

PageObject课程培训记录
前言
昨晚的培训课程讲了PO设计模式,对于PO模式我们需要去了解关于为什么要使用PO,而不使用PO是什么情况?什么是PO模式?PO怎么去使用?
第一,为什么要使用PO,而不使用PO是什么情况?
我们先来看看在使用PO之前,我们的自动化是怎么做的:
# -*- coding:utf-8 -*- __author__ = "清风" from selenium import webdriver driver = webdriver.Firefox() # 打开浏览器 driver.get("http://www.baidu.com") # 百度搜索 输入selenium driver.find_element("id","kw").send_keys("selenium") # 点击搜索按钮 driver.find_element("id","su").click() driver.quit()
从上述代码中,我们能看出我们做UI自动化主要就是定位元素,然后进行输入或鼠标点击操作。可能大家感觉我们写的很简单,但是呢?如果再添加其他操作呢?而且这只是一个页面的操作,那再加上其他的页面呢?随着我们业务越来越多,脚本也就越来越庞大,如果我们要修改页面的元素定位,我们需要去庞大的脚本中寻找到元素,也可能这个元素在多个业务逻辑中都存在,那我们要找到所有存在这个元素的业务逻辑,然后修改这个元素,这就是一个很头疼的事了。一个元素的变动,都需要我们花费大量的代价去维护我们的代码,所以说这时候我们就要引入PO模式来解决这个问题。
第二,什么是PO模式?
PO模式:Page Object Model(也称POM),页面对象模型(POM)是一种设计模式,实现了对页面元素及方法的分离。
通过类来管理页面:程序的每一个页面都有一个对应的page class
通过属性来管理操作对象:每一个页面需要操作的元素都是一个页面类的属性
通过方法来管理业务:每一个业务逻辑都使用类方法去进行管理,方法名最好根据对应的业务场景进行命名。
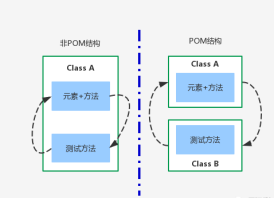
PO模式的好处:
-
POM提供了一种在将页面及元素对象、业务流程操作与验证分离的模式,这样会使得测试代码变得更加清晰和高可读性
-
对象库与用例分离,使得我们更好的重用对象,方便修改变化。
-
页面元素操作方法会使用例变得更加简洁。
-
简单明了的命名方式使得我们更方便的知道方法所操作的对象
第三,怎么去使用PO?
先来看下代码的目录结构:
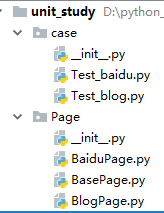
Page目录下存放的是页面对象,BasePage是基类,我们页面对象需要继承基类。
先看基类的代码:
# -*- coding:utf-8 -*- __author__ = "清风" from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait from TestTools.log import log class Base_page(): """ Page基类,所有page类都需要继承该类 """ def __init__(self,driver,base_url): self.driver = driver self.base_url = base_url self.log = log() def find_element(self,*loc,timeout=20): try: WebDriverWait(self.driver,timeout).until(EC.presence_of_element_located(loc)) return self.driver.find_element(*loc) except: self.log.error("对象没有找到!") def send_value(self,loc,text): self.find_element(*loc).send_keys(text) def click(self,loc): self.find_element(*loc).click()
基类主要是将selenium的元素操作进行了再次封装,方便我们的调用。
再看我们的Page页面类:
# -*- coding:utf-8 -*- __author__ = "清风" from Page.BasePage import Base_page class BaiduSerch(Base_page): search_input_loc = ("id","kw") search_button_loc = ("id","su") def __init__(self,driver,base_url="http://www.baidu.com"): Base_page.__init__(self,driver,base_url) def gotoBaidu(self,title): self.driver.get(self.base_url) self.is_title(title) def is_title(self,title): assert title in self.driver.title def input_search(self,text="selenium"): self.send_value(self.search_input_loc,text) def click_button(self): self.click(self.search_button_loc) def search_baidu(self,title,text): self.gotoBaidu(title) self.input_search(text) self.click_button()
Page类主要是将页面元素变为了类属性,将元素操作变为可调用方法,并且也将业务逻辑变为了方法。
再看测试类:
# -*- coding:utf-8 -*- __author__ = "清风" import unittest from selenium import webdriver from TestTools.getCase import getCase import ddt from Page.BaiduPage import BaiduSerch test1 = [['1','test1','selenium','百度一下,你就知道']] @ddt.ddt class testBaidu(unittest.TestCase): excel = getCase() cls = excel.excel_read() def setUp(self): self.driver = webdriver.Firefox() @ddt.data(*test1) def testBaidu(self,cls): print("用例id=%s, 用例名称=%s" % (cls[0],cls[1])) bsp = BaiduSerch(self.driver) bsp.search_baidu(cls[3], cls[2]) def tearDown(self): self.driver.quit() if __name__ == '__main__': unittest.main()
测试类只需要将driver初始化,然后去调用我们的页面类,直接调用我们封装的页面业务逻辑,就可以开始测试了。
最后,只需要运行我们的unittest测试集即可。
最后,关于重点需要指出内容:
我们在使用PO时,使用的selenium查找对象元素的方法是find_element,这时候我们去建立页面属性时使用的是变量存放,如:
search_input_loc = ("id","kw")
则我们需要这样使用driver.find_element(*search_input_loc),为什么加*呢?
在python中,如果是在函数调用中,* args表示将可迭代对象扩展为方法的参数列表;如果是函数定义中参数前的*表示的是将调用时的多个参数放入元组中;
这里是重点,因为如果这里没写好,就会报错。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号