压测指标和结果分析
压测指标
核心性能指标
1、吞吐量(qps/tps)
2、响应时间
3、错误率(<0.5%)
4、并发用户数
系统资源指标
1、cpu使用率
2、内存使用率(如果内存使用率持续线性增长,可能存在内存泄漏)
3、磁盘 I/O(磁盘的读写速率和繁忙程度,如果磁盘I/O利用率持续接近100%,说明磁盘已成为系统瓶颈。)
4、网络 I/O(如果网络带宽被打满,或者出现较高的丢包率,都会影响系统的吞吐量和响应时间。)
其他指标
性能拐点 / 最大容量:
- 当并发用户数增加到一定程度时,系统的吞吐量达到峰值,响应时间开始急剧增加,错误率也开始飙升。压测的一个重要目标就是找到这个拐点。
总结
随着并发用户数的增加
-
健康状态:吞吐量线性上升,响应时间平稳,错误率接近0,资源指标平稳上升。
- 瓶颈状态:当达到某个点时,响应时间开始陡增,吞吐量不再增长甚至下降,错误率开始升高。
此时观察资源指标,哪个先达到极限(如CPU使用率>95%),哪个就可能是瓶颈根源。
压测结果分析
一、数据库死锁
1、吞吐量(TPS/QPS)突然暴跌或维持低位
- 现象:曲线图上出现断崖式下跌,或者吞吐量无论如何增加压力(并发用户数)都无法继续上升,维持在一个很低的水平。
- 原因:发生死锁后,数据库会自动回滚其中一个事务。这个回滚操作和事务的重试(如果代码实现了重试)会消耗资源但并未完成有效工作,导致有效吞吐量下降。
2、响应时间(Response Time)急剧上升且波动很大
-
现象:平均响应时间和P95/P99分位响应时间变得非常高,并且抖动非常剧烈(曲线呈“尖刺”状)。
-
原因:大部分事务可能很快完成,但那些被死锁波及的事务需要经历【等待 -> 被回滚 -> 应用层重试】的过程,这个过程非常耗时,极大地拉高了整体响应时间。
3、并发数很高但交易成功率下降
-
现象:你模拟了大量并发用户,但成功完成的事务数(Success Transactions)相比低并发时没有线性增长,甚至开始下降。
-
原因:很多事务在最终重试多次后依然失败(如果你设置了重试上限),被标记为错误。
4、应用层日志中出现大量错误和重试日志
- 现象:这是最直接的应用层证据。查看压测期间应用的错误日志,如果发现大量特定数据库错误码,就几乎可以确诊。
- 原因:数据库将死锁错误返回给客户端,如果你的应用代码捕获并记录了这些异常,就会在日志中留下痕迹。
获取死锁日志:
SHOW ENGINE INNODB STATUS\G
判断流程:

二、慢sql
判断指标:
1、SQL执行耗时:(理论应该小于100ms)
2、扫描行数:为返回结果检查了多少行( 理论应该接近返回行数为健康状态)
3、返回行数:实际返回给客户端的行数
4、锁等待时间:(理论应该接近0)
5、执行次数:sql被执行的频率
导致的原因:
1、资源竞争
2、缓存失效,跟多sql需要读磁盘
3、低效的索引、不必要的全表扫描、复杂的连接查询
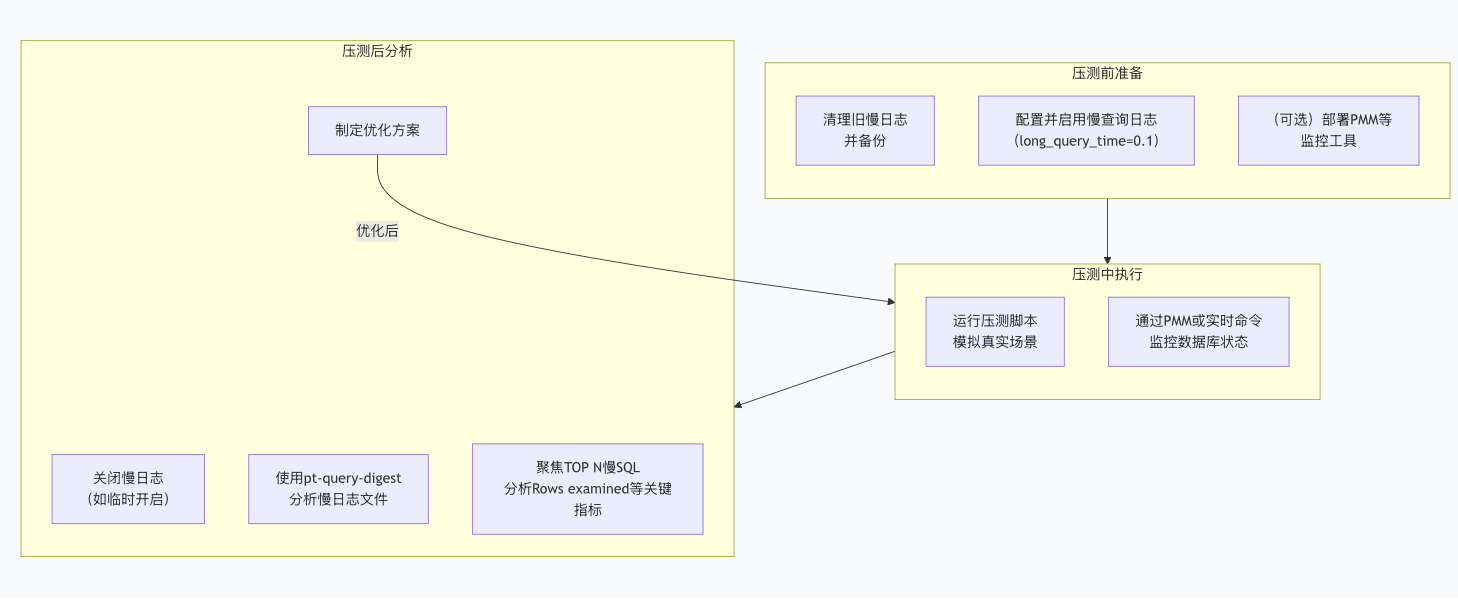
收集日志:
1、开启MySQL 慢查询日志 (Slow Query Log)
2、使用性能模式 (Performance Schema) 和 sys 库
-- 查看哪些语句执行时间最长、执行次数最多 SELECT * FROM sys.statement_analysis LIMIT 10; -- 查看全表扫描的查询 SELECT * FROM sys.statements_with_full_table_scans LIMIT 10; -- 查看哪些语句没有使用索引 SELECT * FROM sys.statements_without_index_analysis LIMIT 10;
3、排查思路

 浙公网安备 33010602011771号
浙公网安备 33010602011771号