

论文阅读 Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis
Style Tokenss
摘要
在这里,我们提出一个“global style token”,在Tacotron(最先进的端到端语音合成系统)中经过共同训练的一堆嵌入内容。嵌入没有明确的标签,就学会了大规模的声学表示。GSTs 带来了一系列的引人瞩目的结果。它们生成的软解释的“标签”可用于以新颖的方式控制合成,例如速度和说话风格的变化–与文本内容无关。它们还可以用于样式传递,在整个长格式文本语料库中复制单个音频片段的说话样式。在针对嘈杂的,未标记的发现数据进行训练时,GST会学习将噪声和说话人身份分解,从而为实现高度可扩展但功能强大的语音合成提供一条途径。
1 介绍
在过去的几年中,使用深度神经网络合成自然发音的人类语音取得了令人振奋的发展。随着文本语音转换(TTS)模型的迅速改进,诸如语音书旁白,新闻阅读器和会话助手之类的许多应用程序都有越来越多的机会。神经模型显示出有力地合成表达性长形式语音的潜力,但是该领域的研究仍处于起步阶段。
为了传达真实人的语音,TTS必须学会模拟韵律。韵律是语音中许多音素的融合,例如副语言信息,语调,重音和风格。现在我们聚焦了一个风格模型,其目的是为模型提供选择适合给定上下文的说话风格的能力。虽然很难准确定义,但风格包含丰富的信息,例如意图和情感,并影响说话者对语调和流向的选择。正确的样式渲染会影响整体感知力(例如,参见(Taylor,2009年)中的“情感韵律”),这对于诸如有声读物和新闻阅读器之类的应用而言非常重要。
样式建模提出了一些挑战。首先,没有客观的措施来衡量“正确的”韵律风格,使建模和评估都变得困难。由于人类评估者经常不同意,因此获取大型数据集的注释可能会耗资巨大且同样存在问题。第二,表达声音的高动态范围很难建模。许多TTS模型,包括最近的端到端系统,仅学习其输入数据的平均韵律分布,从而产生较少表现力的语音,尤其是长句子。此外,它们通常缺乏控制合成语音的表达的能力。
这项工作试图通过向Tacotron(最先进的端到端TTS)引入“global style tokens”(GSTs)来解决上述问题。GSTs通过没有任何韵律标签训练,揭示了大规模的表达风格。这个结构内部可以自己产生可解释的软“标签”,这些标签可以用来表达多种样式的控制和传递任务,可以大大改善长句子合成表达。GST可以直接应用于嘈杂的,未标记的数据,从而为实现高度可扩展但功能强大的语音合成提供了一条途径。
2 模型结构
我们的模型基于Tacotron,这是一种序列到序列(seq2seq)模型,可直接从字素或音素输入中预测梅尔谱图。这些梅尔频谱图可以通过低消耗反演算法(Griffin&Lim,1984)或神经声码器如WaveNet(van den Oord et al。,2016)转换为波形。我们指出,对于Tacotron,声码器的选择不会影响韵律,这是由seq2seq模型建模。
我们提出的GST模型,如图1所示,由参考编码器,样式注意,样式嵌入和序列到序列(Tacotron)模型组成。
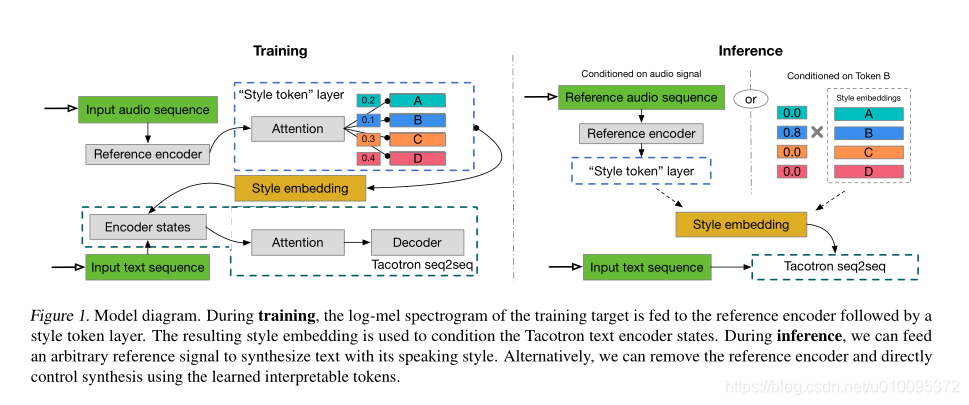
我们提出的GST模型,如图1所示,由参考编码器,样式注意,样式嵌入和序列到序列(Tacotron)模型组成。
2.1 训练
在训练过程中,信息流经模型如下:
- 参考模型,(Skerry-Ryan et al。2018)中提出的方法将可变长度音频信号的韵律压缩为固定长度矢量,我们称其为参考嵌入。在训练过程中,参考信号是真实的音频。
- 参考嵌入传递到 style token层,在这里它用作关注模块的查询向量。这里,注意力不用于学习对齐方式。取而代之的是,它学习参考嵌入与一组随机初始化的嵌入中的每个token之间的相似性度量。我们将这套嵌入(也称为global style tokens,GSTs或token嵌入)在所有训练序列中共享。
- 注意模块输出一组组合权重,这些组合权重表示每个style token对编码参考嵌入的贡献。我们将GSTs的加权总和(我们称为style embedding)传递到文本编码器,以便在每个时间步进行调节。
- style token层与模型的其余部分共同训练,仅受Tacotron解码器的重建损失函数驱动。因此,GSTs不需要任何明确的样式或韵律标签。
2.2 推论数据
GSTs体系结构旨在在推理模式下进行强大而灵活的控制。在这种模式下,信息可以通过以下两种方式流经模型:
- 我们可以将文本编码器直接设置为某些令牌,如图1的推理模式图右侧所示(“在Token B有条件”)。这允许在没有参考信号的情况下进行样式控制和操纵。
- 我们可以提供不同的音频信号(其笔录不需要匹配要合成的文本)来实现样式转换。这在图1的推理模式图的左侧(“视音频信号而定”)中进行了描述。
3 模型细节
3.1 Tacotron 结构
对于我们的基线和GST增强型Tacotron系统,除了一些细节外,我们使用与(Wang等人,2017a)相同的架构和超参数。我们使用音素输入来加快训练速度,并稍微更改解码器,用两层256单元LSTM替换GRU单元;这些使用zoneout(Krueger等人,2017)进行了正则化,概率为0.1。解码器一次输出两个帧的80通道logmel频谱图能量,这些能量通过输出线性频谱图的膨胀卷积网络运行。我们通过Griffin-Lim进行运行,以进行快速波形重建。用WaveNet声码器代替Griffin-Lim可以直接提高音频保真度(Shen等人,2017)。
基线模型获得4.0的平均意见得分,(MOS),在同一评估集上胜过(Wang等,2017a)报告的3.82 MOS。因此,这是一个非常强的基准。
3.2 Style Token 结构
3.2.1 参考编码器
参考编码器由卷积堆栈和RNN组成,它以对数梅尔图作为输入,首先传递到具有3×3内核,2×2步长,批量归一化和ReLU激活功能的六个二维卷积层的堆栈中。我们分别为6个卷积层使用32、32、64、64、128和128个输出通道。然后将生成的输出张量整形为3维(保留输出时间分辨率),并馈送到单层128单位单向GRU。 最后的GRU状态用作参考嵌入,然后将其作为输入提供给style token层。
3.2.2 Style Token 层
style token层由一组style token embeddings 和注意模块组成。除非特殊情况,我们的经验是用十个token,我们发现在训练数据中足以代表少量但丰富的韵律维度。为了匹配文本编码器的维数,每个token嵌入为256-D。相似的,文本编码器用tanh激活;我们发现,在施加关注之前对GST进行tanh激活会导致更大的token多样性。基于内容的tanh注意使用softmax激活来输出token上的一组组合权重。然后将所得的GSTs加权组合用于条件。我们对条件位点的不同组合进行了实验,发现复制样式嵌入并将其简单地添加到每个文本编码器状态的效果最佳。
尽管我们在此工作中使用基于内容的注意力作为相似性度量,但替代品却微不足道。点积注意力,基于位置的注意力,甚至注意力机制的组合都可以学习不同类型的样式标记。在我们的实验中,我们发现使用多头注意力(V aswani et al。,2017)可以显着改善样式转移性能,并且比简单地增加token数量更有效。当使用h个关注头时,我们将token嵌入大小设置为256 / h并连接注意输出,以使最终样式嵌入大小保持不变。
4 模型解释
4.1 端到端的聚类/量化
直观地,GST模型可以被认为是一种将参考嵌入到一组基础向量或软聚类(即样式标记)中的分解的端到端方法。如上所述,每个样式标记的贡献由注意力得分表示,但可以用任何所需的相似性度量代替。 GST层在概念上类似于VQ-V AE编码器(van den Oord et al。,2017),因为它学习了其输入的量化表示形式。我们还尝试用离散的,类似于VQ的查找表层替换GST层,但尚未看到可比的结果。
该分解概念还可以推广到其他模型,例如(Hsu et al。,2017)中的因式分解变项潜模型,它通过在因式分解图形模型中明确地表达语音信号来利用语音信号的多尺度性质。它的依赖序列的先验是由嵌入表制定的,该表类似于GST,但没有基于注意力的聚类。 GST可能会用于减少学习每个先前嵌入所需的样本。
4.2 记忆增强网络
GST嵌入也可以看作是存储从训练数据中提取的样式信息的外部存储器。参考信号在训练时引导存储器写入,而在推理时引导存储器读取。我们可能会利用记忆增强网络的最新进展(Graves等,2014)来进一步改善GST学习。
本文来自博客园,作者:赫凯,转载请注明原文链接:https://www.cnblogs.com/heKaiii/p/15491177.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号