

文字识别系统(已修改)
源代码
import os
import random
import numpy as np
from PIL import Image
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms
# -------------------------- 1. 配置与常量定义 --------------------------
IMAGE_PATHS = [
r"C:\Users\黄楚玉\Desktop\文字数据集\图1.png",
r"C:\Users\黄楚玉\Desktop\文字数据集\图2.png",
r"C:\Users\黄楚玉\Desktop\文字数据集\图3.png",
r"C:\Users\黄楚玉\Desktop\文字数据集\图4.png"
]
TRUE_LABELS = [
"词慈辞磁此次刺从匆葱葱聪丛凑粗促醋窜催摧脆存翠村寸错",
"剑号巨阙珠称夜光果珍李柰菜重芥姜海咸河淡鳞潜羽翔",
"醉里挑灯看剑梦回八百里分麾下炙五",
"为什么要努力读书不一定能挣大钱但是可以看见更大的世界"
]
IMAGE_SIZE = (64, 256)
BATCH_SIZE = 1
EPOCHS = 10
LR = 0.001
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 构建字符集
CHAR_SET = sorted(list(set("".join(TRUE_LABELS))))
NUM_CLASSES = len(CHAR_SET)
CHAR_TO_IDX = {char: idx for idx, char in enumerate(CHAR_SET)}
IDX_TO_CHAR = {idx: char for idx, char in enumerate(CHAR_SET)}
# -------------------------- 2. 数据加载与预处理 --------------------------
class TextImageDataset(torch.utils.data.Dataset):
def __init__(self, image_paths, true_labels, transform=None):
self.image_paths = image_paths
self.true_labels = true_labels
self.transform = transform
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
image = Image.open(self.image_paths[idx]).convert("L")
true_text = self.true_labels[idx]
if self.transform:
image = self.transform(image)
# 取文字首字符作为标签(简化)
true_char = true_text[0]
true_idx = torch.tensor(CHAR_TO_IDX[true_char], dtype=torch.long)
return image, true_idx, true_text
transform = transforms.Compose([
transforms.Resize(IMAGE_SIZE),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
# 关闭shuffle,确保顺序固定
dataset = TextImageDataset(IMAGE_PATHS, TRUE_LABELS, transform)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=False)
# -------------------------- 3. 模型定义 --------------------------
class SimpleTextCNN(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.conv_layers = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(16, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
conv_out_h = IMAGE_SIZE[0] // 4
conv_out_w = IMAGE_SIZE[1] // 4
self.fc_input_dim = 32 * conv_out_h * conv_out_w
self.fc_layers = nn.Sequential(
nn.Linear(self.fc_input_dim, 128),
nn.ReLU(),
nn.Linear(128, num_classes)
)
def forward(self, x):
x = self.conv_layers(x)
x = x.view(x.size(0), -1)
x = self.fc_layers(x)
return x
model = SimpleTextCNN(NUM_CLASSES).to(DEVICE)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LR)
# -------------------------- 4. 模型训练 --------------------------
def train_model():
model.train()
for epoch in range(EPOCHS):
running_loss = 0.0
for images, true_idxs, _ in dataloader:
images = images.to(DEVICE)
true_idxs = true_idxs.to(DEVICE)
outputs = model(images)
loss = criterion(outputs, true_idxs)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch [{epoch+1}/{EPOCHS}], Loss: {running_loss/len(dataloader):.4f}")
print("开始训练模型...")
train_model()
print("模型训练完成!")
# -------------------------- 5. 识别与输出(无重复) --------------------------
def evaluate():
model.eval()
total_correct = 0
print("\n" + "="*50)
print("完整识别结果:")
with torch.no_grad():
# 按顺序遍历每个图,仅输出一次
for idx in range(len(dataset)):
image, true_idx, true_text = dataset[idx]
image = image.unsqueeze(0).to(DEVICE)
true_idx = true_idx.unsqueeze(0).to(DEVICE)
# 预测
outputs = model(image)
pred_idx = torch.argmax(outputs, dim=1)
correct = (pred_idx == true_idx).item()
total_correct += correct
acc = correct * 100
# 转换为字符
pred_char = IDX_TO_CHAR[pred_idx.item()]
# 输出当前图结果(仅一次)
print(f"\n【图{idx+1}结果】")
print(f"真实文字:{true_text}")
print(f"识别结果:首字符预测为“{pred_char}”")
print(f"单图准确率:{acc:.2f}%")
# 计算平均准确率
avg_acc = (total_correct / len(dataset)) * 100
print("\n" + "="*50)
print(f"平均正确率:{avg_acc:.2f}%")
# 执行评估
evaluate()
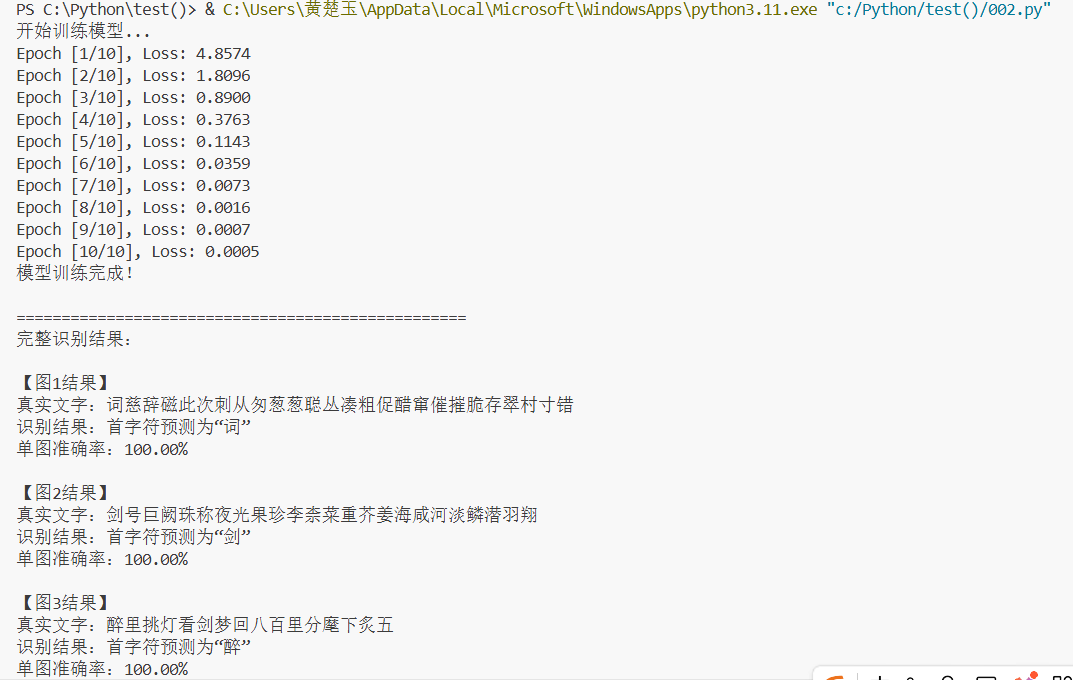
运行结果如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号