runtimClass与多容器进行时
随着越来越多的容器运行时的出现,不同的容器运行时也有不同的需求场景,于是就有了多容器运行时的需求。但是,如何来运行多容器运行时还需要解决以下几个问题:
集群里有哪些可用的容器运行时?
如何为 Pod 选择合适的容器运行时?
如何让 Pod 调度到装有指定容器运行时的节点上?
容器运行时在运行容器时会产生有一些业务运行以外的额外开销,这种「额外开销」需要怎么统计?
RuntimeClass 的工作流程:
K8s-master 接收到创建 Pod 的请求
每个节点上都有 Label 标识当前节点支持的容器运行时,节点内会有一个或多个 handel,每个 handle 对应一种容器运行时。比如有的节点内支持 runc 和 runv 两种容器运行时的 handler;有的节点支持 runhcs 容器运行时的 handler
根据 scheduling.nodeSelector, Pod 最终会调度到适合的节点上,并最终由 对应的runtimeclass handler 来创建 Pod
RuntimeClass 是 Kubernetes 一种内置的全局域资源,主要用来解决多个容器运行时混用的问题。
RuntimeClass 对象代表了一个容器运行时,它的结构体中主要包含以下三个字段:
Handler,它表示一个接收创建容器请求的程序,同时也对应一个容器运行时;
Overhead 是 v1.16 中才引入的一个新的字段,它表示 Pod 中的业务运行所需资源以外的额外开销;
Docker Pod 除了传统的 container 容器之外,还有一个 pause 容器,但我们在计算它的容器开销的时候会忽略 pause 容器。对于 Kata Pod,除了 container 容器之外,kata-agent, pause, guest-kernel 这些开销都是没有被统计进来的。像这些开销,多的时候甚至能超过 100MB,这些开销我们是没法忽略的。
Pod Overhead 的使用场景主要有三处:
Pod 调度:在没有引入 Overhead 之前,只要一个节点的资源可用量大于等于 Pod 的 requests 时,这个 Pod 就可以被调度到这个节点上。引入 Overhead 之后,只有节点的资源可用量大于等于 Overhead 加上 requests 的值时才能被调度上来。
ResourceQuota:它是一个 namespace 级别的资源配额。假设我们有这样一个 namespace,它的内存使用量是 1G,我们有一个 requests 等于 500 的 Pod,那么这个 namespace 之下,最多可以调度两个这样的 Pod。而如果我们为这两个 Pod 增添了 200MB 的 Overhead 之后,这个 namespace 下就最多只可调度一个这样的 Pod。
Kubelet Pod 驱逐:引入 Overhead 之后,Overhead 就会被统计到节点的已使用资源中,从而增加已使用资源的占比,最终会影响到 Kubelet Pod 的驱逐。
除此之外,Pod Overhead 还有一些使用限制和注意事项:
Pod Overhead 最终会永久注入到 Pod 内并且不可手动更改。即便是将 RuntimeClass 删除或者更新,Pod Overhead 依然存在并且有效;
Pod Overhead 只能由 RuntimeClass admission 自动注入(至少目前是这样的),不可手动添加或更改。如果这么做,会被拒绝;
HPA 和 VPA 是基于容器级别指标数据做聚合,Pod Overhead 不会对它们造成影响
Scheduling 也是在 v1.16 中被引入的,该 Scheduling 配置会被自动匹配 Pod 的 nodeSelector 。Scheduling 中包含了两个字段,NodeSelector 和 Tolerations。这两个和 Pod 本身所包含的 NodeSelector 和 Tolerations 是极为相似的。
NodeSelector 代表的是支持该 RuntimeClass 的节点上应该有的 label 列表。一个 Pod 引用了该 RuntimeClass 后,RuntimeClass admission 会把该 label 列表与 Pod 中的 label 列表做一次合并。如果这两个 label 中有冲突的,会被 admission 拒绝。这里的冲突是指它们的 key 相同,但是 value 不相同,这种情况就会被 admission 拒绝。另外需要注意的是,RuntimeClass 并不会自动为 Node 设置 label,需要用户在使用前提前设置好。
Tolerations 表示 RuntimeClass 的容忍列表。一个 Pod 引用该 RuntimeClass 之后,admission 也会把 toleration 列表与 Pod 中的 toleration 列表做一个合并。如果这两处的 Toleration 有相同的容忍配置,就会将其合并成一个。
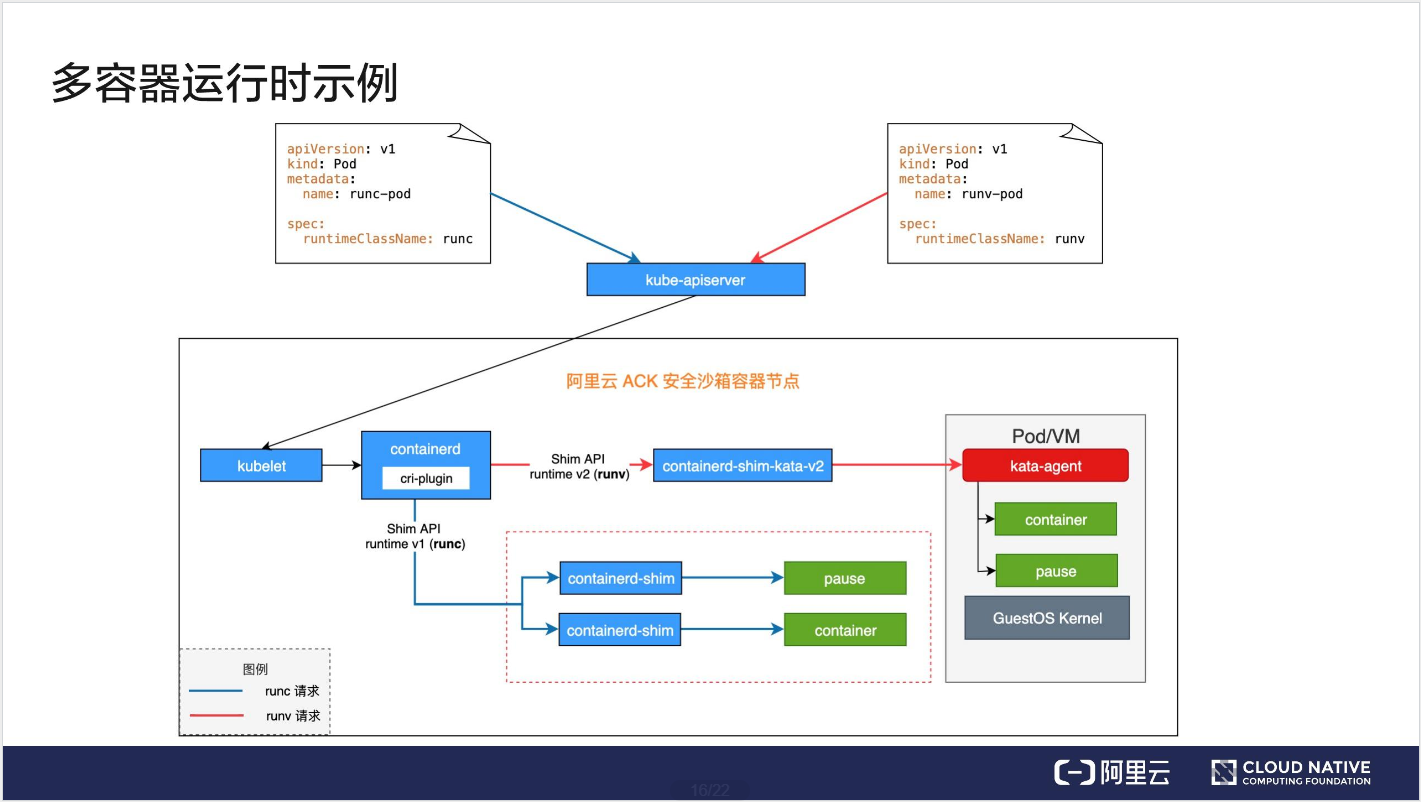
多容器运行时示例
runc 的请求,它先到达 kube-apiserver,然后 kube-apiserver 请求转发给 kubelet,最终 kubelet 将请求发至 cri-plugin(它是一个实现了 CRI 的插件),cri-plugin 在 containerd 的配置文件中查询 runc 对应的 Handler,最终查到是通过 Shim API runtime v1 请求 containerd-shim,然后由它创建对应的容器。这是 runc 的流程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号