spark数据分析导论
1、spark的定义
spark是一个用来实现快速而通用的集群计算平台,高效的支持更多计算模式,包括交互式查询和流处理。
主要特点就是能够在内存中进行计算,即使在磁盘上进行计算依然比mapreduce更加高效。
2、spark的软件栈
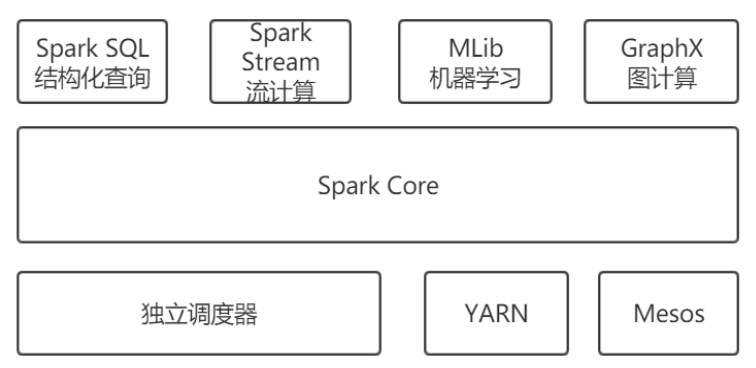
(1)Spark Core实现Spark的基本功能,包括任务调度,内存管理,错误恢复,与存储系统交互模块等。相当于MapReduce都是进行离线数据分析。而Spark Core的核心是RDD(resilient distribute dataset)弹性分布式数据集,由分区组成。
(2)Spark SQL相当于Hive,用来操作结构化数据的程序包。
(3)Spark Streaming是对实时数据进行流式计算的组件相当于Storm。
(4)MLib机器学习的程序库,包括分类,回归,聚类,协同过滤等。
(5)GraphX用来操作图。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号