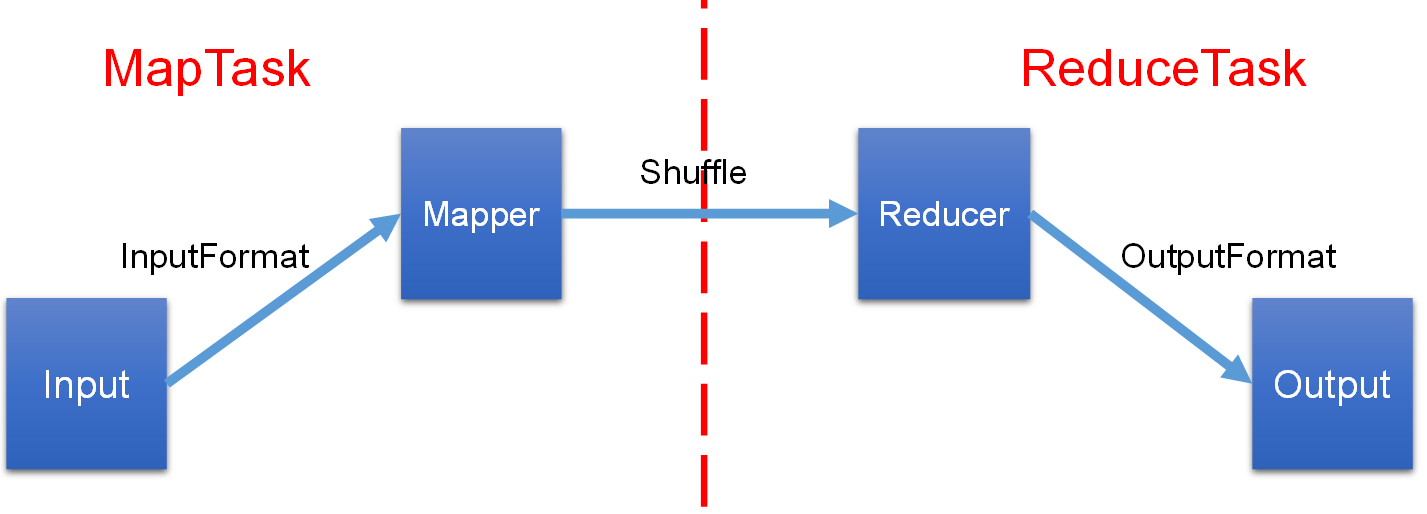
MapReduce
MapReduce
-
InputFormat
- 默认是TextInputFormat,Key:偏移量,Value:一行内容
- 处理小文件问题 CombineTextInputFormat,把多个小文件合并到一起进行统一切片
- 自定义输入
-
Mapper
setup()初始化map()业务逻辑clearup()关闭资源
-
分区
- 默认分区 HashPartitioner,默认按照key的hash值 %numreducetask 个数
- 自定义分区
-
排序
- 部分排序,每个输出的文件内部有序
- 全排序:一个reduce,对所有数据排序
- 二次排序:自定义排序,实现writableCompare接口,重写compareTo方法
-
Combiner
前提:不影响最终的业务逻辑(求和逻辑没问题,求平均值就不行)
在 map端 提前预聚合 => 解决数据倾斜的一个方法
-
Reducer
setup()初始化reduce()业务逻辑clearup()关闭资源
-
OutputFormat
- 默认是TextInputFormat,按行输出到文件
- 自定义输出
常用序列化类型
| Java 类型 | Hadoop Writable 类型 |
|---|---|
| Boolean | BooleanWritable |
| Byte | ByteWritable |
| Int | IntWritable |
| Float | FloatWritable |
| Long | LongWritable |
| Double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
| Null | NullWritable |
MapReduce编程规范
Mapper
- 继承父类
- 输入为Key-Value对(类型可自定义)
- 实现业务逻辑,对每一个<K,V>调用一次。map()方法
- 输出为Key-Value对,进入Reduce阶段
Reduce
- 继承父类
- 输入为Key-Value对,Mapper阶段的输出
- 实现业务逻辑,对 每一组相同 K 的<K,V>组 调用一次。reduce()方法
Driver
将整个程序提交到Yarn集群中
WordCount实现
添加依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
log4j2配置
在src/main/resources目录下,新建“log4j2.xml”
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="error" strict="true" name="XMLConfig">
<Appenders>
<!-- 类型名为Console,名称为必须属性 -->
<Appender type="Console" name="STDOUT">
<!-- 布局为PatternLayout的方式,
输出样式为[INFO] [2018-01-22 17:34:01][org.test.Console]I'm here -->
<Layout type="PatternLayout"
pattern="[%p] [%d{yyyy-MM-dd HH:mm:ss}][%c{10}]%m%n" />
</Appender>
</Appenders>
<Loggers>
<!-- 可加性为false -->
<Logger name="test" level="info" additivity="false">
<AppenderRef ref="STDOUT" />
</Logger>
<!-- root loggerConfig设置 -->
<Root level="info">
<AppenderRef ref="STDOUT" />
</Root>
</Loggers>
</Configuration>
Mapper类
package com.atguigu.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 输出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}
Reducer类
package com.atguigu.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
// 1 累加求和
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2 输出
v.set(sum);
context.write(key,v);
}
}
Driver驱动类
package com.atguigu.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordcountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取配置信息以及获取job对象
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 关联本Driver程序的jar
job.setJarByClass(WordcountDriver.class);
// 3 关联Mapper和Reducer的jar
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
// 4 设置Mapper输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
数据清洗(ETL)
Extract-Transform-Load:将数据从源端经过 抽取-转换-加载 至目的端
在进行核心业务MapReduce之前,需要先对数据进行清洗,这个过程只需要Mapper程序,不需要Reduce程序

 浙公网安备 33010602011771号
浙公网安备 33010602011771号