数据驱动
在做自动化过程,测试数据分离后需考虑如何存储,这个是自动化的核心之一,分离的数据存储方式几种,一种存储到数据库这种需要搭建数据库成本较高,另外一个就是存储到文件种这种笔记简单,那么存储到文件种有多种方式,如存到 ini、csv、txt等,下面一一介绍一下各种文件处理。
1、config配置文件
对config配置文件处理,使用configparser库,以下列出简单用法,具体详细方法内容可看configparser库
1 import configparser 2 3 def configtest(): 4 config = configparser.ConfigParser() 5 config.read('config.ini') 6 section = config.options('MYSQL') #获取MYSQL options
7 print(section) 8 print(config.get('MYSQL','hostname'))
2、csv文件
对csv文件处理,使用csv库,以下列出简单用法,具体详细方法内容可看csv库
1 import csv 2 ''' 3 读写:列表和字典方式 4 ''' 5 class csvtest(object): 6 header=["姓名","语文","数学","英语"] 7 dicts=[ 8 {"姓名":"张三","语文":"99","数学":"98","英语":"97"}, 9 {"姓名":"李四","语文":"99","数学":"98","英语":"100"} 10 ] 11 12 @property 13 def writeCsvList(self): #列表方式写入 14 with open('datacsvlist.csv','w',encoding='utf-8',newline='') as f: 15 w = csv.writer(f) 16 w.writerow(self.header) 17 for item in self.dicts: 18 w.writerow(item.values()) 19 20 21 @property 22 def writeCsvDict(self): #字典方式写入 23 with open('datacsvdict.csv','w',encoding='utf-8',newline='') as f: 24 w = csv.DictWriter(f,self.header) 25 w.writeheader() 26 w.writerows(self.dicts) 27 28 @property 29 def readCsvList(self): #列表方式读取 30 with open('datacsvlist.csv', 'r', encoding='utf-8' ) as f: 31 w = csv.reader(f) 32 next(w) 33 for item in w: 34 print(item) 35 36 @property 37 def readCsvDict(self): #字典方式读取 38 with open('datacsvdict.csv', 'r', encoding='utf-8') as f: 39 w = csv.DictReader(f) 40 for item in w: 41 print(dict(item))
3、excel文件
对excel文件处理使用xrld库,以下列出简单用法,具体其他用法可查看xrld源码
1 import xlrd 2 3 obj = xlrd.open_workbook('chengji.xlsx') 4 #操作进入sheet 5 sheet = obj.sheet_by_name('Sheet1') 6 print(sheet.ncols) #获取列数 7 print(sheet.nrows) #获取行数 8 print(sheet.cell_value(1,3))
4、json文件
对json文件处理使用json库,读取过程进行序列化和反序列化以下列出简单用法,具体其他用法可查看json源码
以下为json内容:
1 { 2 "张三":{"语文":"98","数学":"99","英语":"99"}, 3 "李四":{"语文":"99","数学":"99","英语":"99"} 4 }
1 import json 2 3 with open('chengji.json','r',encoding='utf-8') as f: 4 dict1 = json.loads(f.read()) #反序列化处理 5 print(dict1)
5、txt文件
1 with open('chengji.txt','r',encoding='utf-8') as f: 2 t = f.readlines() 3 print(t)
6、在自动化过程可能需要记录日志,可以使用logging库处理
1 import logging 2 3 logging.basicConfig( 4 format='%(asctime)s-%(name)s-%(levelname)s-%(module)s:%(message)s', 5 datefmt='%y-%m-%d %H:%M:%S', 6 level=10) 7 8 logging.debug('this is a test log') 9 logging.warning('这是⼀个警告⽇志') 10 logging.info('这是⼀个基本的信息')
7、ymal文件
对yaml文件处理,使用库yaml
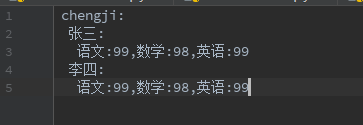
1 import yaml 2 3 with open('chengji.ymal','r',encoding='utf-8') as f: 4 y = yaml.safe_load(f) 5 print(y) 6 print(y['chengji']['张三'])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号