-error=/data/3308/mysql.log
log-error=/data/3309/mysql.log
log-error=/data/3310/mysql.log
cat >/etc/systemd/system/mysqld3307.service<<EOF
Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.html
ExecStart=/app/mysql/bin/mysqld --defaults-file=/data/3307/my.cnf
cat >/etc/systemd/system/mysqld3308.service<<EOF
Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.html
ExecStart=/app/mysql/bin/mysqld --defaults-file=/data/3308/my.cnf
cat >/etc/systemd/system/mysqld3309.service<<EOF
Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.html
ExecStart=/app/mysql/bin/mysqld --defaults-file=/data/3309/my.cnf
cat >/etc/systemd/system/mysqld3310.service<<EOF
Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.html
ExecStart=/app/mysql/bin/mysqld --defaults-file=/data/3310/my.cnf
log-error=/data/3307/mysql.log
log-error=/data/3308/mysql.log
log-error=/data/3309/mysql.log
log-error=/data/3310/mysql.log
cat >/etc/systemd/system/mysqld3307.service<<EOF
Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.html
ExecStart=/app/mysql/bin/mysqld --defaults-file=/data/3307/my.cnf
cat >/etc/systemd/system/mysqld3308.service<<EOF
Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.html
ExecStart=/app/mysql/bin/mysqld --defaults-file=/data/3308/my.cnf
cat >/etc/systemd/system/mysqld3309.service<<EOF
Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.html
ExecStart=/app/mysql/bin/mysqld --defaults-file=/data/3309/my.cnf
cat >/etc/systemd/system/mysqld3310.service<<EOF
Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.html
ExecStart=/app/mysql/bin/mysqld --defaults-file=/data/3310/my.cnf
mysql -S /data/3307/mysql.sock -e "show variables like 'server_id'"
mysql -S /data/3308/mysql.sock -e "show variables like 'server_id'"
mysql -S /data/3309/mysql.sock -e "show variables like 'server_id'"
mysql -S /data/3310/mysql.sock -e "show variables like 'server_id'"
P140- MySQL-Mycat主从搭建

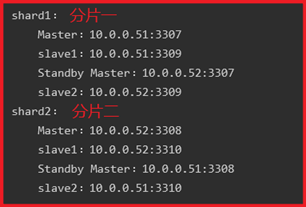
192.168.3.122:3307 <-----> 192.168.3.123:3307
mysql -S /data/3307/mysql.sock
grant replication slave on *.* to repl@'192.168.3.%' identified by '123';
grant all on *.* to root@'192.168.3.%' identified by '123' with grant option;
mysql -S /data/3307/mysql.sock
mysql -S /data/3307/mysql.sock
192.168.3.122:3309 ------> 192.168.3.122:3307
mysql -S /data/3309/mysql.sock
192.168.3.123:3309 ------> 192.168.3.123:3307
mysql -S /data/3309/mysql.sock
192.168.3.123:3308 <-----> 192.168.3.122:3308
mysql -S /data/3308/mysql.sock
grant replication slave on *.* to repl@'192.168.3.%' identified by '123';
grant all on *.* to root@'192.168.3.%' identified by '123' with grant option;
mysql -S /data/3308/mysql.sock
mysql -S /data/3308/mysql.sock
192.168.3.123:3310 -----> 192.168.3.123:3308
mysql -S /data/3310/mysql.sock
192.168.3.122:3310 -----> 192.168.3.122:3308
mysql -S /data/3310/mysql.sock
mysql -S /data/3307/mysql.sock -e "show slave status\G"|grep Yes
mysql -S /data/3308/mysql.sock -e "show slave status\G"|grep Yes
mysql -S /data/3309/mysql.sock -e "show slave status\G"|grep Yes
mysql -S /data/3310/mysql.sock -e "show slave status\G"|grep Yes
mysql -S /data/3307/mysql.sock -e "stop slave; reset slave all;"
mysql -S /data/3308/mysql.sock -e "stop slave; reset slave all;"
mysql -S /data/3309/mysql.sock -e "stop slave; reset slave all;"
mysql -S /data/3310/mysql.sock -e "stop slave; reset slave all;"
P141- MySQL-Mycat分布式架构演变
P142- MySQL- Mycat安装配置
MyCAT安装:(安装包需下载http://dl.mycat.io/)122
查找安装路径:whereis java(查看当前路径直到根路径)

export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.el7_7.x86_64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
tar xf Mycat-server-1.6.5-release-20180122220033-linux.tar.gz
export PATH=/app/mycat/bin:$PATH
错误:修改环境变量后,导致一些常用命令失效,如ll,ls,vi不能用
mysql -uroot -p123456 -h 127.0.0.1 -P8066(mycat默认虚拟账号)

mysql -S /data/3307/mysql.sock
grant all on *.* to root@'192.168.3.%' identified by '123';
mysql -S /data/3308/mysql.sock
grant all on *.* to root@'192.168.3.%' identified by '123';
注意:写节点中包含读节点;默认写节点不可用时,读节点也不可用;防止数据二次损坏
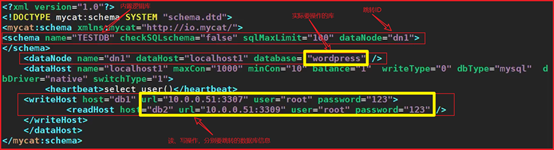
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<dataNode name="dn1" dataHost="localhost1" database= "wordpress" />
<heartbeat>select user()</heartbeat>
<writeHost host="db1" url="192.168.3.122:3307" user="root" password="123">
<readHost host="db2" url="192.168.3.122:3309" user="root" password="123" />
mysql -uroot -p -h 127.0.0.1 -P8066
读:show variables like 'server_id';
vim schema.xml(两主两从,读写分离;;默认第一个写节点写,其余节点轮询读)
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="sh1">
<dataNode name="sh1" dataHost="oldguo1" database= "world" />
<heartbeat>select user()</heartbeat>
<writeHost host="db1" url="192.168.3.122:3307" user="root" password="123">
<readHost host="db2" url="192.168.3.122:3309" user="root" password="123" />
<writeHost host="db3" url="10.0.0.52:3307" user="root" password="123">
<readHost host="db4" url="10.0.0.52:3309" user="root" password="123" />
mysql -uroot -p -h 127.0.0.1 -P8066
show variables like 'server_id';
show variables like 'server_id';
show variables like 'server_id';
show variables like 'server_id';
1. balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的writeHost上。
3. balance="2",所有读操作都随机的在writeHost、readhost上分发。
2. writeType="1",所有写操作都随机的发送到配置的writeHost,但不推荐使用
2 基于MySQL主从同步的状态决定是否切换 ,心跳语句为 show slave status
minCon="10" :mycat在启动之后,会在后端节点上自动开启的连接线程
tempReadHostAvailable="1":一主一从中,主库不可用时,临时使用从库读功能
<heartbeat>select user()</heartbeat> 监测心跳
P145- MySQL- Mycat垂直分表
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="sh1">
<table name="user" dataNode="sh1"/>
<table name="order_t" dataNode="sh2"/>
<dataNode name="sh1" dataHost="oldguo1" database= "taobao" />
<dataNode name="sh2" dataHost="oldguo2" database= "taobao" />
<heartbeat>select user()</heartbeat>
<writeHost host="db1" url="192.168.3.122:3307" user="root" password="123">
<readHost host="db2" url="192.168.3.122:3309" user="root" password="123" />
<writeHost host="db3" url="10.0.0.52:3307" user="root" password="123">
<readHost host="db4" url="10.0.0.52:3309" user="root" password="123" />
<heartbeat>select user()</heartbeat>
<writeHost host="db1" url="192.168.3.122:3308" user="root" password="123">
<readHost host="db2" url="192.168.3.122:3310" user="root" password="123" />
<writeHost host="db3" url="10.0.0.52:3308" user="root" password="123">
<readHost host="db4" url="10.0.0.52:3310" user="root" password="123" />
创建测试库和表:(因为是双主模式,所以在其中一个主机执行就可以;可以参考 P140图)
mysql -S /data/3307/mysql.sock
create database taobao charset utf8;
create table user(id int,name varchar(20));
mysql -S /data/3308/mysql.sock
create database taobao charset utf8;
create table order_t(id int,name varchar(20));
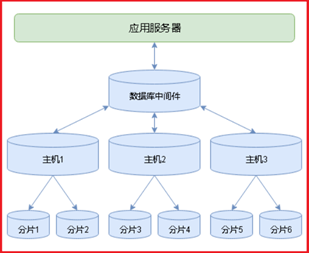
P146- MySQL- Mycat核心特性——分片(水平拆分)
P147- MySQL- Mycat核心特性——分片(范围分片)
(1)行数非常多,2000w(1-1000w:sh1 1000w01-2000w:sh2)
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="sh1">
<table name="t3" dataNode="sh1,sh2" rule="auto-sharding-long" />
<dataNode name="sh1" dataHost="oldguo1" database= "taobao" />
<dataNode name="sh2" dataHost="oldguo2" database= "taobao" />
<tableRule name="auto-sharding-long">
<algorithm>rang-long</algorithm>
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
vim autopartition-long.txt(range范围分片)
mysql -S /data/3307/mysql.sock
create table t3 (id int not null primary key auto_increment,name varchar(20) not null);"
mysql -S /data/3308/mysql.sock
create table t3 (id int not null primary key auto_increment,name varchar(20) not null);"
测试范围分片:(插入成功后,登录到两个物理节点上,可以看到数据分开存放)
mysql -uroot -p123456 -h 127.0.0.1 -P 8066
values(1,'a'), (2,'b'), (3,'c'), (4,'d'), (11,'aa'), (12,'bb'), (13,'cc'), (14,'dd');
P148- MySQL- Mycat核心特性——分片(取模分片)
取余分片方式:分片键(一个列)与节点数量进行取余,得到余数,将数据写入对应节点
<table name="t4" dataNode="sh1,sh2" rule="mod-long" />
<property name="count">2</property>
mysql -S /data/3307/mysql.sock
create table t4 (id int not null primary key auto_increment,name varchar(20) not null);
mysql -S /data/3308/mysql.sock
create table t4 (id int not null primary key auto_increment,name varchar(20) not null);
测试取模分片:(插入成功后,登录到两个物理节点上,可以看到数据分开存放)
mysql -uroot -p123456 -h10.0.0.52 -P8066
values(1,'a'), (2,'b'), (3,'c'), (4,'d'), (11,'aa'), (12,'bb'), (13,'cc'), (14,'dd');
P149- MySQL- Mycat核心特性——分片(枚举分片)
<table name="t5" dataNode="sh1,sh2" rule="sharding-by-intfile" />
<tableRule name="sharding-by-intfile">
<algorithm>hash-int</algorithm>
<function name="hash-int" class="org.opencloudb.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="type">1</property>
<property name="defaultNode">0</property>
columns 标识将要分片的表字段,algorithm 分片函数, 其中分片函数配置中,mapFile标识配置文件名称
mysql -S /data/3307/mysql.sock
create table t5 (id int not null primary key auto_increment,name varchar(20) not null);"
mysql -S /data/3308/mysql.sock
create table t5 (id int not null primary key auto_increment,name varchar(20) not null);"
测试取模分片:(插入成功后,登录到两个物理节点上,可以看到数据分开存放)
mysql -uroot -p123456 -h192.168.3.122 -P8066
insert into t5(id,name) values(1,'bj');
insert into t5(id,name) values(2,'sh');
insert into t5(id,name) values(3,'bj');
insert into t5(id,name) values(4,'sh');
insert into t5(id,name) values(5,'tj');
P150- MySQL- Mycat核心特性——全局表(ER分片)
常用业务的配置或者数据量不大很少变动的表,这些表往往不是特别大,
而且大部分的业务场景都会用到,那么这种表适合于Mycat全局表,无须对数据进行切分,
要在所有的分片上保存一份数据即可,Mycat 在Join操作中,业务表与全局表进行Join聚合会优先选择相同分片内的全局表join,
避免跨库Join,在进行数据插入操作时,mycat将把数据分发到全局表对应的所有分片执行,在进行数据读取时候将会随机获取一个节点读取数据。
<table name="t_area" primaryKey="id" type="global" dataNode="sh1,sh2" />
mysql -S /data/3307/mysql.sock
create table t_area (id int not null primary key auto_increment,name varchar(20) not null);
mysql -S /data/3308/mysql.sock
create table t_area (id int not null primary key auto_increment,name varchar(20) not null);
mysql -uroot -p123456 -h10.0.0.52 -P8066
insert into t_area(id,name) values(1,'a');
insert into t_area(id,name) values(2,'b');
insert into t_area(id,name) values(3,'c');
insert into t_area(id,name) values(4,'d');
<table name="A" dataNode="sh1,sh2" rule="mod-long">
<childTable name="B" joinKey="yy" parentKey="xx" />
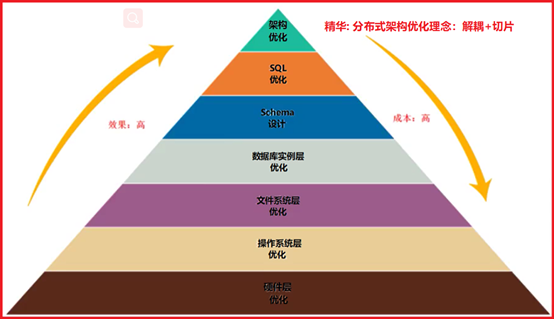
P151- MySQL-优化-优化哲学

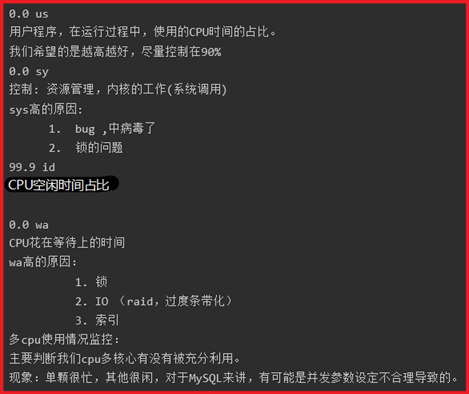
P152- MySQL-优化-Top(CPU指标)
控制器:资源管理 ---> 通过OS kernel(系统内核)调用,来管理硬件资源
%Cpu(s): 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
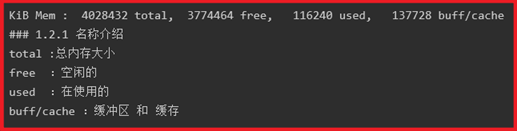
P153- MySQL-优化-Top(MEM-IO指标)
KiB Mem: 1003432 total, 940184 used, 63248 free, 0 buffers
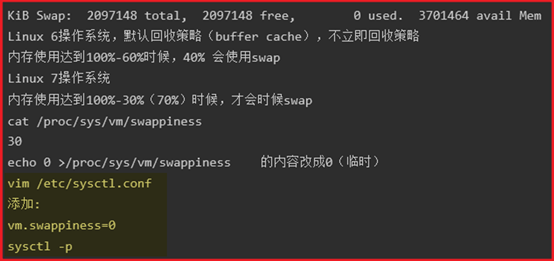
KiB Swap: 2097148 total, 582400 used, 1514748 free. 60024 cached Mem
Linux默认MEM使用到一定比例时,就会自动优先使用Swap;
但是对于数据库来说,要尽量避免使用Swap,等MEM耗尽后,让系统释放buffer cache来继续工作,以免使用Swap卡死
显示当前磁盘IO水平(kb/ms):iostat -dk 1(yum install -y sysstat)
② CPU us高,IO很低;MySQL不在做增删改查,有可能是存储过程数、排序、分组、
③ Wait,SYS高,IO低;IO出问题了,锁等待过多的几率比较大
④ IOPS达到最大值(IOPS:每秒磁盘最多能够发生的IO次数,这是个定值);
频繁小事务,IOPS很高,达到阈值;可能IO吞吐量没超过IO最大吞吐量;但也无法
(事务提交数据量太小,应该按磁盘最佳IO吞吐量,分段提交达到最佳效果)
P154- MySQL-优化-硬件(主机建议)




网络:保证网络的稳定持久可用,配置网络的高可用(建议主备模式)
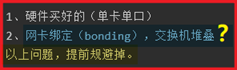
P156- MySQL-优化-硬件(系统建议)
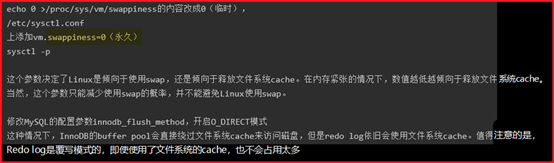

虚拟机vm12.5,OS centos 6.9(系统已优化),cpu*4(I5 4440 3.1GHZ),MEM*4GB ,HardDisk:SSD
drop database if exists oldboy;
create database oldboy charset utf8mb4 collate utf8mb4_bin;
create table t_100w (id int,num int,k1 char(2),k2 char(4),dt timestamp);
create procedure rand_data(in num int)
declare str char(62) default 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
set str2=concat(substring(str,1+floor(rand()*61),1),substring(str,1+floor(rand()*61),1));
set str4=concat(substring(str,1+floor(rand()*61),2),substring(str,1+floor(rand()*61),2));
insert into t_100w values (i,floor(rand()*num),str2,str4,now());
mysqlslap --defaults-file=/etc/my.cnf \
--concurrency=100 --iterations=1 --create-schema='oldboy' \
--query="select * from oldboy.t1000w where k2='FGCD'" engine=innodb \
--number-of-queries=200 -uroot -p123 -verbose
P158- MySQL-优化-参数优化-1
Mysql的最大连接数,mysql会为每个连接提供内存缓冲区,随着服务器的并发请求量增大,可以调高这个值,当然这是要建立在机器能够支撑的情况下
show variables like 'max_connections';
show status like 'Max_used_connections';
+----------------------+-------+
+----------------------+-------+
| Max_used_connections | 101 |
+----------------------+-------+
2.观察show status like 'Max_used_connections';变化
3.如果max_used_connections跟max_connections相同,
那么就是max_connections设置过低或者超过服务器的负载上限了,
发现大量的待连接进程时,就需要加大back_log或者加大max_connections的值
wait_timeout和interactive_timeout ****
wait_timeout:指的是mysql在关闭一个非交互的连接之前所要等待的秒数
interactive_timeout:指的是mysql在关闭一个交互的连接之前所需要等待的秒数,
注:wait_timeout:如果设置太小,那么连接关闭的就很快,从而使一些持久的连接
根据业务情况合理设置wait_timeout、interactive_timeout
interactive_timeout=1200(20分钟)
key_buffer_size指定索引缓冲区的大小,它决定索引处理的速度,尤其是索引读的速度
在有以上查询语句出现的时候,需要创建临时表,用完之后会被丢弃
通过key_read_requests和key_reads可以知道key_baffer_size设置是否合理。
mysql> show variables like "key_buffer_size%";
mysql> show status like "key_read%";
一共有10个索引读取请求,有2个请求在内存中没有找到直接从硬盘中读取索引
注:key_buffer_size只对myisam表起作用,即使不使用myisam表,但是内部的临时 磁盘表是myisam表,也要使用该值。
可以使用检查状态值created_tmp_disk_tables得知:
mysql> show status like "created_tmp%";
+-------------------------+-------+
+-------------------------+-------+
| Created_tmp_disk_tables | 0 |==》磁盘
| Created_tmp_tables | 1 |==》内存
+-------------------------+-------+
Created_tmp_tables/(Created_tmp_disk_tables+Created_tmp_tables)
Created_tmp_disk_tables/(Created_tmp_disk_tables + Created_tmp_tables)
或者已各自的一个时段内的差额计算,来判断基于内存的临时表利用率。所以,我们会
比较关注 Created_tmp_disk_tables 是否过多,从而认定当前服务器运行状况的优劣。
Created_tmp_disk_tables/(Created_tmp_disk_tables + Created_tmp_tables)
180322 17:39:33 7 Connect root@localhost on
7 Query /*!40100 SET @@SQL_MODE='' */
7 Query SHOW TABLES LIKE 'guo'
7 Query LOCK TABLES `guo` READ /*!32311 LOCAL */
7 Query SET OPTION SQL_QUOTE_SHOW_CREATE=1
7 Query show create table `guo`
7 Query show fields from `guo`
7 Query show table status like 'guo'
7 Query SELECT /*!40001 SQL_NO_CACHE */ * FROM `guo`
其中,有一步是:show fields from `guo`。从slow query记录的执行计划中,可以知道
所以说,以上公式并不能真正反映到mysql里临时表的利用率,有些情况下产生的
Tmp_table_on_disk 我们完全不用担心,因此没必要过分关注 Created_tmp_disk_tables, 但如果它的值大的离谱的话,那就好好查一下,你的服务器到底都在执行什么查询了。
(3)配置方法(8M跨度微调,,最大一般在 128-256之间)
P159- MySQL-优化-参数优化-2
query_cache_size ***(MYSQL-5.7默认关闭,8.0取消该参数)
查询缓存简称QC,使用查询缓冲,mysql将查询结果存放在缓冲区中,今后对于同样
的select语句(区分大小写),将直接从缓冲区中读取结果。
mysql> show variables like '%query_cache%' ;
+------------------------------+---------+
+------------------------------+---------+
| query_cache_limit | 1048576 |
| query_cache_min_res_unit | 4096 |
| query_cache_size | 1048576 |
| query_cache_wlock_invalidate | OFF |
+------------------------------+---------+
-------------------配置说明-------------------------------
以上信息可以看出query_cache_type为off表示不缓存任何查询
query_cache_limit:超过此大小的查询将不缓存
query_cache_size:查询缓存大小 (注:QC存储的最小单位是1024byte,所以如果你设 定了一个不是1024的倍数的值,这个值会被四舍五入到最接近当前值的等于1024的 倍数的值。)
query_cache_type:缓存类型,决定缓存什么样的查询,注意这个值不能随便设置,必 须设置为数字,可选项目以及说明如下:
如果设置为0,那么可以说,你的缓存根本就没有用,相当于禁用了。
如果设置为1,将会缓存所有的结果,除非你的select语句使用SQL_NO_CACHE禁用 了查询缓存。
如果设置为2,则只缓存在select语句中通过SQL_CACHE指定需要缓存的查询。
修改/etc/my.cnf文件,在[mysqld]下面添加如下内容
sort_buffer_size ***(以SQL优化为主,这个参数值有点就好)
Sort_Buffer_Size并不是越大越好,由于是connection级的参数,过大的设置+高并发可 能会耗尽系统内存资源。
例如:500个连接将会消耗500*sort_buffer_size(2M)=1G内存
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
mysql根据配置文件会限制,server接受的数据包大小。
有时候大的插入和更新会受max_allowed_packet参数限制,导致写入或者更新失败, 更大值是1GB,必须设置1024的倍数
select a.name,b.name from a join b on a.id=b.id where xxxx
用于表间关联缓存的大小,和sort_buffer_size一样,该参数对应的分配内存也是每个 连接独享;用完会释放。
服务器线程缓存,这个值表示可以重新利用保存在缓存中线程的数量,当断开连接时,那 么客户端的线程将被放到缓存中以响应下一个客户而不是销毁(前提是缓存数未达上
限),如果线程重新被请求,那么请求将从缓存中读取,如果缓存中是空的或者是新的请求, 那么这个线程将被重新创建,如果有很多新的线程,增加这个值可以改善系统性能.
通过比较 Connections 和 Threads_created 状态的变量,可以看到这个变量的作用。
设置规则如下:1GB 内存配置为8,2GB配置为16,3GB配置为32,4GB或更高内存, 可配置更大。
服务器处理此客户的线程将会缓存起来以响应下一个客户而不是销毁(前提是缓存数未 达上限)
mysql> show status like 'threads_%';
Threads_cached :代表当前此时此刻线程缓存中有多少空闲线程。
Threads_connected:代表当前已建立连接的数量,因为一个连接就需要一个线程,所以 也可以看成当前被使用的线程数。
Threads_running :代表当前激活的(非睡眠状态)线程数。并不是代表正在使用的线程 数,有时候连接已建立,但是连接处于sleep状态。
Threads_created :一般在架构设计阶段,会设置一个测试值,做压力测试。
如果在一段时间内,Threads_created趋于平稳,说明对应参数设定是OK。
如果一直陡峭的增长,或者出现大量峰值,那么继续增加此值的大小,在系统资源够用 的情况下(内存)
P160- MySQL-优化-参数优化-3
对于InnoDB表来说,innodb_buffer_pool_size的作用就相当于key_buffer_size对于 MyISAM表的作用一样。
对于单独的MySQL数据库服务器,最大可以把该值设置成物理内存的80%,一般我们建 议不要超过物理内存的70%。
innodb_flush_log_at_trx_commit ******
主要控制了innodb将log buffer中的数据写入日志文件并flush磁盘的时间点,取值分 别为0、1、2三个。
0,表示当事务提交时,不做日志写入操作,而是每秒钟将log buffer中的数据写入日 志文件并flush磁盘一次;
每次事务的提交都会引起redo日志文件写入、flush磁盘的操作,确保了事务的 ACID;
2,每次事务提交引起写入日志文件的动作,但每秒钟完成一次flush磁盘操作。
根据MySQL官方文档,在允许丢失最近部分事务的危险的前提下,可以把该值设为0 或2。
innodb_flush_log_at_trx_commit=1
innodb_thread_concurrency ***(多并发下的最优并发数量)
此参数用来设置innodb线程的并发数量,默认值为0表示不限制。
在官方doc上,对于innodb_thread_concurrency的使用,也给出了一些建议,如下:
如果一个工作负载中,并发用户线程的数量小于64,建议设置 innodb_thread_concurrency=0;
如果工作负载一直较为严重甚至偶尔达到顶峰,建议先设置 innodb_thread_concurrency=128,并通过不断的降低这个参数,96, 80, 64等等,直到
发现能够提供最佳性能的线程数,例如,假设系统通常有40到50个用户,但定期的数
量增加至60,70,甚至200。你会发现,性能在80个并发用户设置时表现稳定,
innodb_thread_concurrency参数为80,以避免影响性能。
如果你不希望InnoDB使用的虚拟CPU数量比用户线程使用的虚拟CPU更多(比如20 个虚拟CPU),建议通过设置innodb_thread_concurrency 参数为这个值(也可能更低,
这取决于性能体现),如果你的目标是将MySQL与其他应用隔离,你可以l考虑绑定
但是需 要注意的是,这种绑定,在myslqd进程一直不是很忙的情况下,可能会导致非 最优的硬件使用率。在这种情况下,你可能会设置mysqld进程绑定的虚拟 CPU,允许
在某些情况下,最佳的innodb_thread_concurrency参数设置可以比虚拟CPU的数量小。
定期检测和分析系统,负载量、用户数或者工作环境的改变可能都需要对 innodb_thread_concurrency参数的设置进行调整。
2. 发现不平均,先设置参数为cpu个数,然后不断增加(一倍)这个数值
3. 一直观察top状态,直到达到比较均匀时,说明已经到位了.
innodb_log_buffer_size(用内存换IO)
此参数确定些日志文件所用的内存大小,以M为单位。缓冲区更大能提高性能,对于 较大的事务,可以增大缓存大小。
innodb_log_file_size = 100M *****
此参数确定数据日志文件的大小,以M为单位,更大的设置可以提高性能.
##innodb_log_files_in_group = 3 *****
为提高性能,MySQL可以以循环方式将日志文件写到多个文件。推荐设置为3组
注:顺序读是指根据索引的叶节点数据就能顺序地读取所需要的行数据。随机读是指 需要根据辅助索引叶节点中的主键寻找实际行数据,而辅助索引和主键所在的数据段不 同,因此访问方式是随机的。
bulk_insert_buffer_size = 8M **
max_binlog_cache_size = 8M //表示的是binlog 能够使用的最大cache 内存大小
expire_logs_days = 7 //定义了mysql清除过期日志的时间。
二进制日志自动删除的天数。默认值为0,表示"没有自动删除"。
sync_binlog=1 什么时候刷新binlog到磁盘,每次事务commit
innodb_flush_log_at_trx_commit=1
Innodb_flush_method=(O_DIRECT, fsync)
(1)在数据页需要持久化时,首先将数据写入OS buffer中,然后由os决定什么时候写入 磁盘
2、 Innodb_flush_method=O_DIRECT
innodb_flush_log_at_trx_commit=1
innodb_flush_log_at_trx_commit=0
innodb_flush_log_at_trx_commit=1 ***************
log_bin=/data/binlog/mysql-bin
innodb_flush_log_at_trx_commit=1
P162- MySQL-优化-锁的监控及处理
UPDATE t_100w SET k1='av' WHERE id=10;
UPDATE t_100w SET k1='az' WHERE id=10;
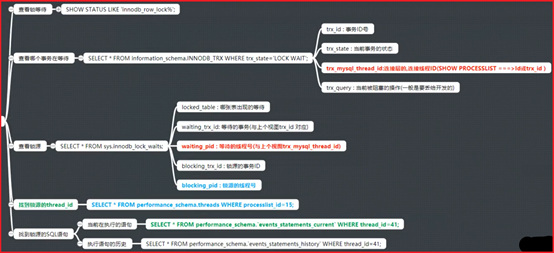
SHOW STATUS LIKE 'innodb_row_lock%';
Innodb_row_lock_current_waits:当前锁等待个数
SELECT * FROM information_schema.INNODB_TRX WHERE trx_state='LOCK WAIT';
trx_mysql_thread_id:连接层的,连接线程ID(SHOW PROCESSLIST ===>Id或trx_id )
trx_query : 当前被阻塞的操作(记录下来,一般是要丢给开发的)
SELECT * FROM sys.innodb_lock_waits; ## ====>被锁的和锁定它的之间关系
waiting_trx_id: 等待的事务(与上个视图trx_id 对应)
waiting_pid: 等待的线程号(与上个视图trx_mysql_thread_id)
SELECT * FROM performance_schema.threads WHERE processlist_id=15;
SELECT * FROM performance_schema.`events_statements_current` WHERE thread_id=41;
SELECT * FROM performance_schema.`events_statements_history` WHERE thread_id=41;
硬件环境: DELL R720,E系列16核,48G MEM,SAS*900G*6,RAID10
在例行巡检时,发现9-11点时间段的CPU压力非常高(80-90%)
1、通过top详细排查,发现mysqld进程占比达到了700-800%
2、其中有量的CPU是被用作的SYS和WAIT,us处于正常
4、经过排查slowlog及锁等待情况,发现有大量锁等待及少量慢语句
db03 [(none)]>show status like 'innodb_row_lock%';
+-------------------------------+-------+
+-------------------------------+-------+
| Innodb_row_lock_current_waits | 0 |
| Innodb_row_lock_time_avg | 0 |
| Innodb_row_lock_time_max | 0 |
+-------------------------------+-------+
有100多个current_waits,说明当前很多锁等待情况
1000多个lock_waits,说明历史上发生过的锁等待很多
(2) 开发人员查看后,发现是业务逻辑问题导致的死锁,产生了大量锁等待
经过排查处理,锁等待的个数减少80%.解决了CPU持续峰值的问题.
show status like 'innodb_rows_lock%'
select * from information_schema.innodb_trx;
select * from sys.innodb_lock_waits;
select * from performance_schema.threads;
select * from performance_schema.events_statements_current;
select * from performance_schema.events_statements_history;
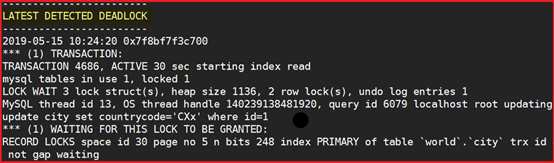
show variables like '%deadlock%';
innodb_print_all_deadlocks = 1
P163- MySQL-优化-主从优化
slave-parallel-type=LOGICAL_CLOCK
slave-parallel-workers=16 ## cpu核心数作为标准
relay_log_info_repository=TABLE
P164- MySQL课程梳理
Select from where group by having order by limit
Join on 函数 concat group concat
5. 精通innodb\tokudb\rocksdb等存储引擎原理
6. 精通mysqldump\xtrabackup生产备份、恢复、迁移及备份策略设计与实现
7. 精通Replication原理及主从故障,延时分析及处理
9. 精通主流读写分离架构架构Atlas\Mycat\proxySQL
11. 精通MySQL架构、系统、硬件、参数、锁、索引、主从全方位优化
12. 精通MongoDB、Redis、ES主流NoSQL分布式架构
14. 精通Percona-toolkit监控第三方管理优化工具
P165-NoSQL-Redis介绍
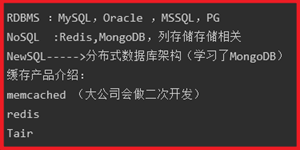

优点:高性能读写、单一数据类型、支持客户端式分布式集群、一致性hash
缺点:无持久化、节点故障可能出现缓存穿透、分布式需要客户端实现、跨机房数据同 步困难、架构扩容复杂度高
优点:高性能读写、多数据类型支持、数据持久化、高可用架构、支持自定义虚拟内存、 支持分布式分片集群、单线程读写性能极高
memcached 适合多用户访问,每个用户少量的rw(读写)
优点:高性能读写、支持三种存储引擎(ddb、rdb、ldb)、支持高可用、支持分布式分 片集群、支撑了几乎所有淘宝业务的缓存。
Memcached:多核的缓存服务,更加适合于多用户并发访问次数较少的应用场景
Redis:单核的缓存服务,单节点情况下,更加适合于少量用户,多次访问的应用场景。
P166-NoSQL-精通Redis安装部署
wget http://download.redis.io/releases/redis-3.2.12.tar.gz
yum -y install gcc automake autoconf libtool make
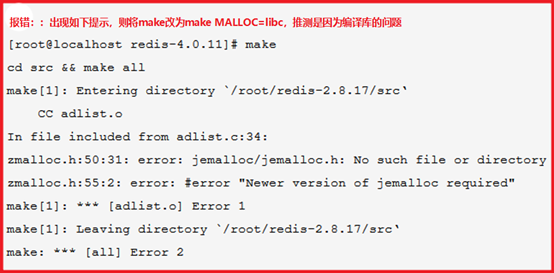
export PATH=/data/redis/src:$PATH
P167-NoSQL-精通Redis基本配置应用
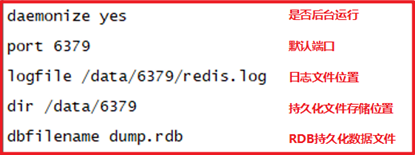
cat > /data/6379/redis.conf<<EOF
redis-cli shutdown // shutdown
redis-server /data/6379/redis.conf
P168-NoSQL-精通Redis安全管理
redis默认开启了保护模式,只允许本地回环地址登录并访问数据库。
protected-mode yes/no (保护模式,是否只允许本地访问)
指定IP进行监听并配置密码:(密码主要控制连接后进行的操作)
redis-server /data/6379/redis.conf
127.0.0.1:6379> set name zhangsan
redis-cli -a 123456 -h 192.168.3.122 -p 6379
P169-NoSQL-精通Redis在线查看和修改配置
在线查看//修改配置信息(重新登录后生效,重启后以配置文件为准):(共70个配置)
redis持久化(内存数据保存到磁盘):两种持久化方式同时存在默认使用AOF
可以在指定的时间间隔内生成数据集的 时间点快照(point-in-time snapshot)。
优点:速度快,适合于用做备份,主从复制也是基于RDB持久化功能实现的。
AOF 持久化(append-only log file) 相当于MySQL中的binlog日志
记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令
来还原数据集。 AOF 文件中的命令全部以 Redis 协议的格式来保存,新命令
redis-server /data/6379/redis.conf

P171-NoSQL-精通Redis数据类型种类
rdb:基于快照的持久化,速度更快,一般用作备份,主从复制也是依赖于rdb持久化 功能
aof:以追加的方式记录redis操作日志的文件。可以最大程度的保证redis数据安全, 类似于mysql的binlog
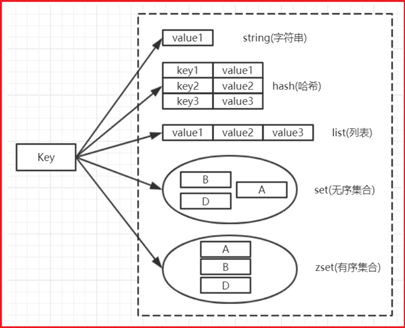
KEYS * keys a keys a* 查看已存在所有键的名字 ****
EXPIRE\ PEXPIRE 以秒\毫秒设定生存时间 ***
hash(字典类型)(一般使用工具由MySQL直接将数据同步到redis中)
hmset stu id 101 name zhangsan age 20 gender m
hmset stu1 id 102 name zhangsan1 age 21 gender f
手动编写MySQL脚本录入Redis脚本:(时间类型需要函数变化)
select concat("hmset t_",id," id ",id," name ",name," country ",country," dis ",dis,
" pop ",pop) from test where id<100 limit 10 into outfile '/tmp/hmset.txt'
cat /tmp/hmset.txt | redis-cli -a 123456
在Redis中我们的最新微博ID使用了常驻缓存,这是一直更新的。
但是做了限制不能超过5000个ID,因此获取ID的函数会一直询问Redis。
只有在start/count参数超出了这个范围的时候,才需要去访问数据库。
系统不会像传统方式那样"刷新"缓存,Redis实例中的信息永远是一致的。
SQL数据库(或是硬盘上的其他类型数据库)只是在用户需要获取"很远"的数据时才会 被触发,
案例:在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存 在一个集合。
Redis还为集合提供了求交集、并集、差集等操作,可以非常方便的实现如共同关 注、共同喜好、二度好友等功能,对上面的所有集合操作,你还可以使用不同的命
P177-NoSQL-精通Redis发布订阅
SUBSCRIBE channel [channel ...]
② 将信息 message 发送到指定的频道 channel
③ 取消订阅指定的频道, 如果不指定频道,则会取消订阅所有频道
PSUBSCRIBE pattern [pattern ...]
##订阅一个或多个符合给定模式的频道,每个模式以 * 作为匹配符,比如 it* 匹配
所有以 it 开头的频道( it.news 、 it.blog 、 it.tweets 等等)
PUNSUBSCRIBE [pattern [pattern ...]]
PUBSUB subcommand [argument [argument ...]]
注意:使用发布订阅模式实现的消息队列,当有客户端订阅channel后只能收到后续发布到 该频道的消息,之前发送的不会缓存,必须Provider和Consumer同时在线。
127.0.0.1:6379> SUBSCRIBE baodi
127.0.0.1:6379> PUBLISH baodi "jin tian zhen kaixin!"
127.0.0.1:6379> PSUBSCRIBE wang*
127.0.0.1:6379> PUBLISH wangbaoqiang "jintian zhennanshou "
P178-NoSQL-精通Redis发布订阅
提交事务:exec (对列中所有操作,要么全成功要么全失败)
窗口1:(在开启事务前监控键值,提交事务时根据键值是否改变,来执行事务或取消队列)
P179-NoSQL-精通Redis主从复制
redis(Master-Replicaset) *****
1. 副本库通过slaveof 192.168.3.122 6379命令,连接主库,并发送SYNC给主库
2. 主库收到SYNC,会立即触发BGSAVE,后台保存RDB,发送给副本库
5. 到此,我们主复制集就正常工作了再此以后,主库只要发生新的操作,都会以命令传播
7. 所有复制相关信息,从info信息中都可以查到.即使重启任何节点,他的主从关系依然
8. 如果发生主从关系断开时,从库数据没有任何损坏,在下次重连之后,从库发送PSYNC
9. 主库只会将从库缺失部分的数据同步给从库应用,达到快速恢复主从的目的
min-slaves-to-write 1 ##最少保证一台从库执行了操作,才认为当前事务成功
min-slaves-max-lag 3 ##延迟超过3秒,就认为此次操作失败
开启!!如果不开有可能,主库重启操作=数据全丢失,造成从库复制主库造成数据丢失!
cat >> /data/6380/redis.conf <<EOF
logfile "/data/6380/redis.log"
cat >> /data/6381/redis.conf <<EOF
logfile "/data/6381/redis.log"
cat >> /data/6382/redis.conf <<EOF
logfile "/data/6382/redis.log"
redis-server /data/6380/redis.conf
redis-server /data/6381/redis.conf
redis-server /data/6382/redis.conf
redis-cli -p 6381 -a 123 SLAVEOF 127.0.0.1 6380
redis-cli -p 6382 -a 123 SLAVEOF 127.0.0.1 6380
redis-cli -p 6380 -a 123 info replication
redis-cli -p 6381 -a 123 info replication
redis-cli -p 6382 -a 123 info replication
P181-监控锁及优化
P182-MySQL+ redis-sentinel(哨兵)
作用:基于redis主从环境;相当于MHA
① 监控
② 自动选主,切换(6381 slaveof no one)
③ 2号从库(6382)指向新主库(6381)
④ 应用透明
⑤ 自动处理故障节点
sentinel搭建过程:
mkdir -p /data/26380
cat>> /data/26380/sentinel.conf <<EOF
port 26380
dir "/data/26380"
sentinel monitor mymaster 127.0.0.1 6380 1
sentinel down-after-milliseconds mymaster 5000
sentinel auth-pass mymaster 123
EOF

启动:(记录到日志里方便查看)
redis-sentinel /data/26380/sentinel.conf &>/tmp/sentinel.log &

Sentinal功能测试:
关掉主库:
redis-cli -p 6381 -a 123 shutdown
查看主从(关掉主库5秒后完成切换):
redis-cli -p 6381 -a 123 info replication
重启6380:
redis-server /data/6380/redis.conf
查看主从(6380自动恢复为从库):
redis-cli -p 6381 -a 123 info replication
Sentinel管理命令:
redis-cli -p 26380
PING :返回 PONG 。
SENTINEL masters :列出所有被监视的主服务器
SENTINEL slaves <master name>
SENTINEL get-master-addr-by-name <master name> : 返回给定名字的主服务器的 IP 地址和端口号。
SENTINEL reset <pattern> : 重置所有名字和给定模式 pattern 相匹配的主服务器。
SENTINEL failover <master name> : 当主服务器失效时, 在不询问其他 Sentinel 意见的情况下, 强制开始一次自动故障迁移。
P183-MySQL+ redis-redis cluster(分布式)
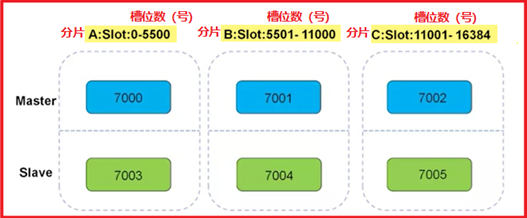
高性能:
1、在多分片节点中,将16384个槽位,均匀分布到3个分片节点中
2、存数据时,将key做hash运算,然后和16384进行取模,得出槽位值(0-16383之间)
3、根据计算得出的槽位值,找到相对应的分片节点的主节点,存储到相应槽位上
4、如果客户端当时连接的节点不是将来要存储的分片节点,分片集群会将客户端连接切换 至真正存储节点进行数据存储
高可用:
在搭建集群时,会为每一个分片的主节点,对应一个从节点,实现slaveof的功能,同时当主节点down,实现类似于sentinel的自动failover的功能。
Redis集群规划、搭建过程:
6个redis实例,一般会放到3台硬件服务器(端口号:7000-7005)
注:在企业规划中,一个分片的两个分到不同的物理机,防止硬件主机宕机造成的整个分片 数据丢失。
安装集群插件:
EPEL源安装ruby支持
yum install ruby rubygems -y
使用国内源:(添加新源,删除旧源,下载插件)
gem sources -l
gem sources -a http://mirrors.aliyun.com/rubygems/
gem sources --remove https://rubygems.org/
gem sources -l
gem install redis -v 3.3.3
集群节点准备:
mkdir -p /data/700{0..5}
cat > /data/7000/redis.conf <<EOF
port 7000
daemonize yes
pidfile /data/7000/redis.pid
loglevel notice
logfile "/data/7000/redis.log"
dbfilename dump.rdb
dir /data/7000
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
cat >> /data/7001/redis.conf <<EOF
port 7001
daemonize yes
pidfile /data/7001/redis.pid
loglevel notice
logfile "/data/7001/redis.log"
dbfilename dump.rdb
dir /data/7001
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
cat >> /data/7002/redis.conf <<EOF
port 7002
daemonize yes
pidfile /data/7002/redis.pid
loglevel notice
logfile "/data/7002/redis.log"
dbfilename dump.rdb
dir /data/7002
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
cat >> /data/7003/redis.conf <<EOF
port 7003
daemonize yes
pidfile /data/7003/redis.pid
loglevel notice
logfile "/data/7003/redis.log"
dbfilename dump.rdb
dir /data/7003
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
cat >> /data/7004/redis.conf <<EOF
port 7004
daemonize yes
pidfile /data/7004/redis.pid
loglevel notice
logfile "/data/7004/redis.log"
dbfilename dump.rdb
dir /data/7004
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
cat >> /data/7005/redis.conf <<EOF
port 7005
daemonize yes
pidfile /data/7005/redis.pid
loglevel notice
logfile "/data/7005/redis.log"
dbfilename dump.rdb
dir /data/7005
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
启动节点:
redis-server /data/7000/redis.conf
redis-server /data/7001/redis.conf
redis-server /data/7002/redis.conf
redis-server /data/7003/redis.conf
redis-server /data/7004/redis.conf
redis-server /data/7005/redis.conf
验证节点是否启动:
ps -ef |grep redis

将节点加入集群管理:(按提示输入yes;;默认前三IP为主,后三IP为从;;
从库要变换位置不与主库同IP)
redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 \
127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
redis-cli -p 7000 cluster nodes | grep master

redis-cli -p 7000 cluster nodes | grep slave
增加新的节点:(非业务繁忙期操作,分配槽位中若有数据,会一并分配,影响性能)
cat > /data/7006/redis.conf <<EOF
logfile "/data/7006/redis.log"
cluster-config-file nodes.conf
cat > /data/7007/redis.conf <<EOF
logfile "/data/7007/redis.log"
cluster-config-file nodes.conf
redis-server /data/7006/redis.conf
redis-server /data/7007/redis.conf
redis-trib.rb add-node 127.0.0.1:7006 127.0.0.1:7000
redis-trib.rb reshard 127.0.0.1:7000

redis-cli -p 7000 cluster nodes | grep master
添加一个从节点:(指定要绑定到的主节点id:7006的id号)
redis-cli -p 7000 cluster nodes | grep slave
转移slot(重新分片,将要删除节点slot移动走;移动走后确认下该节点没有slot)
redis-trib.rb reshard 127.0.0.1:7000
redis-trib.rb del-node 127.0.0.1:7006 2348689602d3e1d8d386880195a2f34skdfghos6
redis-trib.rb del-node 127.0.0.1:7007 1444c684003f9689602d3e1d8d386880195a2f34
config set maxmemory 102400000
P187-MySQL+ redis-多API支持for Python
++++++++++++YUM方式+++++++++++++++
++++++++++++源码方式+++++++++++++++
redis cluster的连接并操作(python2.7.2以上版本才支持redis cluster,我们选择的是3.6)
https://github.com/Grokzen/redis-py-cluster
+++++++++++++++++++++++++++++++++
redis-server /data/6379/redis.conf
>>>r = redis.StrictRedis(host='127.0.0.1', port=6379, db=0,password='123456')

>>>from redis.sentinel import Sentinel
>>> sentinel = Sentinel([('localhost', 26380)], socket_timeout=0.1)
>>> sentinel.discover_master('mymaster')
>>> sentinel.discover_slaves('mymaster')
>>> master = sentinel.master_for('mymaster', socket_timeout=0.1,password="123")
>>> slave = sentinel.slave_for('mymaster', socket_timeout=0.1,password="123")
>>> master.set('oldboy', '123')
通过python连接redis cluster集群:(更换驱动退出重进)
加载Cluster驱动:pip3 install redis-py-cluster
>>> from rediscluster import StrictRedisCluster
### Note: decode_responses must be set to True when used with python3
>>> rc = StrictRedisCluster(startup_nodes=startup_nodes,decode_responses=True)
访问一个不存在的key,缓存不起作用,请求会穿透到DB,流量大时DB会挂掉。
采用布隆过滤器,使用一个足够大的bitmap,用于存储可能访问的key,不存在的key 直接被过滤;
访问key未在DB查询到值,也将空值写进缓存,但可以设置较短过期时间。
大量的key设置了相同的过期时间,导致在缓存在同一时刻全部失效,造成瞬时DB请 求量大、压力骤增,引起雪崩。
可以给缓存设置过期时间时加上一个随机值时间,使得每个key的过期时间分布开来, 不会集中在同一时刻失效。
一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到DB,造 成瞬时DB请求量大、压力骤增。
在访问key之前,采用SETNX(set if not exists)来设置另一个短期key来锁住当前key 的访问,访问结束再删除该短期key。
P188-MongDB核心技术(运维篇)
远程工具设置:选项 –> 会话选项 –> 终端 –> 仿真 –> 终端中选择linux 即可

(4)iptables防火墙&SElinux关闭(root)
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo never > /sys/kernel/mm/transparent_hugepage/enabled
if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo never > /sys/kernel/mm/transparent_hugepage/defrag
cat /sys/kernel/mm/transparent_hugepage/enabled
cat /sys/kernel/mm/transparent_hugepage/defrag
https://docs.mongodb.com/manual/tutorial/transparent-huge-pages/
You should disable THP on Linux machines to ensure best performance with MongoDB.
##################################################################
mkdir -p /mongodb/{conf,log,data}/
https://www.mongodb.com/download-center/community
解压软件并拷贝bin目录到指定位置:
cd /data
tar xf mongodb-linux-x86_64-rhel70-3.6.17.tgz
cp -r /data/mongodb-linux-x86_64-rhel70-3.6.17/bin/ /mongodb:
设置目录结构权限:
chown -R mongod:mongod /mongodb
设置私有用户环境变量:
su – mongod
vi .bash_profile
export PATH=/mongodb/bin:$PATH
mongod --dbpath=/mongodb/data --logpath=/mongodb/log/mongodb.log --port=27017 --logappend --fork
path: "/mongodb/log/mongodb.log" --日志位置
dbPath: "/mongodb/data" --数据路径的位置
pidFilePath: <string> --pid文件的位置,一般不用配置,可以去掉这行,自动生成到data中
port: <port> -- 端口号,默认不配置端口号,是27017
authorization: enabled --是否打开用户名密码验证
------------------以下是复制集与分片集群有关----------------------
cat > /mongodb/conf/mongo.conf <<EOF
path: "/mongodb/log/mongodb.log"
bindIp: 192.168.3.122,127.0.0.1
mongod -f /mongodb/conf/mongo.conf --shutdown
mongod -f /mongodb/conf/mongo.conf
cat > /etc/systemd/system/mongod.service <<EOF
After=network.target remote-fs.target nss-lookup.target
ExecStart=/mongodb/bin/mongod --config /mongodb/conf/mongo.conf
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/mongodb/bin/mongod --config /mongodb/conf/mongo.conf --shutdown
P189-MongDB-常用命令基本操作
P191-MongDB-对象操作
{ "dropped" : "test", "ok" : 1 }
db.test.insert({name:"zhangsan"})
db.stu.insert({id:101,name:"zhangsan",age:20,gender:"m"})
db.stu.insert({id:102,name:"lisi"})
for(i=0;i<10000;i++){db.log.insert({"uid":i,"name":"mongodb","age":6,"date":new
> db.log.find({uid:999}).pretty()
"_id" : ObjectId("5cc516e60d13144c89dead33"),
"date" : ISODate("2019-04-28T02:58:46.109Z")
app> db.log.totalSize() //集合中索引+数据压缩存储之后的大小
P193-MongDB-用户及权限管理
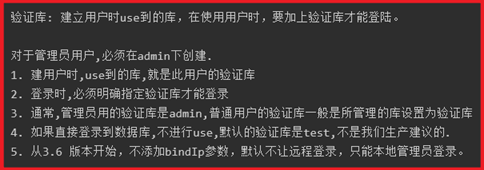
db: "<database>" } | "<role>",
mongo -u oldboy -p 123 10.0.0.53/oldboy
创建超级管理员:管理所有数据库(必须use admin再去创建)
roles: [ { role: "root", db: "admin" } ]
mongo -uroot -proot123 10.0.0.53:27017/admin
db.system.users.find().pretty()
roles: [ { role: "readWrite" , db: "oldboy" } ]
mongo -uroot -proot123 10.0.0.53:27017/admin
db.system.users.find().pretty()
db.createUser({user: "app02",pwd: "app02",roles: [ { role: "readWrite" , db: "oldboy1" } ]})
mongo -uroot -proot123 10.0.0.53:27017/admin
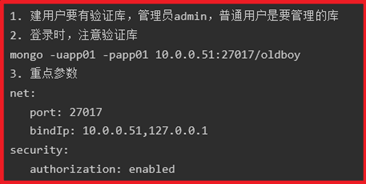
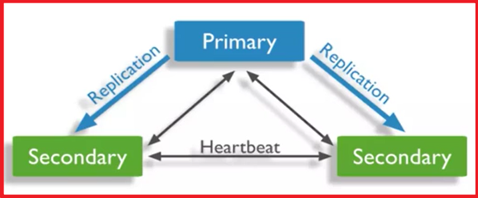
P194-MongDB-复制集RS(ReplicationSet)

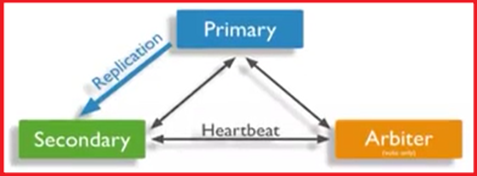 一主一从一投票:(更建议使用,投票机没数据只投票)
一主一从一投票:(更建议使用,投票机没数据只投票)
mkdir -p /mongodb/28017/{conf,data,log}/
mkdir -p /mongodb/28018/{conf,data,log}/
mkdir -p /mongodb/28019/{conf,data,log}/
mkdir -p /mongodb/28020/{conf,data,log}/
cat > /mongodb/28017/conf/mongod.conf <<EOF
path: /mongodb/28017/log/mongodb.log
bindIp: 192.168.3.122,127.0.0.1
\cp /mongodb/28017/conf/mongod.conf /mongodb/28018/conf/
\cp /mongodb/28017/conf/mongod.conf /mongodb/28019/conf/
\cp /mongodb/28017/conf/mongod.conf /mongodb/28020/conf/
sed 's#28017#28018#g' /mongodb/28018/conf/mongod.conf -i
sed 's#28017#28019#g' /mongodb/28019/conf/mongod.conf -i
sed 's#28017#28020#g' /mongodb/28020/conf/mongod.conf -i
mongod -f /mongodb/28017/conf/mongod.conf
mongod -f /mongodb/28018/conf/mongod.conf
mongod -f /mongodb/28019/conf/mongod.conf
mongod -f /mongodb/28020/conf/mongod.conf
config = {_id: 'my_repl', members: [
{_id: 0, host: '192.168.3.122:28017'},
{_id: 1, host: '192.168.3.122:28018'},
{_id: 2, host: '192.168.3.122:28019'}]
config = {_id: 'my_repl', members: [
{_id: 0, host: '192.168.3.122:28017'},
{_id: 1, host: '192.168.3.122:28018'},
{_id: 2, host: '192.168.3.122:28019',"arbiterOnly":true}]
rs.remove("ip:port"); // 删除一个节点
rs.addArb("ip:port"); // 新增仲裁节点
arbiter节点:主要负责选主过程中的投票,但是不存储任何数据,也不提供任何服务
delay节点:延时节点,数据落后于主库一段时间,因为数据是延时的,也不应该提供 服务或参与选主,所以通常会配合hidden(隐藏)
[2]是conf中的id顺序排序数,有修改后需要数一下,会丢失id的
admin> rs.freeze(300) //锁定从,使其不会转变成主库
{ "ok" : 0, "errmsg" : "not master", "code" : 10107 }
admin> rs.printSlaveReplicationInfo()
syncedTo: Thu May 26 2016 10:28:56 GMT+0800 (CST)
0 secs (0 hrs) behind the primary
P198-MongDB-Sharding Cluster 分片集群
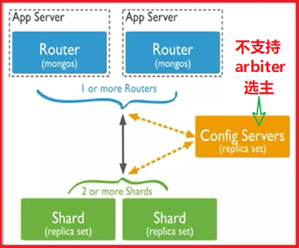
3台构成的复制集(1主两从,不支持arbiter)38018-38020(复制集名字configsvr)
sh1:38021-23 (1主两从,其中一个节点为arbiter,复制集名字sh1)
sh2:38024-26 (1主两从,其中一个节点为arbiter,复制集名字sh2)
mkdir -p /mongodb/38021/{conf,log,data}/
mkdir -p /mongodb/38022/{conf,log,data}/
mkdir -p /mongodb/38023/{conf,log,data}/
mkdir -p /mongodb/38024/{conf,log,data}/
mkdir -p /mongodb/38025/{conf,log,data}/
mkdir -p /mongodb/38026/{conf,log,data}/
cat > /mongodb/38021/conf/mongodb.conf <<EOF
path: /mongodb/38021/log/mongodb.log
bindIp: 192.168.3.122,127.0.0.1
\cp /mongodb/38021/conf/mongodb.conf /mongodb/38022/conf/
\cp /mongodb/38021/conf/mongodb.conf /mongodb/38023/conf/
sed 's#38021#38022#g' /mongodb/38022/conf/mongodb.conf -i
sed 's#38021#38023#g' /mongodb/38023/conf/mongodb.conf -i
cat > /mongodb/38024/conf/mongodb.conf <<EOF
path: /mongodb/38024/log/mongodb.log
bindIp: 192.168.3.122,127.0.0.1
\cp /mongodb/38024/conf/mongodb.conf /mongodb/38025/conf/
\cp /mongodb/38024/conf/mongodb.conf /mongodb/38026/conf/
sed 's#38024#38025#g' /mongodb/38025/conf/mongodb.conf -i
sed 's#38024#38026#g' /mongodb/38026/conf/mongodb.conf -i
mongod -f /mongodb/38021/conf/mongodb.conf
mongod -f /mongodb/38022/conf/mongodb.conf
mongod -f /mongodb/38023/conf/mongodb.conf
mongod -f /mongodb/38024/conf/mongodb.conf
mongod -f /mongodb/38025/conf/mongodb.conf
mongod -f /mongodb/38026/conf/mongodb.conf
ps -ef |grep mongod / netstat -lnt|grep 3802
config = {_id: 'sh1', members: [
{_id: 0, host: '192.168.3.122:38021'},
{_id: 1, host: '192.168.3.122:38022'},
{_id: 2, host: '192.168.3.122:38023',"arbiterOnly":true}]
config = {_id: 'sh2', members: [
{_id: 0, host: '192.168.3.122:38024'},
{_id: 1, host: '192.168.3.122:38025'},
{_id: 2, host: '192.168.3.122:38026',"arbiterOnly":true}]
mkdir -p /mongodb/38018/{conf,log,data}/
mkdir -p /mongodb/38019/{conf,log,data}/
mkdir -p /mongodb/38020/{conf,log,data}/
cat > /mongodb/38018/conf/mongodb.conf <<EOF
path: /mongodb/38018/log/mongodb.conf
bindIp: 192.168.3.122,127.0.0.1
\cp /mongodb/38018/conf/mongodb.conf /mongodb/38019/conf/
\cp /mongodb/38018/conf/mongodb.conf /mongodb/38020/conf/
sed 's#38018#38019#g' /mongodb/38019/conf/mongodb.conf -i
sed 's#38018#38020#g' /mongodb/38020/conf/mongodb.conf -i
mongod -f /mongodb/38018/conf/mongodb.conf
mongod -f /mongodb/38019/conf/mongodb.conf
mongod -f /mongodb/38020/conf/mongodb.conf
config = {_id: 'configReplSet', members: [
{_id: 0, host: '192.168.3.122:38018'},
{_id: 1, host: '192.168.3.122:38019'},
{_id: 2, host: '192.168.3.122:38020'}]
注:configserver 可以是一个节点,官方建议复制集。configserver不能有arbiter。
注:mongodb 3.4之后,虽然要求config server为replica set,但是不支持arbiter
mkdir -p /mongodb/38017/conf /mongodb/38017/log
cat > /mongodb/38017/conf/mongos.conf <<EOF
path: /mongodb/38017/log/mongos.log
bindIp: 192.168.3.122,127.0.0.1
configDB: configReplSet/192.168.3.122:38018,192.168.3.122:38019,192.168.3.122:38020
mongos -f /mongodb/38017/conf/mongos.conf
连接到其中一个mongos(192.168.3.122),做以下配置
$ mongo 192.168.3.122:38017/admin
mongos> db.runCommand( { listshards : 1 } )
P201-MongDB-Sharding Cluster 分片使用
admin> ( { enablesharding : "数据库名称" } )
admin> db.runCommand( { enablesharding : "test" } )
> db.vast.ensureIndex( { id: 1 } )
> db.runCommand( { shardcollection : "test.vast",key : {id: 1} } )
admin> db.runCommand( { enablesharding : "oldboy" } )
oldboy> db.vast.ensureIndex( { id: "hashed" } )
admin > sh.shardCollection( "oldboy.vast", { id: "hashed" } )
for(i=1;i<100000;i++){ db.vast.insert({"id":i,"name":"shenzheng","age":70,"date":new Date()}); }
P203-MongDB-Sharding Cluster-balancer 时间窗口
db.runCommand( { removeShard: "shard2" } )
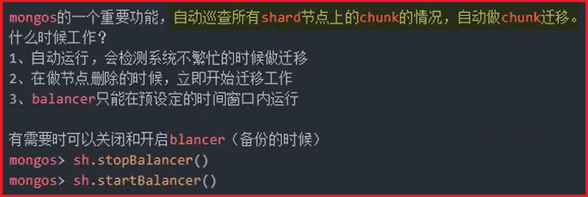
设定balancer时间窗口:(避开业务繁忙期,及备份时间段)
sh.disableBalancing("students.grades")
sh.enableBalancing("students.grades")
db.getSiblingDB("config").collections.findOne({_id : "students.grades"}).noBalance;
P204-MySQL-MongDB-异构平台迁移
(1)** mongoexport/mongoimport(逻辑迁移,格式:json,csv(excl表格))
(2)***** mongodump/mongorestore(物理备份)
导出/导入工具mongoexport/mongoimport
--authenticationDatabase admin
select * from world.city into outfile '/tmp/city1.csv' fields terminated by ',';
db.city.find({CountryCode:"CHN"});
select * from world.city into outfile '/tmp/world_city.csv' fields terminated by ',';
from information_schema.tables where table_schema ='world';
提示,使用infomation_schema.columns + information_schema.tables
fields terminated by ',' ------字段间以,号分隔
optionally enclosed by '"' ------字段用"号括起
escaped by '"' ------字段中使用的转义符为"
lines terminated by '\r\n'; ------行以\r\n结束
load data infile '/tmp/test.csv'
mongodump能够在Mongodb运行时进行备份,它的工作原理是对运行的Mongodb做查询,然后将所有查到的文档写入磁盘。
但是存在的问题时使用mongodump产生的备份不一定是数据库的实时快照,如果我们在备份时对数据库进行了写入操作,
则备份出来的文件可能不完全和Mongodb实时数据相等。另外在备份时可能会对其它客户端性能产生不利的影响。
-j, --numParallelCollections= number of collections to dump in parallel (4 by default)
mongodump -uroot -proot123 --port 27017 --authenticationDatabase admin -o /mongodb/backup
mongodump -uroot -proot123 --port 27017 --authenticationDatabase admin -d world -o /mongodb/backup/
P205-mongodump和mongorestore高级企业应用(--oplog)
注意:这是replica set(复制集)或者master/slave模式专用
use oplog for taking a point-in-time snapshot
在replica set中oplog是一个定容集合(capped collection),它的默认大小是磁盘空间的5%(可以通过--oplogSizeMB参数修改).
位于local库的db.oplog.rs,有兴趣可以看看里面到底有些什么内容。
其中记录的是整个mongod实例一段时间内数据库的所有变更(插入/更新/删除)操作。
其覆盖范围被称作oplog时间窗口。需要注意的是,因为oplog是一个定容集合,
所以时间窗口能覆盖的范围会因为你单位时间内的更新次数不同而变化。
"ts" : Timestamp(1553597844, 1),时间戳
configured oplog size: 1561.5615234375MB <--集合大小
log length start to end: 423849secs (117.74hrs) <--预计窗口覆盖时间
oplog first event time: Wed Sep 09 2015 17:39:50 GMT+0800 (CST)
oplog last event time: Mon Sep 14 2015 15:23:59 GMT+0800 (CST)
now: Mon Sep 14 2015 16:37:30 GMT+0800 (CST)
for(var i = 1 ;i < 100; i++) {
db.oplog.rs.find({"op":"i"}).pretty()
mongodump --port 28018 --oplog -o /mongodb/backup
作用介绍:--oplog 会记录备份过程中的数据变化。会以oplog.bson保存下来
mongorestore --port 28018 --oplogReplay /mongodb/backup
4、截取全备之后到world.city误删除时间点的oplog,并恢复到测试库
mongodump --port 28018 --oplog -o /mongodb/backup
--oplog功能:在备份同时,将备份过程中产生的日志进行备份
文件必须存放在/mongodb/backup下,自动命令为oplog.bson
mongodump --port 28018 -d local -c oplog.rs -o /mongodb/backup
[mongod@db03 local]$ mongo --port 28018
db.oplog.rs.find({op:"c"}).pretty();
"ts" : Timestamp(1553659908, 1),
"h" : NumberLong("-7439981700218302504"),
"ui" : UUID("db70fa45-edde-4945-ade3-747224745725"),
"wall" : ISODate("2019-03-27T04:11:48.890Z"),
"ts" : Timestamp(1553659908, 1)
[mongod@db03 backup]$ cd /mongodb/backup/local/
oplog.rs.bson oplog.rs.metadata.json
[mongod@db03 local]$ cp oplog.rs.bson ../oplog.bson
mongorestore --port 38021 --oplogReplay --oplogLimit "1553659908:1" --drop /mongodb/backup/
Percona Toolkit-3.1
https://www.cnblogs.com/zhs0/p/10600318.html
Percona Toolkit简称pt工具—PT-Tools,是Percona公司开发用于管理MySQL的工具,功能包括检查主从复制的数据一致性、检查重复索引、定位IO占用高的表文件、在线DDL等
下载地址:https://www.percona.com/downloads/percona-toolkit/LATEST/
安装:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号