

通过XmlReader类操作Xml (1 of n)
自己常常忘记在使用XmlReader读取xml的时候,每次都要使用Read方法来读取xml的下一个节点(next node),这里的所谓next node要怎么来理解?不妨通过例子来体现:
一个xml实例,很简单:
1 XmlReader reader = XmlReader.Create(new XmlTextReader(path), null);
XmlReader reader = XmlReader.Create(new XmlTextReader(path), null);
2
3 while (reader.Read())
4 {
5 Console.WriteLine(string.Format("{0}: \t({1} , {2}) ",
6 reader.NodeType.ToString(),
7 reader.Name, reader.Value));
8 }
XmlReader reader = XmlReader.Create(new XmlTextReader(path), null);2
3
while (reader.Read())4 {
5 Console.WriteLine(string.Format("{0}: \t({1} , {2}) ",
6 reader.NodeType.ToString(),
7 reader.Name, reader.Value));
8 }
下面的打印结果印象要深刻,常记在脑子里: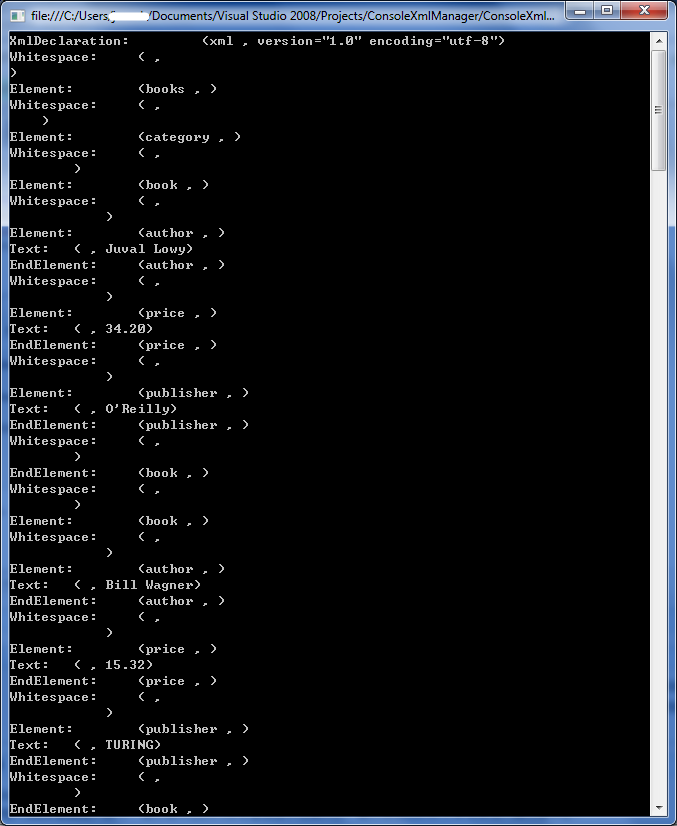
重点在Element,Text, EndElement的一对对上。一个习惯上以'<'和'>',或'/>'分隔的xml,在被XmlReader解读之后再被细分成三种XmlNodeType,即Element, Text, EndElement。
括号里的x是每个"element”的名字(Name), Y是Element的值(Value)。每个Element的Attribute要通过GetAttribute方法得到,示例就不演示了。
这里奇怪的看到Whitespace节点——默认XmlReader创建时是不会IgnoreWhitespace的, 除非Mybooklist.xml本来就是不留空格或换行符。
要排除这样的节点,使遍历更轻松方便,使用XmlReaderSetting类规范,并作为XmlReader创建时的参数传入。
1 XmlReaderSettings settings = new XmlReaderSettings();
2 settings.IgnoreComments = false;
3 settings.IgnoreWhitespace = true;
4 XmlReader reader = XmlReader.Create(new XmlTextReader(path), settings);
5
6 while (reader.Read())
7 {
8 Console.WriteLine(string.Format("{0}: \t({1} , {2}) ",
9 reader.NodeType.ToString(),
10 reader.Name, reader.Value));
11 }
2 settings.IgnoreComments = false;
3 settings.IgnoreWhitespace = true;
4 XmlReader reader = XmlReader.Create(new XmlTextReader(path), settings);
5
6 while (reader.Read())
7 {
8 Console.WriteLine(string.Format("{0}: \t({1} , {2}) ",
9 reader.NodeType.ToString(),
10 reader.Name, reader.Value));
11 }
继续打印: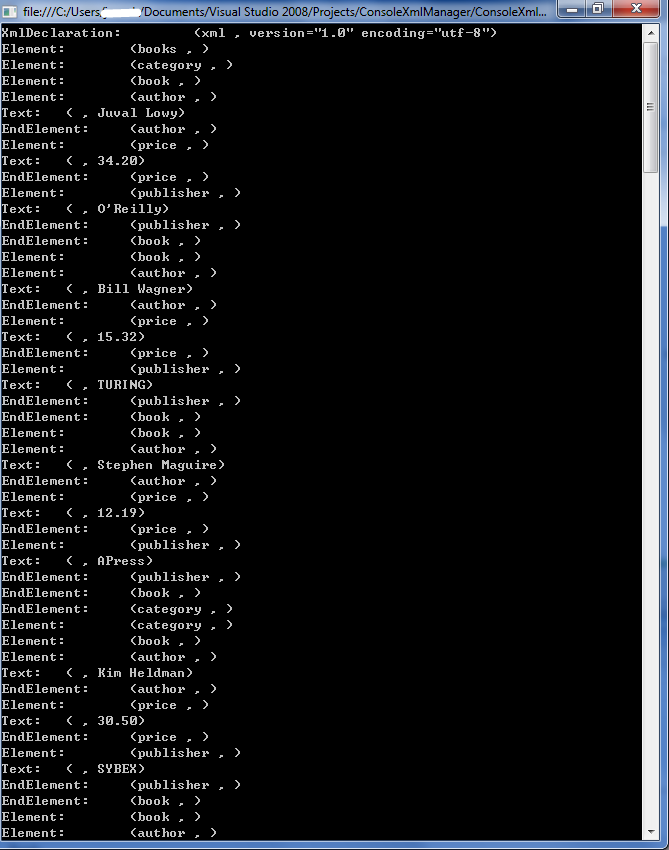

 浙公网安备 33010602011771号
浙公网安备 33010602011771号