准实时计算+机器学习 架构
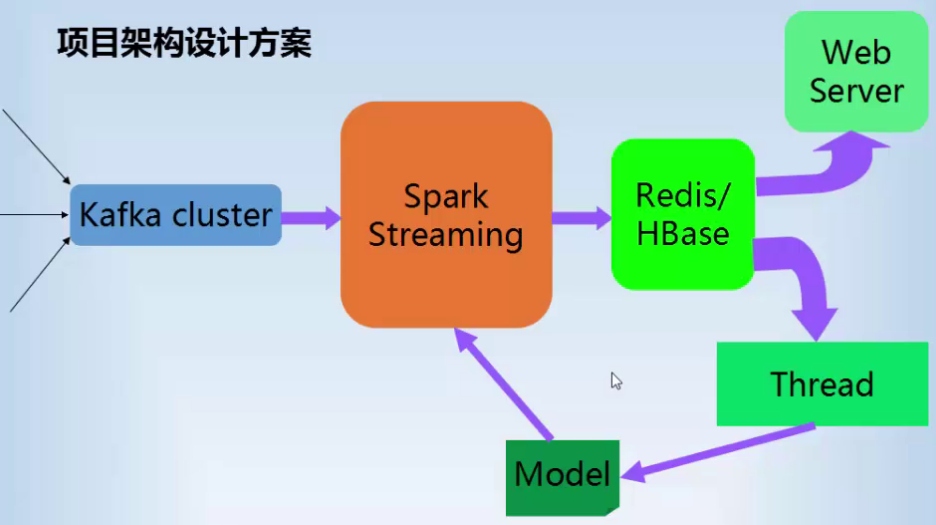
kafka: 0.8.2.1
spark: 1.3
redis: 3.0
hadoop: 2.6
部署:
kafka:主要消耗磁盘和网卡,数据量大时,能将网卡跑满,所以单独安排几台机器做kafka集群,三台左右就可以了
spark: 主要消耗内存和cpu,最好放在YARN上去执行
hdfs: 主要消耗 磁盘,除了kafka所在的机器,其他机器都可以跑个DataNode
yarn: 主要是消耗CPU和内存
redis: 主要消耗内存,单独拿几台机器跑redis集群
zookeeper:消耗小,可以和其他应用共用机器
Kafka 和 spark streaming
kafka 和 spark streaming通过zookeeper 维护 offset 来保证 消息只处理一次。
spark streaming可以进行窗口操作(比如:以每3分钟为窗口,进行数据处理)。
spark Streaming 可以和 spark MLlib很好的配合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号