面试题目
(1)大CPU大内存,网卡超烂,如何优化?
强制本地化,选高压缩的序列化格式,核心就是尽量减少网络IO。
计算机中内存、cache和寄存器之间的关系及区别:
(1)寄存器是CPU内部的元件,寄存器拥有非常高的读写速度,所以在寄存器之间的数据传送非常快,可用来暂存指令、数据和位址。
(2)内存包含的范围非常广,一般分为只读存储器(ROM)、随机存储器(RAM)和高速缓存存储器(cache)。
(3)Cache :即高速缓冲存储器,是位于CPU与主内存间的一种容量较小但速度很高的存储器。Cache缓存则是为了弥补CPU与内存之间运算速度的差异.
(2)spark的分组排序:
核心思想是相对分组内部排序,然后取前N个,然后对分组之间进行排序;groupBy和groupByKey是不同的,比如(A,1),(A,2);使用groupBy之后结果是(A,((A,1),(A,2))),使用groupByKey之后结果是:(A,(1,2));关键区别就是合并之后是否会自动去掉key信息;
(3)给出a,b两个文件,各存放50亿条url,内存限制为4G,如何找出这两个文件重复的url:
方案1:可以估计每个文件按的大小为5G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
1、遍历文件a,对每个url求取hash(url)%1000,然后根据所取得的值将url分别存储到1000个小文件(记为a0,a1,…,a999)中。这样每个小文件的大约为300M。
2、遍历文件b,采取和a相同的方式将url分别存储到1000小文件(记为b0,b1,…,b999)。这样处理后,所有可能相同的url都在对应的小文件(a0vsb0,a1vsb1,…,a999vsb999)中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
3、求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
方案2:如果允许有一定的错误率,可以使用Bloomfilter,4G内存大概可以表示340亿bit。将其中一个文件中的url使用Bloomfilter映射为这340亿bit,然后挨个读取另外一个文件的url,检查是否与Bloomfilter,如果是,那么该url应该是共同的url(注意会有一定的错误率)。
(4)有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M,要求返回频数最高的100个词:
1、顺序读文件中,对于每个词x,取hash(x)%5000,然后按照该值存到5000个小文件(记为f0,f1,...,f4999)中,这样每个文件大概是200k左右,如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M;
2、对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100词及相应的频率存入文件,这样又得到了5000个文件;
3、把这5000个文件进行归并排序或者最小堆排序。;
若内存能一次读取所有文件如何求topK:
1、维护一个Key为单词,Value为该Query出现次数的HashMap,即hash_map(Word,Value),每次读取一个word,如果该字串不在HashMap中,那么加入该字串,并且将Value值设为1;如果该字串在HashMap中,那么将该字串的计数加一即可。最终我们在O(N)的时间复杂度内用Hash表完成了统计;
2、堆排序:第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。即借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比。所以,我们最终的时间复杂度是:O(N) + N' * O(logK),(N为1000万,N’为300万)。
(5)在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数:
方案1:采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多次,11无意义)进行,共需内存2^32*2bit=1GB内存,还可以接受。然后扫描这2.5亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完事后,查看bitmap,把对应位是01的整数输出即可。
方案2:也可采用与第1题类似的方法,进行划分小文件的方法。然后在小文件中找出不重复的整数,并排序。然后再进行归并,注意去除重复的元素。
(6)给40亿个不重复的unsignedint的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中:
申请512M的内存,一个bit位代表一个unsignedint值。读入40亿个数,设置相应的bit位,读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示不存在。
(7)如何解决client和hdfs读写延迟过高:
(1)Chunk缓冲机制:数据会被写入一个chunk缓冲数组,这个chunk是一个512字节大小的数据片段,这个缓冲数组可以容纳多个chunk大小的数据在里面缓冲。
(2)Packet数据包机制:当chunk缓冲数组都写满了之后,就会把这个chunk缓冲数组进行一下chunk切割,切割为一个一个的chunk,一个chunk是一个数据片段。然后多个chunk会直接一次性写入另外一个内存缓冲数据结构,就是Packet数据包,一个Packet数据包,设计为可以容纳127个chunk
(3)当一个Packet被塞满了chunk之后,就会将这个Packet放入一个内存队列来进行排队。然后有一个DataStreamer线程会不断的获取队列中的Packet数据包,通过网络传输直接写一个Packet数据包给DataNode。
(8)分布式系统实现幂等性的方式
幂等性:对数据的多次操作,得到的结果一致
1)方式一:使用乐观锁,通过version版本条件进行控制,来做乐观锁的判断条件
2)方式二:使用悲观锁,在整个执行过程中锁定相应的数据。
3)方式三:全局唯一ID,根据业务的操作和内容生成一个全局ID,在执行操作前先根据这个全局唯一ID是否存在,来判断这个操作是否已经执行。如果不存在则把全局ID,存储到存储系统中,比如数据库、redis等。如果存在则表示该方法已经执行。
(9)如何保证数据质量和数据一致性
分布式事务,幂等性
(10)如何实现分布式事务
分布式事务指事务的操作位于不同的节点上,需要保证事务的 AICD 特性。
1、两阶段提交(2PC):两阶段提交(Two-phase Commit,2PC),通过引入协调者(Coordinator)来协调参与者的行为,并最终决定这些参与者是否要真正执行事务。
2、补偿事务:TCC 其实就是采用的补偿机制,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。
3、本地消息表(异步确保):本地消息表与业务数据表处于同一个数据库中,这样就能利用本地事务来保证在对这两个表的操作满足事务特性,并且使用了消息队列来保证最终一致性。
hadoop实现冗余备份的难点:
对于不同的数据备份,需要放到不同的节点上面,利用Hash函数,这样可以把每个备份id对应到一个哈希值,然后再将这个哈希值与某个节点对应起来,就完成了一个数据备份的分配。这样做在时间复杂度上只有O(1),但是很多哈希函数有一个问题,就是不稳定。这里所谓的不稳定是指,当节点个数发生变化的时候,原来被分配到节点K上的数据备份可能就会被分配到另一个节点上。常用的哈希函数为:hash(x) = x % N,其中N为节点个数,x为备份id,这样当集群中节点出现故障或者扩展新的节点时,原来的计算的哈希值几乎全都变了,那么对于整个系统中的数据访问来说,无疑是一个灾难,因为访问位置全都得改变,并且需要重新迁移数据。
那么有没有可能在N变化的侯,原有数据备份的哈希值不改变呢?这就是一致性哈希的优势所在。一致性哈希的原理可以这么理解:原来哈希是用x%N,现在是用x%S且N%S,这里的S表示哈希函数本身可以表示的哈希值范围,比如它的范围是0~2^32 - 1,那么S=2^32。
如下图如果选取的哈希函数取值范围在0到2^32 - 1之间(Hash Range),那么我们可以同时把Data Blocks和Data Nodes同时哈希到这个范围里面,这些Nodes会把Hash Range划分为若干区域,规定每个Node存储与其相邻的前一个区域中的Blocks,从而完成数据的分配。这种方式的好处在于,即使出现Data Nodes数量变化的情况,也不会影响其它Nodes和Blocls的位置情况,最多是在被删除节点或者新增节点的附近进行调整,比如将原有区域中的Blocks进一步划分或者合并。
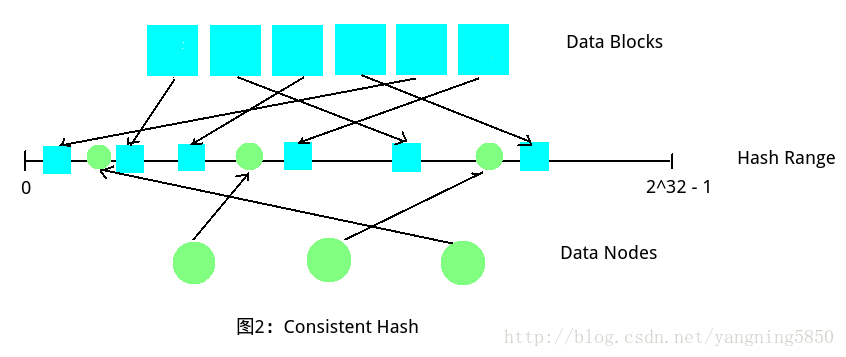
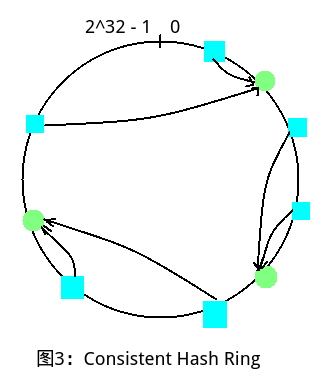
上图展示的方式中,三个Nodes将Hash Range分为了4个区域,显然不方便分配,所以提出一致性哈希环的概念,即将Hash Range的首位相连,然后在一个环路上面进行划分,N个Nodes一定能够划分出N个区域,然后让每个Node存储前一个相邻区域即可。如下图所示:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号