【机器学习分类任务2】Xgboost分类任务 -- BBC新闻文章
本文将以BBC新闻文章分类为例,讨论不同的文本分类技术。同时,本文将讨论如何用不同向量空间模型代表文本数据。
具体数据集:https://www.kaggle.com/yufengdev/bbc-fulltext-and-category
为解决此问题,将使用到Python、Sci-kit-learn、Genism和Xgboost库等工具。
以下代码均在 jupyter notebook 上进行,也可以在其他解释器执行,大同小异:
GET_DATA --> 获取数据,查看数据展现格式
import pandas as pd
bbc_text_df = pd.read_csv("bbc-text.csv")
bbc_text_df.head()

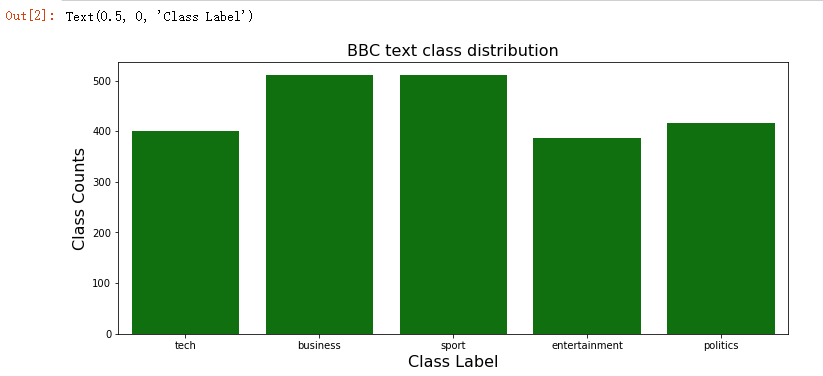
Data Exploration & Visualisation --> 查看BBC新闻的分类统计情况
%matplotlib inline
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(12,5))
sns.countplot(x=bbc_text_df.category, color='green')
plt.title('BBC text class distribution', fontsize=16)
plt.ylabel('Class Counts', fontsize=16)
plt.xlabel('Class Label', fontsize=16)
# plt.xticks(rotation='vertical');
# 标签标记
label_enum = {
"tech":0,
"business":1,
"sport":2,
"entertainment":3,
"politics":4
}
Data Clean --> 清洗数据,利用Gensim自带的一些清洗效果
from gensim import utils
import gensim.parsing.preprocessing as gsp
filters = [
gsp.strip_tags, # 删除多余的html标签
gsp.strip_punctuation, # 删除标点符号
gsp.strip_multiple_whitespaces, # 删除多行
gsp.strip_numeric, # 删除数字
gsp.remove_stopwords, # 删除停用词(英文中的and, to, the)
gsp.strip_short, # 小写形式化单词
gsp.stem_text # 提取词干到词源的形式
]
def clean_text(s):
s = s.lower()
s = utils.to_unicode(s)
for f in filters:
s = f(s)
return s
## 原数据结果
bbc_text_df.iloc[2,1]

## 使用gensim的清洗结果

Data Statisticss Gesture --> 词云表述,展现词数,词语越多的,呈现的字体越大
%matplotlib inline
from wordcloud import WordCloud
def plot_word_cloud(text):
wordcloud_instance = WordCloud(width = 800, height = 800,
background_color ='black',
stopwords=None,
min_font_size = 10).generate(text)
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud_instance)
plt.axis("off")
plt.tight_layout(pad = 0)
plt.show()
texts = ''
for index, item in bbc_text_df.iterrows():
texts = texts + ' ' + clean_text(item['text'])
plot_word_cloud(texts)
## 针对某个类别进行查看词云情况
def plot_word_cloud_for_category(bbc_text_df, category):
text_df = bbc_text_df.loc[bbc_text_df['category'] == str(category)]
texts = ''
for index, item in text_df.iterrows():
texts = texts + ' ' + clean_text(item['text'])
plot_word_cloud(texts)
### 'tech'类
plot_word_cloud_for_category(bbc_text_df,'tech')
### 'sport'类
plot_word_cloud_for_category(bbc_text_df,'sport')
### 'politics'类
plot_word_cloud_for_category(bbc_text_df,'politics')

Split Data
df_x = bbc_text_df['text'] df_y = bbc_text_df['category']
print(df_x.shape)
print(df_y.shape)
Building the Machine Learning model & pipeline --> 构建特征向量转换器 & 管道
Doc2Vec转换器
from gensim.models.doc2vec import TaggedDocument, Doc2Vec
from sklearn.base import BaseEstimator
from sklearn import utils as skl_utils
from tqdm import tqdm
import multiprocessing
import numpy as np
class Doc2VecTransformer(BaseEstimator):
def __init__(self, vector_size=100, learning_rate=0.02, epochs=20):
self.learning_rate = learning_rate
self.epochs = epochs
self._model = None
self.vector_size = vector_size
# self.workers = multiprocessing.cpu_count() - 1
# 采用一般的CPU核数
self.workers = multiprocessing.cpu_count()//2
def fit(self, df_x, df_y=None):
tagged_x = [TaggedDocument(clean_text(row).split(), [index]) for index, row in enumerate(df_x)]
model = Doc2Vec(documents=tagged_x, vector_size=self.vector_size, workers=self.workers)
for epoch in range(self.epochs):
# 随机打乱
model.train(skl_utils.shuffle([x for x in tqdm(tagged_x)]), total_examples=len(tagged_x), epochs=1)
model.alpha -= self.learning_rate
model.min_alpha = model.alpha
self._model = model
return self
def transform(self, df_x):
return np.asmatrix(np.array([self._model.infer_vector(clean_text(row).split())
for index, row in enumerate(df_x)]))
# Doc2Vec转换器 -- 文章的数字化特征,
doc2vec_trf = Doc2VecTransformer() doc2vec_features = doc2vec_trf.fit(df_x).transform(df_x) doc2vec_features
Pipeline with Doc2Vec & LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
pl_log_reg = Pipeline(steps=[('doc2vec',Doc2VecTransformer()),
('log_reg', LogisticRegression(multi_class='multinomial', solver='saga', max_iter=100))])
scores = cross_val_score(pl_log_reg, df_x, df_y, cv=5,scoring='accuracy')
print('Accuracy for Logistic Regression: ', scores.mean())
## 结果展示,精确度,看起来doc2vec转换的文章向量,准去率不高 -->
Accuracy for Logistic Regression: 0.36675712731190263
Pipeline with Doc2Vec & RandomForest
from sklearn.ensemble import RandomForestClassifier
pl_random_forest = Pipeline(steps=[('doc2vec',Doc2VecTransformer()),
('random_forest', RandomForestClassifier())])
scores = cross_val_score(pl_random_forest, df_x, df_y, cv=5,scoring='accuracy')
print('Accuracy for RandomForest : ', scores.mean())
## 结果展示,精确度,看起来doc2vec转换的文章向量,准确率也不高 -->
Accuracy for RandomForest : 0.3371682446893121
Pipeline with Doc2Vec & Xgboost
import xgboost as xgb
pl_xgb = Pipeline(steps=[('doc2vec',Doc2VecTransformer()),
('xgboost', xgb.XGBClassifier(objective='multi:softmax'))])
scores = cross_val_score(pl_xgb, df_x, df_y, cv=5)
print('Accuracy for XGBoost Classifier : ', scores.mean())
## 结果展示,精确度,看起来doc2vec转换的文章向量,准确率也不高 -->
Accuracy for XGBoost Classifier : 0.3622375475395138
“Tf-Idf”编写一个相似Doc2Vec的转换器。
from sklearn.feature_extraction.text import TfidfVectorizer
class Text2TfIdfTransformer(BaseEstimator):
def __init__(self):
self._model = TfidfVectorizer()
pass
def fit(self, df_x, df_y=None):
df_x = df_x.apply(lambda x : clean_text(x))
self._model.fit(df_x)
return self
def transform(self, df_x):
return self._model.transform(df_x)
tfidf_transformer = Text2TfIdfTransformer() tfidf_vectors = tfidf_transformer.fit(df_x).transform(df_x)
tfidf_vectors.shape
print(tfidf_vectors)
-->
(2225, 18754)

### 打标签
#label label = np.array(df_y) #特征 features = tfidf_vectors[:,:]
Tf-Idf & LogisticRegression
pl_log_reg_tf_idf = Pipeline(steps=[('tfidf',Text2TfIdfTransformer()),
('log_reg', LogisticRegression(multi_class='multinomial', solver='saga', max_iter=100))])
scores = cross_val_score(pl_log_reg_tf_idf, df_x, df_y, cv=5,scoring='accuracy')
print('Accuracy for Tf-Idf & Logistic Regression: ', scores.mean())
## 结果展示,精确度,看起来tfidf转换的文章向量,准确率很高 -->
Accuracy for Tf-Idf & Logistic Regression: 0.8966269268867583
Tf-Idf & RandomForest
pl_random_forest_tf_idf = Pipeline(steps=[('tfidf',Text2TfIdfTransformer()),
('random_forest', RandomForestClassifier())])
scores = cross_val_score(pl_random_forest_tf_idf, df_x, df_y, cv=5,scoring='accuracy')
print('Accuracy for Tf-Idf & RandomForest : ', scores.mean())
## 结果展示,精确度,看起来tfidf转换的文章向量,准确率很高 -->
Accuracy for Tf-Idf & RandomForest : 0.8687162071782858
Tf-Idf & XGBoost
pl_xgb_tf_idf = Pipeline(steps=[('tfidf',Text2TfIdfTransformer()),
('xgboost', xgb.XGBClassifier(objective='multi:softmax'))])
scores = cross_val_score(pl_xgb_tf_idf, df_x, df_y, cv=5)
print('Accuracy for Tf-Idf & XGBoost Classifier : ', scores.mean())
## 结果展示,精确度,看起来tfidf转换的文章向量,准确率很高 -->
Accuracy for Tf-Idf & XGBoost Classifier : 0.933037928578659
How to Train A Xgboost
from sklearn.model_selection import train_test_split # 分训练集测试集
# features --> 上面用tfidfvector进行转换成文章数字向量
# label --> 文章的分类的情况
# 训练集:测试集 = 99:1 --> 因为数量比较少,比较极端的取法,建议还是8/2比例
X_train, X_test, y_train, y_test = train_test_split(features, label, test_size=0.01, random_state=3)
# 构建Xgboost模型
model = xgb.XGBClassifier(learning_rate=0.01, n_estimators=10, # 树的个数-10棵树建立xgboost max_depth=10, # 树的深度 min_child_weight = 1, # 叶子节点最小权重 gamma=0.1, # 惩罚项中叶子结点个数前的参数 subsample=0.7, # 所有样本建立决策树 colsample_btree=0.7, # 所有特征建立决策树 scale_pos_weight=1, # 解决样本个数不平衡的问题 random_state=27, # 随机数 slient = 0, objective='multi:softmax' ) model.fit(X_train, y_train)
# 多分类任务的预测情况
from sklearn import metrics #预测 y_test, y_pred = y_test, model.predict(X_test) print("Accuracy : %.4g" % metrics.accuracy_score(y_test, y_pred))
# 预测结果展示:
Accuracy : 0.9565
尾声 --> 总结
尽管在自然语言处理中,“DocVec”模型比“Tf-Idf”模型更高级,但我们的案例证明,后者效果更佳。我们分别使用了基于线性、袋状以及推进型的分类器。
原因可以这么理解。在我们的数据集中,每一个“文本”领域包含了一些决定其类别的高频单词/标记。因此,应用一个对语境/上下文敏感的模型会使问题更为复杂、(或者)混淆信息。某些文本类别包含一些高频出现的标记,这些标记提供了大量数值以定义“Tf-Idf”模型。同时,“文本”是细分领域的。
比如,“布莱尔 (blair) ”一词更可能出现在“政治”类别,而非“运动”类别。因此,像这样的词对“Tf-Idf”模型起了作用。
而且,“Doc2Vec”模型更适合应用于语法正确的文本中。
而我们的案例文本本质上过于粗糙。
“维基百科”文本就是一个语法正确的文本。
同时,大量案例和数据科学家的实验证明,虽然“Tf-Idf”模型次于”DocVec”模型,但前者对于细分领域的文本分类更为有效。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号