
由JDK源码学习HashMap
HashMap基于hash表的Map接口实现,它实现了Map接口中的所有操作。HashMap允许存储null键和null值。这是它与Hashtable的区别之一(另外一个区别是Hashtable是线程安全的)。另外,HashMap中的键值对是无序的。下面,我们从HashMap的源代码来分析HashMap的实现,以下使用的是Jdk1.7.0_51。
一、HashMap的存储实现
HashMap底层采用的是数组和链表这两种数据结构.当我们把key-value对put到HashMap时,系统会根据hash算法计算key的hash值,根据hash值决定key-value对存放在数组的哪个位置(也就是散列表中的”桶”位).如果该位置已经存放Entry,则该位置上的Entry形成Entry链.下面我们从源代码入手分析.
public V put(K key, V value) { //① 如果table为空,调用inflateTable()初始化table数组 if (table == EMPTY_TABLE) { inflateTable(threshold); } // 如果key为null,调用putForNullKey()处理 if (key == null) return putForNullKey(value); // ② 调用hash算法,算出key的hash值 int hash = hash(key); // ③ 根据hash值和table的长度计算在table中的存放位置 int i = indexFor(hash, table.length); // 如果key存在,则替换之前的value值 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } // 模数自增,用于实现fail-fast机制 modCount++; // ④ 添加key-value对 addEntry(hash, key, value, i); return null; }
上面的程序中用到了一个重要的内部接口:Map.Entry,每个Map.Entry其实就是一个封装了key-value属性的对象.从上面的代码中也可以看出:系统决定HashMap中的key-value对时,没有考虑Entry中的value,仅仅是根据key来计算并决定每个Entry的存储位置.
从①处代码可以看到,调用put方法时会检查table数组的容量.如果table数组为空数组,会先初始化table数组,我们看下HashMap是如何初始化table数组的。
private void inflateTable(int toSize) { // 找到大于toSize的最小的2的n次方 int capacity = roundUpToPowerOf2(toSize); threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); // 初始化table数组 table = new Entry[capacity]; initHashSeedAsNeeded(capacity); }
从上面的代码中可以知道,HashMap中table数组的长度一定是2的n次方.实际上,这是一个很优雅的设计,在后面我们还会提到。如果key不为null,系统会调用hash()算法算出key的hash值,并据此来计算key的的存放位置.
final int hash(Object k) { int h = hashSeed; // 如果key为字符串,调用stringHash32()处理 // 因为字符串的hashCode码一样的可能性大,造成hash冲突的可能性也大 if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); } // 根据key的hashCode值算hash值 h ^= k.hashCode(); h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }
得到key的hash值后,从④处的代码知道,此时系统会根据hash值和table的长度来计算key在table数组中的存放位置.
static int indexFor(int h, int length) { return h & (length-1); }
这个方法的设计非常巧妙,通过h&(table.length-1)来得到该key的保存位置,而上面说到了HashMap底层数组长度总是2的n次方.当length总是2的n次方时,h&(length-1)能保证计算得到的值总是位于table数组的索引之内.假设h=5,length=16,h&(length-1)=5;h=6,length=16,h&(length-1)=6…
接下来,如果key已经存在,则替换其value值.如果不存在则调用addEntry()处理.
void addEntry(int hash, K key, V value, int bucketIndex) { // 检查HashMap容量是否达到极限(threshold)值 if ((size >= threshold) && (null != table[bucketIndex])) { // 扩充table数组的容量为之前的1倍 resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } // 调用createEntry()添加key-value对到HahsMap createEntry(hash, key, value, bucketIndex); } void createEntry(int hash, K key, V value, int bucketIndex) { // 获取table[bucketIndex]的Entry Entry<K,V> e = table[bucketIndex]; // 根据key-value创建新的Entry对象,并把新创建的Entry存放到table[bucketIndex]处 // 新Entry对象保存e对象(之前table[bucketIndex]的Entry对象)的引用,从而形成Entry链 table[bucketIndex] = new Entry<>(hash, key, value, e); size++; }
系统总是将新添加的Entry对象放入table[bucketIndex]—如果bucketIndex处已经有一个Entry对象,那新添加的Entry对象指向原有的Entry对象(Entry持有一个指向原Entry对象的引用,产生一个Entry链),如果bucketIndex处没有Entry对象,即上面代码中e为null,也就是新添加的Entry对象持有一个null引用,并没有产生Entry链.
从上面整个put方法的分析来看,我们可以知道HashMap存储元素的基本流程:首先根据算出key的hash值,根据hash值和table的长度计算该key的存放位置.如果key相同,则新值替换旧值.如果key不同,则在table[i]桶位形成Entry链,而且新添加的Entry位于Entry链的头部(table[i]).
上面的代码有点多,附上put(K key,V value)方法的流程图:
 下面是HashMap的存储示意图:
下面是HashMap的存储示意图:
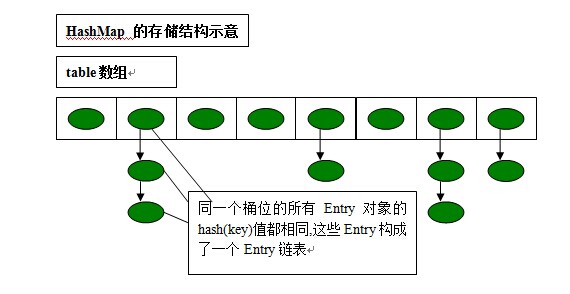
二、HashMap的读取实现
当HashMap的每个buckete里存储的Entry只是单个Entry—也就是没有通过指针产生Entry链(没有产生hash冲突)时,此时HashMap具有最好的性能(底层结构仅仅是数组,没有产生链表):当程序通过key取出对应的value时,系统先计算出hash(key)值找到key在table数组的存放位置,然后取出该桶位的Entry链,遍历找到key对应的value.以下是get(K key)方法的源代码:
public V get(Object key) { // 如果key为null,调用getForNullKey()处理 if (key == null) return getForNullKey(); // 获取key所对应的Entry Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); } final Entry<K,V> getEntry(Object key) { if (size == 0) { return null; } // 计算hash(key)值 int hash = (key == null) ? 0 : hash(key); // 遍历Entry链,找到key所对应的Entry for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }
上面的代码很简单,如果HashMap的每个bucket里只有一个Entry时,HashMap可以根据hash(key)值快速取出table[bucket]的Entry.在发生”Hash冲突”的情况下,table[bucket]存放的不是一个Entry,而是一个Entry链,系统只能按顺序遍历Entry链,直到找到key相等的Entry,如果要搜索的Entry位于Entry链的最末端(该Entry最早放入bucket),那么系统必须循环到最后才能找到该Entry.
归纳起来简单地说,HashMap在底层将key-value当成一个整体进行处理,这个整体就是一个Entry对象.HashMap底层采用一个Entry[]数组来保存所有的key-value对,当存储一个Entry对象时,会根据Hash算法来决定其存储位置;当需要取出一个Entry时,也会根据Hash算法找到其存储位置,再取出该Entry.由此可见:HashMap快速存取的基本原理是:不同的东西放在不同的位置,需要时才能快速找到它.
三、Hash算法的性能选项
HashMap中定义了以下几个成员变量:
① size:HashMap中存放的Entry数量
② loadFactor:HashMap的负载因子
③ threshold:HashMap的极限容量,当HashMap的容量达到该值时,HashMap会自动扩容(threshold=loadFactory*table.length)
HashMap默认的构造函数会创建一个初始容量为16,负载因子为0.75的HashMap对象.当然,我们也可以通过其他构造函数指定HashMap的初始容量和负载因子.从上面的源码分析中,我们知道创建HashMap时的实际容量通常比initialCapacity大一些,除非我们指定的initialCapacity参数值正好是2的n次方.当然,知道这个以后,应该在创建HashMap时将initialCapacity参数值指定为2的n次方,这样可以减少系统的计算开销.
当创建HashMap时,有一个默认的负载因子(load factor),其默认值为0.75,这是时间和空间成本上的一种折衷:增大负载因子可以减少Hash表(Entry数组)所占用的内存空间,但会增加查询数据的时间开销,而查询时最频繁的操作(HashMap的get()与put()方法都要用到查询);减少负载因子会提高数据查询的性能,但会增加Hash表所占用的内存空间.
如果能够预估HashMap会保存Entry的数量,可以再创建HashMap时指定初始容量,如果HashMap的size一直不会超过threshold(capacity*loadFactory),就无需调用resize()重新分配table数组,resize()是很耗性能的,因为要对所有的Entry重新分配位置.当然,开始就将初始化容量设置太高可能会浪费空间(系统需要创建一个长度为capacity的Entry数组),因此创建HashMap时初始化容量也需要小心设置.
四、细数HashMap中的优雅的设计
- 底层数组的长度总是为2的n次方
- indexFor(hash,table.length)保证每个Entry的存储位置都在table数组的长度范围内
- 新添加的Entry总是存放在table[bucket],相同hash(key)的Entry形成Entry
目前就发现这么多,以后发现了再继续补上.
都说好的设计是成功的一半,HashMap的设计者展示了一种设计美感.
五、HashMap使用注意问题
以本人目前的经验来看,HashMap使用过程中应注意两大类问题,其一,线程安全问题,因为HashMap是非同步的,在多线程情况下请使用ConcurrentHashMap。其二,内存泄露问题.我们这里只讨论第二种问题.由上面的分析可以知道,存放到HashMap的对象,强烈建议覆写equals()和hashCode().但hashCode值的改变可能会造成内存泄露问题.看代码:
public class HashCodeDemo { public static void main(String[] args) { User user = new User("zhangsan",22); Map<User,Object> map = new HashMap<User,Object>(); map.put(user, "user is exists"); // user is exists System.out.println(map.get(user)); // 改变age值,将会改变hashCode值 user.setAge(23); // null,因为user.hashCode值变化了,此时,我们可能永远也无法取出该Entry对象,但HashMap持有该Entry对象的引用,这就造成了内存泄露 System.out.println(map.get(user)); } } class User{ private String name; private Integer age; public User() { } public User(String name, Integer age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } @Override public int hashCode() { return name.hashCode()*age.hashCode(); } @Override public boolean equals(Object obj) { if(obj instanceof User){ User user = (User)obj; return this.name.equals(user.name)&&this.age==user.getAge()?true:false; } return false; } }
六、自定义HashMap实现
这里只做简单模拟,加深对HashMap的理解.
第一步,创建MyEntry类,用于封装key-value属性.
class MyEntry<K, V> { private final K key; private V value; private MyEntry<K, V> next; private final int hash; /** 构造函数 **/ public MyEntry(K key, V value, MyEntry<K, V> next, int hash) { this.key = key; this.value = value; this.next = next; this.hash = hash; } /** 返回Entry.key **/ public K getKey() { return this.key; } /** 返回Entry.value **/ public V getValue() { return this.value; } /** 替换Entry.value **/ public V setValue(V val) { V oldVal = value; this.value = val; return oldVal; } public MyEntry next(){ return next; } public int hash(){ return hash; } @Override public String toString() { return this.key + "=" + this.value; } public void setNext(MyEntry myEntry) { this.next = myEntry; } }
第二步,实现MyHashMap,底层采用数组+链表结构.到这里,我们会发现,其实实现HashMap关键点有以下几个:
① HashMap容量的管理和性能参数的设置
② hash()算法的实现,理想的hash算法是不会产生"hash冲突的"(HashMap底层仅仅是数组),在这种情况下,HashMap能达到最好的存取性能.
HashMap的设计者很好的解决了这两个问题,关于这两个问题,可以参考源码.
以上就是我对HashMap源码的学习总结,有不正确或不准确的地方,请大家指出来!非常欢迎大家一起交流学习!
以上内容参考:http://www.ibm.com/developerworks/cn/java/j-lo-hash/?ca=drs-tp4608

 浙公网安备 33010602011771号
浙公网安备 33010602011771号