

第四次作业:猫狗大战
使用VGG模型进行猫狗大战
1首先下载数据:

2.数据处理:

datasets 是 torchvision 中的一个包,可以用做加载图像数据。
它可以以多线程(multi-thread)的形式从硬盘中读取数据,使用 mini-batch 的形式,在网络训练中向 GPU 输送。
在使用CNN处理图像时,需要进行预处理。图片将被整理成 的大小,同时还将进行归一化处理。
torchvision 支持对输入数据进行一些复杂的预处理/变换 (normalization, cropping, flipping, jittering 等)。
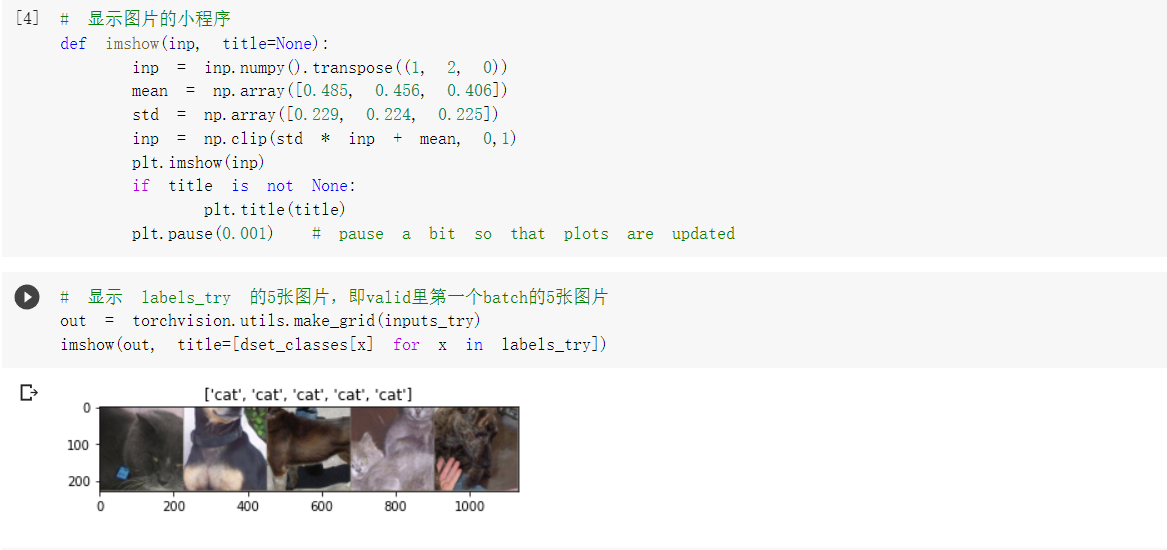
3.创建VGG Model
torchvision中集成了很多在 ImageNet (120万张训练数据) 上预训练好的通用的CNN模型,可以直接下载使用。
在本课程中,我们直接使用预训练好的 VGG 模型。同时,为了展示 VGG 模型对本数据的预测结果,还下载了 ImageNet 1000 个类的 JSON 文件。
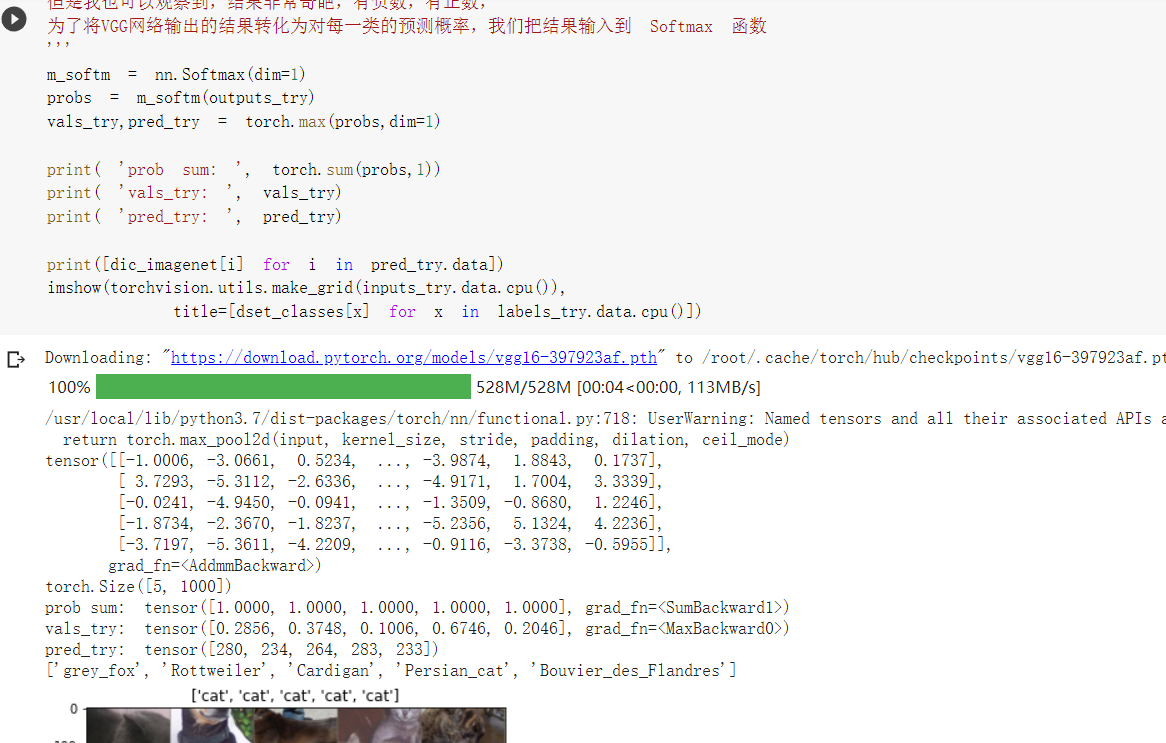
在这部分代码中,对输入的5个图片利用VGG模型进行预测,同时,使用softmax对结果进行处理,随后展示了识别结果。可以看到,识别结果是比较非常准确的。

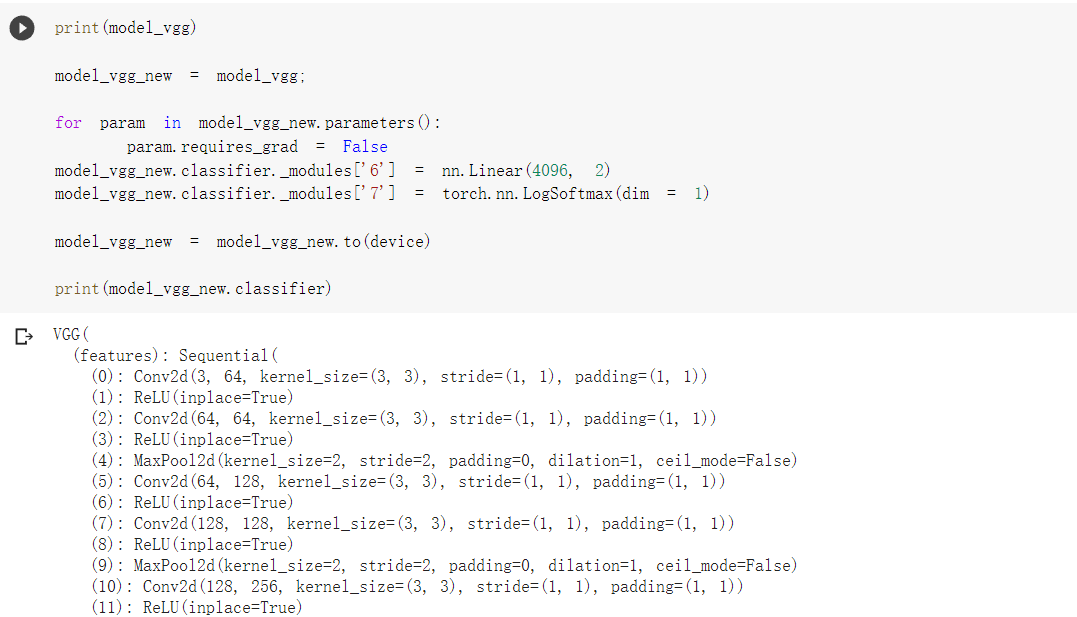
4.修改最后一层,冻结前面层的参数
卷积层(CONV)是发现图像中局部的 pattern
全连接层(FC)是在全局上建立特征的关联
池化(Pool)是给图像降维以提高特征的 invariance
我们的目标是使用预训练好的模型,因此,需要把最后的 nn.Linear 层由1000类,替换为2类。为了在训练中冻结前面层的参数,需要设置 required_grad=False。这样,反向传播训练梯度时,前面层的权重就不会自动更新了。训练中,只会更新最后一层的参数。
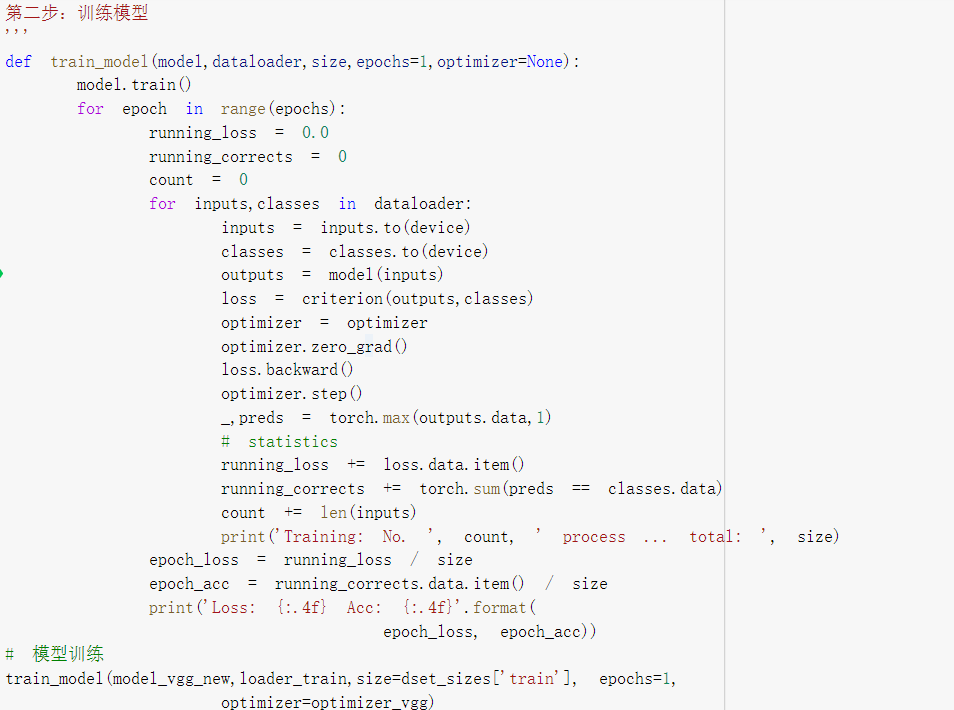
5.训练并测试全连接层
- 创建损失函数和优化器

测试模型:


6.可视化模型测试结果(主观分析)
随机查看一些预测正确的图片
随机查看一些预测错误的图片
预测正确,同时具有较大的probability的图片
预测错误,同时具有较大的probability的图片
最不确定的图片,比如说预测概率接近0.5的图片


最后由于模型训练时间太长没有训练完,造成准确率比较低:
结果:
使用Adam可以在一定程度上提高准确率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号