阅读笔记: Knowledge Graph Embedding Based Question Answering
Knowledge Graph Embedding Based Question Answering
本文是论文Knowledge Graph Embedding Based Question Answering的阅读笔记和个人理解.
Basic Idea
作者发现KBQA中的三个挑战问题:
- 谓词(关系)有多种自然语言的表示法.
- 实体也会有严重的模糊性而产生大量候选答案, 即实体的歧义问题.
- 用户的问题领域可能是开放的, KG也有可能是不完整的, 这对鲁棒性有一定的要求.
Knowledge Embedding可以将实体映射为低维向量, KG中的关系信息会被保存, 各种KRL会非常有益于下游任务. 因此, 作者希望提出一种基于KGE方法, 并能够回答所有自然语言问题的框架.
KGE能够保证得到的单词表示的质量, 因为每个嵌入表示都是与整个KG交互的结果, 并且它也能保持相似的关系或实体之间的表示相似性.
在本文中, 作者只关注了最简单的QA, 直接使用一个三元组就能描述整个问题, 而非多跳推理的问题.
KEQA
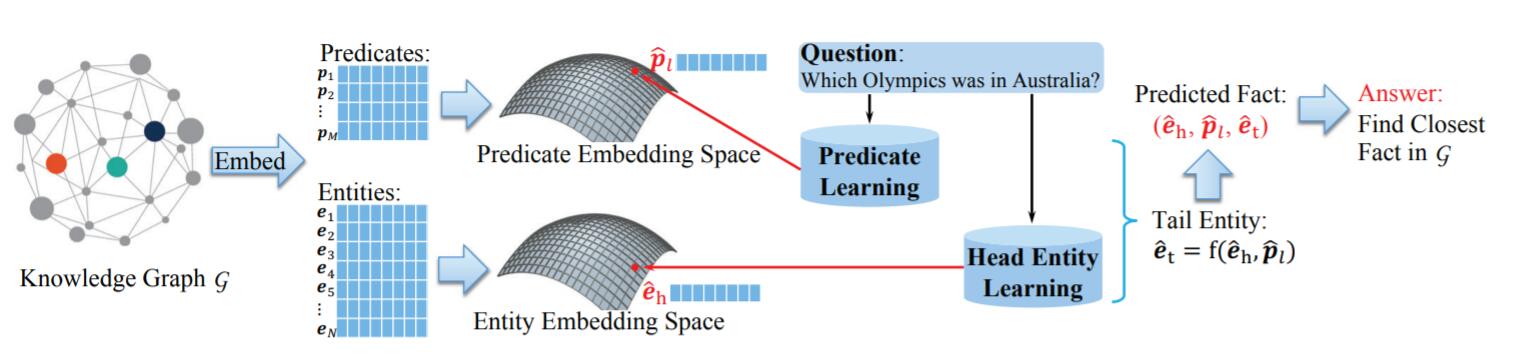
KEQA的大致思路是通过某种结构, 对自然语言中的整个句子抽取出与Knowledge Embedding相似的表示, 即希望用句子抽取后的表示空间等价于Knowledge Embedding的空间.
Predicate and Head Entity Learning Models
Knowledge Graph Embedding

当KGE训练完成时, 实体和关系的表示将会固定下来, 这样才能保存住KG的信息. 若继续在后续训练时更新Embedding, 将会对原有信息扰动. 所以KGE只是做了空间指示作用.
Neural Network Based Predicate Representation Learning
有了KGE中获取的 P, E, 接着需要将自然语言中的谓词表示(在三元组中也是关系)与KGE空间相对齐, 作者在这里采用了比较简单的双向LSTM + Attention:
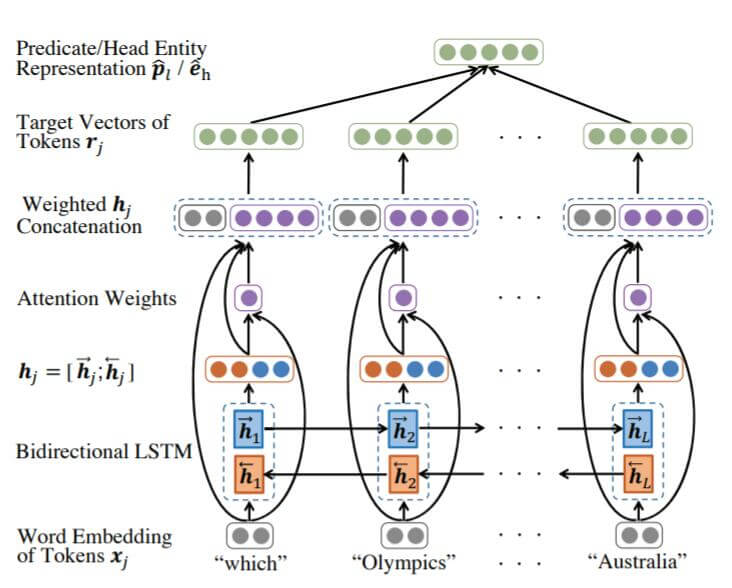
其实在作者发布的代码中, 用的是GRU, 不过都大差不差了.
图中在绿色向量 rj 和 hj 拼接后的向量之间还有一个FC层没画出来.
先将自然语言的Token转换为Embedding(图中灰色), 记为 xj , 然后再用双向LSTM获取双向表示 hj (图中红色蓝色).
下述数学表达都是LSTM, 左右双向同理, 下面只是单向:
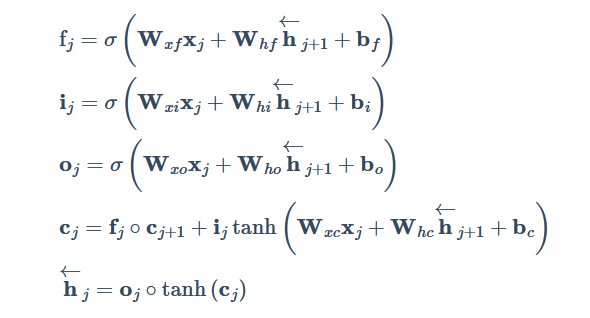

Neural Network based Head Entity Learning Model
对于一个自然语言问题, 作者用类似获取谓词表示的方法获取头实体表示![]() , 用同样的架构获取头实体的表示, 也与KGE空间相对齐.
, 用同样的架构获取头实体的表示, 也与KGE空间相对齐.
这样直接把NER这步给省略掉了, 规避了自然语言中实体表示的模糊性问题.
Head Entity Detection Model
因为自然语言问题中的候选实体可能过多, 所以需要一个头实体检测模型来减少问题中的候选实体, 从一个句子中选择一个或几个连续的Token作为实体名称.
同样是使用双向LSTM去处理整个句子:
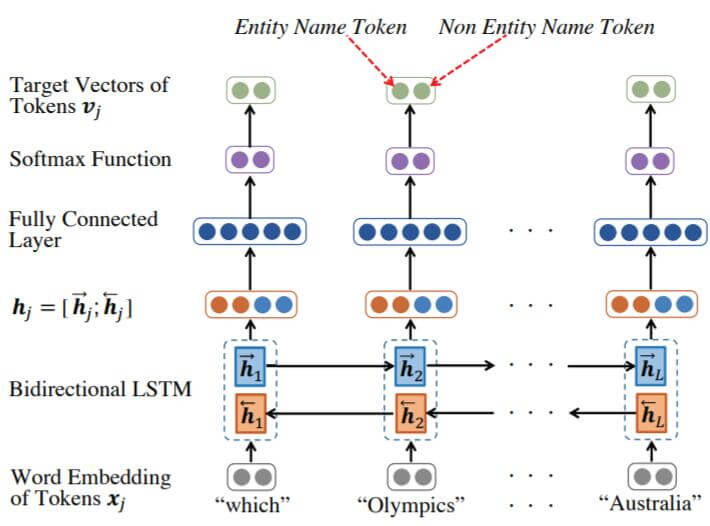

这样, 相连的HED可能是同一个实体, 而不相连的HED可能是多个实体名. 在获取完实体名后, 再从KG中找到对应的候选实体集, 很大程度上缩小了与KG中实体匹配的范围.
Joint Search on Embedding Spaces
如果只是想简单的缩小模型与KGE空间中的距离, 只需计算模型抽取出的表示与KGE空间中表示的范数. 但这显然没有考虑过KGE中保留的关系信息.
基于前面的谓词学习模型, 实体学习模型, 头实体检测模型, 作者提出了对三种模型的联合距离度量:
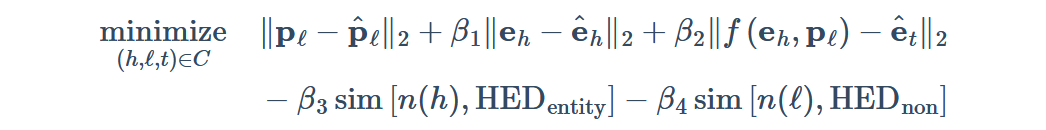

第一, 二项均用于缩小模型抽取出的头实体和谓词表示与KGE空间中相应表示的距离, 第三项用于缩小尾实体表示与KGE中相应实体表示的距离. 第四项和第五项针对头实体检测模型, ![]() 是度量两个字符串之间相似性的函数, 在这里最大化标出的头实体和目标实体之间的相似度, 以及句子的非实体部分和真实谓词之间的相似度.
是度量两个字符串之间相似性的函数, 在这里最大化标出的头实体和目标实体之间的相似度, 以及句子的非实体部分和真实谓词之间的相似度.
KEQA的框架执行流程如下:

大致流程是:

头实体检测模型训练时采用的损失与联合距离度量略有不同, 训练时采用的是极大似然, 但在计算联合距离时采用的是字符串相似度.
KEQA对不同的损失项的优化实际上是分步运行的, 并且不同损失项针对的是不同模型.
Experiments
实验部分详细的参数请参照原论文.
Datasets
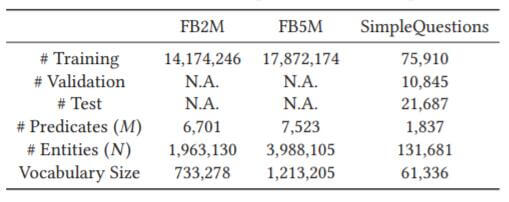
因为本文探讨的是简单问题的回答, 作者除了采用FB2M, FB5M外, 还使用了从FB2M中的子集数据集SimpleQuestions, 统计信息如下:
Effectiveness of KEQA
KEQA在FB2M, FB5M上的实验结果如下:
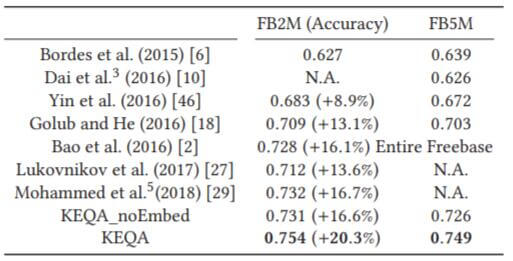
其中, KEQA_noEmbed是随机得到的Embedding, 没有经过KGE训练.
相较于提出的Baseline, 提升比较大. 在引入Knowledge Embedding后, 模型性能有了进一步的提升, 但其实在没引入KGE模型的情况下, 本身的效果也还可以, 因为它仍然超过了其他的Baseline.
Generalizability and Robustness Evaluation
为检测KEQA的鲁棒性, 作者从两个角度做了实验:
- 对KEQA使用不同的KGE方法.
- 对所有的谓词划分为三个组, 然后将训练集, 验证集, 测试集的问题按照谓词划分为三组. 这样测试集中出现的谓词肯定没有在训练集和验证集中出现过, 三类数据的谓词都是相互独立的. 按照该方法将SimpleQuestions改进为SimpleQ_Missing.
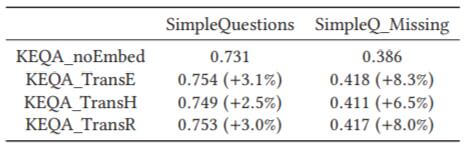
不同的KGE方法对结果其实没有太大的影响. 最简单的TransE就能有不错的结果. 对于新的数据集, 在TransE的帮助下仍然有40%左右的精度, 比不依赖KGE方法要高一些.
Parameter Analysis
为了探究联合距离度量中每项的贡献程度, 作者分别采用三种设置:
- Only_Keep: 仅保留五项中的该度量.
- Remove: 从五项中删除该项度量.
- Accumulate: 逐项添加度量.
实验结果如下:
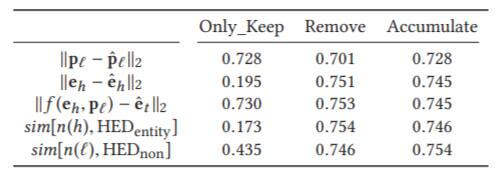
仅保留实体相关项的精度都非常低, 而仅保留谓词项的精度都比较高, 这也侧面说明了关系在KGE中发挥的重要作用, 实际上就是在针对关系学习.
在第一二项均保留的情况下, 结合谓词信息, 实体信息能够得到充分的利用.
第五项仍然使得模型性能涨了一个点, 说明问题中的某些Token可能和谓词共享信息.
我认为第三项和第一二项可能是近似等价的, 而不是互为补充的.
因为第三项的引入并没有使得模型性能提升产生多大的变化, 但仅保留时仍然发挥了相当重要的作用, 而且在删除第三项时也没有对性能产生太大的影响.
即仅保留第三项时没有第一二项, 性能好. 删除第三项, 剩下其余四项, 性能没有明显变化. 在已经有第一二项的情况下, 加上第三项, 几乎无提升.
Summary
KEQA是一种基于Knowledge Embedding的问答框架, 能从繁杂的自然语言中直接抽取出谓词表示和实体表示, 缓解了自然语言的模糊性和歧义性问题. 并通过头实体检测模型过滤掉非常多的候选实体三元组, 缩小搜索范围. 同时, 作者充分结合了KGE能够保存关系信息的特性, 提出了联合距离度量.
除此外, 我个人认为联合度量中第三项的必要性是有待商榷的.
BERT具有类似KGE获取表示的能力, 在依托KGE方法的KEQA的框架下, 结合一些上下文相关的KGE方法可能会有奇效, 例如CoKE, CoLAKE, 因为它们与KEQA类似能够利用自然语言信息的能力, 而不单单是利用知识本身.
本文只关注于最基本的单跳简单问题, 该如何扩展到多跳复杂问题?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号