(转)第三章 少量(无)标记增强现实——Chapter 3:Marker-less Augmented Reality
第三章 少量(无)标记增强现实——Chapter 3:Marker-less Augmented Reality

5、我的工程下载地址:http://download.csdn.net/detail/xuluhui123/6599019
6、本章用的OpenCV2.4.3编译支持OpenGL的lib和dll下载地址:http://download.csdn.net/detail/xuluhui123/6599081
7、如果你不想下载我编译好的OpenCV2.4.3,自己编译的话,请参考:http://blog.csdn.net/raby_gyl/article/details/16877141
8、书中源代码的最新更新可以参考网址:https://github.com/MasteringOpenCV/code
请先阅读:
0、Marker-less可能翻译成无标记吧,像homeless表示无家可归等等。对于第二章基于标记的内容不晓得讲的什么,谢谢网友的纠正,下面的不再修改了。
1、运行本章的程序必须是OpenCV2.4.2版本以上,但是OpenCV2.4.6版本(或者以上)是不可以用的。我亲自用OpenCV2.4.6版本进行重新编译使其支持OpenGL,编译后支持是支持了,但是运行本章程序时会报错。原因是:你可以参看一下两个版本或者更多OpenCV版本中支持OpenGL的源文件发生了显著的改变。如在目录下:D:\opencv\modules\core\src ,OpenCV 2.4.7版本opengl_interop.cpp是没有的。OpenCV 2.4.3版本也是没有:gl_core_3_1.cpp,而OpenCV2.4.6含有这个版本等等。我使用的是OpenCV2.4.3,你可以自己编译使其支持OpenGL,也可以从我上面的连接下载编译好的,建议下载编译好的。对于OpenCV2.4.5,OpenCV2.4.4等是否编译后能够运行本章程序,我并没有测试过。你可以从上面注释6下载。
2、本章我的工程可以从上面注释5中下载,并要看一下下面的第7条。我的工程中修改了一下std::min和std::max。
3、我不是搞三维重建的,也没有接触过OpenGL。所有翻译内容不免有错,仅供参考。并且我只是运行了程序,并没有分析程序中代码和流程,对具体操作还不清楚,所以翻译也难免有错。快考六级了,还有很多事情要做,等以后有空再具体分析整个工程的操作。阅读本文时,一定要参考英文原文。
4、要学习本章,你必须有C++编程基础,并且会一些OpenGL。使OpenCV支持OpenGL并不是OpenGL所有代码在OpenCV的环境下运行。只是支持其部分功能。
5、运行本章程序建议使用台式机,不要使用笔记本。因为将进行大量的数学运算。
6、文章中绿色部分是个人理解,不是翻译内容。
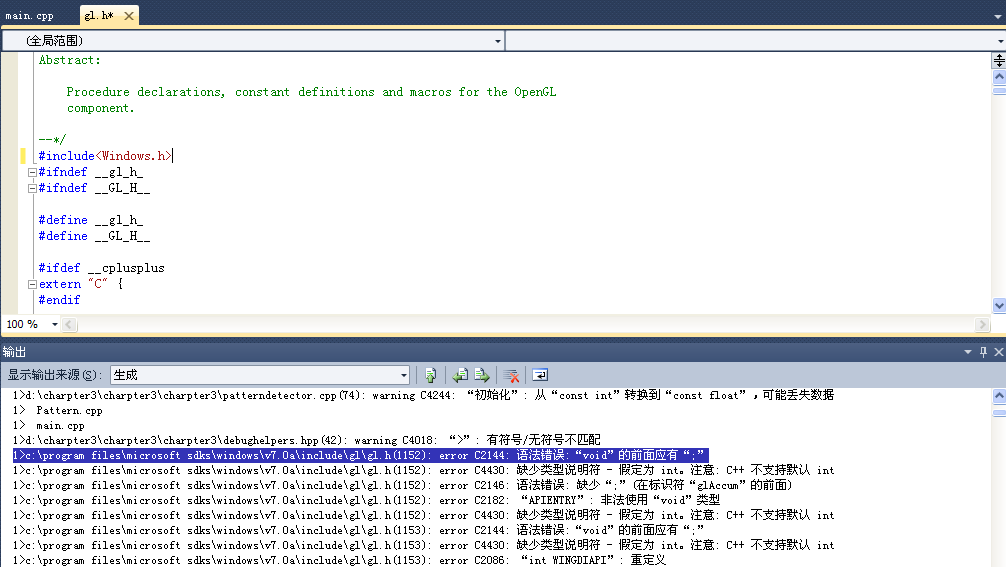
7、编译下载后我的工程(上面注释5)时,如果出现下面的截图错误,则双击错误跳转到gl.h文件,在上面添加#include<Windows.h>,如下图所示:
Chapter 3 Marker-less Augmented Reality
在这一章读者将要学习如何利用OpenCV创建一个标准的实时工程,并且学习怎样使用实际环境作为输入代替印刷的正方形标记(printed square markers)来执行一个少量标记增强现实的新方法。在这以一章将涉及到一些少量标记AR(AR就是Augmented Reality,增强现实)理论和怎么在有用的工程中使用它。
本章将包含下面的主题列表:
1、基于标记(Marker-based) VS 少量标记增强现实(Marker-less AR)2、使用特征描述子来找到视频中的任意图像
3、模式姿态估计。(这里模式可以认为是一个样本,我们匹配两个图像中的特征点时一个是pattern image 模式图像,一个是test image测试图像)
4、应用基础结构
5、在OpenCV中支持OpenGL的可视化
6、渲染增强的现实
7、示范
在开始之前,让我简单的列一下这一章你将要需要的知识和软件:
1、CMake的基础知识。CMake是一个交叉平台的、开源的编译系统。用来编译、测试和打包软件。像OpenCV的库,本章的示例工程同样使用CMake编译系统。CMake可以从这里下载: http://www.cmake.org/.2、需要C++编程语言的基础知识。不过,应用程序源代码的所有复杂的部分将详细的阐述。
基于标记(Marker-based)VS 少量标记增强现实(marker-less AR)
在前一章,我们学习了怎样使用指定的的图像(称为markers,标记)来增强一个现实场景。这个markers的优点如下:
1、简单的检测算法
2、对光照变化有鲁棒性
markers同样也有一些缺点,如下:
1、如果部分重叠了,则不能工作。
2、标记图像(Marker image)必须是黑色和白色
3、在大多数情况下拥有正方形外形(因为易于检测)
4、marker非审美的可视化外表
5、与现实世界的对象没有共同点
因此,markers是一个好的起始点来学习增强现实技术。但是如果你想进一步的学习,是时候从基于标记(marker-based)转向少量标记增强现实了(marker-less AR)。
少量标记增强现实是一种基于真实世界存在的目标的识别的一种技术。一些使用少量标记增强现实的例子:杂志封面,公司logo,玩具,等等。总的来说,任何对象,拥有关于场景部分的足够的描述性和可分性的信息,都可以作为少量标记增强现实技术应用的对象。
少量标记增强现实方法的优点是:
1、可以用来检测现实世界的对象
2、即使目标对象部分重叠也可以工作
3、可以有任意外形和纹理(除了立方体或者平滑的梯度纹理)
少量标记AR(少量标记增强现实)系统可以使用真实图像和目标在3D空间定位相机以及在真实图片上呈现引人注目的效果。少量标记AR的核心是图像识别和目标检测算法。不像markers,makers的形状和内部结构是固定和已知的,真实对象不能用这样的方式定义。同样的,物体可以拥有复杂的形状并且需要修改姿势估计算法来找到他们正确的3D转换。
注释:
为了让你知道少量标记AR的思想,我们将使用平面图像作为目标。在这里,我们不在详细考虑复杂形状的物体。在本章的后面部分,我们将讨论用来增强现实的复杂形状。
少量标记AR执行大量的CPU运算,因此移动设备经常不能保持平稳的视频帧率。在这一章,我们将针对台式电脑平台,例如PC或者Mac。为了这个目标,我们需要一个交叉平台编译系统。在这一章,我们使用CMake编译系统。
使用特征描述在视频中找到一个任意的图像
图像识别是一种计算机视觉技术,它对特定的位图模式来搜索输入图像。即使图像尺度化,旋转,和原图像有不同亮度,我们的图像识别算法也能够检测到这个模式。
我们如何比较模式图像(pattern image)和其他图像呢?因为模式(the pattern)受透视变换的影响,很显然,我们不能直接比较模式图像(the pattern)和测试图像(test image)。在这种情况下,特征点和特征描述子很有用。特征是什么没有一般性或者准确性的定义。准确的定义经常依赖于实际问题或者应用类型。通常,一个特征是指一副图像中“感兴趣”的部分,并且特征通常作为许多机器视觉算法的起始点。在这一章,我们将使用特征点(feature point)术语,它是定义了中心点,半径和方向的图像中的一部分。每一个特征检测算法试图检测同样的特征点而忽略透视变换的影响。
特征提取
特征检测是用来从输入的图像中找到感兴趣区域的方法。有很多特征检测算法,这些算法寻找边缘,角点,或者斑点。在我们实例中,我们对于角点检测感兴趣。角点检测是分析图像中的边缘。一种基于角点的边缘检测算法寻找图中梯度的快速变化。通常,这种做法通过寻找图像梯度在x,y方向上的一阶导数的极值来实现。
通常使用在特定区域中占主导图像梯度的方向作为特征点的方向。当图像旋转或者尺度化,特征检测算法重新计算占主导地位的图像梯度方向。这意味着,忽略图像的旋转,特征点的方向不会发生改变。这样的特征称为旋转不变性(rotation invariant)。
同样地,我们必须提及一些关于特征点尺寸的要点。一些特征检测算法使用固定尺寸(fixed-size)的特征,然而其他算法分别地计算每一个关键点的最优化尺寸。了解了特征尺寸,我们就可以在尺度化的图像上找到相同的特征点。这使得特征具有尺度不变性。(scale invariant)。
OpenCV带有几个特征检测算法。它们都继承于基类cv::FeatureDetector。特征检测算法的创建可以通过下面两种方式来完成:
1、通过显示调用具体特征检测器类的构造函数:
cv::Ptr<cv::FeatureDetector> detector = cv::Ptr<cv::FeatureDetector>(new cv::SurfFeatureDetector());
cv::Ptr<cv::FeatureDetector> detector = cv::FeatureDetector::create("SURF");
这两个方法都有各自的优点,因此选择你最喜欢的那一个。显示类创建允许我们给特征检测器构造函数传递额外的参数,同时通过算法的名字的创建可以在运行时很容易的切换算法。
为了检测特征点,你应当调用detect方法:
std::vector<cv::KeyPoint> keypoints;
detector->detect(image, keypoints);
检测到的特征点存储于keypoints容器中。每一个关键点包含它的中心,半径,角度和评分,以及一些与特征点的“质量”(quality)或者“强度”(strength)相关的量。每一个特征检测算法拥有自己的评分计算算法,因此比较通过一个特定的检测算法检测到的关键点的评分是很有效的。
注释:
基于角点的特征检测算法使用灰度图像来寻找特征点。描述子的提取算法同样地处理灰度图像。当然,这两个算法可以隐式做彩色转换。但是,在我们的实例中,彩色变换将做两次。我们可以通过显示的将输入图像从彩色转换到灰度来改善性能,并且对特征检测和描述子的提取都使用该过程。
在模式检测中,如果检测器计算关键点的方向和尺寸,那么可以达到最后的效果。这使得关键点对于旋转和尺度具有不变性。最有名的并且鲁棒性的关键点检测算法是众所周知的,它们用在了SIFT和SURT特征检测/描述提取。不幸的是,它们是专利的;因此,对于商业使用并不免费。然而,它们的实现呈现在OpenCV中,因此你可以免费的使用它们做评估。但是也有一些好的并且免费的有效的替代品。你可以使用ORB或者PREAK算法来替代。ORB检测是一个修改的FAST特征检测器。原有的FAST检测器惊人的快,但是它不计算关键点的方向和尺寸。幸运的是,ORB算法能够估算关键点的方向,但是特征尺寸仍然是固定的。从接下来的段落中,你将学习处理这个问题的既好又便宜技巧。但是首先,让我来解释一下为什么特征点在图像识别中如此重要:
如果我们处理的图像通常是24位深度的彩色图像,并且分辨率是640×480,我们将得到912KB的数据。在现实世界中,我们如何找到我们的模式图像(pattern image)呢?
一个像素一个像素的匹配会花费很长时间,并且我们还必须处理旋转和尺度化。当然,这不是可选的。使用特征点可以解决这样的问题。通过检测关键点,我们可以确保返回的特征所描图像部分含有大量的信息(这是因为基于角点的检测器返回边缘,角点,和其他尖锐形状)。因此为了在两个图像帧中找到相对应的部分,我们仅需要匹配关键点。
从关键点定义的块部分(the patch),我们提出一个矢量,称为描述子。它是特征点的一个表现形式。从特征点提取描述子的方法有很多。所有的这些方法都具有各自的优缺点。例如,SIFT和SURT描述子提取算法是密集型(占CPU比较高),但是它提供了带有好的可区分性的鲁棒性的描述子。在我们的样本工程中,我们使用ORB描述子提取算法,这是因为我们也使用它作为一个特征检测器。
注意:
使用来至于同样算法的特征检测器和描述子检测器总是一个好的主意,因为它们可以完美地适合彼此。
特征描述子表现为一个固定大小的矢量(16或者更多的元素)。比方说我们的图像,拥有640×480像素的分辨率并且含有1500个特征点。那么,它将需要1500*16*sizeof(float)=96KB(对于SURF)大小。与原有的图像数据相比小十倍。同样的,操作描述子比操作光栅位图更加容易。对于两个特征描述子,我们可以引入一个相似度的评分——一个度量,即定义两个矢量的相似水平。通常选择L2范数或者汉明距离(基于使用的特征描述子的类型)。
特征描述子提取算法继承于基类cv::DescriptorExtractor。同样地,如同特征检测算法,它们也可以通过指定它们的名字或者使用显示构造函数调用来创建。
一个模式对象的定义——Definition of a pattern object
为了描述一个模式对象,我们引入Pattern 类,该类保存一副训练图像,特征和提取的描述子的列表,对于初始化模式位置的2D和3D对应关系。
/** * Store the image data and computed descriptors of target pattern//存储图像数据和计算得到的目标模式的描述子 */ struct Pattern { cv::Size size; cv::Mat data; std::vector<cv::KeyPoint> keypoints; cv::Mat descriptors; std::vector<cv::Point2f> points2d; std::vector<cv::Point3f> points3d; };
特征点匹配
寻找帧图像和帧图像之间的相应部分过程可以公式化为从一组描述子中找到与另外一个描述子最相邻的描述子。这个过程称之为“匹配”过程。对于描述子的匹配,在OpenCV中有两个主要的算法:
1、Brute-force匹配器(cv::BFMatcher)
2、Flann-based匹配器(cv::FlannBasedMatcher)
Brute-force匹配器通过尝试计算第一个描述子集中的每一个描述子来找到与第二个子集中最相近的描述子(穷举搜索)。cv::FlannBasedMatcher使用快速的近似邻近搜索算法来找到相应的部分(该算法使用第三方库作为最临近算法的库)。
描述子匹配的结果是两个描述子集的一系列对应部分。第一个描述子集通常称为训练集,这是因为它对应于我们的模式图像(pattern image),第二个描述子集称为查询集,这是因为它属于我们将用来寻找目标模式的图像。找到的正确匹配越多(存在更多的相应模式),在这个图像中目标模式呈现更多的可能性。
为了增加匹配速度,我们可以在调用match函数之前训练一个匹配器。训练阶段可以用来最优化cv::FlannBasedMatcher的性能。为此,train类用来为训练描述子建立索引树。并且对于大数据集这将增加匹配的速度(例如,你想从数百张图像中找到一个匹配图像)。对于cv::BFMatcher,train类不做什么,因为没有什么需要预处理的。在内部领域,它只是简单地存储训练描述子(train descriptors)。
PatternDetector.cpp
下面的代码块使用模式图像来训练描述子匹配器:
void PatternDetector::train(const Pattern& pattern) { // Store the pattern object//存储模式对象 m_pattern = pattern; // API of cv::DescriptorMatcher is somewhat tricky//DescriptorMatcher的API有点棘手 // First we clear old train data://首先我们清除旧的训练数据 m_matcher->clear(); // That we add vector of descriptors //我们增加描述子容器 // (each descriptors matrix describe one image).//每一个描述子矩阵描述一副图像 // This allows us to perform search across multiple images://这使得我们可以执行多图像搜索 std::vector<cv::Mat> descriptors(1); descriptors[0] = pattern.descriptors.clone(); m_matcher->add(descriptors); // After adding train data perform actual train://增加训练数据之后,执行实际训练 m_matcher->train(); }
为了匹配查询描述子(query descriptors),我们可以使用下面的cv::DescriptorMatcher类的方法中的一个:
1、用来寻找最佳匹配的简单列表:
void match(const Mat& queryDescriptors, vector<DMatch>& matches,const vector<Mat>& masks=vector<Mat>() );
2、用来寻找每一个描述子的K最邻近的匹配
匹配阶段错误匹配可能发生,这很正常。在匹配中有两种类型的错误:
1、错误正匹配(false-positive matches):当特征点的对应是错误的。
2、错误负匹配(false-negative matches):当特征点在两个图像可视时,没有匹配。
错误正匹配明显不好,但是我们不能处理它们,因为匹配算法已经拒绝了它们。因此我们的目标是最小化错误正匹配的数量。为了拒绝错误的错误的对应,我们使用交叉匹配技术(cross-match technique)。它的思想是用查询集匹配训练描述子集,反义依然。仅这两个匹配中共同的匹配才被返回。当有足够的匹配时,这种技术通常得到带有最少数量异常值的最好的结果。
交叉匹配滤波器——Cross-match filter
交叉匹配(Cross-match)可以在cv::BFMatcher类中访问到。为了应用交叉检验测试,创建一个cv::BFMatcher对象,将构造函数第二个参数设置为true。
cv::Ptr<cv::DescriptorMatcher> matcher(new cv::BFMatcher(cv::NORM_HAMMING, true));
使用交叉检验的匹配结果可以共下面的截图中看到:

比率检定
第二个众所周知的异常值移除技术是比率验证。我们首先执行参数K=2的KNN匹配。对于每个匹配,返回两个最邻近的描述子。只有当第一个匹配和第二个匹配之间的距离比例足够大,匹配才返回(比率阈值通常接近于2)。
PatternDetector.cpp
下面的代码使用比率检定执行鲁棒性的描述子匹配:
void PatternDetector::getMatches(const cv::Mat& queryDescriptors, std::vector<cv::DMatch>& matches) { matches.clear(); if (enableRatioTest) { // To avoid NaNs when best match has // zero distance we will use inverse ratio. //当最好的匹配距离是0时,为了避免出现NaN(除数为0),我们将使用反比例 const float minRatio = 1.f / 1.5f; // KNN match will return 2 nearest // matches for each query descriptor//KNN匹配对于每一个查询描述子返回两个最邻近的匹配 m_matcher->knnMatch(queryDescriptors, m_knnMatches, 2); for (size_t i=0; i<m_knnMatches.size(); i++) { const cv::DMatch& bestMatch = m_knnMatches[i][0]; const cv::DMatch& betterMatch = m_knnMatches[i][1]; float distanceRatio = bestMatch.distance /betterMatch.distance; // Pass only matches where distance ratio between //仅通过最邻近匹配距离比例大于1.5的匹配 // nearest matches is greater than 1.5 // (distinct criteria) if (distanceRatio < minRatio) { matches.push_back(bestMatch); } } } else { // Perform regular match//执行常规匹配 m_matcher->match(queryDescriptors, matches); } }
比率检定几乎可以移除所有的异常值。但是在一些情况下,错误正匹配可以通过这个检定。在下一部分,我们将向你展示如何移除剩下的异常值并且仅剩下正确的匹配。
单应性估计
为了进一步改善我们的匹配,我们使用随机抽样一致性方法(RANSAC)来进行异常值过滤。就像我们正在处理一副图像(一个平面对象)并且我们期望它是刚性的。找到模式图像上的特征点到查询图像上的特征点之间的单应性变换是可以的。单应性变换将点从模式图像转换到查询图像的坐标系统。为了找到这个变换,我们使用cv::findHomography函数。它使用随机抽样一致性方法通过输入点子集来侦探来找到最好的单应性矩阵。作为一种副作用,这个函数标记每一个对应部分为内围层或者离群值(异常值),这取决于计算得到的单应性的重投影误差。
PatternDetector.cpp
下面的代码使用单应性矩阵估计来滤去几何上错误的匹配,矩阵的估计采用RANSAC算法:
bool PatternDetector::refineMatchesWithHomography ( const std::vector<cv::KeyPoint>& queryKeypoints, const std::vector<cv::KeyPoint>& trainKeypoints, float reprojectionThreshold, std::vector<cv::DMatch>& matches, cv::Mat& homography ) { const int minNumberMatchesAllowed = 8; if (matches.size() < minNumberMatchesAllowed) return false; // Prepare data for cv::findHomography //为cv::findHomograph准备数据 std::vector<cv::Point2f> srcPoints(matches.size()); std::vector<cv::Point2f> dstPoints(matches.size()); for (size_t i = 0; i < matches.size(); i++) { srcPoints[i] = trainKeypoints[matches[i].trainIdx].pt; dstPoints[i] = queryKeypoints[matches[i].queryIdx].pt; } // Find homography matrix and get inliers mask//找到单应性矩阵并且获取内围层掩码 std::vector<unsigned char> inliersMask(srcPoints.size()); homography = cv::findHomography(srcPoints, dstPoints, CV_FM_RANSAC, reprojectionThreshold, inliersMask); std::vector<cv::DMatch> inliers; for (size_t i=0; i<inliersMask.size(); i++) { if (inliersMask[i]) inliers.push_back(matches[i]); } matches.swap(inliers); return matches.size() > minNumberMatchesAllowed; }
下面是使用这个技术提纯得到的匹配的可视化:

单应性搜索步骤很重要,因为获得的转换是在查询图像中找到模式图像(the pattern)的关键。
单应性提纯
当我们寻找单应性转换,我们已经拥有所有需要的数据来找到它们在三维空间中的位置。然而,我们可以通过寻找更精确的模式角点(pattern corner)来进一步改善它的位置。为此,我们使用估计的单应性来变换输入图像以获取已经找到的模式(pattern)。结果应当非常接近于源训练图像。单应性提纯可以帮助我们找到更精确的单应性变换。

然后,我们获得另一个单应性和另一个内层围特征集。结果精确的单应性将是第一个单应性矩阵H1和第二个单应性H2矩阵的乘积。
PatternDetector.cpp
下面的代码块包含了模式检测过程的最终版本:
bool PatternDetector::findPattern(const cv::Mat& image, PatternTrackingInfo& info) { // Convert input image to gray //转换输入图像到灰度 getGray(image, m_grayImg); // Extract feature points from input gray image //从灰度图像中提取特征点 extractFeatures(m_grayImg, m_queryKeypoints, m_queryDescriptors); // Get matches with current pattern//使用当前模式获取匹配 getMatches(m_queryDescriptors, m_matches); // Find homography transformation and detect good matches//寻找单应性变换和检测好的匹配 bool homographyFound = refineMatchesWithHomography( m_queryKeypoints, m_pattern.keypoints, homographyReprojectionThreshold, m_matches, m_roughHomography); if (homographyFound) { // If homography refinement enabled //如果启用单应性提纯,则改善找到的单应性变换 // improve found transformation if (enableHomographyRefinement) { // Warp image using found homography//使用找到单应性转换图像 cv::warpPerspective(m_grayImg, m_warpedImg, m_roughHomography, m_pattern.size, cv::WARP_INVERSE_MAP | cv::INTER_CUBIC); // Get refined matches://获取提纯的匹配 std::vector<cv::KeyPoint> warpedKeypoints; std::vector<cv::DMatch> refinedMatches; // Detect features on warped image//在转换后的图像上检测特征 extractFeatures(m_warpedImg, warpedKeypoints, m_queryDescriptors); // Match with pattern//使用模式进行匹配 getMatches(m_queryDescriptors, refinedMatches); // Estimate new refinement homography//估计新的提纯单应性 homographyFound = refineMatchesWithHomography(warpedKeypoints, m_pattern.keypoints, homographyReprojectionThreshold, refinedMatches,m_refinedHomography); // Get a result homography as result of matrix product // of refined and rough homographies://得到一个结果单应性作为提纯和粗糙单应性矩阵乘积的结果。 info.homography = m_roughHomography * m_refinedHomography; // Transform contour with precise homography//使用精确的单应性转换轮廓 cv::perspectiveTransform(m_pattern.points2d, info.points2d, info.homography); } else { info.homography = m_roughHomography; // Transform contour with rough homography//使用粗略的单应性转换轮廓 cv::perspectiveTransform(m_pattern.points2d, info.points2d, m_roughHomography); } } return homographyFound; }
如果,进行了所有异常值移除阶段之后,匹配的数量任然相当的大(至少拥有来至模式图像和输入图像相应特征的百分之25),你可以确保模式图像正确的定位。如果如此,我们进行下一个阶段——估计关于相机的模式姿态的3D位置。
将它们整合到一起
为了保存特征检测器,描述子提取器,和匹配算法等实例,我们创建PatternMatcher类,该类将封装所有的这些数据。该类对特征检测,描述子提取算法,特征匹配逻辑,以及控制检测过程的设置具有所有关系。
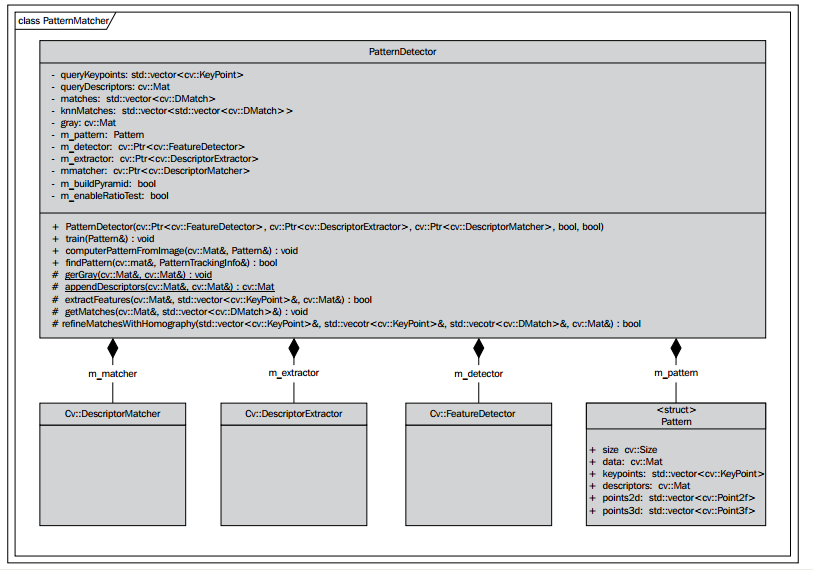
该类提供一个计算所需数据的方法用给定的图像来建立一个模式结构:
void PatternDetector::computePatternFromImage(const cv::Mat& image, Pattern& pattern);
该方法在输入的图像上找到特征点并且使用指定的检测器和特征提取算法来提取描述子,以及为后面的使用,用这些数据填充模式结构。
当Pattern计算完毕,我们可以通过调用train函数用它来训练一个检测器:
void PatternDetector::train(const Pattern& pattern)
这个函数设置参数为我们将要寻找的当前目标模式。同样,它用模式的描述子集训练一个描述子匹配器。调用这个方法之后,我们开始寻找我们的训练图像。模式检测(pattern detection)在最后一个共有函数findPattern中完成。这个方法封装先前描述的整个流程,包括:特征检测,描述子提取,和过滤异常值的匹配。
让我们再次总结一下我们执行步骤的简单列表:
1、转换输入图像到灰度图像
2、使用我们的特征检测算法在查询图像上检测特征
3、从输入的图像中检测到的特征点中抽取描述子
4、与模式描述子进行匹配
5、使用交叉检验或比率检定来移除异常值
6、使用内围层匹配找到单应性变换
7、使用前一步得到的单应性矩阵转换查询图像来提纯单应性
8、找到精确的单应性,以粗糙单应性和提纯单应性的乘积作为结果
9、转换模式角点(pattern corners)到一副图像的坐标系统用来获取模型在输入图像中的位置。
模式姿态估计——Pattern pose estimation
姿态估计(pose estimation)的做法和前一章的标记姿态估计(marker pose estimation)类似。像往常一样,我们需要2D-3D的对应来估计相机的外在参数。我们分配4个三维点来配合位于XY平面(Z轴向上)的单元矩形角点,二维点对应于图像位图的角点。
PatternDetector.cpp
buildPatternFromImage类用输入的图像创建一个Pattern对象,如下:
float step = sqrtf(2.0f); // Store original image in pattern structure//将原始图像存储在pattern结构中 pattern.size = cv::Size(image.cols, image.rows); pattern.frame = image.clone(); getGray(image, pattern.grayImg); // Build 2d and 3d contours (3d contour lie in XY plane since //建立2d和3d轮廓(3d轮廓位于XY平面,因为它是平面的) // it's planar) pattern.points2d.resize(4); pattern.points3d.resize(4); // Image dimensions //图像大小 const float w = image.cols; const float h = image.rows; // Normalized dimensions://归一化大小 const float maxSize = std::max(w,h); const float unitW = w / maxSize; const float unitH = h / maxSize; pattern.points2d[0] = cv::Point2f(0,0); pattern.points2d[1] = cv::Point2f(w,0); pattern.points2d[2] = cv::Point2f(w,h); pattern.points2d[3] = cv::Point2f(0,h); pattern.points3d[0] = cv::Point3f(-unitW, -unitH, 0); pattern.points3d[1] = cv::Point3f( unitW, -unitH, 0); pattern.points3d[2] = cv::Point3f( unitW, unitH, 0); pattern.points3d[3] = cv::Point3f(-unitW, unitH, 0); extractFeatures(pattern.grayImg, pattern.keypoints, pattern.descriptors); }
这个角点参数很有用,因为这个模式坐标系统将直接位于模式位置的中心,且模式位置位于XY平面上,Z轴是直视相机的方向。
获取相机内在参数矩阵——Obtaining the camera-intrinsic matrix
相机的内在参数的计算可以使用来至OpenCV分发包的简单程序即camera_cailbration.exe来计算获得。这个程序将使用一系列的模式图像找到内部透镜参数,例如焦距,主点,畸变系数。让我们讲一下我们拥有的一组来至不同视觉点的8个标定模式图像。

然后,执行标定的命令行语法如下:
imagelist_creator imagelist.yaml *.png calibration -w 9 -h 6 -o camera_intrinsic.yaml imagelist.yaml
第一条命令将使用当前目录下的所有PNG文件作为相机标定工具的输入图像来创建一个YAML格式的图像列表。你可以使用具体的文件名字,例如:img1.png,img2.png和img3.png。然后产生的文件imagelist.yaml将传递给相机标定应用。同样,标定工具可以从常规的网络相机获取图像。
我们指定标定模式和输入输出文件的大小,相机标定的数据将存储在这个输出文件中。
标定完成之后,你将在YAML文件中得到如下的结果:
%YAML:1.0 calibration_time: "06/12/12 11:17:56" image_width: 640 image_height: 480 board_width: 9 board_height: 6 square_size: 1. flags: 0 camera_matrix: !!opencv-matrix rows: 3 cols: 3 dt: d data: [ 5.2658037684199849e+002, 0., 3.1841744018680112e+002, 0., 5.2465577209994706e+002, 2.0296659047014398e+002, 0., 0., 1. ] distortion_coefficients: !!opencv-matrix rows: 5 cols: 1 dt: d data: [ 7.3253671786835686e-002, -8.6143199924308911e-002, -2.0800255026966759e-002, -6.8004894417795971e-004, -1.7750733073535208e-001 ] avg_reprojection_error: 3.6539552933501085e-001
我们主要对camera_matrix感兴趣,这是一个3×3的相机标定矩阵。它有如下形式:
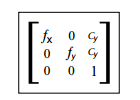
我们主要对四个成分感兴趣:fx,fy,cx和cy。使用这些数据我们可以用下面的代码为标定创建一个相机标定对象实例:
CameraCalibration calibration(526.58037684199849e,524.65577209994706e, 318.41744018680112, 202.96659047014398)
没有正确的相机标定,不可能创建一个看起来自然的增强现实。估计的透视变换将不同于相机固有的变换。这将导致增强的对象看起来或者太近或者太远。下面是一个举例截屏,这里相机标定故意地改变了:

就像你看到的那样,盒子的远景观察不同于整个全景。
为了估计模式的位置(pattern position ),我们使用OpenCV的函数cv::solvePnp来解决PnP问题。你可能熟悉这个函数,因为我们在基于标记的增强现实(marker-based AR)中也使用它。我们需要模式当前图像上模式角点(pattern corners)的坐标,并且先前我们定义了它的相关3D坐标。
(设被观察物体上有n个特征点,且已知他们之间的相对位置。所谓PNP(Perspective-N-Point)问题就是要从透视投影得到的n个象点中,求解摄像时刻物体相对于相机姿态(位置和姿态)。为保证PNP问题解的唯一性,在特征点共面的情形下需要四个点,在非共面情形下需要六个点)
注释:
cv::solvePnP函数可以处理多于4个点。同样,如果你想使用复杂形状模式创建一个增强现实,它是关键的函数。思想是一样的——你仅需要定义一个你的模式的3D结构和找到相应的2D点。当然这里单应性的估计不适用。
我们从训练的模式对象中获取参考的3D点,并且从PatternTrackingInfo结构中获取他们在2维上的相应的投影。相机标定存储在PatternDetector的private领域。
Pattern.cpp
3D空间中模式的位置通过computePose函数来估计,如下:
void PatternTrackingInfo::computePose(const Pattern& pattern, const CameraCalibration& calibration) { cv::Mat camMatrix, distCoeff; cv::Mat(3,3, CV_32F,const_cast<float*>(&calibration.getIntrinsic().data[0])).copyTo(camMatrix); cv::Mat(4,1, CV_32F,const_cast<float*>(&calibration.getDistorsion().data[0])).copyTo(distCoeff); cv::Mat Rvec; cv::Mat_<float> Tvec; cv::Mat raux,taux; cv::solvePnP(pattern.points3d, points2d, camMatrix,distCoeff,raux,taux); raux.convertTo(Rvec,CV_32F); taux.convertTo(Tvec ,CV_32F); cv::Mat_<float> rotMat(3,3); cv::Rodrigues(Rvec, rotMat); // Copy to transformation matrix //复制到转换矩阵 pose3d = Transformation(); for (int col=0; col<3; col++) { for (int row=0; row<3; row++) { pose3d.r().mat[row][col] = rotMat(row,col); // Copy rotation component //复制旋转成分 } pose3d.t().data[col] = Tvec(col); // Copy translation component //复制平移成分 } // Since solvePnP finds camera location, w.r.t to marker pose, // to get marker pose w.r.t to the camera we invert it. // pose3d = pose3d.getInverted(); }
应用基础结构——Application infrastructure
到目前位置,我们已经学习了如何检测一个模式和估计它关于相机的3D位置。现在,是时候向你展示将这些算法应用到一个实际的应用中。因此,这一部分的目的是展示如何使用OpenCV从网络相机捕捉一个视频并且为3D渲染创建可视化的环境。
因为我们的目的是展示如何使用少量标记增强现实(marker-less AR)的关键特征,我们将创建一个简单的命令行应用程序,该应用将能够检测一个视频帧中或者静止图像中的任意模式图像。
为了保存所有图像处理逻辑和中间数据,我们引入ARPipeline类。它是容纳增强现实中所有需要的子成分和对输入帧中执行所有处理过程的根对象。下面是ARPipline和它子成分的一个UML图表:
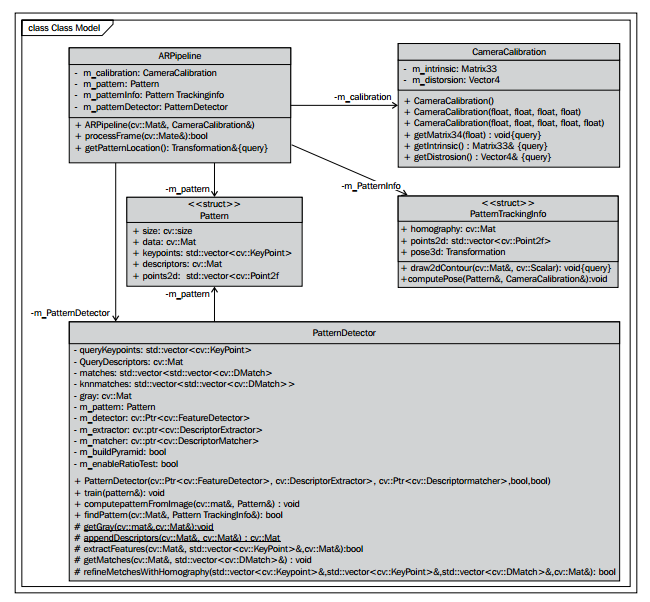
有下面组成:
1、相机标定对象
2、模式检测器对象的一个实例
3、一个训练过的模式对象
4、模式跟踪的中间数据
ARPipeline.hpp
下面的代码包含了ARPipline类的声明:
class ARPipeline { public: ARPipeline(const cv::Mat& patternImage, const CameraCalibration& calibration); bool processFrame(const cv::Mat& inputFrame); const Transformation& getPatternLocation() const; private: CameraCalibration m_calibration; Pattern m_pattern; PatternTrackingInfo m_patternInfo; PatternDetector m_patternDetector; };
在ARPipline的构造函数中,一个模式对象被初始化并且标定数据存储在private领域。processFrame函数实现模式检测和人的姿态估计过程(the person's pose-estimation routine)。返回值表示模式检测成功。你可以通过调用getPatternLocation函数获取计算得到的模式姿态(pattern pose)。
ARPipeline.cpp
下面的代码包含了ARPipline类的实现:
ARPipeline::ARPipeline(const cv::Mat& patternImage, const CameraCalibration& calibration) : m_calibration(calibration) { m_patternDetector.buildPatternFromImage (patternImage, m_pattern); m_patternDetector.train(m_pattern); } bool ARPipeline::processFrame(const cv::Mat& inputFrame) { bool patternFound = m_patternDetector.findPattern(inputFrame, m_patternInfo); if (patternFound) { m_patternInfo.computePose(m_pattern, m_calibration); } return patternFound; } const Transformation& ARPipeline::getPatternLocation() const { return m_patternInfo.pose3d; }
在OpenCV中支持3D可视化——Enabling support for 3D visualization in OpenCV
像先前一章,我们将使用OpenGL来渲染我们的3D工作。但是不像iOS环境,那里我必须遵循应用体系结构的需求,现在我们更自由了。在Windows和Mac系统上,你可以从许多3D引擎中选择。在这一章,我们将学习如何使用OpenCV创建交叉平台3D的可视化。从2.4.2版本开始,OpenCV拥有OpenGL支持的可视化窗口。这意味着,在OpenCV中,你可以容易的渲染任何3D环境。
为了在OpenCV中建立一个OpenGL窗口,你需要做的第一件事是编译OpenCV使其支持OpenGL。否则,当你试图使用OpenCV中与OpenGL相关的函数时,将抛出异常。你应当使用ENABLE_OPENGL=YES标志编译OpenCV库。
注释:
自当前版本(OpenCV 2.4.2)起,OpenGL的支持默认是关闭的,这我们不能保证。或许在未来的版本中默认支持OpenGL。如果那样,我们没有必要手动地编译OpenCV了。
为了在OpenCV中建立一个OpenGL窗口,执行下面的操作:
1、从GitHub(https://github.com/Itseez/opencv)中克隆OpenCV仓库(repository)。你将需要命令行git工具或者安装在你电脑上的GitHub应用程序来执行这一步。
2、配置OpenCV并且为你的编译环境产生一个工作空间。你将需要一个CMake应用来完成这一步。CMake可以免费的从下面的网址获得:http://www.cmake.org/cmake/resources/software.html
为了配置OpenCV,你可以使用如下的命令行CMake指令(从你想产生工程位置的目录开始):
cmake -D ENABLE_OPENGL=YES <path to the OpenCV source directory>
或者你喜欢GUI风格,使用更加友好的工程配置——CMake-GUI:
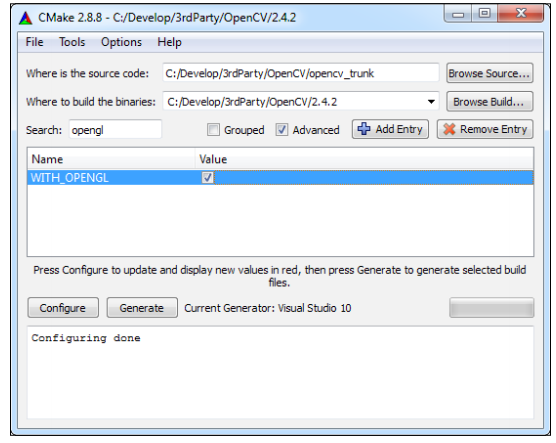
为选择的集成开发环境产生OpenCV工作空间之后,打开工程并且执行INSTALL TARGET来编译库并且INSTALL它。当这个过程完成后,你可以使用你刚刚编译的新的OpenCV库配置样本工程。
使用OpenCV创建OpenGL窗口——Creating OpenGL windows using OpenCV
既然我们的OpenCV库支持了OpenGL,那么是时候创建我们第一个OpenGL窗口了。OpenGL窗口的初始化通过创建带有一个OpenGL标志的命名窗口开始:
cv::namedWindow(ARWindowName, cv::WINDOW_OPENGL);
ARWindowName是我们窗口名字的字符串常量。这里我们使用“Markerless AR”。这个调用将使用指定的名字创建一个窗口。cv::WINDOW_OPENGL标志指示我们将在这个窗口中使用OpenGL。然后我们设置期望窗口的大小:
cv::resizeWindow(ARWindowName, 640, 480);
我们为这个窗口建立画图环境:
cv::setOpenGlContext(ARWindowName);
现在我们创建已准备好使用了。为了在上面画一些东西,我们应当使用下面的方法注册一个回调函数:
cv::setOpenGlDrawCallback(ARWindowName, drawAR, NULL);
在重画窗口时,这个回调将被调用。第一个参数设置窗口的名字,第二个参数是一个回调函数,并且第三个是可选参数,将用来传递给回调函数。
drawAR函数应当有下面的形式:
void drawAR(void* param) { // Draw something using OpenGL here }
为了通知系统,你想重画你的窗口,使用cv::updateWindow函数:
cv::updateWindow(ARWindowName);
使用OpenCV进行视频捕捉——Video capture using OpenCV
OpenCV允许你从几乎每一个网络相机中获取视频帧并且和从视频文件中获取一样的简单。为了从网络相机或者视频文件捕捉视频,我们可以像第一章Cartoonifier and Skin Changer for Android 的Accessing the webcam部分展示的那样,使用cv::VideoCapture类。
渲染增强的现实——Rendering augmented reality
我们引入ARDrawindContext结构体来容纳可视化可能需要的所有数据:
1、从相机获取的最新图像
2、相机标定矩阵
3、3D空间中的模式姿态(如何需要呈现)
4、关于OpenGL的内部数据(纹理ID等等)
ARDraingContext.hpp
下面的代码包含了ARDrawingContext类的声明:
class ARDrawingContext { public: ARDrawingContext(const CameraCalibration& c); bool patternPresent; Transformation patternPose; //! Request the redraw of the OpenGl window void draw(); //! Set the new frame for the background void updateBackground(const cv::Mat& frame); private: //! Draws the background with video void drawCameraFrame (); //! Draws the AR void drawAugmentedScene(); //! Builds the right projection matrix //! from the camera calibration for AR void buildProjectionMatrix(const Matrix33& calibration, int w, int h, Matrix44& result); //! Draws the coordinate axis void drawCoordinateAxis(); //! Draw the cube model void drawCubeModel(); private: bool m_textureInitialized; unsigned int m_backgroundTextureId; CameraCalibration m_calibration; cv::Mat m_backgroundImage; };
ARDrawingContext.cpp
OpenGL窗口的初始化在ARDrawingContext类的构造函数内完成,如下:
ARDrawingContext::ARDrawingContext(std::string windowName, cv::Size frameSize, const CameraCalibration& c) : m_isTextureInitialized(false) , m_calibration(c) , m_windowName(windowName) { // Create window with OpenGL support cv::namedWindow(windowName, cv::WINDOW_OPENGL); // Resize it exactly to video size cv::resizeWindow(windowName, frameSize.width, frameSize.height); // Initialize OpenGL draw callback: cv::setOpenGlContext(windowName); cv::setOpenGlDrawCallback(windowName, ARDrawingContextDrawCallback, this); }
因为现在我们有一个单独的类用来存储可视化状态,我们修改cv::setOpenGLDrawCallback调用并且传递ARDraingContext的一个实例作为参数:
修改后的回调函数如下:
void ARDrawingContextDrawCallback(void* param) { ARDrawingContext * ctx = static_cast<ARDrawingContext*>(param); if (ctx) { ctx->draw(); } }
ARDranwingContext负责渲染增强的现实。要渲染的图像帧通过使用正交投影画一个背景开始。然后我们使用正确的透视投影和模型转换来渲染一个3D模型。下面的代码包含了draw函数的最终的版本:
void ARDrawingContext::draw() { // Clear entire screen glClear(GL_DEPTH_BUFFER_BIT | GL_COLOR_BUFFER_BIT); // Render background drawCameraFrame(); // Draw AR drawAugmentedScene(); }
清除屏幕和深度缓存之后,我们检查用来呈现一个视频的纹理是否被初始化。如果初始化了,我们进行画一个背景,否则我们通过调用glGenTextures函数创建一个新的2D纹理。
为了画出一个背景,我们建立一个正交投影并且画出一个覆盖屏幕所有视点的立方体矩形。这个矩形限制在纹理单元内。这个纹理用一个m_backgroundImage对象填充。它的内容预先上传到OpenGL的内存。这个函数和前一章的函数相同,因为这里我们忽略它的代码。
画出从相机获得的图像之后,我们切换到画一个增强现实。设置正确的匹配我们相机标定的透视投影是必须的。
下面的代码展示了如何建立正确的来至相机标定的OpenGL投影矩阵并且渲染场景:
void ARDrawingContext::drawAugmentedScene() { // Init augmentation projection Matrix44 projectionMatrix; int w = m_backgroundImage.cols; int h = m_backgroundImage.rows; buildProjectionMatrix(m_calibration, w, h, projectionMatrix); glMatrixMode(GL_PROJECTION); glLoadMatrixf(projectionMatrix.data); glMatrixMode(GL_MODELVIEW); glLoadIdentity(); if (isPatternPresent) { // Set the pattern transformation Matrix44 glMatrix = patternPose.getMat44(); glLoadMatrixf(reinterpret_cast<const GLfloat*>(&glMatrix.data[0])); // Render model drawCoordinateAxis(); drawCubeModel(); } }
buildProjectionMatrix函数来至于先前的一章,因为它是一样的。应用透视投影之后,我们设置GL_MODEL_VIEW矩阵用来模式转换。为了证明我们的姿态估计正常工作,我们在模式位置画一个单位坐标系统。
所有的事情几乎做完了。我们创建一个模式检测算法并且我们估计在3D空间中找到的模式的姿态,用来渲染增强现实的一个可视化的系统。让我们看一下下面的UML程序表,它用来阐述在我们的应用中帧处理的过程:
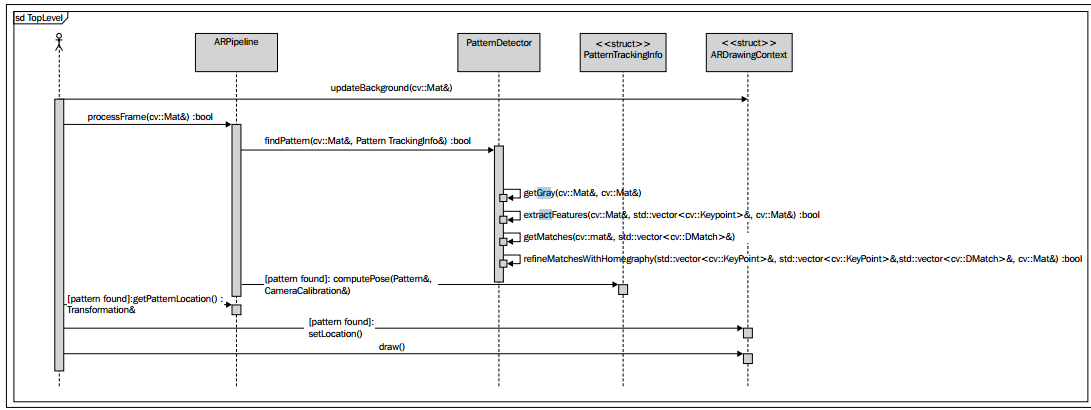
示范——Demonstration
我们的师范工程支持静态图像,录制视频,以及来至网络相机的实时取景的处理。我们创建两个函数帮我们完成这个功能。
main.cpp
函数processVideo操作视频的处理并且函数processSingleImage用来处理单个图像,如下:
void processVideo(const cv::Mat& patternImage, CameraCalibration& calibration, cv::VideoCapture& capture); void processSingleImage(const cv::Mat& patternImage, CameraCalibration& calibration, const cv::Mat& image);
从函数的名字,我们很清晰地知道第一个函数处理视频来源,第二个函数处理单个图像(这个函数用作调试很有用)。这两个函数有一个非常相同的图像处理过程,模式检测,场景渲染和用户交互。
processFrame函数包装这些步骤,如下:
/** * Performs full detection routine on camera frame .* and draws the scene using drawing context. * In addition, this function draw overlay with debug information .* on top of the AR window. Returns true .* if processing loop should be stopped; otherwise - false. */ bool processFrame(const cv::Mat& cameraFrame, ARPipeline& pipeline, ARDrawingContext& drawingCtx) { // Clone image used for background (we will // draw overlay on it) cv::Mat img = cameraFrame.clone(); // Draw information: if (pipeline.m_patternDetector.enableHomographyRefinement) cv::putText(img, "Pose refinement: On ('h' to switch off)", cv::Point(10,15), CV_FONT_HERSHEY_PLAIN, 1, CV_RGB(0,200,0)); else cv::putText(img, "Pose refinement: Off ('h' to switch on)", cv::Point(10,15), CV_FONT_HERSHEY_PLAIN, 1, CV_RGB(0,200,0)); cv::putText(img, "RANSAC threshold: " + ToString(pipeline.m_patternDetector. homographyReprojectionThreshold) + "( Use'-'/'+' to adjust)", cv::Point(10, 30), CV_FONT_HERSHEY_PLAIN, 1, CV_RGB(0,200,0)); // Set a new camera frame: drawingCtx.updateBackground(img); // Find a pattern and update its detection status: drawingCtx.isPatternPresent = pipeline.processFrame(cameraFrame); // Update a pattern pose: drawingCtx.patternPose = pipeline.getPatternLocation(); // Request redraw of the window: drawingCtx.updateWindow(); // Read the keyboard input: int keyCode = cv::waitKey(5); bool shouldQuit = false; if (keyCode == '+' || keyCode == '=') { pipeline.m_patternDetector.homographyReprojectionThreshold += 0.2f; pipeline.m_patternDetector.homographyReprojectionThreshold = std::min(10.0f, pipeline.m_patternDetector. homographyReprojectionThreshold); } else if (keyCode == '-') { pipeline.m_patternDetector. homographyReprojectionThreshold -= 0.2f; pipeline.m_patternDetector.homographyReprojectionThreshold = std::max(0.0f, pipeline.m_patternDetector. homographyReprojectionThreshold); } else if (keyCode == 'h') { pipeline.m_patternDetector.enableHomographyRefinement = !pipeline.m_patternDetector.enableHomographyRefinement; } else if (keyCode == 27 || keyCode == 'q') { shouldQuit = true; } return shouldQuit; }
ARPipline和ARDrawingContext的初始化化在processSingleImage或者processVideo函数中完成,如下:
void processSingleImage(const cv::Mat& patternImage, CameraCalibration& calibration, const cv::Mat& image) { cv::Size frameSize(image.cols, image.rows); ARPipeline pipeline(patternImage, calibration); ARDrawingContext drawingCtx("Markerless AR", frameSize, calibration); bool shouldQuit = false; do { shouldQuit = processFrame(image, pipeline, drawingCtx); } while (!shouldQuit); }
我们使用模式图像和标定参数创建ARPipline。然后我们再次使用标定初始化ARDrawingContext。这些步骤之后,OpenGL的窗口被创建。然后我们上传查询图像到画图环境中并且调用ARPipline.processFrame函数找到一个模式。如果姿态模式已经找到,我们复制它的位置到这个画图环境来做进一步的视频帧渲染。如果模式没有检测到,我们仅渲染没有任何现实增强的相机视频帧。
你用下面的一种方式运行示例工程:
1、运行在单个图像上调用:
markerless_ar_demo pattern.png test_image.png
2、运行录制视频的调用:
markerless_ar_demo pattern.png test_video.avi
3、运行实时相机的调用:
markerless_ar_demo pattern.png
增强单个图像的效果在下面的截图中展示:

总结——summary
在这一章,你已经学习了特征描述子和如何使用他们来定义一个尺度和旋转不变的模式描述。这个描述可以用来在其他图像中找到相似的条目。许多流行的特征描述子的优点和弱点也解释了。在这一章的第二半部分,我们学习了如何一起使用OpenGL和OpenCV来渲染增强的现实。
参考——References
• Distinctive Image Features from Scale-Invariant Keypoints(http://www.cs.ubc.
ca/~lowe/papers/ijcv04.pdf)
• SURF: Speeded Up Robust Features(http://www.vision.ee.ethz.ch/~surf/
eccv06.pdf)
• Model-Based Object Pose in 25 Lines of Code, Dementhon and L.S Davis,
International Journal of Computer Vision, edition 15, pp. 123-141, 1995
• Linear N-Point Camera Pose Determination, L.Quan, IEEE Trans. on Pattern
Analysis and Machine Intelligence, vol. 21, edition. 7, July 1999
• Random Sample Consensus: A Paradigm for Model Fitting with Applications to
Image Analysis and Automated Cartography, M. Fischer and R. Bolles, Graphics
and Image Processing, vol. 24, edition. 6, pp. 381-395, June 1981
• Multiple View Geometry in Computer Vision, R. Hartley and A.Zisserman,
Cambridge University Press(http://www.umiacs.umd.edu/~ramani/
cmsc828d/lecture9.pdf)
• Camera Pose Revisited – New Linear Algorithms, M. Ameller, B.Triggs, L.Quan
(http://hal.inria.fr/docs/00/54/83/06/PDF/Ameller-eccv00.pdf)
• Closed-form solution of absolute orientation using unit quaternions, Berthold K. P.
Horn, Journal of the Optical Society A, vol. 4, 629–642
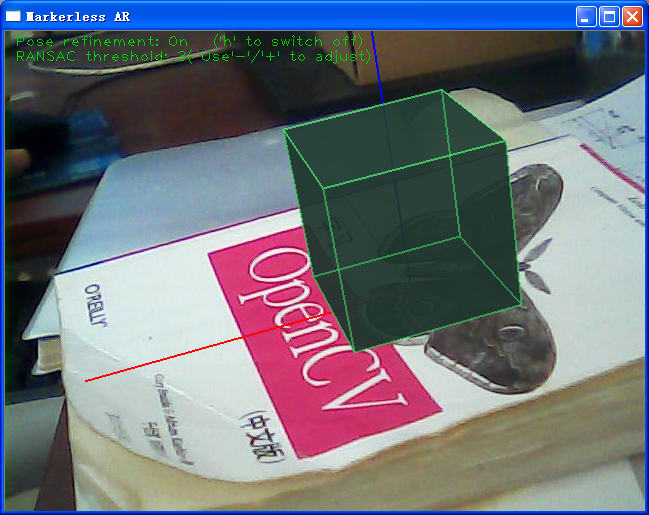
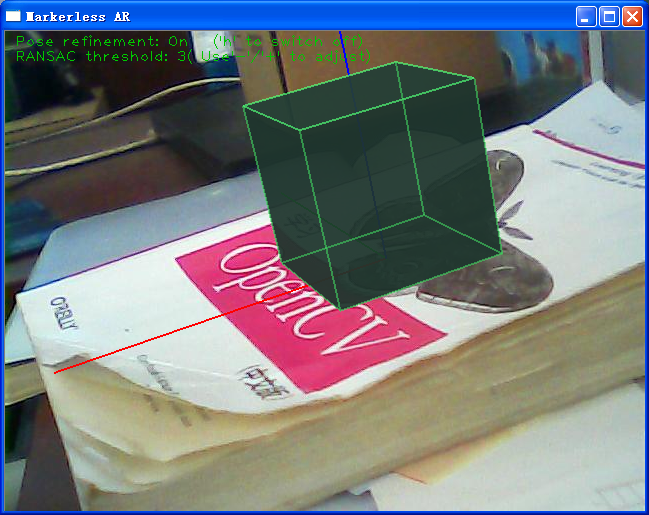
附测试图:
我用的相机参数为:1031.67 1034.56 307.542 266.352


转自:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号