
模块的详解
模块
(1)什么是模块?
一个模块就是一个python文件,文件名就是模块名字加上.py后缀。因此模块名称也必须符合变量名的命名规范。
(2)为什么要使用模块?
每次退出python解释器的时候,再打开时,内存原本存储的变量和函数都会消失,如果想持久使用,就需要保持到文件中。每次执行需要“python xxx.py”的形式,这个时候xxx.py就称为脚本。随着程序需求的越来越来复杂,功能越来越多,为了更好的管理代码,就需要把程序拆成一个个文件,此时,这个文件不仅仅可以可以当成一个脚本去执行,还可以作为模块导入到另外一个模块中使用。
(3)如何使用模块
方式一:import
方式二:from...import...
接下来将详细地讲解两个方式的用法。
import
首先,定义一个my_module模块。


name = 'my module' def my_module_func(): print(name) print('in my module')
- 在import一个模块的过程中,发生了哪些事情?
# 用import导入my_module模块 import my_module >>> in my module #怎么回事,竟然执行了my_module模块中的print语句
import my_module
import my_module
import my_module
import my_module
import my_module
>>>
in my module #只打印一次
从上面的结果可以看出,import一个模块的时候相当于执行了这个模块,而且一个模块是不会重复被导入的,只会导入一次(python解释器第一次就把模块名加载到内存中,之后的import都只是在对应的内存空间中寻找。)成功导入一个模块后,被导入模块与本文件之间的命名空间的问题,就成为接下来要搞清楚的概念了。
- 被导入模块与本文件之间命名空间的关系?
假设当前文件也有一个变量为:name = 'local file',也有一个同名的func方法。
# 本地文件
name = 'local file'
def func():
print(name)
#本地文件有跟被导入模块同名的变量和函数,究竟用到的是哪个呢?
import my_module
print(my_module.name) #根据结果可以看出,引用的是模块里面的name
my_module.func() #执行的是模块里面的func()函数
>>>
my module
my module
print(name) #使用的是本地的name变量
func() #调用的是本地的func函数
>>>
local file
local file
#############################################################
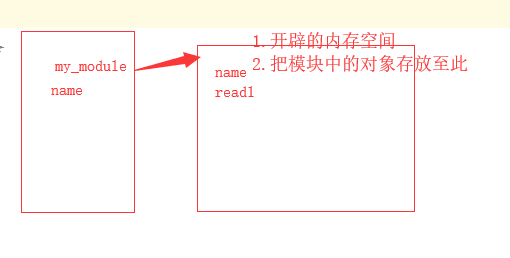
在import模块的时候发生了下面几步:
(1)先寻找模块
(2)如果找到了,就在内存中开辟一块空间,从上至下执行这个模块。
(3)把这个模块中用到的对象都收录到新开辟的内存空间中。
(4)给这个内存空间创建一个变量指向这个空间,用来引用其内容。
总之,模块和文件之间的内存空间始终是隔离的。
#############################################################
- 如果同时导入多个模块?
方式一:每行导入一个模块
import os import time
方式二:一行导入多个模块,模块之间通过逗号","来分隔
import os,time,my_module
但是,根据PEP8规范规定使用第一种方式,并且三种模块有先后顺序(内置>第三方>自定义)
#根据PEP8规范
import os
import django
import my_module
- 给导入的模块取别名,用as关键字
如果导入的模块名太长不好记,那么可以通过“import 模块名 as 别名”的方式给模块名取一个别名,但此时原来的模块就不再生效了(相当于创建了新的变量名指向模块内存空间,断掉原模块名的引用)。
# 给my_module模块取别名 import my_module as m print(m.name) >>> my module print(my_module.name) #取了别名后,原来的模块名就不生效了 >>> NameError: name 'my_module' is not defined
给模块取别名,还可以使得代码更加灵活,减少冗余,常用在根据用户输入的不同,调用不同模块。
#(1)按照先前的做法,写一个函数,根据用户传入的序列化模块,使用对应的方法
def dump(method):
if method == 'json':
import json
with open('dump.txt','wb') as f:
json.dump('xxx',f)
elif method == 'pickle':
import pickle
with open('dump.txt','wb') as f:
pickle.dump('xxx',f)
#上面的代码冗余度很高,如果简化代码?通过模块取别名的方式,可以减少冗余
def dump(method):
if method == 'json':
import json as m
elif method == 'pickle'
import pickle as m
with open('dump.txt','wb') as f:
m.dump('xxx',f)
- 模块搜索路径
通过之前对sys内置模块的学习,我们知道sys.path存储了所有模块的路径,但是正常的sys.path的路径中除了内置模块,第三方模块所在的路径之外,只有一个路径是永远正确的,就是当前执行的文件所有在目录。一个模块是否能够被导入,就取决于这个模块所在的目录是否在sys.path中。
import sys
print(sys.path)
sys.path.append('这个文件所在的目录路径')
- 模块和脚本
运行一个py文件有两种方式,但是这个两种执行方式之间有一个明显的差别,就是__name__。
(1)以脚本的方式执行:cmd中“python xxx.py”或者pycharm等IDE中执行。
__name__ = '__main__'
(2)导入模块时执行:import模块,会执行该模块。
__name__ = 模块名
然而,当你有一个py文件既可以作为脚本执行,又可以作为模块提供给其他模块引用时,这时作为模块需要导入时不显示多余的打印逻辑/函数调用,所以这些逻辑可以放在"if __name__ = '__main__': xxx"代码块中。
这样py文件作为脚本执行的时候就能够打印出来,以模块被导入时,便不会打印出来。
from...import...
from...import是另一种导入模块的形式,如果你不想每次调用模块的对象都加上模块名,就可以使用这种方式。接下来,我们将详解地分析一下from..import...的实现。
- 在from...import...的过程中发生了什么事儿?
from my_module import name,func
print(name) #此时引用模块中的对象时,就不要再加上模块名了。
func()
(1)寻找模块
(2)如果找到模块,在内存中开辟一块内存空间,从上至下执行模块。
(3)把模块中的对应关系全部都保存到新开辟的内存空间中
(4)建立一个变量xxx引用该模块空间中对应的xxx,如果没有import进来的对象,就使用不了。
- from...import...方式取别名
与import方式如出一辙,通过"from 模块名 import 对象名 as 别名"。
- from...import *
import * 相当于把这个模块中的所有名字都引入到当前文件中,但是如果你自己的py文件如果有重名的变量,那么就会产生不好的影响,因此使用from...import *时需要谨慎,不建议使用。
- * 与 __all__
__all__是与*配合使用的,在被导入模块中增加一行__all__=['xxx','yyy'],就规定了使用import *是只能导入在__all__中规定的属性。
# 在my_module模块中定义__all__
__all__ = ['name']
name = 'my module'
def func():
print(name)
#在其他文件中通过import *导入所有属性
from my_module import *
print(name)
>>>
my module
func()
>>>
NameError: name 'func' is not defined
拓展知识点:
(1)pyc文件与pyi文件 *
pyi文件:跟.py一样,仅仅作为一个python文件的后缀名。
pyc文件: python解释器为了提高加载模块的速度,会在__pycache__目录中生成模块编译好的字节码文件,并且对比修改时间,只有模块改变了,才会再次编译。pyc文件仅仅用于节省了启动时间,但是并不能提高程序的执行效率。
(2)模块的导入和修改 *
1.导入模块后,模块就已经被加载到内存中,此后计算对模块进行改动,读取的内容还是内存中原来的结果。
2.如果想让改动生效,可以通过“from importlib import reload”, 需要'reload 模块名'重新加载模块,改动才生效。
(3)模块的循环使用 ****
谨记模块的导入必须是单链的,不能有循环引用,如果存在循环,那么就是程序设计存在问题。
(4)dir(模块名) ***
可以获得该模块中所有的名字,而且是字符串类型的,就可以通过反射去执行它。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号