python 基础
1)CPU 、 内存 、硬盘 、操作系统
cpu: 计算机的运算和计算中心,相当于人类大脑
内存: 暂时存储数据,临时加载数据应用程序 4G,8G,16G,32G
硬盘:磁盘,长期存储数据,D盘,E盘
操作系统:一个软件,连接计算机的硬件与所有软件之间的一个软件
2) 编译型语言和解释型语言
编译型:
将代码一次性全部编译成二进制,然后再执行
优点:执行效率高
缺点:开发效率低,不能跨平台
解释型:
逐行解释成二进制,逐行运行
优点:开发效率高
缺点:执行效率低
3)python的种类
官方推荐 Cpython 将python代码转化为C代码
Jpython 将python代码转化为java代码
ironpython 将python代码转化为.net代码
pypy 还在测试中 未来的趋势 执行效率高且开发效率高
4)安装python编辑器
windows 版本 3.6.8 Install自动安装版本


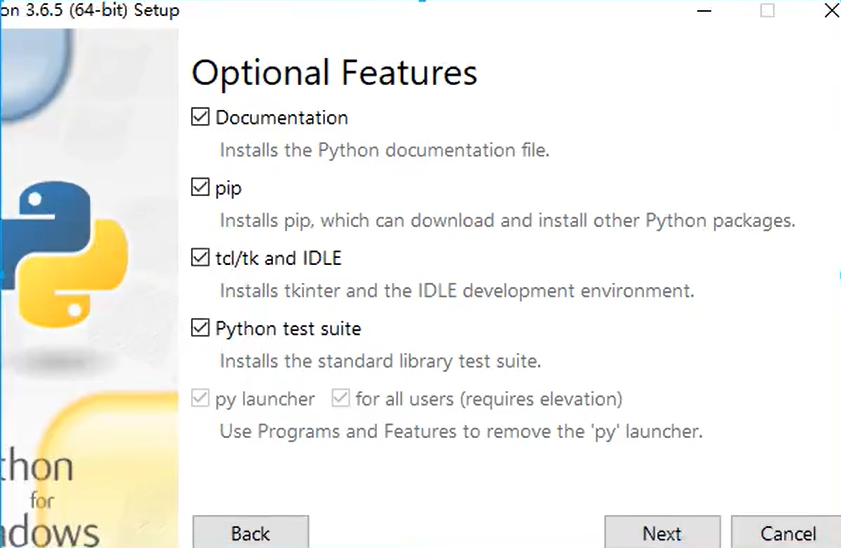

验证是否安装成功
命令行 输入 python
### 如果报错说明,没有勾选自动配置环境变量(手动进行配置即可)
找到下方的path 双击进行添加(建议安装的路径一定要短,添加python的根目录即可)
5) 运行第一行python代码
print('hello python') // 文件名为python1.py
命令行 输入 python c:\python1.py
6) 常量
NAME = "李白" // 全部大写表示常量
7) z=注释
单行注释: #
多行注释: '''被注释内容''' """被注释内容"""
8) 字符串 ’‘’ ''' 三引号
用于 控制台输出字符串换行
msg = '''
君不见黄河之水天上来,
奔流到海不复回,
君不见高堂明镜悲白发,
朝如青丝暮成雪
'''
9) 字符串可以相乘和相加
msg = '剑气'
print(msg * 8) // 输出8个剑气
#### 相加只可以str + str 不可以加其他类型
10) input交互
逐行执行代码,不输入账号,程序将一直停留,输入之后的内容会赋值给变量
# input交互
username = input('请输入账号')
password = input('请输入密码')
print(username,type(username))
print(password,type(password))
11)if语句
单语句:if + 空格 + 条件判断 + 英文冒号 + 回车 + 四个空格
# if语句
print(888)
if 3 < 2 :
print(666)
print(688)
12) if else 语句
# if else 语句
age = input('请输入年龄')
if int(age) > 18 :
print('恭喜成年了')
else:
print('小屁孩一个')
13) if elif else多分支语句
# 多分支if elif
num = int(input('输入点数'))
if num == 1 :
print('晚上请你吃饭')
elif num == 2 :
print('一起溜达')
elif num == 3 :
print('请你大保健')
else:
print('太笨了.....')
14) if 嵌套
首先判断code是否正确,再判断用户名和密码
# if 嵌套
username = input('请输入用户名')
password = input('请输入密码')
code = 'qwer'
your_code = input('请输入验证码')
if your_code == code :
if username == '娃娃鱼' and password == '123456' :
print('登录成功')
else:
print('账号或者密码错误')
else:
print('验证码输入错误')
15) 博客园使用
- 点击管理/点击选项/默认编辑器选择markdown
- 发布文章:选择文章 然后新建文章,将markdown中的内容,ctrl + A ctrl + c 复制即可
16)pycharm(ctrl + 鼠标滚轮 调整页面字体大小)

17)while 循环
-
while循环
-
why:地球自转,大气循环,单曲循环,列表循环
-
whta: while 无限循环。
-
how:
-
基本结构
while 条件: 循环体 -
初识循环
//过程分析 首先进行条件判断 满足条件进入循环体 执行完成后再次进行条件判断 往复交替进行
while True : print("其实很爱你") print("神话") print("差不多先生") print("晚风吹") print("六月的雨") -
循环终止条件
- 改变条件(改变条件,不是终止语句break,还是会执行完一遍后再进行条件判断)
flag = True while flag : print("其实很爱你") print("神话") print("差不多先生") flag = False print("晚风吹") print("六月的雨")- break(循环中遇见break,强行终止退出循环)
flag = True while flag : print("其实很爱你") print("神话") print("差不多先生") break print("晚风吹") print("六月的雨")- continue(continue相当于执行到了循环体底部,即使下面有代码也不会执行,接着进行条配件判断)
flag = True while flag: print("其实很爱你") print("神话") print("差不多先生") continue print("晚风吹") print("六月的雨") -
while else 语句(不满足条件时执行,如果执行break语句,不会执行else语句)
num = 1 while num < 5: print(num) num = num + 1 else: print(666)
-
-
18)格式化输出(d digut i int 都表示数字类型)
- 用处:当字符串中静态的文字,需要变成动态的变量时使用
- 语法说明(必须一一对应)
- %代表占位符,s表示字符串类型数据,结尾处再来个 % ( ) 结尾,括号中依次输入每个位置需要替换的变量即可
name = input('请输入姓名')
age = input('请输入年龄')
job = input('请输入工作')
like = input('请输入爱好')
msg = '''------------ info of %s -----------
Name : %s
Age : %s
job : %s
Hobbie: %s
------------- end -----------------''' % (name,name,age,job,like)
print(msg)
- 输出效果
------------ info of 娃娃鱼 -----------
Name : 娃娃鱼
Age : 28
job : 程序员
Hobbie: 听音乐
------------- end -----------------
-
格式化输出的坑(在格式化输出下,如果只有一个%会报错,如果需要输出%,需要输入两个%%)
msg = '我叫%s,今年%s,学习进度1%%' % ("娃娃鱼",18) print(msg)
19) 逻辑运算符
-
not取反运算符
flag = False if not flag: print(666) -
or两边是数字运算
print(0 or -1) // 寻真 -1 遇到真停止运算 -
and两边是数字运算
print(-1 and 0) // 寻假 0 如果没有假 取and右边的值
20) ASCII码表(8位表示一个字符,字节)
ASCII码:只包含 英文字母,数字,特殊字符
0000 0001 : a
0000 0101 : ;
8bit = 1 byte
'hello123' : 8byte
21) gbk 编码
包含: 英文字母,数字,特殊字符和中文
一个英文字母: 0000 0001 : a // 一个英文字母占8位(比特) == 1个byte(字节)
一个中文 0000 0010 0010 0011 : 中 // 一个中文占16位(比特) == 2个byte(字节)
22)unicode万国码
全部使用 4 个字节 表示1个字符
00000000 00000000 00000000 01010101 : A 32bit == 4byte
00000000 00000000 00000000 01010100 : 中 32bit == 4byte
23) utf-8(对unicode优化)
最少用8bit 1个字节表示一个字符
0000 0011 : a 1字节
0000 0011 0000 0011 欧洲2个字节
0000 0011 0000 0011 0000 0011 中 3个字节
24)编码练习
'中国12he' GBK 占用 8个字节
'中国12he' UTF-8 占用 10个字节
25)pycharms设置锁定源码方法总览
-
第一步,点击设置
![]()
-
第二步,圆圈


- 设置效果

26) int 方法
- int.bit_length()
// 查询二进制位数的长度
i = 4
print(i.bit_length()) // 3 根据 8421法则
i = 10
print(i.bit_length()) // 4 根据 8421法则
27)str只有为空才是false
msg = input('输入内容')
if msg:
print('有内容')
else:
print('无内容')
28) str相关操作方法
- 切片,步长(不影响原字符串)
s = 'python全站自学第二天'
# 按索引取值 print(s[0]) p
# 按照切片: print(s[0:6]) python //左闭右开
# 按照切片步长 print(s[0:6:2]) pto //没隔两步取一个
# 反向按照切片步长 print(s[-1:-6:-2]) 天第自
# 倒叙全部取出 print(s[-1: :-1]) 天二第学自站全nohtyp :不写代表对应的头部或尾部
# 正序全部取出 print(s[:]) python全站自学第二天 :不写代表对应的头部或尾部
- str.upper( )、 str.lower( )大小写转换(不影响原字符串)
msg = 'qeErt'
# print(msg.upper()) 大写转换 QEERT
# print(msg.lower()) 小写转换 qeert
username = input('请输入用户名')
password = input('请输入密码')
code = 'QaBa'
your_code = input('请输入验证码,不区分大小写')
if your_code.upper() == code.upper():
if username == '娃娃鱼' and password == '123456':
print('登录成功')
else:
print('用户名或密码错误')
else:
print('验证码输入错误')
- str.startswith( )、str.endswith( )是否以什么开头或结尾
msg = 'lkjlasd'
print(msg.startswith('l')) // true
print(msg.startswith('lk')) // true
print(msg.startswith('lkjlasd')) // true
print(msg.endswith('d')) // true
print(msg.endswith('sd')) // true
- str.replace( )替换 只能替换字符串
msg = 'alex说他很帅,其实alex并不帅,没有余凱帅'
msg2 = msg.replace('alex','杨鹏飞') // 默认不写次数 全部替换
msg3 = msg.replace('alex','杨鹏飞',1) // 只替换第一次出现的地方
print(msg2)
print(msg3)
- 制表位(\t)与换行符(\n)
msg = '大鱼\t小于\t无于\t老于\t沙盘于'
print(msg)
大鱼 小于 无于 老于 沙盘于
- str.strip( ) 删除指定元素(从字符串的两端开始查找,如果左右两边第一个元素,不包含指定删除元素,将不会再向里面查找,书写顺序没有要求)
msg = '大鱼小于无于老于沙盘于'
print(msg.strip('大于')) 或者'大于'都可以
msg = '大鱼小于无于老于沙盘于'
print(msg.strip('鱼盘'))
- str.split( )字符串转成数组格式(列表)==>以什么字符位基准转换为数组
# msg = '大鱼/小鱼/海鱼'
# print(msg.split('/'))
# msg = '大鱼:小鱼:海鱼'
# print(msg.split(':'))
# msg = '大鱼 小鱼 海鱼'
# print(msg.split())
// 三者输入结果都一样 ['大鱼', '小鱼', '海鱼']
// 了解
msg = ':大鱼:小鱼:海鱼'
print(msg.split(':')) // ['', '大鱼', '小鱼', '海鱼']
// 指定具体分割前两个
print(msg.split(':',2)) // ['', '大鱼', '小鱼:海鱼']
- str.join( ) 将字符串中的每个元素以特定符号拼接,只能将(全是字符串的数组)转换成字符串拼接
msg = '大鱼小鱼海鱼'
print('+'.join(msg)) // 大+鱼+小+鱼+海+鱼
arr = ['大鱼','小鱼','海鱼'] // 数组中必须全部是字符串,才可以转换
print(','.join(arr)) // 大鱼,小鱼,海鱼
- str.format( )格式化输出
// 第一种 占位
msg = '我叫{},今年{}岁,爱好{}'.format('余凱','28','学习')
print(msg)
// 第二种 索引
msg2 = '我叫{0},今年{1}岁,其实我还叫{0}'.format('余凱','28')
print(msg2)
// 第三种 键值对
msg3 = '我叫{name},今年{age}岁,其实我还叫{name}'.format(age=28,name='余凱')
print(msg3)
- is系列(用于购物车)
# name = '24651yukai'
# print(name.isalnum()) // 字母或者数字组成 true
# name = '24651yukai'
# print(name.isalpha()) // 字符串只由字母组成 false
# name = '100'
# print(name.isdecimal()) // 字符串由十进制组成 false 判断正整数
- in notin 判断成员中是否包含字符(整体字符)
name = '24651yukai'
print('24' in name) // true
name2 = '24651yukai'
print('42' in name2) // false
name3 = '24651yukai'
print('y' in name3) // true
name4 = '24651yukai'
print('y1' not in name4) // true
-
str.find( ) str.index( )
查询对应索引,find找不到返回-1,index找不到直接报错
msg = 'brray'
print(msg.find('r')) // 1
==================================
msg = 'brray'
print(msg.index('r')) // 1
- str.title( )每个单词的首字母大写
msg = 'brray habby'
print(msg.title()) // Brray Habby
- str.capitalize( ) 首字母大写,其余变小写
msg = 'brray habby'
print(msg.capitalize()) // Brray habby
- str.swapcase( ) 大小写翻转
msg = 'Bbrray Habby'
print(msg.swapcase()) // bBRRAY hABBY
- str.center( )居中 ==》 填充可以默认不写
msg = 'Bbrray'
print(msg.center(20,'*')) //*******Bbrray*******
29) 内置函数 len( ) 获取长度
name = ‘娃娃鱼’
len(name) // 3
30) for循环
name = '24651yukai'
for i in name:
print(i) // 打印每一项
31) 列表创建
- li = [1,2,3,'a',[1,2,3]]
- li = list( ) // 打印li 为空列表
- li = list(asd) // 打印Li 为[a,s,d] 自动将每个元素放进列表中 (迭代追加)
32)列表的增
- list.append( ) 尾部追加
li = ['吴迪','冷血','铁手']
li.append(‘追命’)
print(li) // ['吴迪','冷血','铁手','追命']
- list.insert( ) 任意位置插入
li = ['吴迪','冷血','铁手']
li.insert(2,'李白')
print(li) // ['吴迪', '冷血', '李白', '铁手']
- list.extend( ) 迭代追加 追加的是每一个元素
li = ['吴迪','冷血','铁手']
li.extend('asd')
print(li) // 字符串中由三个元素构成,所以追加3个
['吴迪', '冷血', '铁手', 'a', 's', 'd']
li = ['吴迪','冷血','铁手']
li.extend([132])
print(li) // 列表中只有一个元素,所以只追加一个 ['吴迪', '冷血', '铁手', 132]
33)列表的删除
- list.pop( )
li = ['吴迪','冷血','铁手']
print(li.pop(-1)) // 按照索引删除(有返回值) 铁手
print(li) // ['吴迪','冷血']
---------------------------------
li = ['吴迪','冷血','铁手','缀名']
print(li.pop()) // **默认删除最后一个
print(li) // ['吴迪', '冷血', '铁手']
- del
li = ['吴迪','冷血','铁手','缀名']
del li[-1] // 按照索引删除
print(li) // ['吴迪', '冷血', '铁手']
---------------------------------------
li = ['吴迪','冷血','铁手','缀名']
del li[::2] // 按照切片(步长)删除
print(li) // ['冷血', '缀名']
- list.remove( )
// 指定元素删除,如果有重名元素,默认删除从左数第一个
li = ['吴迪','冷血','铁手','缀名']
li.remove('缀名')
print(li)
- list.clear( )
// 清空列表
li = ['吴迪','冷血','铁手','缀名']
li.clear()
print(li)
34)列表的修改
- 按照索引修改
li = ['吴迪','冷血','铁手','缀名']
li[0] = '杨颖'
print(li) // ['杨颖', '冷血', '铁手', '缀名']
- 按照切片修改
li = ['吴迪','冷血','铁手','缀名']
li[2:] = 'qwertyuio'
print(li) // ['吴迪', '冷血', 'q', 'w', 'e', 'r', 't', 'y', 'u', 'i', 'o']
- 按照切片(步长)
// 必须一一对应
li = ['吴迪','冷血','铁手','缀名']
li[::2] = ['娃娃鱼','赵芹']
print(li) // ['娃娃鱼', '冷血', '赵芹', '缀名']
-------------------------------------
li = ['吴迪','冷血','铁手','缀名']
li[::2] = 'qp'
print(li) // ['q', '冷血', 'p', '缀名']
35 ) 列表的查
li = ['吴迪','冷血','铁手','缀名']
for i in li:
print(i)
36 ) 元组(只读列表,存储大量的数据,可以索引,切片(步长))
元组不可以增删改,但是元组中的列表可以正常操作
zu = (100,'太白',True,[1,2,3])
for i in zu:
print(i)
100
太白
True
[1, 2, 3]
- 元组的拆包
// 必须一一对应 (列表也可以拆包,但是没有什么意义,没人列表拆包)
a,b = (100,'haha')
print(a,b) // 100 haha
- 元组细节
// 元组中如果只有一个元素,并且没有逗号,那么它不是元组数据类型,是对应元素类型的数据类型
// 有逗号就是元组
zu = (100)
print(type(zu)) // <class 'int'>
- tuple.count( ) 元素出现次数
zu = ('sdfsdfsdf')
print(zu.count('s')) // 3
- tuple.index( )元素第一次出现的索引,找不到会报错
zu = ('sdfsdfsdf')
print(zu.index('s')) // 0
37)range
类似列表的数字型列表(左闭右开)
r = range(10) #[0,1,2,3,4,5,6,7,8,9]
for i in r:
print(i)
--------------------------------------
a = range(100,200) // (左闭右开)
for i in a:
print(i)
--------------------------------------
for i in range(100,1,-1): // 可以步长
print(i)
38)列表方法的补充
- list.count( ) 查询元素出现次数
li = [1,2,3,4,5,2]
print(li.count(2)) // 2
- list.index( ) 查询元素第一次出现的索引
li = [1,2,3,4,5,2]
print(li.index(2)) // 1
- 列表的相加(合并在一起)
li = [11,22,33]
l2 = [4,5,6]
print(li+l2) // [11, 22, 33, 4, 5, 6]
- 列表与数字相乘(复制N份)
l2 = [4,5,6]
print(l2 * 3) // [4, 5, 6, 4, 5, 6, 4, 5, 6]
- list.sort( )排序
// 从小到大排序
l2 = [4,5,6,9,3,7,8]
l2.sort()
print(l2) // [3, 4, 5, 6, 7, 8, 9]
// 从大到小
l2 = [4,5,6,9,3,7,8]
l2.sort(reverse=True)
print(l2) // [9, 8, 7, 6, 5, 4, 3]
- list.reverse( ) 列表反转
l2 = [4,5,6,9,3,7,8]
l2.reverse()
print(l2) // [8, 7, 3, 9, 6, 5, 4]
39) 列表的坑(不要直接改变列表的大小)
40)数据类型的分类
- 可变(不可哈希)的数据类型: list dict(字典) set(集合) ==> 操作方法的时候可以改变原对象
- 不可变(可哈希)的数据类型: str bool int tuple(元组) ==> 操作方法的时候不可以改变原对象
41)字典
-
{}括起来,以键值对形式存储的容器型数据类型:
dic = { "name":"娃娃鱼","age":18 } -
键必须是不可变的数据类型: int str (bool,tuple元组几乎不用)
-
值可以是任意数据类型。
-
字典3.5x版本之前(包括3.5)是无序的
-
字典3.6x会按照初次建立字典的顺序排列,学术上不认为是有序的
-
字典3.7x以后都是有序的
-
字典的查询速度非常快
-
字典的缺点: 以空间换时间
-
字典的创建方式
-
dic = dict((('one',1),('two',2),('three',3),)) print(dic) // {'one': 1, 'two': 2, 'three': 3} -
dic = dict(one=1, two=2,three=3) print(dic) // {'one': 1, 'two': 2, 'three': 3} -
dic = dict({'one':1,'two':2,'three':3}) print(dic) // {'one': 1, 'two': 2, 'three': 3}
-
-
字典新增(键名重复,后者会覆盖前者)
dic = dict({'name':'娃娃鱼','age':18}) dic['age'] = 23 print(dic) // {'name': '娃娃鱼', 'age': 23} -
字典新增(键名重复,不会覆盖前者)
dic = dict({'name':'娃娃鱼','age':18}) dic.setdefault("hobby","打篮球") print(dic) // {'name': '娃娃鱼', 'age': 18, 'hobby': '打篮球'} -
字典删除(有返回值返回具体的删除的值,设置第二个参数,无论字典中有无此键,都不会报错)
dic = dict({'name':'娃娃鱼','age':18}) dic.pop('age') print(dic) // {'name': '娃娃鱼'} ========================================== dic = dict({'name':'娃娃鱼','age':18}) print(dic.pop('asd','没有此键')) print(dic) 没有此键 {'name': '娃娃鱼', 'age': 18} -
字典删除(清空)
dic = dict({'name':'娃娃鱼','age':18}) dic.clear() print(dic) //{ } -
字典删除
dic = dict({'name':'娃娃鱼','age':18}) del dic['age'] del dic['age2'] // 错误的键名 报错 print(dic) -
字典修改
dic = dict({'name':'娃娃鱼','age':18}) dic['age'] = 28 print(dic) -
字典的查
dic = dict({'name':'娃娃鱼','age':18}) print(dic['age']) // 18 不存在会报错dic = dict({'name':'娃娃鱼','age':18}) name = dic.get('name') // 不存在的话不会报错 print(name) // 娃娃鱼- dict.keys( ) dict.values( ) dict.items( )
dic = dict({'name':'娃娃鱼','age':18}) keys = dic.keys() print(keys) // dict_keys(['name', 'age']) print(list(keys)) // ['name', 'age'] ================================================ dic = dict({'name':'娃娃鱼','age':18}) values = dic.values() print(values) // dict_values(['娃娃鱼', 18]) print(list(values)) // ['娃娃鱼', 18] ================================================ dic = dict({'name':'娃娃鱼','age':18}) items = dic.items() for key,value in dic.items(): print(key,value) // name 娃娃鱼 age 18
42) 字典的补充
- dict.update( ) 更新,修改
dic = {'name':'娃娃鱼','age':18}
dic.update(like="写代码",height=170)
print(dic) //{'name': '娃娃鱼', 'age': 18, 'like': '写代码', 'height': 170}
========================================================================
dic = {'name':'娃娃鱼','age':18}
dic.update(age=23) // 存在相同的键名会进行覆盖
print(dic) // {'name': '娃娃鱼', 'age': 23}
=======================================================================
dic = {'name':'娃娃鱼','age':18}
dic.update([(1,'a'),(2,'b')])
print(dic) // {'name': '娃娃鱼', 'age': 18, 1: 'a', 2: 'b'}
======================================================================
dic = {'name':'娃娃鱼','age':18}
dic2 = {'name':'alex','like':'打篮球'}
dic.update(dic2) # update 一个字典相当于 合并 有相同的会进行覆盖
print(dic) // {'name': 'alex', 'age': 18, 'like': '打篮球'}
print(dic2) // {'name': 'alex', 'like': '打篮球'}
- dict.fromkeys( ) 值共用一个,修改任何一个,全部改变
dic = dict.fromkeys('asd',100)
print(dic) // {'a': 100, 's': 100, 'd': 100}
==============================================
dic = dict.fromkeys([1,2,3],[])
dic[1].append(666)
print(dic) // {1: [666], 2: [666], 3: [666]}
43) 字典的坑(不要直接改变字典的大小)
dic = {"k1":123,"k2":456,'k3':789,'age':18}
for i in list(dic.keys()): # 转换为列表 进行删除
if 'k' in i:
dic.pop(i)
print(dic)
44)id is == 三者区别
- id ==> 指的是内存地址, 获取内存的地址 id(查询的变量)
- is ==> 判断的是内存地址是否相同(内存地址相同,值一定相同)
- == 判断的是值是否相同(值相同,内存地址不一定相同)
45) 代码块
- 代码块: 所有的代码都需要依赖代码块执行。
- 一个文件就是一个代码块
- 交互式(命令行==>进入cmd控制台中在python中输入的单行命令,每一行都是代码块)
- 同一代码块下的缓存机制(字符串驻留机制)
- str,int,bool 如果多个变量存储都是同一个数据,不会开辟新的内存地址,列表会新开辟
a1 = 100
a2 = 100
a3 = 100
内存中不会多次开辟内存地址
优点: 提升性能,节约内存
- 不同代码块下的缓存机制(小数据池)
- int(-5~256默认数据池中存在)str(部分字符串)
- 优点: 提升性能,节约内存
46 集合{}
python基础数据类型: 集合set。容器型的数据类型,它要求里面的元素是不可变的数据,但是他它本身是可变的数据类型。集合是无序的。
-
集合的作用
- 列表去重
- 关系测试: 交集,并集,差集,.....
-
集合的创建
set1 = set({1,2,'hello'}) set2 = {1,2,'hello'} print(set1,set2) -
集合的增
-
普通增
set2 = {1,2,'hello'} set2.add('dd') print(set2) // {'hello', 1, 2, 'dd'} -
迭代追加
set2 = {1,2,'hello'} set2.update('sdf') print(set2) // {1, 2, 's', 'hello', 'd', 'f'}
-
-
集合的删
-
指定删除
set2 = {1,2,'hello'} set2.remove(1) print(set2) // {2, 'hello'} -
随机删除一个元素
set2 = {1,2,'hello'} set2.pop() print(set2) // {1, 2} -
清空集合
set2 = {1,2,'hello'} set2.clear() print(set2) // set() -
删除集合
set2 = {1,2,'hello'} del set2 print(set2) // 删除集合 将不存在set2变量,打印会报错
-
-
集合的其他操作:
-
交集(& 或者 intersection)
set1 = {1,2,3,4,5} set2 = {4,5,6,7,8} print(set1 & set2) # {4, 5} print(set1.intersection(set2)) # {4, 5} -
并集。(| 或者 union)
set1 = {1,2,3,4,5} set2 = {4,5,6,7,8} print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7,8} print(set2.union(set1)) # {1, 2, 3, 4, 5, 6, 7,8} -
4.3 差集。(- 或者 difference)
// 交集表示set1中所独有的 set1 = {1,2,3,4,5} set2 = {4,5,6,7,8} print(set1 - set2) # {1, 2, 3} print(set1.difference(set2)) # {1, 2, 3} -
反交集。 (^ 或者 symmetric_difference)
// 去除交集以外的所有元素 set1 = {1,2,3,4,5} set2 = {4,5,6,7,8} print(set1 ^ set2) # {1, 2, 3, 6, 7, 8} print(set1.symmetric_difference(set2)) # {1, 2, 3, 6, 7, 8} -
子集与超集
set1 = {1,2,3} set2 = {1,2,3,4,5,6} print(set1 < set2) print(set1.issubset(set2)) # 这两个相同,都是说明set1是set2子集。 print(set2 > set1) print(set2.issuperset(set1)) # 这两个相同,都是说明set2是set1超集。
-
47)深浅拷贝
- 浅拷贝 (只有修改可修改数据类型,两者才会同时改变)==补充(对原对象的新增任何操作,都不会互相影响)

原理分析:
两者的内存地址不同,浅拷贝的值是相同的,对拷贝的内容只有操作可修改的数据类型,才会两者都改变
如果修改的不是可修改的数据类型,将不会互相影响,追加的任何操作,都不会互相影响
s1 = [1,2,3,[22,33]]
s2 = s1.copy()
s1[-1].append(666)
print(s1)
print(s2)
[1, 2, 3, [22, 33, 666]]
[1, 2, 3, [22, 33, 666]]
=============================
s1 = [1,2,3,[22,33]]
s2 = s1.copy()
s1[0] = 66
print(s1)
print(s2)
[66, 2, 3, [22, 33]]
[1, 2, 3, [22, 33]]
-
深拷贝(两者相当于,各自独立没有关联性)
![]()

import copy
s1 = [1,2,3,[22,33]]
s2 = copy.deepcopy(s1)
s1[-1].append(666)
print(s1)
print(s2)
[1, 2, 3, [22, 33, 666]]
[1, 2, 3, [22, 33]]
48编码的进阶(编码:给电脑看的,解码给人看的)
- bytes数据简单定义
s1 = '中国'
b = b'asd'
print(type(b)) // <class 'bytes'>
- 存储原理

计算机在内存(临时存储区域)中都是以unicode编码进行存储,存储到硬盘或者进行数据传输时,又全部转为非unicode编码(bytes数据类型),节省空间
- str ----->bytes(字符串转utf-8)
s1 = '中国'
b = s1.encode('utf-8')
print(b)
- bytes------>str(utf-8转换字符串)
s1 = '中国'
b = s1.encode('utf-8')
b2 = b.decode('utf-8')
print(b2)
- gbk -----> utf-8(以Unicode编码为桥梁,进行转换)
s1 = '中国'
b = s1.encode('gbk') # 编码成gbk
s = b.decode('gbk') #节码成unicode
b2 = s.encode('utf-8') # 编码成utf-8
print(b2)
49)文件操作
- 操作本质
利用内置函数open 调用操作系统的接口
- 文件操作三部曲
1. 打开文件。 # encoding不写,默认以操作系统为基准
f1 = open('c:\少妇的练习方式.txt',encoding='utf-8',mode='r') // 定义 f1,fh,file_handler,f_h等变量(也叫文件句柄)
2. 对文件句柄进行相应的操作
content = f1.read()
print(content)
3. 关闭文件句柄
f1.close()
- 路径层级深的解决方案(推荐第二种)
1. f1 = open('C:\\Users\Admin\Desktop\少妇的练习方式.txt',encoding='utf-8',mode='r') // 双\\转译
2. f1 = open(r'C:\\Users\Admin\Desktop\少妇的练习方式.txt',encoding='utf-8',mode='r') //开头加个r
50)文件读的几种方式( r(读取文本类型),rb(读取非文本类型),r+b,r+ ....)
- read 全部读取
f1 = open(r'C:\Users\Admin\Desktop\少妇的练习方式.txt',encoding='utf-8',mode='r')
content = f1.read()
print(content)
f1.close()
- read(n) 按照字符读取==》写几 读取几个
f1 = open(r'C:\Users\Admin\Desktop\少妇的练习方式.txt',encoding='utf-8',mode='r')
content = f1.read(5)
print(content) // 少妇的练习
f1.close()
- readline( ) 按行读取
f1 = open(r'C:\Users\Admin\Desktop\少妇的练习方式.txt',encoding='utf-8',mode='r')
content = f1.readline()
print(content)
f1.close()
- readlines( )返回一个列表
f1 = open(r'C:\Users\Admin\Desktop\少妇的练习方式.txt',encoding='utf-8',mode='r')
content = f1.readlines()
print(content) // ['少妇的练习方式:\n', 'www.baidu.com']
f1.close()
- for 读取(遇见文件特别大的时候用for读取)
f1 = open(r'C:\Users\Admin\Desktop\少妇的练习方式.txt',encoding='utf-8',mode='r')
for line in f1:
print(line)
f1.close()
- rb模式下的读(不要写encoding,不然会报错)
f1 = open(r'C:\Users\Admin\Desktop\微信图片_20221008163041.jpg',mode='rb')
content = f1.read()
print(content)
f1.close()
51) 文件的写
1.写文本文件
- 在同级目录下没有此文件时(会自动生成一个文件)
f1 = open('文件的写',mode='w',encoding='utf-8')
content = f1.write('继续努力')
print(content) // 继续努力
f1.close()
- 在同级目录下有此文件时(会将原文件先清空,再写入)
f1 = open('文件的写',mode='w',encoding='utf-8')
content = f1.write('继续努力天天向上')
print(content) // 继续努力天天向上
f1.close()
2.写非文本文件
先读取bytes数据,变相copy
f1 = open('微信图片_20220410005723.jpg',mode='rb')
content = f1.read()
f1.close()
f2 = open('黑客.jpg',mode='wb') # 没有文件会先创建
f2.write(content)
f2.close()
52)文件的追加(a模式或者a+模式,读取文件内容时,需要把光标位置重置到0处,通过 fp.seek(0),a模式下默认光标位置在末尾)
- 没有文件时,创建文件
f1 = open('文件的追加',mode='a',encoding='utf-8')
content = f1.write('你是真的牛逼')
f1.close()
// 你是真的牛逼
- 有文件时,追加内容
f1 = open('文件的追加',mode='a',encoding='utf-8')
content = f1.write('你无敌了已经')
f1.close()
// 你是真的牛逼你无敌了已经
53) 文件操作的其他模式r+(先读后追加)
f1 = open('文件的读并追加',mode='r+',encoding='utf-8')
content = f1.read()
print(content)
f1.write('奔流到海不复回')
f1.close()
54)文件操作的其他功能
总结:
三个大方向:
读,四种模式: r rb r+ r+b
写,四种模式: w wb w+ w+b
追加 四种模式: a ab a+ a+b
相应的功能: 对文件句柄的操作: read read(n) readline() readlines() write() tell() seek() flush()
- tell( )
# tell 获取光标的位置 单位字节
f1 = open('文件的写',mode='r',encoding='utf-8')
print(f1.tell()) # 0
content = f1.read()
print(f1.tell()) # 24
f1.close()
- seek( )
中文编码报错解决 errors='ignore'
# 调整光标的位置 原文件内容asdasdasdasdasdasdasddas
f = open('file_write',encoding='utf-8',errors='ignore',mode='r')
f.seek(20)
content = f.read()
print(content) # ddas
f.close()
- flush 强制刷新
// 用于及时保存 类似ctrl+s
f = open('file_write',mode='w',encoding='utf-8')
f.write('asdasd')
f.flush() // 立即保存刷新
f.close()
55)文件的另一种打开方案
- 优点1:不用手动关闭文件句柄
with open('file_write',encoding='utf-8',mode='r') as f1:
print(f1.read())
- 优点2: 可同时操作多个文件句柄
with open('file_write',encoding='utf-8',mode='r') as f1,\
open('文件的追加',encoding='utf-8',mode='w') as f2:
print(f1.read())
f2.write('方平心态,好好学习')
- 缺点待续
56)文件的改
- low版(文件过大,直接读取会爆栈)
'''
1. 以读的模式打开原文件。
2. 以写的模式创建一个新文件。
3. 将原文件的内容读出来修改成新内容,写入新文件。
4. 将原文件删除
5. 将新文件重命名成原文件
'''
import os
# 1 以读的模式打开原文件。
# 2 以写的模式创建一个新文件
with open('alex自述',encoding='utf-8') as f1,\
open('alex自述.bak',mode='w',encoding='utf-8') as f2:
# 3 将原文件的内容读出来修改成新内容,写入新文件。
old_content = f1.read()
new_conten = old_content.replace('alex','SB')
f2.write(new_conten)
os.remove('alex自述')
os.rename('alex自述.bak','alex自述') # 前者改为后者
- 进阶版(for循环)
'''
1. 以读的模式打开原文件。
2. 以写的模式创建一个新文件。
3. 将原文件的内容读出来修改成新内容,写入新文件。
4. 将原文件删除
5. 将新文件重命名成原文件
'''
import os
# 1 以读的模式打开原文件。
# 2 以写的模式创建一个新文件
with open('alex自述',encoding='utf-8') as f1,\
open('alex自述.bak',mode='w',encoding='utf-8') as f2:
# 3 将原文件的内容读出来修改成新内容,写入新文件。
for line in f1.read():
line.replace('SB','alex')
f2.write(line)
os.remove('alex自述')
os.rename('alex自述.bak','alex自述')
57)有关文件清空问题
# 关闭文件句柄,再次以w模式打开此文件时,才会清空。
with open('文件的写',encoding='utf-8',mode='w') as f1:
for i in range(9):
f1.write('恢复贷款首付款')
58) 函数定义
def say_hi():
print('hello')
say_hi()
- 普通形参 + 默认形参
# 普通形参必须放到默认形参的前面,不能调整位置
def say_hi(name,age='18'):
print('hello'+name+age)
say_hi('娃娃鱼') # hello娃娃鱼18
- 关键字实参
# 如果都是关键字实参,可以任意调整实参的顺序
# 普通实参必须写在关键字实参的前面
def say_hi(name,a,b,c,age='18'):
print('hello'+name+age)
say_hi(name='娃娃鱼',a=1,b=21,c=3,age=18)
- 普通收集参数(*args)==》应用场景求任何个数的和
# 普通收集参数:专门用来收集那些多余的没人要的,普通实参
# 收集之后会把多余实参打包成一个元组
def fn(a,b,c,*args):
print(a,b,c) # 1 2 3
print(args) # (4, 5, 6)
fn(1,2,3,4,5,6)
=================================
# 任意个数值得累加和
def fn(*args):
total = 0
for i in args:
total += i
print(total)
fn(1,2,3,4,5,6) # 21
- 关键字收集形参(**kwargs)
# 关键字收集形参: 专门用于收集那些多余的没人要的关键字实参
# 收集之后,会把多余关键字实参打包成一个字典
def fn(**kwargs):
value1 = '' # 有职务
value2 = '' # 无职务
dic = {"banzhang":'班长','banhua':'班花'}
for k,v in kwargs.items():
if k in dic:
value1 += dic[k] +':' + v +'\n'
else:
value2 += v + ','
print(value1.strip())
print(value2.strip(','))
fn(banzhang="娃娃鱼",banhua='赵芹',water="刘能",water2="赵四",water3="谢广坤")
- 命名关键字参数(在函数调用时,必须使用关键字实参的形式来进行调用)
'''
(1) def fn(a,b,*,c,d) 跟在*号后面的c和d是必须命名关键字参数
(2) def fn(*args,e,**kwargs) 夹在*args和**kwargs之间的参数必须是命名关键字参数
跟在*args后面即使没有**kwargs也是命名关键字参数
'''
# 定义方法一
def fn(a,b,*,c,d):
print(a,b) # 1 2
print(c,d) # 3 4
# 必须指定关键字实参,才能对命名关键字形参进行赋值
fn(1,2,c=3,d=4)
==========================================
# 定义方法二
def fn(*args,e,**kwargs):
print(args) # (1, 2, 3)
print(e) # 我是e
print(kwargs) # {'name': '娃娃鱼', 'age': 18}
fn(1,2,3,name="娃娃鱼",age=18,e='我是e')
- 星号的使用
'''
* 和 ** 如果在函数的定义处使用:(打包)
* 把多余的普通实参打包成元组
** 把多余的关键字实参打包成字典
* 和 ** 如果在函数的调用处使用:(解包)
* 把元组或者列表进行解包
** 把字典进行解包
'''
def fn(a,b,*,c,d):
print(a,b) # 1 2
print(c,d) # 3 4
# 函数的调用处 * 用法
li = [1,2] # tup(1,2)
fn(*li,c=3,d=4) # 等价于 fn(1,2,c=3,d=4)
========================================
# 函数的调用处 ** 用法
def fn(a,b,*,c,d):
print(a,b) # 1 2
print(c,d) # 3 4
dic = {"c":3,"d":4}
fn(1,2,**dic) # 等价于 fn(1,2,c=3,d=4)
=====================================
# 综合写法
def fn(a,b,*,c,d):
print(a,b) # 1 2
print(c,d) # 3 4
li = [1,2]
dic = {"c":3,"d":4}
fn(*li,**dic)
- 总结
# 定义成如下形式,可以收集所有的实参
def fn(*args,**kwargs)
# 总结: 当所有的形参都放在一起的时候,顺序yuanze
'''
普通形参 -> 默认形参 -> 普通收集形参 -> 命名关键字形参 -> 关键字收集形参
'''
def f1(a,b,c=0,*args,d,**kw):
print(a,b,c,args,kw) # a=1,b=2,c=3,args=('a','b'),kw = {'x': 99, 'y': 77}
print(d) #67
f1(1,2,3,'a','b',d=67,x=99,y=77)
59)函数中修改全局变量
'''
总结: global的使用
如果当前不存在全局变量,可以在函数内部通过glibal关键字来定义全局变量
如果当前存在全局变量,可以在函数内部通过global关键字修改全局变量
'''
b = 10
def fn():
global b
b = 20
fn()
print(b) # 20
60)生命周期
'''
该变量的作用时长
内置命名空间 -> 全局命名空间 -> 局部命名空间(最短)函数调用时创建,调用后立即释放
'''
61)函数名的使用
- 当作变量使用
a = 1
def fn():
print(1)
a = fn
a()
- 动态销毁
a = 1
def fn():
print(1)
a = fn
del a
a() # NameError: name 'a' is not defined
- 当参数传递
def fn1():
return '我是fn1函数'
def fn2(f):
return f()
res = fn2(fn1)
print(res) # 我是fn1函数
- 作为值返回
def fn3():
print('我是fn3函数')
def fn4(f):
return f
res = fn4(fn3)
print(res) # <function fn3 at 0x0000023EB15A1F28>
res() # 我是fn3函数
- 函数名可以作为容器类型数据的元素
def fn1():
print('我是fn1函数')
def fn2():
print('我是fn2函数')
li = [fn1,fn2]
for i in li:
i()
62) help查看文档
def study(kemu):
'''
功能:叫你如何学习
参数:具体学科
返回值:是否学会
'''
print('选择具体的科目名称{}'.format(kemu))
print('先从基础,表现出来即可')
print('再从细节下手')
print('大量的练习,输入与输出相匹配')
return '学会了'
# 方法一 函数名.__doc__
res = study.__doc__
print(res)
# 方式二
help(study)
63)函数的嵌套nonlocal 修改的是(局部变量)
# 此时的两个a 相当于两个局部变量 找对应和自己平级的
def outer():
a = 10
def inner():
a = 20
print(a) # 20
inner()
print(a) # 10
outer()
===================================
# nonlocal 修改上一层的局部变量,如果上上层还有相同名字的变量,将不会被修改
def outer():
a = 10
def inner():
nonlocal a
a = 20
print(a) # 20
inner()
print(a) # 20
outer()
64)闭包函数
- 闭包函数概念
'''
互相嵌套的两个函数,如果内函数使用了外函数的局部变量
并且外函数把内函数返回出来的过程,叫做闭包
里面的内函数叫做闭包函数
是不是闭包?
1. 内函数使用了外函数的局部变量
2 .外函数返回内函数
'''
def macun_family():
father ='马云'
def hobby():
print('我对钱没有一丝丝的兴趣,我不看重钱,这是我爸爸{}说的'.format(father))
return hobby
fn = macun_family()
fn()
- 闭包函数复杂形式
def zhaowanli_family():
gege = '王思聪'
didi = '高振宁'
money = 1000
def gege_hobby():
nonlocal money
money -= 500
print('我叫朋友不在乎他有没有钱,反正都没有我有钱,我就喜欢交女朋友... 钱物还剩下{}'.format(money))
def didi_hobby():
nonlocal money
money -= 400
print('家里有鞋柜,各式各样的奢侈鞋,一双大概20-30万... 钱物还剩下{}'.format(money))
def big_master():
return [gege_hobby,didi_hobby]
return big_master
fn = zhaowanli_family() # 得到 big_master 函数对象
fn2 = fn() # 得到 [gege_hobby,didi_hobby] 函数对象列表
gege = fn2[0] # 得到 gege_hobby函数对象
gege() # 执行 gege_hobby函数
didi = fn2[1] # 得到 didi_hobby函数对象
didi() # 执行 didi_hobby函数
65)判断闭包的另一种方式
# 使用 __closure__, cell_contents 判定闭包
'''如果返回的元组中有数据说明是闭包,谁的生命周期被延长旧打印谁'''
# 使用 __closure__, cell_contents 判定闭包
'''如果返回的元组中有数据说明是闭包,谁的生命周期被延长旧打印谁'''
def zhaowanli_family():
gege = '王思聪'
didi = '高振宁'
money = 1000
def gege_hobby():
nonlocal money
money -= 500
print('我叫朋友不在乎他有没有钱,反正都没有我有钱,我就喜欢交女朋友... 钱物还剩下{}'.format(money))
def didi_hobby():
nonlocal money
money -= 400
print('家里有鞋柜,各式各样的奢侈鞋,一双大概20-30万... 钱物还剩下{}'.format(money))
def big_master():
return [gege_hobby, didi_hobby]
return big_master
fn = zhaowanli_family()
newFn = fn.__closure__ # (<cell at 0x0000023986B78888: function object at 0x0000023987227A60>, <cell at 0x0000023986B789D8: function object at 0x00000239872279D8>)
print(newFn[0].cell_contents) # 等价于 获取到 didi_hobby 函数
newFn[0].cell_contents() # 家里有鞋柜,各式各样的奢侈鞋,一双大概20-30万... 钱物还剩下600
66)闭包的意义
# 闭包可以优先使用外函数中的变量,并对闭包中的值起到了封装保护的作用,外部无法访问
67) lambda表达式
'''
用一句话来表达只有返回值的函数
语法 lambda 参数 : 返回值
特点: 简洁,高效
'''
- (1) 无参的lambda表达式
def func():
return "你是大帅哥"
# 改造
fn = lambda : "你是大帅哥"
print(fn()) # 你是大帅哥
- (2)有参的lambda表达式
def fn(n):
return n
# 改造
fn = lambda n : n
print(fn(10)) # 10
- (3) 带有判断的lambda表达式
def fn(n):
if n % 2 ==0:
return '偶数'
else:
return '奇数'
# 改造
fn = lambda n : '偶数'if n % 2 ==0 else '奇数'
print(fn(10)) # 偶数
68) 三元表达式
'''
基本语法
if 条件 else 语句
满足条件 返回if前面的值 不满足条件返回 else 值
'''
res = 'OK'if 3>2 else 'NOKO'
print(res)
69)locals 与 globals 使用(了解)
'''
locals 获取当前作用域所有的变量
locals 在全局空间, 获取的是打印之前print(locals())所有的全局变量
locals 在局部空间, 获取的是 res 之前的所有局部变量
'''
# 全局空间
def func():
a1 = 1
b2 = 2
a = 1
b = 2
res = locals()
c = 3
print(res)
d = 4
=====================================
# 局部空间
a = 1
b = 2
def func():
a1 = 1
b2 =2
res = locals()
c3 =3
print(res)
d4 = 4
c = 3
func()
d = 4
'''
globals 在全局空间, 获取的是打印之前print(locals())所有的全局变量
globals 在局部空间, 获取的是 函数调用处 之前的所有全局变量
'''
- globals 返回的是内置系统的全局字典
dic = globals()
print(dic) # 获取内置系统的全局字典
# 通过字符串可以创建全局变量
dic['wangwen'] = '18岁' # 此语法 相当于向全局字典中添加 一个变量并赋值
print(wangwen)
# 批量创建全局变量
def fn():
dic = globals()
for i in range(1,5):
dic['s{}'.format(i)] = i
fn()
print(s1,s2,s3,s4) # 1,2,3,4
70) 迭代器
- 迭代器的创建 判断
'''
迭代器: 能被next()函数调用并不断返回下一个值的对象称为迭代器(Iterator 迭代器是对象)
概念:
迭代器指的是迭代取值的工具,迭代是一个重复的过程,每次重复都是居于上一次的结果而继续的,
单纯的重复并不是迭代
特征:
并不依赖索引,而通过next指针(内存地址寻址)迭代所有数据,一次只取一个值,
而不是一股脑的把所有数据放进内存,大大节省空间
'''
# 可迭代对象
setvar = {'马思纯','晓晓','王麻子','了不得'}
# 获取当前对象成员的内置成员
lst = dir(setvar)
print(lst)
# 判断是否是可迭代对象
res = '__iter__' in lst
print(res)
- 判断是否是迭代器以及调用迭代器
'''
for循环之所以可以遍历所有的数据,是因为底层使用了迭代器,通过地址寻找地址的方式,一个一个的找数据
可迭代对象 -> 迭代器 实际上就是从不能够被next直接调用 -> 可以被next指针直接调用的过程
'''
# 如何创建一个迭代器
setvar = {'马思纯','晓晓','王麻子','了不得'}
res = iter(setvar)
print(res)
# 如何判断是否是迭代器
print(dir(res))
result = '__iter__' in dir(res) and '__next__' in dir(res)
print(result) # True
# 如何调用一个迭代器
'''next是单项不可逆的过程,一条路走到黑'''
res1 = next(res)
print(res1)
res1 = next(res)
print(res1)
res1 = next(res)
print(res1)
res1 = next(res)
print(res1)
res1 = next(res)
print(res1) # StopIteration报错 超出迭代器范围 只能打印出四个元素
- 重置迭代器
# 重置迭代器
setvar = {'马思纯','晓晓','王麻子','了不得'}
it = iter(setvar)
print(it.__next__())
print(it.__next__())
print(it.__next__())
print(it.__next__())
- 调用迭代器的其他方法
# 调用迭代器的其他方法
setvar = {'马思纯','晓晓','王麻子','了不得'}
it = iter(setvar)
for i in it:
print(i)
==========================
setvar = {'马思纯','晓晓','王麻子','了不得'}
it = iter(setvar)
# 推荐使用(数据过大时,for循环容易卡死)
for i in range(2):
print(next(it))
- 判断迭代器/可迭代对象的其他方法(推荐使用)
# 判断迭代器/可迭代对象的其他方法
# 从...模块 引入...内容
from collections import Iterator,Iterable
'''Iterator 迭代器 Iterable 可迭代的对象'''
setvar = {'马思纯','晓晓','王麻子','了不得'}
it = iter(setvar)
res = isinstance(it,Iterator)
print(res) # True
res = isinstance(it,Iterable)
print(res) # True
71)高阶函数map()整理数据格式
- map
'''
语法: map(function,iterable可迭代对象)
功能: 处理数据
把Iterable中的数据一个一个放到function中处理,通过调用迭代器来获取返回值
参数:
function : 函数(内置函数,自定义函数)
Iterable : 可迭代性对象 (容器类型数据,range对象,迭代器)
返回值:
迭代器
'''
- 入门案例
'''将字符串转化为整型'''
li = ['1','2','3','4']
res = map(int,li)
# 调用迭代器 next
print(next(res)) # 1
print(next(res)) # 2
print(next(res)) # 3
print(next(res)) # 4
# 调用迭代器 for
for i in res:
print(i)
# for + next
for i in range(4):
print(next(res))
# 强转成列表
print(list(res))
- 进阶案例
'''
map 会将li中的每个元素放入函数中 形参和return返回值必须写
'''
li = [1,2,3,4]
def fn(i):
if i == 1:
li[i-1] = i * 1
return li[i-1]
else:
li[i-1] = i * 2**i
return li[i-1]
print(li)
res = map(fn,li)
print(list(res)) # [1, 8, 24, 64]
'''['a','b','c']换成[97,98,99]'''
dic = {97:'a',98:"b",99:'c'}
new_dic = dic.items()
def fn(i):
for k,w in new_dic:
if i == w:
return k
li = ['a','b','c']
res = map(fn,li)
print(list(res))
72) 高阶函数 reduce(计算)
- 基本语法
'''
from functools import reduce 需要引入reduce
reduce(function,iterable)
功能: 计算数据
把iterable中的前两个数据放入function中进行计算,把计算的结果和function中第三个值再继续放入function中做计算
以此类推...
最后返回计算结果
参数:
function: 自定义函数
iterable: 可迭代对象(容器类型数据 range对象 迭代器)
返回值:
计算的结果
'''
- 入门案例
li = [1,2,3,4]
def fn(x,y):
return x + y
from functools import reduce
res = reduce(fn,li)
print(res) # 10
==============================================
# lambda表达式改造
li = [1,2,3,4]
def fn(x,y):
return x + y
from functools import reduce
res = reduce(lambda x,y: x + y,li)
print(res) # 10
73)高阶函数 filter(过滤)
- 基本语法
'''
filter(function,iterable)
功能: 过滤数据
在自定义的函数中,
如果返回True, 保留该数据
如果返回False,舍弃该数据
参数:
function: 自定义函数
iterable: 可迭代对象(容器类型数据 range对象 迭代器)
返回值:
迭代器
'''
- 入门案例(保留偶数)
li = [1,2,3,4,5,6,7,8,9,10]
def fn(n):
if n % 2 == 0:
return True
res = filter(fn,li)
print(list(res)) # [2, 4, 6, 8, 10]
# lambda 简化
li = [1,2,3,4,5,6,7,8,9,10]
res = filter(lambda n: True if n % 2 ==0 else False,li)
print(list(res)) # [2, 4, 6, 8, 10]
74)高阶函数sorted(排序)
- 基本语法
'''
sorted(iterable,key=函数,reverse=Fales)
功能:排序
参数:
iterable: 可迭代对象(容器类型数据 range对象 迭代器)
key : 指定函数(自定义/内置)
reverse : 是否倒叙
返回值:
列表
'''
- 入门案例
tup = (-3,-80,1,10)
# 从小到大
res = sorted(tup) # [-80, -3, 1, 10]
# 从大到小
res = sorted(tup,reverse = True) # [10, 1, -3, -80]
# 按照绝对值进行排序
res = sorted(tup,key = abs) # [1, -3, 10, -80]
- 自定义函数排序
'''按照余数进行排序'''
tup = (29,33,12,67)
def fn(i):
return i % 10
res = sorted(tup,key = fn)
print(res) # [12, 33, 67, 29]
- 任意类型数据都可以通过sorted排序
data = 'abc'
print(sorted(data)) # ['a', 'b', 'c']
data = [1,2,3]
print(sorted(data)) # [1,2,3]
data = {"你好","娃娃鱼","大鱼海棠"}
print(sorted(data)) # ['你好', '大鱼海棠', '娃娃鱼'] 中午无序
data = {"zhaobenshan",'songdandan','caiqin','liguyi'}
print(sorted(data)) # ['caiqin', 'liguyi', 'songdandan', 'zhaobenshan'] 按照英文字母顺序排列
data = {"xiaozhan":'博主',"miss":'大小姐','yaoyang':'东星耀阳'}
print(sorted(data)) # ['miss', 'xiaozhan', 'yaoyang']
- 总结
'''
sorted(推荐使用)
(1) 可以排序所有的容器类型数据
(2) 返回一个新的列表
sort
(1) 只能排序列表
(2) 基于原来的列表进行排序
'''
75)列表推导式
- 基本语法入门
# 推导式: 通过一行循环判断遍历出一系列数据的方法叫推导式
'''
语法:
val for val in iterable
'''
li = []
for i in range(1,51):
li.append(i)
print(li)
# 推导式改写
'''
代码解读:
将for循环中的每一个i,给到for关键字前面的i,再用列表将每一个for循环中的i包裹起来,形成列表
'''
li = [i for i in range(1,51)]
print(li)
- 小练习
# [1,2,3,4,5] ==> [2,4,6,8,10]
li = [i*2 for i in range(1,6)]
print(li) # [2, 4, 6, 8, 10]
- 带判断条件的推导式
li = [1,2,3,4,5,6,7,8,9,10]
res = [i for i in li if i % 2 == 1]
print(res) # [1, 3, 5, 7, 9]
- 推导式小练习
# 把字典写成 x=A,y=B,z=C的列表推导式
dic = {'x':'A','y':'B','z':'C'}
res = [k + '=' + w for k,w in dic.items()] # 将每次遍历的 k,w 赋值给for关键字前面的k,w
print(res) # ['x=A', 'y=B', 'z=C']
# 把列表中所有字符变成小写 ['ADDD','dddDD','DDaa','sss']
li = ['ADDD','dddDD','DDaa','sss']
res = [i.lower() for i in li ]
print(res) # ['addd', 'ddddd', 'ddaa', 'sss']
# x是0-5之间的偶数,y是0-5之间的奇数 把 x,y组成一起变成元组,放到列表当中
li = []
for x in range(6):
for y in range(6):
if x % 2 == 0 and y % 2 == 1:
li.append((x,y))
print(li) # [(0, 1), (0, 3), (0, 5), (2, 1), (2, 3), (2, 5), (4, 1), (4, 3), (4, 5)]
# 使用列表推导式 制作99 乘法表
for i in range(1,10):
for j in range(1,i+1):
print('{0} * {1} = {2}'.format(i,j,i*j),end=" ")
print()
===========================================改写
li = ['{0} * {1} = {2}'.format(i,j,i*j) for i in range(1,10) for j in range(1,i+1) ]
#
76)集合推导式
'''
案例:
满足年龄在18到21,存款大于等于5000 小于等于5500的人,
开卡格式为:尊贵VIP卡老X(姓氏),否则开卡格式为:扣脚大汉卡老x(姓氏)
把开卡的种类统计出来
'''
lst = [
{"name":'张苫布',"age":18,"money":3000},
{"name":'张三丰',"age":19,"money":5200},
{"name":'张衣衫',"age":20,"money":100000},
{"name":'张无极',"age":21,"money":1000},
{"name":'王志国',"age":18,"money":5500},
{"name":'王志飞',"age":99,"money":5500},
]
sets = set()
for i in lst:
if 18<=i['age']<=21 and 5000<=i['money']<=5500:
res = '尊贵VIP卡老{}'.format(i['name'][0])
else:
res = '扣脚大汉卡老{}'.format(i['name'][0])
sets.add(res)
print(sets) # {'尊贵VIP卡老王', '尊贵VIP卡老张', '扣脚大汉卡老王', '扣脚大汉卡老张'}
# 改写集合推导式
set_new = {'尊贵VIP卡老{}'.format(i['name'][0])if 18<=i['age']<=21 and 5000<=i['money']<=5500 else '扣脚大汉卡老{}'.format(i['name'][0]) for i in lst}
77)字典推导式
- 枚举(enumerate)
'''
enumerate(iterable,[start=0])
功能:枚举 将索引号和iterable中的值,一个一个拿出来配对组成元组,通过迭代器返回
参数:
iterable: 可迭代性数据(常用:迭代器,容器类型数据,可迭代对象range)
start: 可以选择开始的索引号(默认从0开始索引)
返回值:迭代器
'''
from collections import Iterator,Iterable
li = ['铁拐李','吕洞宾','何仙姑','张果老','曹国舅','蓝采和','韩湘子','钟离权']
it = enumerate(li)
# 字典推导式 配合枚举(enumerate)
dic = {k:v for k,v in it}
print(dic)
# {0: '铁拐李', 1: '吕洞宾', 2: '何仙姑', 3: '张果老', 4: '曹国舅', 5: '蓝采和', 6: '韩湘子', 7: '钟离权'}
=====================================================
# 使用dict 强转迭代器
dic = dict(enumerate(li))
# {0: '铁拐李', 1: '吕洞宾', 2: '何仙姑', 3: '张果老', 4: '曹国舅', 5: '蓝采和', 6: '韩湘子', 7: '钟离权'}
- zip
'''
zip(iterable,... ...)
功能: 将多个iterable中的值,一个一个拿出来(按照索引值)配对组成元组,通过迭代器返回
iterable: 可迭代性数据(常用:迭代器,容器类型数据,可迭代对象range)
返回: 迭代器
'''
# 基本语法
lst1 = ['阿萨大','而她否','咯卡开']
lst2 = ['拉卡市','请问饿','主栈中']
lst3 = ['吹催促','本本版','你你你']
it = zip(lst1,lst2,lst3)
print(list(it)) # [('阿萨大', '拉卡市', '吹催促'), ('而她否', '请问饿', '本本版'), ('咯卡开', '主栈中', '你你你')]
# 在索引下标同时存在时,才会进行配对,否则放弃
lst1 = ['阿萨大','而她否','咯卡开']
lst2 = ['拉卡市','请问饿']
lst3 = ['吹催促']
it = zip(lst1,lst2,lst3)
print(list(it)) # [('阿萨大', '拉卡市', '吹催促')]
# 字典推导式 配合 zip 来实现
lst_key = ['ww','axd','yyt']
lst_val = ['王伟','安晓东','杨元套']
dic = {k:v for k,v in zip(lst_key,lst_val)}
print(dic) # {'ww': '王伟', 'axd': '安晓东', 'yyt': '杨元套'}
# 使用dict强转迭代器,瞬间得到字典
dic = dict(zip(lst_key,lst_val))
print(dic) # {'ww': '王伟', 'axd': '安晓东', 'yyt': '杨元套'}
78)生成器(元组推导式)
- 基本概念
'''
生成器本质是迭代器,允许自定义逻辑的迭代器
生成器和迭代器的区别:
迭代器本身是系统内置的,重写不了
而生成器是用户自定义的,可以重写迭代逻辑
生成器可以用两种方式创建:
1. 生成器表达式( 里面是推导式,外面用圆括号)
2. 生成器函数 (用def定义,里面含有yield)
'''
# 生成表达式 (里面是推导式,外面用圆括号)
gen = (i for i in range(10))
print(gen) # <generator object <genexpr> at 0x00000236257D8360>
# 判断类型
from collections import Iterator,Iterable
print(isinstance(gen,Iterator)) # True
#1 next 调用生成器
print(next(gen)) # 0
print(next(gen)) # 1
#2 for + next 调用生成器
for i in range(3):
print(next(gen)) # 2 3 4
#3 for 调用生成器所有数据
for i in gen:
print(i) # 5 6 7 8 9
#4 list强转生成器,瞬间得到所有数据
gen = (i for i in range(10))
print(list(gen)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
- 生成器函数
- 基本语法
def fn():
print('111')
yield 1
print('222')
yield 2
print('333')
yield 3
# 初始化生成器函数
gen = fn()
# 第一次调用
res = next(gen) # 111
print(res) # 1
# 第二次调用
res = next(gen) # 222
print(res) # 2
# 第三次调用
res = next(gen) # 333
print(res) # 3
# 第四次调用 超出范围 报错
res = next(gen)
print(res)
'''
第一次调用
print('111') yield 1 保存当前行代码的状态,把1返回,并且等待下一次调用
第二次调用
从上一次保存当前行往下走,print('222') yield 2,保存当前行代码状态,把2返回,继续等待下一次调用
依次类推....yield后面没用代码的情况下,再次调用会报错
'''
- 优化生成器代码
'''生成器应用的场景是大数据的范围中使用,切记不可直接用for遍历所有,可能无法短时间获取'''
def fn():
for i in range(1,101):
yield i
# 初始化生成器函数
gen = fn()
# 第一次调用会记住结束时的位置
for i in range(30):
print(next(gen))
#第二次调用会延续上一次之后的位置继续调用
for i in range(40):
print(next(gen))
79)send的使用方式
'''
next 和send 区别:
next 只能取值
send 不但能取值,还能发送值
send注意点:
第一个 send 不能给 yield 传值 默认只能写None
最后一个yield 接收不到send的发送值
'''
def mygen():
print('start')
res = yield '内部1'
print(res,'<==内部==>')
res = yield '内部2'
print(res,'<==内部==>')
res = yield '内部3'
print(res,'<==内部==>')
print('end')
# 初始化生成器函数
gen = mygen()
# 第一次调用生成器
'''第一次调用生成器时,因为没有遇到yield保存代码的位置,
无法发送数据,默认第一次只能发送None
'''
res = gen.send(None) # start
print(res,'<==外部==>') # 内部1 <==外部==>
# 第二次调用生成器
res = gen.send('100') # 100
print(res,'<==外部==>') # 内部2 <==外部==>
# 第三次调用生成器
res = gen.send('200') # 200
print(res,'<==外部==>') # 内部3 <==外部==>
# 第四次调用生成器
res = gen.send('300')
print(res,'<==外部==>') # 报错StopIteration超出范围
- 过程示意图

'''
第一次调用 执行print('start') res = yield '内部1' 遇见yield将终止运行并保存当前行(第四行) 并将'内部1'返回
res = gen.send(None) # start
print(res,'<==外部==>') # 内部1 <==外部==>
第二次调用 传入了'100' 从第四行的下一行开始执行 执行print(res(此时为100),'<==内部==>') res = yield '内部2'
遇见yield将终止运行并保存当前行(第七行) 并将'内部2'返回
res = gen.send('100') # 100
print(res,'<==外部==>') # 内部2 <==外部==>
第三次调用 传入了'200' 从第七行的下一行开始执行 执行print(res(此时为200),'<==内部==>') res = yield '内部3'
遇见yield将终止运行并保存当前行(第十行) 并将'内部3'返回
res = gen.send('200') # 200
print(res,'<==外部==>') # 内部3 <==外部==>
第四次调用 传入了'300' 从第十行的下一行开始执行,由于没有遇见yield(报错 StopIteration 超出范围)
'''
80)yield from 的使用
'''
将一个可迭代对象变成一个迭代器返回
'''
def mygen():
lst = ['张磊','李亚峰','刘意蜂','王陪同']
yield from lst
# 初始化生成器函数
gen = mygen()
print(next(gen)) # 张磊
print(next(gen)) # 李亚峰
print(next(gen)) # 刘意蜂
print(next(gen)) # 王陪同
# 斐波那契数列
'''
使用生成器分段获取所有内容,而不是一股脑的把所有数据全部打印
'''
'''1 1 2 3 5 8 13 21 34'''
def mygen(maxval):
a,b = 0,1
i = 0
while i < maxval:
# print(b)
yield b
a,b = b,a+b
i += 1
# 初始化生成器
gen = mygen(10)
# 第一次获取
for i in range(3):
print(next(gen))
# 第二次获取
for i in range(5):
print(next(gen))
81) 递归过程示意图
'''
每次调用函数时,都要单独在内存当中开辟空间,交作栈帧空间,以运行函数中的代码
递归总结:
(1)递归实际上是不停的开辟栈帧空间和释放栈帧空间的过程,开辟就是去的过程,释放就是回的过程
(2)递归什么时候触发归的过程:
1.当最后一层栈帧空间执行结束的时候,触发归的过程(条件不满足时)
2.当遇到return返回值的时候终止当前函数,触发归的过程
(3)递归不能无限的去开辟空间,可能造成内存溢出,蓝屏死机的情况,所以一定要给予跳出的条件(如果递归的层数太大,不推荐使用)
(4)开辟的每一个栈帧空间,数据是彼此独立不共享的。
'''
- 递归练习
# 任意数的阶乘
def fn(n):
if n <= 1:
return 1
return fn(n-1) * n
print(fn(5))
'''
代码解析:
去的过程:
n = 5 return fn(n-1) * n => fn(4) * 5
n = 4 return fn(n-1) * n => fn(3) * 4
n = 3 return fn(n-1) * n => fn(2) * 3
n = 2 return fn(n-1) * n => fn(1) * 2
n = 1 return 1
回的过程
n = 2 return fn(1) * 2 => 1 * 2
n = 3 return fn(2) * 3 => 1 * 2 * 3
n = 4 return fn(3) * 4 => 1 * 2 * 3 * 4
n = 5 return fn(4) * 5 => 1 * 2 * 3 * 4 * 5
到此程序结束:
返回 1 * 2 * 3 * 4 * 5
'''
82)虚拟机安装步骤
无脑点击下一步即可
83)新建虚拟机步骤



























84) 安装插件VMware





-
第六步调整全屏 点击左上角产看/自适应客户机即可
-
第七步 将windows的文件拖拽到虚拟机中 虚拟机的文件也可以拖拽到windows 虚拟机终端中的命令可以复制到windows,
并且 windows的文字 也可以复制到虚拟机终端中 表示插件安装成功
所有步骤按照以上来还不行的情况下,重启电脑
85)网络配置
1. 关闭虚拟机 点击编辑/虚拟网络编辑器 2. 将所有网络移除,然后还原默认配置
86)linux 和 windows的区别
''' 1. 目录的结构 2. 文件格式 windows 操作系统内核以NT标准为基础创建, 而linux是以posix标准为基础创建 windows 主要文件系统是 fat32或NTFS 而linux 主要文件系统时 Ext2,Ext3 3. 安全性 ''' # 目录含义 ''' /bin 存放普通用户的命令文件 /boot 存放系统启动文件 /cdrom 存放读取光盘的相关文件 /dev 设备文件 /etc 配置文件 /home 家目录 /lib 库文件 /lib64 64位库文件 /lost+found 系统异常产生错误时,丢失文件放在这 /media 媒体文件 /mnt 挂载目录 /opt 安装软件是的默认目录 /proc 内存中相关数据文件 /root root用户登录的家目录 /run 系统运行时候 用到的文件 /sbin 超级管理员运行的文件 /srv 服务启动之后需要访问的数据目录 /sys 系统文件 /tmp 临时文件 /user 应用程序存放目录 /var 放置系统执行过程中经常变化的文件,如随时更改的日志文件 linux 系统当中 一切皆文件 '''87)Linux命令
- 目录图
- part1
'''
ls 查看目录下有哪些文件
ls -a 查看所有文件(包括隐藏文件)
ls -l 以列表的形式查看目录下有哪些文件
ls -lh 可以让文件带上大小单位
ll 相当于 ls -a 和 ls -l 的结合 一次性以列表形式展示所有的文件(包括隐藏文件)
cd + / 切换到根目录
cd + ~ 切换到家目录
cd - 当前目录 与 上一个目录 来回切换
pwd 查看所在目录位置
'''
- part2
'''
ctrl + l 清屏
mkdir + 文件夹名 创建文件夹
touch + 文件名 创建文件
sudo mkdir + 文件夹名 (可以在根目录进行创建,sudo提高权限)
ln -s 创建链接 (ln -s 指定想要创建的连接 放到哪个目录下面) 必须是绝对路径
ln -s /home/yukai/ceshi100 /home/yukai/ceshi200 相当于把ceshi100 复制一份到ceshi200下
Linux ifconfig 查看Ip地址
Windows ipconfig 查看Ip地址
'''
- part3
'''
mv 剪切
mv 从哪个路径 到哪个路径
mv mv.txt ../ceshi100 相对路径和绝对路径都可以
cp 复制
cp mv.txt ../ceshi200 相对路径和绝对路径都可以
cp -r ceshi200 ceshi100 复制文件夹 -r
cp -a ceshi200 ceshi100 复制文件夹(以及权限复制)
rm -rf ceshi100 删除
'''
- part4
'''
nano mv.txt 进行文件的编辑(ctrl + x 再输入y + 回车 保存编辑并退出)
cat mv.txt 读取文件内容
more mv.txt 文件内容过多时(分页效果 空格 即可翻页)
head -3 mv.txt 查看前三行内容
tail -3 mv.txt 查看后三行内容
'''
88)文件权限
文件类型:
d: 目录 -普通文件 l链接文件
文件类型 所属主 所属组 其他 所属主 所属组 文件大小 文件修改时间 文件名称
d rwx rwx rwx wangwen wangwen 4096 9月 27 17:06 ceshi100
r :可读->4 w:可写->2 x:可执行->1
r => 4
w => 2
x => 1
r w x任意拼凑一共是8种权限
--- => 0
--x => 1
-w- => 2
-wx => 3
r-- => 4
r-x => 5
rw- => 6
rwx => 7
在家目录中,默认创建一个文件的权限是664
在根目录中,默认创建一个文件的权限是644
在家目录中,默认创建一个文件夹的权限是775
在根目录中,默认创建一个文件的权限是755
89)修改权限
# 方法一
chmod + 权限 + 文件名
chmod 777 111.py
chmod 777 ceshi100
# 递归更改文件夹中所有文件的权限(将文件夹下的所有内容全部同时修改权限,包括文件夹本身)
chmod -R 777 ceshi1200
# 方法二
u: 所属主
g: 所属组
o: 其他
chmod u-x,g-w,o-r 1.py #表示含义 所属主去掉x(执行)权限 所属组去掉w(写,修改)权限 其他去掉r(读)权限
chmod u=wx,g=x,o=r 1.py #表示含义 所属主只有w(写,修改)x(执行)权限 所属组只有x(执行)权限 其他只有r(读)权限
90)文件和目录权限的不同含义
=>对于目录来讲
r 是否呈现里面的文件
w 是否可以在里面创建文件或文件夹
x cd 切不进来 不能访问这个目录
=>对于文件来讲
r 可以看到文件内容
w 可以更改删除文件及内容
x 是否可以执行这个文件 ./abc.sh (shell)
91)添加账号与密码
sudo useradd a01 # 添加账号
sudo passwd a01 # 添加密码
sudo su a01 # 切换账号
exit # 退出当前账号
sudo userdel a01 # 删除具体账号
92)查找文件与内容
关注点:
关注文件或者文件夹的时候,不光要看他的权限,也要看他的类型;
只能通过权限位第一位来判断,不能单纯通过名字来判断
# find -name 用于查找文件
find ~/ -name ceshi200 或者 find ~ -name ceshi200 按照具体名字进行搜索
# find -iname 用于查找文件
find ~/ -iname ceshi200 或者 find ~ -iname ceshi200 忽略名字大小写进行查询
passwd 专门存放用户账号
shadow 专门存放用户密码
# 名字故意这么起 障眼法
# grep 用于查询具体的字符串内容
grep 'root' passwd #在passwd文件 查询具体的字符串在
grep -i 'root' passwd #忽略大小写搜索内容
grep -v 'root' passwd #反向搜索除了root字符串外的所有内容
93)移动硬盘 与 U盘的挂载和卸载
移动硬盘 与 U盘的资源 都是放在根目录下的 mnt 目录下
在 mnt 目录下创建一个 cdrom目录用于挂载外部资源
# 挂载
/dev/sda1 * 2048 37750783 37748736 18G 83 Linux (主分区)
/dev/sda2 37752830 41940991 4188162 2G 5 扩展 (扩展分区)
/dev/sda5 37752832 41940991 4188160 2G 82 Linux 交换 / Solari (交换分区)
oom 内存溢出死机 linux不会出现,因为交换分区的存在,可以临时作为内存空间进行调度,如果负载过大,默认杀死后台占空间资源最大的进程,以节省资源
sudo fdisk -l 查看设备名
mount 设备路径 哪个目录 # 理解为将外部设备路径移动到哪个文件下
sudo mount /dev/sdb /mnt/cdro #/dev/sdb(设备路径)
# 取消挂载
sudo umount /mnt/cdro # /mnt/cdro 具体挂载的目录
表示移动设备将不在windows中显示
94)共享文件(都是放在根目录下/mnt/hgfs中)Linux实时共享
点击虚拟机/设置/选项/共享文件夹 然后将具体的windows中文件目录填写即可
#将安装包 复制到家目录中
# 1. 家目录中 mkdir mysoft 创建一个mysoft文件夹
# 2. cp -a /mnt/hgfs/python_gx/pycharm-community-2020.1.3.tar.gz ~/mysoft/ 进行复制操作
# 3. 在unbantu 页面中Home 中 找到压缩包 右键提取到此处
# 4. 打开解压好的文件目录 进入到bin目录中 右键在终端打开 输入 ./pycharm.sh 进行安装
# 5. 在home/yukai/ 创建一个项目文件夹 以后项目的代码都在这里
'''
在linux中写代码太卡的情况
在共享文件中创建一个python文件然后 拖到linux中python编辑器中 在windows中进行编写 linux中运行
'''
95)python内置函数
'''
# 绝对值
print(abs(-1))
print(abs(100))
# round四舍五入(n.5的前提下 奇进偶不进)
print(round(6.5)) # 6
print(round(6.51)) # 7
print(round(5.5)) # 6
# sum 计算一个序列的和
lst = [1,2,3,456,5]
print(sum(lst)) #467
# max 获取一个序列里面最大值
lst = [1,2,3,456,5]
print(max(lst)) #456
print(min(lst)) #1
# max / min 进阶用法 return 的内容是数字 按照数字进行比较
tup = (('网卡名',18),('卡酷动画',500),('dsfsdf',-1))
def fn(n):
print(n)
return n[-1]
res = min(tup,key=fn)
res = max(tup,key=fn)
print(res)
####重点是传入的参数打印是什么 那么最后返回的打印结果就是什么
dic = {'杨颖':100,'王祖蓝':200,'孟繁蔚':-1000}
def fn(n):
return n
res = min(dic,key=fn)
res = max(dic,key=fn)
print(res)
# pow 计算某个数值的x次幂
# 如果是三个参数,前两个运算的结果和第三个参数取余
print(pow(2,3)) #8
print(pow(2,3,7))#1
print(pow(2,3,4))#0
print(pow(2,3,5))#3
# range 产生指定范围数据的可迭代对象
# 一个参数
for i in range(3):
print(i) # 0 1 2
# 二个参数(左闭右开)
for i in range(3,8):
print(i) # 3 4 5 6 7
# 三个参数
for i in range(1,9,5):
print(i) # 1 6
# 逆向操作
for i in range(9,1,-3):
print(i) # 9 6 3
# bin(10进制转二进制) oct(10进制转八进制) hex(10进制转16进制)
print(bin(8)) # 0b1000
print(oct(8)) # 0o10
print(hex(16)) # 0x10
# char(将ASCII编码转换为字符) ord(将字符转换为ASCII编码)
print(chr(65)) # A
print(ord('A'))# 65
# eval(将字符串当作python代码执行) exec(将字符串当作python代码执行==>功能更加强大)
msg = 'print(123)'
eval(msg) # 123
num = 'a=3'
exec(num)
print(a) #3
msg = '''
for i in range(10):
print(i)
'''
exec(msg) # 打印 1 - 9
# repr 不转义字符输出字符串(不输出换行等效果)
msg = 'klkl\ndsfsdf\13246'
print(repr(msg)) #不会进行换行操作
# hash 生成哈希值 用于文件校验
with open('ceshi1.py,mode='r',encoding='utf-8') as fl1,open('ceshi1.py,mode='r',encoding='utf-8') as fl2:
res1 = fl1.read()
res1 = fl2.read()
if hash(res1) == hash(res2):
print('文件校验成功')
else:
print('文件校验失败')
'''
96)模块相关
- 数学模块
import math
# ceil() 向上取整
res = math.ceil(3.01) # 4
res = math.ceil(-3.01)# -3
# floor() 向下取整
res1 = math.floor(3.99) #3
res2 = math.floor(-3.99)#-4
#pow() 计算一个数值的N次方(结果为浮点数) 只有两个参数
res = math.pow(2,3) # 8.0
#sqrt()开平方运算(结果浮点数)
res = math.sqrt(9) #3.0
# fabs() 绝对值(结果浮点数)
res = math.fabs(-1) #1.0
#modf() 将一个数值拆分为整数和小数(结果浮点数)
res = math.modf(3.897) # (0.8969999999999998, 3.0)
#copysign() 将第二个参数的正负号 拷贝给第一个参数(第一个参数无论是正负,都以拷贝的符号为准)(结果浮点数)
res = math.copysign(-12,-9.1)
print(res) # -12.0
#fsum() 将一个容器数据中的数据进行求和运算(结果浮点数)
lst = [1,2,3,4,5]
res = math.fsum(lst)
print(res) # 15.0
# 圆周率常数 pi
res = math.pi
print(res) # 3.141592653589793
- 随机模块
import random
# random() 获取随机 0 - 1 之间的小数(左闭右开)
res = random.random()
print(res)
#randrange() 随机获取指定范围内的整数(包含开始值,不包含结束值,间隔值)
# 一个参数
res = random.randrange(3)
print(res) # 0 1 2
# 二个参数
res = random.randrange(3,6)
print(res) # 3 4 5
# 三个参数
res = random.randrange(1,9,4)
print(res) # 1 5
res = random.randrange(7,3,-1)
print(res) # 7 6 5 4
# randint() 随机产生指定范围内的随机整数
res = random.randint(1,3)
print(res) # 1 2 3
# uniform() 获取指定范围内的随机小数(左闭右开)
res = random.uniform(0,2)
print(res) # 大于等于0 小于2
res = random.uniform(2,0)
print(res) # 大于于0 小于等于2
# choice() 随机获取序列中的值(多选一)
lst = ['顺凯西','卡卡西','选我明儿你','须臾间','偶然间']
res = random.choice(lst)
print(res)
# sample() 随机获取序列中的值(多选多) 返回值为列表
tup = ('顺凯西','卡卡西','选我明儿你','须臾间','偶然间')
res = random.sample(tup,3)
print(res) # ['选我明儿你', '须臾间', '偶然间']
# shuffle() 随机打乱(原序列的值)
lst = ['顺凯西','卡卡西','选我明儿你','须臾间','偶然间']
random.shuffle(lst)
print(lst) # ['卡卡西', '偶然间', '顺凯西', '须臾间', '选我明儿你']
# 验证码效果
# 验证码里面有大写字母 65 -90
# 小写字母 97 - 122
# 数字 0 - 9
def yanzhengma():
value = ''
for i in range(4):
b_c = chr(random.randrange(65,91)) # 大写字母
s_c = chr(random.randrange(97,123)) # 小写字母
num = str(random.randrange(10)) # 数字
lst = [b_c,s_c,num]
value += random.choice(lst) # 随机抽取一个元素 抽取4次
return value
print(yanzhengma())
- 序列化模块(主要用于存储,数据永久化)
import pickle
'''
序列化: 把不能够直接存储在文件中的数据变得可存储(封印九尾)
反序列化: 把存储在文件中的数据拿出来恢复成原来的数据类型(解开封印)
'''
# dumps 把任意对象序列化成一个bytes(字节流)
lst = [1,2,3]
res = pickle.dumps(lst)
print(res,type(res)) # b'\x80\x03]q\x00(K\x01K\x02K\x03e.' <class 'bytes'>
# loads 把任意bytes反序列化成原来数据
res2 = pickle.loads(res)
print(res2,type(res2)) # [1, 2, 3] <class 'list'>
# dump 把对象序列化后写入到 file-like object(即文件对象)
lst = [1,2,3]
with open('lianxi1.txt',mode='wb') as fp:
pickle.dump(lst,fp)
#load 把file-like object(即文件对象)中的内容拿出来,反序列化成原来数据
with open('lianxi1.txt',mode='rb') as fp:
res2 = pickle.lod(fp)
print(res2,type(res2))
- json 序列化/反序列化模块
import json
'''
json格式的数据, 所有的变成语言都能识别,本身是字符串
类型有要求: int float bool str list tuple dict None
json 主要应用于传输数据, 序列化成字符串
pickle 主要应用于存储数据, 序列化成二进制字节流
'''
# json 基本用法
# json => dumps 和 loads
'''ensure_ascii=False 显示中文 sort_keys=True 按键排序'''
dic = {'name':'娃娃鱼','age':18,'family':['爸爸','妈妈','老婆','妹妹']}
res = json.dumps(dic,ensure_ascii=False,sort_keys=True)
print(res,type(res)) # {"age": 18, "family": ["爸爸", "妈妈", "老婆", "妹妹"], "name": "娃娃鱼"} <class 'str'>
dic = json.loads(res)
print(dic,type(dic)) # {'family': ['爸爸', '妈妈', '老婆', '妹妹'], 'name': '娃娃鱼', 'age': 18} <class 'dict'>
# json => dump 和 load
with open('lianxi3.pkl',mode='w',encoding='utf-8') as fp:
json.dump(dic,fp,ensure_ascii=False) #将字典以str格式写入lianxi3.pkl
with open('lianxi3.pkl',mode='r',encoding='utf-8') as fp:
dic = json.load(fp) # 将文件对象反序列化 得到原数据
print(dic,type(dic)) # {'family': ['爸爸', '妈妈', '老婆', '妹妹'], 'name': '娃娃鱼', 'age': 18} <class 'dict'>
# ### json 和 pickle 之间的区别
# json 连续 dump 数据,但是不能连续 load数据,是一次性获取所有内容进行反序列化
dic1 = {'a':1,'b':2}
dic2 = {'c':3,'d':4}
with open('lianxi6.json',mode='w',encoding='utf-8') as fp:
json.dump(dic1,fp)
fp.write('\n')
json.dump(dic2,fp)
fp.write('\n')
# 不能连续load,只可以一次行获取所有数据, error
'''
with open('lianxi6.json',mode='r',encoding='utf-8') as fp:
dic = json.load(fp) 此处会报错 不能不能连续 load数据
'''
# 解决方法 loads
with open('lianxi6.json',mode='r',encoding='utf-8') as fp:
for lin in fp:
dic = json.loads(line)
print(dic)
#{'a': 1, 'b': 2} <class 'dict'>
#{'c': 3, 'd': 4} <class 'dict'>
# 2.pickle 可以连续dump数据 同时可以连续load 数据
import pickle
# 方法1
dic1 = {'a':1,'b':2}
dic2 = {'c':3,'d':4}
# pickle => dump 和 load
# pickle 连续 dump 数据
with open('lainxi5.json',mode='wb') as fp:
pickle.dump(dic1,fp)
pickle.dump(dic2,fp)
with open('lainxi5.json',mode='rb') as fp:
dic1 = pickle.load(fp)
dic2 = pickle.load(fp)
print(dic1) # {'a': 1, 'b': 2}
print(dic2) # {'c': 3, 'd': 4}
# 方法2
'''
try .. except .. 把有可能报错的代码放到try代码块中,如果出现异常执行except分支,来抑制报错
'''
try:
with open('lainxi5.json',mode='rb') as fp:
while 1:
dic = pickle.load(fp)
print(dic)
# {'a': 1, 'b': 2}
# {'c': 3, 'd': 4}
except:
pass
# json 和 pickle 两个模块的区别
1. json序列化值得数据类型是str,所有编程语言都识别,
但是仅限于(int float bool)(str list tuple dict None)
json不能连续load,只能一次性拿出所有数据
2. pickle序列化之后的数据类型是bytes,用于数据存储
所有数据类型都可转化,但仅限于python之间的存储传输,
pickle可以连续load,多套数据放到同一个文件中
- 时间模块
# ### time 时间模块
import time
# time() 获取本地时间戳
res = time.time()
print(res)
#localtime() 获取本地时间元组 (参数是时间戳,默认当前)
# 默认当前时间元组
ttp = time.localtime()
print(ttp) #(tm_year=2023, tm_mon=3, tm_mday=21, tm_hour=10, tm_min=58, tm_sec=8, tm_wday=1, tm_yday=80, tm_isdst=0)
# 指定具体的时间戳获取时间元组
ttp = time.localtime(1601360000)
print(ttp)
# mktime() 通过时间元组获取时间戳 (参数是时间元组)
res1 = time.mktime(ttp)
print(res1) # 1601360000.0
# ctime() 获取本地时间字符串(参数是时间戳,默认当前)
# 默认当前时间戳
res = time.ctime()
print(res) # Tue Mar 21 11:09:05 2023
# 指定具体的时间戳
res = time.ctime(1601360000)
print(res) # Tue Sep 29 14:13:20 2020
# asctime() 通过实践元组获取时间字符串(参数是时间元组)有瑕疵(了解)
'''只能通过手动的形式来调星期'''
ttp = (2020,9,29,16,48,30,0,0,0)
res = time.asctime(ttp)
print(res)
# sleep() 程序睡眠等待(延时器)
time.sleep(3)
print('我睡醒了') # 3秒后执行
# strftime() 格式化时间字符串(格式化字符串,时间元组)
'''linux支持中文 windows不支持'''
strvar = time.strftime('%Y-%m-%d %H:%M:%S')
print(strvar) # 2023-03-21 12:20:35
strvar = time.strftime('%Y-%m-%d %H:%M:%S 是帅哥的生日')
print(strvar) # 2023-03-21 12:22:20 是帅哥的生日
res = time.localtime(12345678911)
print(res)
strvar = time.strftime('%Y-%m-%d %H:%M:%S',(res))
print(strvar) # 2361-03-22 03:15:11
# strptime() 将时间字符串通过指定格式提取到时间元组中(时间字符串,格式化字符串)
'''注意: 替换时间格式化标签时,必须严丝合缝,不能随便加空格或特殊字符'''
ttp = time.strptime('2023年3月21号了','%Y年%m月%d号了')
print(ttp) # (tm_year=2023, tm_mon=3, tm_mday=21, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=1, tm_yday=80, tm_isdst=-1)
'''
strftime : 把时间元组 转换为 字符串
strptime : 把字符串 转换为 时间元组
'''
# perf_counter() 用于计算程序运行的时间(了解)
starttime = time.perf_counter()
for i in range(10000000):
pass
endtime = time.perf_counter()
print(endtime - starttime) # 0.7231218
- zipfile 压缩模块
import zipfile
# (1) 压缩文件
'''zipfile.ZIP_DEFLATED 压缩模式'''
# 创建压缩包
zf = zipfile.ZipFile('ceshi111.zip','w',zipfile.ZIP_DEFLATED)
# 写入文件
'''e=write(路径,别名)'''
zf.write('/bin/uname','uname')
zf.write('/bin/ip','ip')
zf.write('/bin/kill','temp/kill') # 可以临时创建temp文件夹存放
# 关闭文件释放资源
zf.close()
# (2) 解压文件
zf = zipfile.ZipFile('ceshi111.zip','r')
# 解压单个文件
zf.extract('uname','ceshi111') # uname具体的文件名 ceshi111解压到当前文件夹
# 解压全部文件
zf.extractall('ceshi222') # 全部解压到 ceshi222文件夹
zf.close()
# (3) 追加文件
zf = zipfile.ZipFile('ceshi111.zip','a',zipfile.ZIP_DEFLATED)
zf.write('/bin/vdir','vdir')
zf.close()
# 用with 简写
with zipfile.ZipFile('ceshi111.zip','a',zipfile.ZIP_DEFLATED) as zf:
zf.write('/bin/vdir','vdir')
# (4) 查看文件
with zipfile.ZipFile('ceshi111.zip','a',zipfile.ZIP_DEFLATED) as zf:
lst = zf.namelist()
print(lst) # ['uname', 'ip', 'temp/kill', 'vdir']
- os模块
import os
# system() 在python中执行系统命令
os.system('ifconfig') # linux
os.system('ipconfig') # windows
# open() 执行系统命令返回对象,通过read方法读取字符串
obj = os.popen('ipconfig')
print(obj.read())
# listdir() 获取当前同级别文件夹中所有内容的名称列表
lst = os.listdir()
print(lst) # ['ceshi111', 'ceshi111.zip', 'ceshi222', 'lianxi01.py']
# getcwd() 获取当前文件所在的默认路径
# 路径
res = os.getcwd()
print(res)
# 路径加别名
print(__file__) # /mnt/hgfs/PycharmProjects/pythonProject1/pythoncode/lianxi01.py
# chdir() 修改当前文件工作的默认路径
os.chdir('/home/yukai') # 跳转到此路径 对当前路径进行操作
os.system('touch 888.txt') # 新建文件
os.system('rm -rf 888.txt')# 删除文件
# environ 获取或修改环境变量
os.environ['PATH'] += ':/home/yukai' # 注意必须以 :开头 文件的路径在linux终端输入pwd查看
os.system('yukai') # 执行文件
- os 模块属性
import os
# name 判断操作系统
print(os.name) # linux(posix) windows(nt)
# sep 获取路径分割符号 linux,mac -> / window -> \
print(os.sep)
# linesep 获取系统的换行符号 linux,mac -> \n window->\r\n 或 \n
print(repr(os.linesep))
- os模块(文件操作,新建和删除)
import os
# mknod 创建文件 默认创建在同一目录下
os.chdir('/home/yukai/mysoft') # 更改工作路径
os.mknod('888.txt')
# remove 删除文件
os.remove('888.txt')
# mkdir 创建目录(文件夹)
os.mkdir('tiantian')
# rmdir 删除目录(文件夹)
os.rmdir('tiantian')
# rename 对文件,目录重命名
os.rename('yukai','wawayu')
# makedirs 递归创建文件夹
os.makedirs('a/b/c/d/e/f')
# removedirs 递归删除文件夹(所有文件夹内容必须为空 ==> 有内容先删除)
os.removedirs('a/b/c/d/e/f')
- shutil模块(复制文件和文件夹)
import shutil
# copyfileobj(fsrc,fdst[,length=16*1024]) 复制文件(length的单位是字符(表示一次读多少字符/字节))
fp_src = open('wawayu',mode='r',encoding='utf-8')
fp_dst = open('4.txt',mode='w',encoding='utf-8')
shutil. copyfileobj(fp_src,fp_dst) # 把fp_src 复制到 fp_dst
# copyfile(src,dst) 单纯复制文件内容 底层调用了 copyfileobj
shutil.copyfile('4.txt','5.txt')
# copymode(src,dst) 单纯的复制文件权限,不包括内容(必须有两个文件才可以,不会默认创建)
shutil.copymode('4.txt','5.txt')
# copystat(src,dst) 复制所有状态信息,包括权限,组,用户,修改时间等,不包括内容
shutil.copystat('4.txt','5.txt')
# copy(src,dst) 复制文件权限和内容
shutil.copy('5.txt','6.txt')
# copy2(src,dst) 复制文件权限和内容,还包括权限组,用户,修改时间等
shutil.copy2('5.txt','7.txt')
# copytree(src,dst) 拷贝文件夹里所有内容(递归拷贝)
shutil.copytree('lianxi','lainxi2')
# rmtree(path) 三处当前文件夹及其中所有内容(递归删除)
shutil.rmtree('lainxi2')
# move 剪切文件
shutil.move('4.txt','lianxi')
shutil.move('5.txt','lianxi/888.py') # 可以改名
- os.path 路径模块
import os
pathvar = __file__ # 获取当前文件路径
# basename() 返回文件名部分
res = os.path.basename(pathvar)
print(res) # lianxi01.py
# dirname() 返回路径部分
res = os.path.dirname(pathvar)
print(res) # /mnt/hgfs/PycharmProjects/pythonProject1/pythoncode
# split() 将路径拆分成文件部分和路径部分,组成一个元组
print(os.path.split(pathvar)) # ('/mnt/hgfs/PycharmProjects/pythonProject1/pythoncode', 'lianxi01.py')
# join() 将多个路径和文件组成新的路径 可以自动通过不同的系统加不同的斜杠
path1 = 'home'
path2 = 'yukai'
path3 = 'mywork'
pathvar = path1 + os.sep + path2 + os.se +path3
print(pathvar) # home/yukai/mywork
'''用join改造'''
path_new = os.path.join(path1,path2,path3)
print(path_new) # home/yukai/mywork
# splitext() 将路径分割为后缀和其他部分
pathvar = '/hone/yukai/mywork/ceshi.py'
print(os.path.splitext(pathvar)) # ('/hone/yukai/mywork/ceshi', '.py')
print(pathvar.split('.')[-1]) # py
# getsize() 只可以获取文件的大小(不可以文件夹)
res = os.path.getsize(__file__)
print(res) # 2060 返回的是字节
# islink() 检测路径是否是一个链接
res = os.path.islink('/home/yukai/lianxi2')
print(res) # True
# isdir() 检测路径是否是一个文件夹
res = os.path.isdir('/home/yukai/lianxi2')
print(res) # True
# isfile() 检测路径是否是一个文件
res = os.path.isfile('/home/yukai/lianxi2/1.js')
print(res) # True
# getctiome() windows文件的创建时间 linux权限改动的时间(返回时间戳)
import time
res = os.path.getctime('/home/yukai/mywork/1.js')
print(time.ctime(res))
# getmtime() 获取文件最后一次修改时间(返回时间戳)
res = os.path.getctime('/home/yukai/mywork/1.js')
print(time.ctime(res))
# getatime() 获取文件最后一次访问时间(返回时间戳)
res = os.path.getctime('/home/yukai/mywork/1.js')
print(time.ctime(res))
# exists() 检测指定的路径是否存在
res = os.path.exists('/home/yukai/mywork/1.js')
print(res) # True
# isabs() 检测一个路径是否是绝对路径
res = os.path.isabs('1.js')
print(res) # False
# abspath() 将相对路径转化为绝对路径
res = os.path.abspath('1.js')
print(res) # /home/yukai/mywork/1.js
pathvar = '1.js'
if not os.path.isabs(pathvar):
abs_path = os.path.abspath('1.js')
print(abs_path) # /home/yukai/mywork/1.js
-
tarfile压缩模块
-
压缩文件
import tarfile # 单纯打包不压缩 tf = tarfile.open('ceshi322_0.tar','w',encoding='utf-8') # 写入文件 '''add(路径,别名)''' tf.add('/bin/cp','cp') tf.add('/bin/dd','dd') tf.add('/bin/df','df') # 关闭文件 tf.close() # 使用gz算法压缩 tf = tarfile.open('ceshi322_1.tar.gz','w:gz',encoding='utf-8') # 写入文件 '''add(路径,别名)''' tf.add('/bin/cp','cp') tf.add('/bin/dd','dd') tf.add('/bin/df','df') # 关闭文件 tf.close() # 使用bz2算法压缩(最小) tf = tarfile.open('ceshi322_2.tar.bz2','w:bz2',encoding='utf-8') # 写入文件 '''add(路径,别名)''' tf.add('/bin/cp','cp') tf.add('/bin/dd','dd') tf.add('/bin/df','df') # 关闭文件 tf.close() -
解压文件
# 单个解压 tf = tarfile.open('ceshi322_1.tar.gz','r',encoding='utf-8') '''extract(文件,路径) 解压单个文件''' tf.extract('cp','ceshi001') # 将cp文件 解压到 ceshi001文件夹 # 解压所有 tf.extractall('ceshi_all') # 将所有文件 解压到 ceshi_all文件夹 -
追加文件
'''对已经压缩过得包文件无法进行追加,只有没压缩过得包才可以直接追加''' tf = tarfile.open('ceshi322_0.tar','a',encoding='utf-8') tf.add('/bin/znew','tmp/znew') tf.close() # 用with 进行改造 with tarfile.open('ceshi322_0.tar','a',encoding='utf-8') as tf: tf.add('/bin/znew', 'tmp/znew') -
查看文件
with tarfile.open('ceshi322_1.tar.gz','r',encoding='utf-8') as tf: lst = tf.getnames() print(lst) # ['cp', 'dd', 'df']
-
97)正则表达式(不会写的地方,无脑.*?)
-
匹配单个字符
import re '''lst = re.findall(正则表达式,字符串)''' # \d 匹配数字 starvar = 'asdasd145#$$T%' lst = re.findall('\d',starvar) print(lst) # ['1', '4', '5'] # \D 匹配非数字 starvar = '231321sdfsdfasd' lst = re.findall('\D',starvar) print(lst) # ['s', 'd', 'f', 's', 'd', 'f', 'a', 's', 'd'] # \w 匹配字母或数字或下划线 (正则函数中,支持中文的匹配) starvar = 'dsf132_!@#$$%^&*哈喽' lst = re.findall('\w',starvar) print(lst) # ['d', 's', 'f', '1', '3', '2', '_', '哈', '喽'] # \W 匹配非字母或数字或下划线 starvar = 'dsf132_!@#$$%^&*哈喽' lst = re.findall('\W',starvar) print(lst) # ['!', '@', '#', '$', '$', '%', '^', '&', '*'] # \n 匹配一个换行符 strvar =''' 你好拉开圣,\t 诞 节分厘卡就, 微软微软, 二体问题 ''' lst = re.findall(r'\n',strvar) print(lst) # ['\n', '\n'] # \t 匹配一个制表符 lst = re.findall(r'\t',strvar) print(lst) -
字符组 [ ] 匹配出字符组当中列举的字符 只能从中选择一个不是多个
'''解读: a[abc]b a和b固定位置 中间必须有[]中的任意一项 才满足匹配规则''' print(re.findall('a[abc]b','aab abb acb adb')) # ['aab', 'abb', 'acb'] print(re.findall('a[0123456789]b','a1b a2b a3b adb ayb')) # ['a1b', 'a2b', 'a3b'] # 优化写法 print(re.findall('a[0-9]b','a1b a2b a3b adb ayb')) # ['a1b', 'a2b', 'a3b'] print(re.findall('a[abcdefg]b','a1b a2b a3b acb ayb adb')) # ['acb', 'adb'] # 优化写法 print(re.findall('a[a-g]b','a1b a2b a3b acb ayb adb')) # ['acb', 'adb'] # 匹配所有字母和数字 print(re.findall('a[a-zA-Z0-9]b','a1b a2b a3b acb ayb adb')) # print(re.findall('a[a-zA-Z0-9]b','a1b a2b a3b acb ayb adb')) '''此处注意: aqba1b不是全部返回 而是满足一个返回一个''' print(re.findall('a[a-zA-Z0-9]b','a-b aab aAb aWb aqba1b')) # ['aab', 'aAb', 'aWb', 'aqb', 'a1b'] print(re.findall('a[0-9][*#/]b','a1/b a2b a29b a56b a456b')) # ['a1/b'] '''尖括号表示 除了得意思''' print(re.findall('a[^-+*/]b','a%b ccaa*bda&bd')) # ['a%b', 'a&b'] # 匹配 ^ - 时 需要前面加上 \进行转义 starvar = 'a^c a-c' lst = re.findall(r'a[\^\-]c',starvar) print(lst) # ['a^c', 'a-c'] # 注意点: 为了防止转义,在正则表达式中或者要匹配得字符串 无脑加r strvar = r'a\n' lst = re.findall(r'a\\n',strvar) print(lst) # ['a\\n'] 显示是这样显示 实际取值是 a\n print(lst[0]) # a\n -
匹配多个字符
-
? 匹配0个或者1个
'''匹配0个a或者1个a 不能两个a挨在一起''' print(re.findall('a?b','abbzab abb aab')) # ['ab', 'b', 'ab', 'ab', 'b', 'ab'] -
+匹配1个或者多个
''' + 匹配1个或者多个a''' print(re.findall('a+b','b ab aaaaaab abb')) # ['ab', 'aaaaaab', 'ab'] -
*匹配0个或者多个
''' * 匹配0个或者多个a''' print(re.findall('a*b','b ab aaaaaab abbbbbbb')) ['b', 'ab', 'aaaaaab', 'ab', 'b', 'b', 'b', 'b', 'b', 'b'] -
{m,n} 匹配m个至n个
# 1 <= a <= 3 print(re.findall('a{1,3}b','aab ab aab abbb aaz aabb')) # ['aab', 'ab', 'aab', 'ab', 'aab'] # {2} 代表必须匹配2个a print(re.findall('a{2}b','aab ab aab abbb aaz aabb')) # ['aab', 'aab', 'aab'] # {2,} 代笔至少匹配2个a print(re.findall('a{2,}b','aaab ab aab abbb aaz aabb'))# ['aaab', 'aab', 'aab']
-
-
贪婪模式 和 非贪婪模式
- 贪婪模式
''' 贪婪模式 : 默认向更多次匹配 (回溯算法) 非贪婪匹配: 默认向更少次匹配 回溯算法: 从左向右进行匹配, 直到找到最后一个,再也没有了,回头,将上一个找到得结果赶回 . 除了\n,匹配所有字符 ''' import re # 贪婪模式 strvar = '罗非鱼和罗志祥和罗三泡13211子84564子' lst = re.findall('罗.',strvar) print(lst) # ['罗非', '罗志', '罗三'] lst = re.findall('罗.?',strvar) print(lst) # ['罗非', '罗志', '罗三'] lst = re.findall('罗.+',strvar) print(lst) # ['罗非鱼和罗志祥和罗三泡13211子84564子'] lst = re.findall('罗.*',strvar) print(lst) # ['罗非鱼和罗志祥和罗三泡13211子84564子'] lst = re.findall('罗.{1,20}',strvar) print(lst) # ['罗非鱼和罗志祥和罗三泡13211子8456'] lst = re.findall('罗.*子',strvar) print(lst) # ['罗非鱼和罗志祥和罗三泡13211子84564子']-
非贪婪模式
import re # 贪婪模式 strvar = '罗非鱼和罗志祥和罗三泡13211子84564子' lst = re.findall('罗.??',strvar) print(lst) # ['罗', '罗', '罗'] lst = re.findall('罗.+?',strvar) print(lst) # ['罗非', '罗志', '罗三'] lst = re.findall('罗.*?',strvar) print(lst) # ['罗', '罗', '罗'] lst = re.findall('罗.{1,20}?',strvar) print(lst) # ['罗非', '罗志', '罗三'] lst = re.findall('罗.*?子',strvar) print(lst) # ['罗非鱼和罗志祥和罗三泡13211子']
-
边界符
'''
\b 本身是转义字符(退格) 退到光标上一位
\b 在正则中表示边界符得意思
'word'
卡住左边界:\bw
卡住有边界:d\b
'''
# 右边界
import re
strvar = 'word old fuck'
lst = re.findall(r'd\b',strvar)
print(lst) # ['d', 'd']
lst = re.findall(r'.*d\b',strvar)
print(lst) # ['word ']
lst = re.findall(r'.*?d\b',strvar) # 遇见一个以d结尾的 就返回一个值
print(lst) # ['word', ' old']
==================================================>
# 左边界
strvar = 'word old fuck'
lst = re.findall(r'\bw',strvar)
print(lst) # ['w']
lst = re.findall(r'\bw.*',strvar)
print(lst) # ['word old fuck']
lst = re.findall(r'\bw.*?',strvar)
print(lst) # ['w']
lst = re.findall(r'\bw.*? ',strvar)
print(lst) # ['word ']
lst = re.findall(r'\bw\S*',strvar)
print(lst) # ['word']
-
^ $ 的使用
import re ''' ^ 写在字符串的开头,表达必须以某个字符开头 $ 写在字符串的结尾,表达必须以某个字符结尾 当使用了 ^ & 代表要把字符串当成一个整体 ''' strvar = '大哥大嫂大爷' print(re.findall('大.',strvar)) # ['大哥', '大嫂', '大爷'] print(re.findall('^大.',strvar)) # ['大哥'] print(re.findall('大.$',strvar)) # ['大爷'] print(re.findall('^大.$',strvar)) # [] print(re.findall('^大.*?$',strvar)) # ['大哥大嫂大爷'] print(re.findall('^大.*?大$',strvar)) # [] print(re.findall('^大.*?爷$',strvar)) # ['大哥大嫂大爷'] -
匹配分组
# ### 匹配分组 ()表达整体 import re # (1)分组 print(re.findall('.*?_good','wusir_good alex_good secret男_good')) print(re.findall('(.*?)_good','wusir_good alex_good secret男_good')) # (?:) 代表不优先显示分组里面的内容,只是显示正常匹配到的内容 print(re.findall('(?:.*?)_good','wusir_good alex_good secret男_good')) # (2) | 代表或 , a|b 匹配字符a 或者 匹配字符b . strvar = "abceab" lst = re.findall("a|b",strvar) print(lst) # 注意点:把不容易匹配到的内容放到前面,把容易匹配到的内容放到后面 strvar = "abcdeabc234f" lst = re.findall("abcd|abc",strvar) print(lst) # (3) 练习 """ . 可以匹配任意的字符,除了\n \. 对.进行转义,表达.这个字符本身. """ # 匹配小数 strvar = "3.... ....4 .3 ...3 1.3 9.89 10" lst = re.findall(r"\d+\.\d+",strvar) print(lst) # 匹配小数和整数 lst = re.findall(r"\d+\.\d+|\d+",strvar) print(lst) # 使用分组改造 '''findall优先显示括号里的内容,需要加上?:取消哦优先显示,按照匹配到的内容显示''' lst = re.findall(r"\d+(?:\.\d+)?",strvar) print(lst) # 匹配135或171的手机号 strvar = "13566668888 17366669999 17135178392" lst = re.findall(r"(?:135|171)\d{8}",strvar) print(lst) # 优化,只能匹配出一个手机号 strvar = "13566668888" lst = re.findall(r"^(?:135|171)\d{8}$",strvar) print(lst) obj = re.search(r"^(135|171)\d{8}$",strvar) print(obj) print(obj.group()) print(obj.groups()) # 匹配www.baidu.com 或者 www.oldboy.com """ findall : 从左到右,匹配出所有的内容,返回到列表 问题是,匹配到的字符串和分组的内容不能同时显示; search : 从左到右,匹配到一组内容就直接返回,返回的是对象 优点是,可以让匹配到的内容和分组里的内容同时显示; 匹配不到内容时,返回的是None obj.group() : 获取匹配到的内容 obj.groups(): 获取分组里面的内容 """ # findall strvar = "www.baidu.com www.oldboy.com www.wangwen.com" lst = re.findall(r"(?:www)\.(?:baidu|oldboy)\.(?:com)",strvar) print(lst) # search strvar = "www.baidu.com www.oldboy.com www.wangwen.com" obj = re.search(r"(www)\.(baidu|oldboy)\.(com)",strvar) print(obj) # 获取匹配到的内容 print(obj.group()) # 获取分组里面的内容 (推荐) print(obj.groups()) # 方法二,可以直接通过下标1来获取分组里面的第一个内容; print(obj.group(1)) print(obj.group(2)) print(obj.group(3)) # search 练习 : 计算"5*6-7/3"结果 匹配 5*6 或者 7/3 strvar = "5*6-7/3" # strvar = "www.baidu.com www.oldboy.com www.wangwen.com" obj = re.search(r"\d+[*/]\d+",strvar) res1 = obj.group() print(res1 , type(res1)) # 5*6 <class 'str'> # 计算结果 a,b = res1.split("*") res2 = int(a) * int(b) print(res2) # 把30替换回原来的字符串中 strvar = strvar.replace(res1,str(res2)) print(strvar) # 以此类推 ...
98)反向引用 命名分组
# ### 反向引用
import re
strvar = "<div>明天又要休息了</div>"
obj = re.search("<(.*?)>(.*?)<(.*?)>",strvar)
print(obj)
# 获取匹配到的内容
res1 = obj.group()
print(res1)
# 获取分组里的内容
res2 = obj.groups()
print(res2)
# 反向引用的语法 \1把第一个括号里面匹配到的内容在引用一次
obj = re.search(r"<(.*?)>(.*?)</\1>",strvar)
print(obj)
print(obj.group())
print(obj.groups())
strvar = " z3d4pzd a1b2cab "
obj = re.search(r"(.*?)\d(.*?)\d(.*?)\1\2",strvar)
print(obj)
print(obj.group())
print(obj.groups())
# ### 命名分组
"""
3) (?P<组名>正则表达式) 给这个组起一个名字
4) (?P=组名) 引用之前组的名字,把该组名匹配到的内容放到当前位置
"""
# 写法一
strvar = " z3d4pzd a1b2cab "
obj = re.search(r"(?P<tag1>.*?)\d(?P<tag2>.*?)\d(?P<tag3>.*?)\1\2",strvar)
print(obj)
print(obj.group())
# 写法二
strvar = " z3d4pzd a1b2cab "
obj = re.search(r"(?P<tag1>.*?)\d(?P<tag2>.*?)\d(?P<tag3>.*?)(?P=tag1)(?P=tag2)",strvar)
print(obj)
print(obj.group())
99)正则函数
# ### 正则函数
import re
# search 通过正则匹配出第一个对象返回,通过group取出对象中的值
strvar = "3+4 6*4"
obj = re.search(r"(\d+[+*]\d+)",strvar)
print(obj)
# 获取匹配到的内容
print(obj.group())
# 获取分组当中的内容 (返回元组)
print(obj.groups())
# match 验证用户输入内容 (了解)
"""search在正则表达式的前面加上^ 等价于 match ,其他用法上一模一样"""
strvar = "a17366668888"
strvar = "17366668888"
# obj = re.search(r"^\d+",strvar)
# obj = re.match(r"\d+",strvar)
# print(obj.group())
print(obj)
# split 切割
strvar = "alex|wusir_xboyww@risky"
lst = re.split("[|_@]",strvar)
print(lst)
strvar = "alex2341273894wusir234234xboyww11111risky"
lst = re.split("\d+",strvar)
print(lst)
# sub 替换
strvar = "alex|wusir_xboyww@risky"
"""
strvar = strvar.replace("|","&")
strvar = strvar.replace("_","&")
strvar = strvar.replace("@","&")
print(strvar)
"""
# sub(正则,替换的字符,原字符串[,替换的次数])
res = re.sub("[|_@]","&",strvar)
res = re.sub("[|_@]","&",strvar,1)
print(res)
# subn 替换 (用法上与sub相同,只是返回值不同)
res = re.subn("[|_@]","&",strvar)
res = re.subn("[|_@]","&",strvar,2)
print(res)
# res = re.sub("[|_@]","&",strvar)
# ('alex&wusir&xboyww@risky', 2)
# finditer 匹配字符串中相应内容,返回迭代器
"""返回的是迭代器,迭代器中包含了对象 对象.group来获取匹配到的值"""
from collections import Iterator, Iterable
strvar = "sdf23647fdgdfg()*()*23423423"
it = re.finditer("\d+",strvar)
print(isinstance(it,Iterator))
for obj in it:
print(obj.group())
# compile 指定一个统一的匹配规则
"""
正常情况下,正则表达式编译一次,执行一次
为了避免反复编译,节省时间空间,可以使用compile统一规则
编译一次,终身受益
"""
strvar = "asdfs234sdf234"
pattern = re.compile("\d+")
print("<===>")
obj = pattern.search(strvar)
print(obj.group())
lst = pattern.findall(strvar)
print(lst)
# 修饰符
# re.I 使匹配对大小写不敏感
strvar = "<h1>大标题</H1>"
pattern = re.compile("<h1>(.*?)</h1>" , flags=re.I)
obj = pattern.search(strvar)
print(obj.group())
# re.M 使每一行都能够单独匹配(多行匹配),影响 ^ 和 $
"""单行独立匹配,而不是整体匹配"""
strvar = """
<p>111</p>
<a>222</a>
<strong>333</strong>
"""
pattern = re.compile("^<.*?>(?:.*?)<.*?>$" , flags=re.M)
lst = pattern.findall(strvar)
print(lst)
# re.S 使 . 匹配包括换行在内的所有字符
strvar = """
give
sdfsdfmefive
"""
# 多个修饰符一起使用通过|拼接
pattern = re.compile(".*?mefive" , flags = re.S|re.I|re.M )
obj = pattern.search(strvar)
print(obj.group())
100)import 导入模块
- 模块的基本导入
'''
模块就是具体的一个文件 包是文件夹
在同级目录下 import导入包会直接进行搜索并导入
import modouleB
import modouleB
import modouleB
# 注意点: 模块导入时,导入一次,终身受益,并不会重复导入
'''
# (1) 模块.变量
print(moduleB.name)
# (2) 模块.函数
moduleB.jump()
# (3) 模块.类
print(moduleB.Classrome().name)
- 非同级别(其他文件夹下的模块导入)
import sys # 导入系统口快
# 将环境变量追加到列表中即可
sys.path.append('/mnt/hgfs/PycharmProjects/pythonProject1/pythoncode/day19')
import day19
print(day19.bird)
101)from .. import .. 导入模块
# 导入单个成员
from moduleB import name
print(name) # 小猫猫
# 导入多个成员
from moduleB import name,like
print(name,like) # 小猫猫 吃鱼
# 导入所有成员 *代表所有
from moduleB import *
print(name,like) # 小猫猫 吃鱼
jump() # 我会上树
# 设置 * 导入范围 在需要被导入的文件中操作
__all__ = ['like'] # 全部导入时 只允许导入一个成员
# 设置引入成员的别名 as
from moduleB import name as n,lookdoor as ld
print(n) # 小猫猫
ld() # 我会看门
# __name__ 的使用
'''
返回模块名字的魔术属性 __name__
如果当前文件是直接运行的(没有被其他模块导入),返回'__main__'字符串
如果当前文件是间接导入的(被其他模块导入),返回的是当前模块的模块名
'''
modouleB文件
__all__ = ['like']
name = '小猫猫'
like = '吃鱼'
def jump():
print('我会上树')
def lookdoor():
print('我会看门')
class Classrome():
name = '自学python19课'
print(__name__,'======')
# 如果是在modouleB文件下打印__name__返回的是'__main__'
# 如果是在其他模块下引入modouleB模块时 modouleB文件下打印__name__返回的是该模块的模块名modouleB
102)import 导入包
'''
文件夹: 包 文件:模块
当引入包时,会自动执行包中的__init__.py的初始化文件,对包进行初始化
相当于直接导入了__init__模块 里面的所有成员都可以直接使用
'''
# 1. import 导入包下的初始化文件__init__.py
import bao
print(bao.name) # 娃娃鱼
# 2. 导入报下的某个模块
# 方法一
import bao.mywork
bao.mywork.fn()
# 方法二 as 别名
import bao.mywork as mk
mk.fn()
# 方法三 把要引入的模块放到初始化文件当中进行引入,简化操作 (常用)
在__init__文件中引入 from baopilong import mywork
import baopilong
baopilong.mywork.fn()
103)from.. import.. 导入包
# 1. 导入初始化文件__init__.py中的成员
from baopilong import name
print(name)
# 2. 引入包中的模块
from baopilong import mywork
mywork.fn()
# 3. 引入包中模块下的成员
from baopilong.mywork import fn
fn()
104单入口模式

105)构造方法
# ### __init__构造方法
'''
触发时机: 实例化对象,初始化的时候触发
功能: 为对象添加成员
参数: 参数不不固定,至少一个self参数
返回值: 无
'''
-
基本语法
class MyClass(): def __init__(self): print('构造方法被触发') self.color = '天空蓝' # 给实例化对象 创建成员 # 实例化对象 obj = MyClass() # 构造方法被触发 print(obj.__dict__) # {'color': '天空蓝'} print(obj.color) # 天空蓝 -
带有多个参数的构造方法
class MyClass(): def __init__(self,color): print('构造方法被触发') self.color = color # 实例化对象 obj = MyClass('粉红色') # 构造方法被触发 print(obj.color) # 粉红色 obj2 = MyClass('黑色') # 构造方法被触发 print(obj2.color) # 黑色 -
一个类可以实例化多个对象
class Children(): def __init__(self,name,skin): self.name = name self.skin = skin def cay(self): print('小孩生下来就会哇哇的哭') def info(self): print('小孩的名字{},皮肤{}'.format(self.name,self.skin)) afanda = Children('阿凡达','深蓝色') afanda.info() # 小孩的名字阿凡达,皮肤深蓝色 haoke = Children('路巨人','绿色') haoke.info() # 小孩的名字路巨人,皮肤绿色
106)继承
'''
一个类除了自身所拥有的属性方法之外,还获取了另一个类的成员属性和方法 是一种继承关系
被继承的类叫做父类(基类,超类),继承的类叫做子类(衍生类)
在python中所有类都继承object这个父类
继承: 1.单继承 2.多继承
'''
单继承
'''私有成员只有在本类中 通过公有方法进行返回'''
class HuMan():
eye = '黑色的'
def jump(self):
print('古代人都能上树{}')
def beat_animal(self):
print('古代人都会打猎')
def __makefire(self):
print('古代人会生火')
def pub_fnc(self):
self.__makefire()
'''继承的类 写在类的定义处'''
class Man(HuMan):
pass
# 实例化对象
xiaoming = Man()
print(xiaoming.eye) # 黑色的
# 方法重写(并不是把父类的方法修改,而是不同的对象自己创建的一个方法,名字上和父类的一样而已)
# 子类对象中有 beat_animal 调用子类对象的 没有 就找 子类 再没有 就找父类 再没有就报错
xiaoming.beat_animal() # xiaoming可不会打猎
xiaoming.pub_fnc() # 古代人会生火
107)多继承
-
基本语法
class Father(): property = '风流倜傥,才华横溢,玉树临风,才高八斗' def f_hobby(self): print('吃喝嫖赌抽,坑蒙拐骗偷,抽烟喝酒烫头') class Mother(): property = '倾国倾城,貌美如花,沉鱼落雁,闭月羞花' def m_hobby(self): print('泵野滴,社会摇,打麻将,网红勾引小鲜肉') class Daugther(Father,Mother): pass obj = Daugther() '''property 先看类对象有没有 没有再看类本身 没有再看父类''' print(obj.property) # 风流倜傥,才华横溢,玉树临风,才高八斗 obj.m_hobby() # 泵野滴,社会摇,打麻将,网红勾引小鲜肉
108)super()
class Father():
property = '风流倜傥,才华横溢,玉树临风,才高八斗'
def f_hobby(self):
print('吃喝嫖赌抽,坑蒙拐骗偷,抽烟喝酒烫头')
class Mother():
property = '倾国倾城,貌美如花,沉鱼落雁,闭月羞花'
def m_hobby(self):
print(self.property) #喜欢看lol,dnf
print('泵野滴,社会摇,打麻将,网红勾引小鲜肉')
'''
super()只能调用父类相关成员
调用super时会传递参数对象(如果实例化对象和类中属性名相同,以实例化对象为主)
'''
class Son(Father,Mother):
property = '打游戏,吃小零食'
def skill(self):
print(super().property) # 风流倜傥,才华横溢,玉树临风,才高八斗 优先从Father开始找
super().m_hobby() # 泵野滴,社会摇,打麻将,网红勾引小鲜肉
# 实例化对象
obj = Son()
obj.property = '喜欢看lol,dnf'
obj .skill()

- super深度解析
# ### 菱形继承 (钻石继承)
"""
Human
Man Woman
Children
"""
class MyClass():
pass
class Human():
pty = 1
def feelT(self):
print("古代人类,天热了,光腚1")
print(self.pty)
print("古代人类,天冷了,穿寿衣2")
class Man(Human):
# pty = 2
def feelT(self):
print("男人,天热了,光膀子3")
print(super(),"<==2==>")
super().feelT()
print("男人,天冷了,光腚4")
class Woman(Human):
# pty = 3
def feelT(self):
print("女人,天热了,脱毛5")
print(super(),"<==3==>")
super().feelT()
print("女人,天冷了,穿貂6")
class Children(Man,Woman):
# pty = 4
def feelT(self):
print("小孩,天热了,光腚7")
print(super(),"<==1==>")
super().feelT()
print("小孩,天冷了,多喝热水8")
# ### super的深层理解
obj = Children()
obj.feelT()
# 73512648
"""
# mro: 方法解析顺序 (c3算法计算的)
# 语法: 类.mro() => 列表
m :method
r :resolution
o :order
super 会自动根据mro列表返回出来的顺序关系,依次调用
super作用:专门用于解决复杂的多继承调用顺序关系;依照mro返回的列表顺序,依次调用;
super调用的顺序:会按照c3算法的广度优先原则进行调用
super传参:会默认在调用方法时,传递该对象参数;
"""
lst = Children.mro()
print(lst)
"""
[
<class '__main__.Children'>,
<class '__main__.Man'>,
<class '__main__.Woman'>,
<class '__main__.Human'>,
<class 'object'>
]
"""
# ### issubclass与isinstance
# issubclass 判断类的子父关系(应用在类与类之间)
"""只要在一条继承链上满足关系即可"""
res = issubclass(Children,Man)
res = issubclass(Children,Human)
res = issubclass(Children,MyClass)
# 如果元组当中有一个父类满足,即返回真
res = issubclass(Children, (Man,Human,MyClass) )
print(res)
# isinstance 判断对象的类型 (应用在类与对象之间)
"""只要在一条继承链上满足关系即可"""
res = isinstance(obj,Children)
res = isinstance(obj,Human)
res = isinstance(obj,MyClass)
# 如果元组当中有一个类满足,即返回真
res = isinstance(obj, (Man,Human,MyClass) )
print(res)
109)多态
# ### 多态: 不同的子类对象调用相同的父类方法,得到不同的结果
'''有继承关系,子类重写了父类的方法'''
# 军队类
class Trup():
def attack(self):
print('进攻')
def retreat(self):
print('撤退')
class Air(Trup):
def attack(self):
print('[空军]空中投放导弹,原子弹')
def retreat(self):
print('[空军]跳机撤退,打开降落伞')
class Navy(Trup):
def attack(self):
print('[海军]海上定位发射激光进攻')
def retreat(self):
print('[海军]跳海撤退,开始游泳')
class Army(Trup):
def attack(self):
print('[陆军]陆地上小步枪射击,手雷弹')
def retreat(self):
print('[陆军]直接拔腿就跑,可以不用回头')
# 实例化对象
obj1 = Air()
obj2 = Navy()
obj3 = Army()
lst = [obj1,obj2,obj3]
mingling = input('''
*******************请输入命令************************
1. 全体进攻
2. 全体撤退
3. 空军上,其他军兵种撤退
''')
for i in lst:
if mingling == '1':
i.attack()
elif mingling == '2':
i.retreat()
elif mingling == '3':
# 判断当前类对象 是否是空军类的实例
if isinstance(i,Air):
# 空军进攻
i.attack()
else:
# 其他兵种撤退
i.retreat()
else:
print('输入命令不存在,退出程序')
break
110)魔术方法__ new __
'''
触发时机: 实例化类生成对象的时候促发(促发时间在__init__之前)
功能: 控制对象的创建过程
参数: 至少一个cls接受当前的类
返回值: 通常返回对象或None
'''
- 返回对象
class Cat():
a = 1
cat = Cat()
class Per():
def __new__(cls):
'''返回本类对象'''
# return object.__new__(cls)
return cat # 返回猫对象
obj = Per() # 此时实例化的对象是猫对象
print(obj.a) # 1
- 返回None
class Cat():
a = 1
cat = Cat()
class Per():
def __new__(cls):
return None
obj = Per()
print(obj) # None
- __ new __ 要先于 __ init __ 执行
class Per():
def __init__(self):
print(2)
def __new__(cls):
print(1)
return object.__new__(cls)
obj = Per() # 1 2
- __ new __的参数要和 __ __ init __一一对应
class Per():
def __init__(self,name):
print(name) # 娃娃鱼
def __new__(cls,name):
return object.__new__(cls)
obj = Per('娃娃鱼')
==================================================
# 使用 *args 和 **kwargs 改造
# 推荐使用
class Per():
def __new__(cls, *args, **kwargs):
return object.__new__(cls)
def __init__(self,name):
print(name)
obj = Per('娃娃鱼')
- __ new 和 __ __ init __的注意事项
'''
如果 __ new__没有返回对象或者返回的是其他类的对象,不会调用构造方法,
只有返回本类对象的时候,才会调用构造方法
'''
class Cat():
a = 1
cat = Cat()
class Per():
def __new__(cls, *args, **kwargs):
return object.__new__(Cat) # 返回的不是本类对象 __init__初始化方法不会执行
def __init__(self,name):
self.name = name
obj = Per('娃娃鱼')
print(obj.name) # error
111)单态
# ### 单态模式: 同一个类,无论实例化多少次,都有且只有一个对象(指向的都是同一个对象)
'''
每创建一个对象,就会在内存中多占用一份空间
为了节省空间,提升执行效率,使用单态模式
场景: 只是单纯调用类中的成员,而不会额外为当前对象添加成员
'''
class Singleton():
__obj = None
def __new__(cls, *args, **kwargs):
if cls.__obj is None:
cls.__obj = object.__new__(cls)
return cls.__obj
'''
第一次,在实例化对象是触发 __new__魔术方法
if cls.__obj is None 条件成立 cls.__obj = object.__new__(cls) 创建一个对象赋值给私有属性 cls.__obj
return cls.__obj 用obj1接收到了对象
第二次,在实例化对象时触发__new__魔术方法 if cls.__obj is None 不满足,因为已经在__obj中存放了一个对象
return cls.__obj(第一次的对象)
第三次,在实例化对象时触发__new__魔术方法 if cls.__obj is None 不满足,因为已经在__obj中存放了一个对象
return cls.__obj(第一次的对象)
'''
obj1 = Singleton()
obj2 = Singleton()
obj3 = Singleton()
print(obj3,obj1,obj2) # 地址相同

class Singleton():
__obj = None
def __new__(cls, *args, **kwargs):
if cls.__obj is None:
cls.__obj = object.__new__(cls)
return cls.__obj
def __init__(self,name):
self.name = name
'''
单态模式下都是使用第一次实例化返回的对象
修改都是同一个变量 或者覆盖前者
'''
obj1 = Singleton('王一博')
obj2 = Singleton('张一山')
print(obj1.name)
print(obj2.name)
112)魔术方法__ del__(析构方法)
'''
触发时机: 当对象被内存回收的时候自动触发[1.页面代码全部执行完毕 2. 所有对象被删除时]
功能: 对象使用完毕后资源回收
参数: 一个self接收对象
返回值: 无
'''
- 执行方式一(页面执行完毕回收所有变量)
class Lion():
def __init__(self,name):
self.name = name
def __del__(self):
print('析构方法被触发...')
# 触发方式一: 页面执行完毕回收所有变量
obj1 = Lion('辛巴')
- 执行方式二(所有对象被del的时候)
class Lion():
def __init__(self,name):
self.name = name
def __del__(self):
print('析构方法被触发...')
obj1 = Lion('辛巴')
obj2 = obj1
obj3 = obj1
print(obj3,obj1,obj2) # 指向同一个引用地址
# 所有对象被del的时候
print('=======start========')
del obj1
del obj2
del obj3
print('=======end========')

析构方法案例(模拟文件操作)
# 模拟文件操作
import os
class ReadFile():
# 判断文件是否存在
def __new__(cls,filename):
if os.path.exists(filename):
return object.__new__(cls)
else:
print('文件不存在')
# 打开文件
def __init__(self,filename):
self.fp = open(filename,mode='r',encoding='utf-8')
# 关闭文件
def __del__(self):
self.fp.close()
# 读取文件
def read_file(self):
return self.fp.read()
obj = ReadFile('moduleB.py')
print(obj.read_file())
113)魔术方法 __ str __
# ### __str__魔术方法
'''
触发时机: 使用print(对象)或者str(对象的时候触发)
功能: 查看对象信息
参数: 一个self接收当前对象
返回值: 必须返回字符串类型
'''
class Cat():
gift = '抓老鼠'
# 定义小猫名字
def __init__(self,name):
self.name = name
#定义小猫技能
def cat_gift(self):
return '小猫叫{},小猫会{}'.format(self.name,self.gift)
# 功能说明
def __str__(self):
return self.cat_gift()
tom = Cat('汤姆')
# 触发时机1 : pring(对象)
print(tom) # 小猫叫汤姆,小猫会抓老鼠
# 触发时机2 : str(对象)
res = str(tom)
print(res) # 小猫叫汤姆,小猫会抓老鼠
114)魔术方法 __ repr__
# ### __repr__魔术方法
'''
触发时机: 对比__str__ 新增了一个 repr(对象)的触发方式 底层默认做了 __repr__ = __str__ 处理
功能: 查看对象信息 和__str__ 类时
参数: 一个self接收当前对象
返回值: 必须返回字符串类型
'''
class Mouse():
gift = '偷油吃'
# 定义老鼠名字
def __init__(self,name):
self.name = name
#定义老鼠技能
def cat_gift(self):
return '老鼠叫{},老鼠会{}'.format(self.name,self.gift)
# 功能说明
def __repr__(self):
return self.cat_gift()
jerry = Mouse('杰瑞')
# 触发时机1 : pring(对象)
print(jerry) # 小猫叫汤姆,小猫会抓老鼠
# 触发时机2 : str(对象)
res = str(jerry)
print(res)
# 触发时机3 : repr(对象)
res = repr(jerry)
print(res)
115)魔术方法__ call __
'''
触发时机: 把对象当作函数调用的时候自动触发
功能: 模拟函数化操作
参数: 参数不固定,至少一个self参数
返回值: 看需求
'''
- 基本语法
class MyClass():
def __call__(self):
print('魔术方法__ call __被触发...')
obj = MyClass()
obj() # 魔术方法__ call __被触发...
- 利用__ call __ 魔术方法做统一调用
class Wash():
def __call__(self,somthing):
print('我要洗{}'.format(somthing))
self.step1(somthing)
self.step2()
self.step3()
return '洗完了'
def step1(self,somthing):
print('放水,把{}人进去'.format(somthing))
def step2(self):
print('倒洗衣粉,洗衣液,蓝月亮...')
def step3(self):
print('洗一洗,晾干,穿上')
obj = Wash()
res = obj('衣服')
print(res)
116)魔术方法__ bool __
# ### __bool__ 魔术方法
'''
触发时机: 使用bool(对象)的时候自动触发
功能: 强转对象
参数: 一个self接受当前对象
返回值: 必须是布尔类型
'''
'''
类似的还有如下等待(了解):
__complex__(self) 被complex强转对象时调用
__int__(self) 被int强转对象时调用
__float__(self) 被float强转对象时调用
'''
class Myclass():
def __bool__(self):
return True
obj = Myclass()
print(bool(obj))
117)add 魔术方法 (与之相关的__radd__ 反向加法)
'''
触发时机:使用对象进行运算相加的时候自动触发
功能:对象运算
参数:二个对象参数
返回值:运算后的值
'''
'''
类似的还有如下等等(了解):
__sub__(self, other) 定义减法的行为:-
__mul__(self, other) 定义乘法的行为:
__truediv__(self, other) 定义真除法的行为:/
...
...
'''
class MyClass():
def __init__(self,num):
self.num = num
# 当对象在 + 号的左侧时,自动触发
def __add__(self,other):
return self.num * 3 + other
def __radd__(self,other):
return self.num * 5 + other
# add的触发方式
a = MyClass(3)
res = a + 1
print(res) # 10
# radd的触发方式
b = MyClass(5)
res = 7 + b
print(res) # 32
# 对象 + 对象
res = a + b
print(res) # 34
"""
a+b 触发的是add魔术方法 self 接受的是a other 接受的是b
return a.num + b => return 9 + b
res = 9 + b 触发的是radd魔术方法 self 接受的是b other 接受的是9
return b.num * 5 + 9 => 5 * 5 + 9 => 34
"""
118)__ len__ 魔术方法
'''
触发时机:使用len(对象)的时候自动触发
功能:用于检测对象中或者类中某个内容的个数
参数:一个self接受当前对象
返回值:必须返回整型
'''
# len(对象) => 类中的所有自定义成员
class MyClass():
pty1 = 1
pty2 = 2
__pty3 = 3
def func1():
pass
def func2():
pass
def __func3():
pass
def __len__(self):
# 以__开头并且以__结尾的成员过滤掉;
return len( [ i for i in MyClass.__dict__ if not ( i.startswith("__") and i.endswith("__") ) ] )
obj = MyClass()
print(len(obj))
"""
代码原型;
print(MyClass.__dict__)
lst = []
for i in MyClass.__dict__:
print(i , type(i))
if not ( i.startswith("__") and i.endswith("__") ):
lst.append(i)
print(len(lst))
"""
"""
{
'__module__': '__main__',
'pty1': 1,
'pty2': 2,
'_MyClass__pty3': 3,
'func1': <function MyClass.func1 at 0x7f6898431378>,
'func2': <function MyClass.func2 at 0x7f6898431400>,
'_MyClass__func3': <function MyClass.__func3 at 0x7f6898431488>,
'__len__': <function MyClass.__len__ at 0x7f6898431510>,
'__dict__': <attribute '__dict__' of 'MyClass' objects>,
'__weakref__': <attribute '__weakref__' of 'MyClass' objects>,
'__doc__': None
}
"""
119)魔术属性
__ dict __ 获取对象或类的内部成员结构
# 魔术属性
class Sasuke():
__eye = '写轮眼->万花筒->轮回眼'
skin = '白色'
def skylight(self):
print('使用天照,一团黑色的火焰 ... 恐怖如斯')
def __moonread(self):
print('使用月读,将敌人拉入到幻术空间,被施法者掌握')
obj = Sasuke()
# __dict__ 获取对象或类的内部成员结构
dic = Sasuke.__dict__
dic = obj.__dict__
__ doc __获取对象或类的内部文档(注释说明)
# 魔术属性
class Sasuke():
'''
描述: 佐助这个人的天生属性,技能
成员属性: __eye skin
成员方法: skylight __moonread
'''
obj = Sasuke()
print(obj.__doc__)
print(Sasuke.__doc__)
__ name __获取类名函数名
# 魔术属性
class Sasuke():
__eye = '写轮眼->万花筒->轮回眼'
skin = '白色'
def skylight(self,myFunc):
print('使用天照,一团黑色的火焰 ... 恐怖如斯')
res = myFunc.__name__
print(res) # func22
def __moonread(self):
print('使用月读,将敌人拉入到幻术空间,被施法者掌握')
obj = Sasuke()
def func22():
print(132)
obj.skylight(func22)
__ 获取当前对象所属的类 __
# 魔术属性
class Sasuke():
'''
描述: 佐助这个人的天生属性,技能
成员属性: __eye skin
成员方法: skylight __moonread
'''
__eye = '写轮眼->万花筒->轮回眼'
skin = '白色'
def skylight(self,myFunc):
print('使用天照,一团黑色的火焰 ... 恐怖如斯')
res = myFunc.__name__
print(res) # func22
def __moonread(self):
print('使用月读,将敌人拉入到幻术空间,被施法者掌握')
obj = Sasuke()
print(obj.__class__) # <class '__main__.Sasuke'>
__ bases __ 获取一个类的直接继承的所有父类(返回元组)
class Mom():
pass
class Father():
pass
class Sasuke(Mom,Father):
'''
描述: 佐助这个人的天生属性,技能
成员属性: __eye skin
成员方法: skylight __moonread
'''
__eye = '写轮眼->万花筒->轮回眼'
skin = '白色'
def skylight(self,myFunc):
print('使用天照,一团黑色的火焰 ... 恐怖如斯')
res = myFunc.__name__
print(res) # func22
def __moonread(self):
print('使用月读,将敌人拉入到幻术空间,被施法者掌握')
obj = Sasuke()
print(Sasuke.__bases__) # (<class '__main__.Mom'>, <class '__main__.Father'>)
120)异常的分类
IndexError 索引超出序列的范围
KeyError 字典中查找一个不存在的关键字
NameError 尝试访问一个不存在的变量
IndentationError 缩进错误
AttributeError 尝试访问未知的对象属性
StopIteration 迭代器没有更多的值
AssertionError 断言语句(assert)失败
EOFError 用户输入文件末尾标志EOF(Ctrl+d)
FloatingPointError 浮点计算错误
GeneratorExit generator.close()方法被调用的时候
ImportError 导入模块失败的时候
KeyboardInterrupt 用户输入中断键(Ctrl+c)
MemoryError 内存溢出(可通过删除对象释放内存)
NotImplementedError 尚未实现的方法
OSError 操作系统产生的异常(例如打开一个不存在的文件)
OverflowError 数值运算超出最大限制
ReferenceError 弱引用(weak reference)试图访问一个已经被垃圾回收机制回收了的对象
RuntimeError 一般的运行时错误
SyntaxError Python的语法错误
TabError Tab和空格混合使用
SystemError Python编译器系统错误
SystemExit Python编译器进程被关闭
TypeError 不同类型间的无效操作
UnboundLocalError 访问一个未初始化的本地变量(NameError的子类)
UnicodeError Unicode相关的错误(ValueError的子类)
UnicodeEncodeError Unicode编码时的错误(UnicodeError的子类)
UnicodeDecodeError Unicode解码时的错误(UnicodeError的子类)
UnicodeTranslateError Unicode转换时的错误(UnicodeError的子类)
ValueError 传入无效的参数
ZeroDivisionError 除数为零
121)异常处理
'''
try .. except .. 来抑制错误
把有可能报错的代码放到try代码块中
如果有报错,直接执行except这个代码块
如果没有报错,不执行except这个代码块
'''
'''
在异常处理当中,所有的异常错误都继承 BaseException Exception 普通异常的父类(了解)
'''
# 类型上的子父关系
from collections import Iterator,Iterable
print(issubclass(Iterator, Iterable))
"""
-
基本语法
try: lst = [1, 2, 3] lst[1000] except: pass -
带有分支的异常处理
# 2.带有分支的异常处理
'''
类似于 if else 属于哪个错误 打印哪个错误 都不属于的话 走最后的 except:
'''
try:
# lst = [1,2,3]
# lst[1000]
dic = {"a":1,"b":2}
dic["c"]
# print(lisi)
print(asd)
except IndexError:
print("下标越界1")
except KeyError:
print("字典的键不存在2")
except NameError:
print("这个变量不存在的3")
except:
print("有异常错误4")
- 处理生成器异常的错误
def mygen():
yield 1
yield 2
yield 3
return 4
try:
gen = mygen()
print(next(gen)) 1
print(next(gen)) 2
print(next(gen)) 3
print(next(gen))
# 给StopIteration这个类创建出来的对象起一个别名叫e
"""
当你打印对象时,会触发内部__str__方法,通过一些列的调用,返回出最后的返回值
"""
except StopIteration as e:
# 可以获取返回值 4
print(e)
- 异常处理的其他写法
"""
1 .try .. except .. else ..
当try这个代码块当中没有报错的时候,执行else这个分支
如果try代码块有报错,就不执行else这个分支
"""
try:
print(123)
except:
pass
else:
print("执行了else分支 ... ") # 会执行
"""
2.try .. finally ... 无论代码是否报错,都必须要执行的代码写在finally这个代码块当中
场景:应用在异常环境下,保存数据或者关闭数据库等操作,必须要在数据库程序崩溃之前执行的代码写在finally代码块中;
"""
try:
lst = [1,2,3]
lst[1000]
finally:
print(234678)
"""3.try .. except .. else .. finally .. """
try:
lst = [1, 2, 3]
lst[1000]
except:
print(456)
else:
print("执行了else分支 ... ")
finally:
print("执行关闭数据库操作")
122)主动抛异常
# ### 主动抛异常
"""
BaseException 所有异常类的父类
Exception 普通异常类的父类
raise + 异常错误类 / 异常错误类对象
"""
# (1) raise 基本语法
# raise KeyError
# raise KeyError()
"""
try:
raise
except:
pass
try:
raise
except BaseException:
pass
"""
# (2) 自定义异常错误类
"""必须继承异常类的父类 BaseException """
# return_errorinfo必须在报错的情况下才能触发内部相应方法获取当前行号和文件名
def return_errorinfo(n):
import sys
f = sys.exc_info()[2].tb_frame.f_back
if n == 1:
return str(f.f_lineno) # 返回当前行数
elif n == 2:
return f.f_code.co_filename # 返回文件名
# 通过主动抛出异常,来获取响应的数据
def get_info(n):
try:
raise
except:
return return_errorinfo(n)
# 自定义异常错误类
class MyException(BaseException):
def __init__(self, error_num, error_msg, error_filename, error_linenum):
self.error_num = error_num
self.error_msg = error_msg
self.error_filename = error_filename
self.error_linenum = error_linenum
eye = "轮回眼"
try:
if eye == "轮回眼":
raise MyException(404, "人类没有轮回眼", get_info(2), get_info(1))
except MyException as e: # 给自定义MyException异常类的对象起个别名叫做e
print(e.error_num) # 404
print(e.error_msg) # 人类没有轮回眼
print(e.error_filename) # /mnt/hgfs/PycharmProjects/pythonProject1/pythoncode/import_bao/moduleA.py
print(e.error_linenum) # 57
123)装饰器(本质也是函数)
在不改变原有代码的前提下,为原函数扩展新功能
- 装饰器的原型
def kuozhan(_func):
def newfunc():
print('厕所前...干净整齐')
_func()
print('厕所后...臭气熏天')
return newfunc
def func():
print('我是屌丝')
func = kuozhan(func)
func()
'''
厕所前...干净整齐
我是屌丝
厕所后...臭气熏天
'''
- 装饰器改造@符号的使用
'''执行流程: 将func传递给kuozhan,并且将扩展函数中的闭包函数 newfunc 直接返回给原函数 func'''
def kuozhan(_func):
def newfunc():
print('厕所前...干净整齐')
_func()
print('厕所后...臭气熏天')
return newfunc
@kuozhan
def func():
print('我是屌丝')
func()
'''
厕所前...干净整齐
我是屌丝
厕所后...臭气熏天
'''
装饰器原理图

3)装饰器的嵌套(由下往上执行)
'''
执行流程: 首先将func传递给kuozhan1,并且将扩展函数中的闭包函数 newfunc 直接返回给原函数 func
此时的func() 输出 '厕所前...人模狗样1' '我是白富美...5' 厕所后...牛头马面2
再将此时的func()传递给 kuozhan2,并且将扩展函数中的闭包函数 newfunc 直接返回给原函数 func
这时的func() 输出的就是最后的结果
'''
def kuozhan1(_func):
def newfunc():
print('厕所前...人模狗样1')
_func()
print('厕所后...牛头马面2')
return newfunc
def kuozhan2(_func):
def newfunc():
print('厕所前...面黄肌瘦3')
_func()
print('厕所后...红光满面4')
return newfunc
@kuozhan2
@kuozhan1
def func():
print('我是白富美...5')
func()
'''
1厕所前...面黄肌瘦3
厕所前...人模狗样1
我是白富美...5
厕所后...牛头马面2
厕所后...红光满面4
'''
4)用装饰器扩展带有参数的原函数
def kuozhan(func):
def newfunc(who,where):
print('厕所前,萎靡不振')
func(who,where)
print('厕所后,兽性大发')
return newfunc
@kuozhan
def func(who,where):
print('{}在{}解手'.format(who,where))
func('孙志和','鸟窝') # func('孙志和','鸟窝') == newfunc('孙志和','鸟窝')
'''
厕所前,萎靡不振
孙志和在鸟窝解手
厕所后,兽性大发
'''
- 用装饰器扩展带有参数和返回值的原函数
def kuozhan(func):
def newfunc(*args,**kwargs): # 此处是定义函数处 将参数进行打包
print('厕所前,饥肠辘辘')
res = func(*args,**kwargs) # 此处是调用处 将参数进行解包
print('厕所后,酒足饭饱')
return res
return newfunc
@kuozhan
def func(*args,**kwargs):
lst = []
dic = {'gaoxuefeng':'高雪峰','sunzhihe':'孙志和','gelong':'戈隆'}
# 解手的地点遍历出来
for i in args:
print('拉屎的地点:',i)
for k,v in kwargs.items():
if k in dic:
strvar = dic[k] + '留下了' + v +'黄金'
lst.append(strvar)
return lst
lst = func('电影院','水下',gaoxuefeng = '15g',sunzhihe = '15吨',gelong = '15斤')
print(lst)
'''
厕所前,饥肠辘辘
拉屎的地点: 电影院
拉屎的地点: 水下
厕所后,酒足饭饱
['高雪峰留下了15g黄金', '孙志和留下了15吨黄金', '戈隆留下了15斤黄金']
'''
6)使用类装饰器
方式一
class Kuozhan():
def kuozhan(func):
def newfunc():
print('厕所前...饥肠辘辘')
func()
print('厕所后...衣衫褴褛')
return newfunc
@Kuozhan.kuozhan
def func():
print('厕所进行时')
func()
方式二
class Kuozhan():
def __call__(self,_func):
return self.kuozhan(_func)
def kuozhan(self,func):
def newfunc():
print('厕所前...饥肠辘辘')
func()
print('厕所后...衣衫褴褛')
return newfunc
@Kuozhan()
def func():
print('厕所进行时')
func()
- 带有参数的函数装饰器
# (7) 带有参数的函数装饰器
def outer(num):
def kuozhan(_func):
def newfunc1(self):
print(self)
print("厕所前 ... 老实巴交")
_func(self)
print("厕所后 ... 浑身哆嗦")
def newfunc2(self):
print(self)
print("厕所前 ... 狂送人头")
_func(self)
print("厕所后 ... 让二追三")
if num == 1:
return newfunc1
elif num == 2:
return newfunc2
elif num == 3:
return "厕所前,洗洗手,厕所后,簌簌口"
return kuozhan
class MyClass():
@outer(1) # @outer(1) => func1 = kuozhan(func1) ==> func1 = newfunc1
def func1(self):
print("向前一小步,文明一大步")
@outer(2) # @outer(2) => func2 = kuozhan(func2) ==> func2 = newfunc2
def func2(self):
print("不冲就打包带走")
@outer(3) # @outer(3) => func3 = kuozhan(func3) ==> func3 = return "厕所前,洗洗手,厕所后,簌簌口"
def func3(self):
print("请瞄准后发射,尿到外边,说明你短!")
obj = MyClass()
obj.func1() # 相当于 obj.newfunc1()
obj.func2() # 相当于 obj.newfunc2()
print(obj.func3)
- 带有参数的类装饰器
# (8) 带有参数的类装饰器
"""
参数1: 给修饰的类添加成员属性和方法
参数2: 把类中的run方法变成属性
"""
class Kuozhan():
ad = "贵族茅厕,茅厕中的百岁山."
def money(self):
print("贵族茅厕,包月1100,一小时200元")
def __init__(self, num):
self.num = num
def __call__(self, cls):
print(cls) # MyClass
if self.num == 1:
return self.kuozhan1(cls)
elif self.num == 2:
return self.kuozhan2(cls)
# 参数1的情况 : 添加成员属性和方法
def kuozhan1(self, cls):
def newfunc():
# MyClass.ad = "贵族茅厕,茅厕中的百岁山."
cls.ad = Kuozhan.ad
cls.money = Kuozhan.money
return cls()
return newfunc
# 参数2的情况 : 把方法变成属性;
def kuozhan2(self, cls):
def newfunc():
if "run" in cls.__dict__:
cls.run = cls.run()
return cls()
return newfunc
print("<==================>")
# 方式一
@Kuozhan(1) # => @obj(MyClass) =>
class MyClass():
def run():
return "亢龙有悔"
obj = MyClass()
print(obj.ad) # 贵族茅厕,茅厕中的百岁山
obj.money() # 贵族茅厕,包月1100,一小时200元
124)类中相关方法
'''
(1) 普通无参方法
(2) 绑定方法: 1) 绑定到对象 2) 绑定到类
(3) 静态方法: 无论是对象还是类调用静态方法,都不会默认传递任何参数
'''
class Dog():
# 普通无参方法
def tail():
print('小狗喜欢摇尾巴')
# 绑定到对象的方法
def wang(self):
print('汪汪汪的叫')
# 绑定到类的方法 需要借助修饰器
@classmethod
def tian(cls):
print(cls)
print('小狗喜欢舔骨头')
# 静态方法
@staticmethod
def jump(something):
print('小狗喜欢接{}'.format(something))
obj = Dog()
# 无参方法调用
Dog.tail() # 小狗喜欢摇尾巴
# 绑定到对象方法调用
obj.wang() # 汪汪汪的叫
Dog.wang(obj) # 汪汪汪的叫
# 绑定到类方法使用
'''无论对象还是类都可以调用,默认传递的是类'''
print(obj.__class__)
obj.jump('飞盘')
Dog.jump('飞盘')
125)@property 修饰器
'''
可以把方法变成属性 : 可以动态的控制属性的获取,设置,删除相关操作
@property 获取属性
@方法名.setter 设置属性
@方法名.deleter 删除属性
'''
- 方式一
class Myclass():
def __init__(self,name):
self.name = name
@property
def username(self):
print('@property被触发....')
return self.name
@username.setter
def username(self,val):
print('username.setter被触发....')
self.name = val
@username.deleter
def username(self):
print('@username.deleter被触发....')
del self.name
obj = Myclass('小红')
# 获取值得时候自动触发@property装饰器下的方法
res = obj.username
print(res) # 小红
# 设置值的时候自动触发@username.setter 装饰器下的方法
obj.username = '小兰'
print(obj.username) # 小兰
# 删除值得时候自动触发@username.deleter 装饰器下的方法
del obj.username
print(obj.username) # 将报错 被删除了
- 方式二
class Myclass():
def __init__(self,name):
self.name = name
def get_username(self):
return self.name
def set_username(self,val):
self.name = val
def del_username(self):
del self.name
# 参数得顺序 获取 设置 删除
username = property(get_username,set_username,del_username)
obj = Myclass('小红')
# 获取值得时候 执行get_username下得相关操作
print(obj.username) # 小红
# 设置值得时候 执行 set_username 下得相关操作
obj.username = '小兰'
print(obj.username)
# 删除值得时候 执行 del_username下得相关操作
del obj.username
print(obj.username) # 将会报错 已被删除
126)反射(通过字符串反射类和对象中的成员)
''' 通过字符串操作类对象 或者 模块中得相关成员得操作'''
'''
hasattr() 检测对象/类是否有指定得成员
getattr() 获取对象/类成员得值
setattr() 设置对象/成员得值
delattr() 删除对象/类成员得值
'''
- (1)hasattr( ) 检测对象/类是否有指定的成员
class Father():
pass
class Mother():
pass
class Children(Father,Mother):
eye = '蓝色的'
weight = '1吨'
def eat(self):
print('小孩下生会喝奶')
def drink(self):
print('小孩下生喜欢喝勇闯天涯...')
def __la(self):
print('小孩自动拉,无法控制')
obj = Children()
# 对象
res = hasattr(obj,'eye')
print(res)# True
# 类
res = hasattr(Children,'eye123')
print(res)# False
- (2)getattr( ) 获取对象/类成员的值
class Father():
pass
class Mother():
pass
class Children(Father,Mother):
eye = '蓝色的'
weight = '1吨'
def eat(self):
print('小孩下生会喝奶')
def drink(self):
print('小孩下生喜欢喝勇闯天涯...')
def __la(self):
print('小孩自动拉,无法控制')
obj = Children()
# 对象
res = getattr(obj,'weight')
print(res) # 1吨
# 如果获取的值不存在,可以设置第三个参数,防止报错
res = getattr(obj,'weight123','抱歉这个值不存在')
print(res) # 抱歉这个值不存在
# 类
# 通过类进行反射(反射出来的是普通方法)
func = getattr(Children,'drink')
print(func) # <function Children.drink at 0x0000014859B879D8> 普通方法
func(1) # 小孩下生喜欢喝勇闯天涯...
# 通过对象进行反射(反射出来的是绑定方法)
func = getattr(obj,'drink')
print(func) # <bound method Children.drink of at 0x000001CA32E03748>> 绑定方法
func() # 小孩下生喜欢喝勇闯天涯...
# 综合案例
strvar = 'eat123'
if hasattr(obj,strvar):
func = getattr(obj,strvar)
func()
else:
print('抱歉该成员不纯在')
- (3) setattr( ) 设置对象/类成员的值
class Father():
pass
class Mother():
pass
class Children(Father,Mother):
eye = '蓝色的'
weight = '1吨'
def eat(self):
print('小孩下生会喝奶')
def drink(self):
print('小孩下生喜欢喝勇闯天涯...')
def __la(self):
print('小孩自动拉,无法控制')
obj = Children()
# 对象
setattr(obj,'skin','白皮肤')
print(obj.skin) # 白皮肤
# 类
setattr(Children,'fromwhere','美国')
print(Children.fromwhere) # 美国
- (4) delattr( ) 删除对象/类成员的值
class Father():
pass
class Mother():
pass
class Children(Father,Mother):
eye = '蓝色的'
weight = '1吨'
def eat(self):
print('小孩下生会喝奶')
def drink(self):
print('小孩下生喜欢喝勇闯天涯...')
def __la(self):
print('小孩自动拉,无法控制')
obj = Children()
# 对象
setattr(obj,'skin','白皮肤')
print(obj.skin) # 白皮肤
# 类
setattr(Children,'fromwhere','美国')
print(Children.fromwhere) # 美国
# 对象
delattr(obj,'skin')
print(obj.skin) # 报错 has no attribute 'skin'
# 类
delattr(Children,'fromwhere')
print(Children.fromwhere) # 报错 has no attribute 'fromwhere'
127)反射(通过字符串反射模块中的成员)
'''
sys.modules 返回一个系统字典,字典的键是加载的所有模块
'__main__': <module '__main__' from '/mnt/hgfs/PycharmProjects/pythonProject1/pythoncode/装饰器.py'
字典中的__main__这个键对应的是该文件的模块对象
'''
def func1():
print('我是func1方法')
def func2():
print('我是func2方法')
def func3():
print('我是func3方法')
# 引入模块
import sys
print(sys.modules) # 系统字典
module = sys.modules['__main__'] # 获取本模块对象
print(module) # <module '__main__' from '/mnt/hgfs/PycharmProjects/pythonProject1/pythoncode/装饰器.py'>
while 1:
strvar = input('请输入你想要使用的功能')
if hasattr(module,strvar):
func = getattr(module,strvar)
func()
elif strvar.upper() == 'Q':
print('再见')
break
else:
print('没有该功能')
128)网络开发的两大架构
c/s 架构 : client server
B/S 架构 : Brower server
(1)bs 和 cs 架构之间的关系?
(2)哪一种架构更好呢?
1.c/s 架构(客户端和服务端)

2.B/S 架构(客户端和服务端交互)

129)基础概念
#一台主机有两个重要标识:
(1)mac地址:标记一台机器的物理地址 (不可变)
(2)ip 地址:#标记一台机器的逻辑地址 (可变)
#IP地址是指互联网协议地址(英语:Internet Protocol Address,又译为网际协议地址),是IP Address的缩写。ip地址用来标记网络上的每一台主机,方便在收发数据,网络请求时能够找到响应;
#ip地址分为两种 ipv4 和 ipv6: 分类ipv4 和 ipv6:
ipv4地址是一个32位的二进制数
ipv6地址是一个128位的二进制数
ipv4: 以4段点分十进制表示 X.X.X.X => 范围
0.0.0.0 ~ 255.255.255.255 地址范围2^32-1
ipv6 : 以8段冒分十六进制表示 X:X:X:X:X:X:X:X => 范围
0:0:0:0:0:0:0:0 ~ FFFF:FFFF:FFFF:FFFF:FFFF:FFFF:FFFF:FFFF 地址范围2^128-1
ip地址的最后一位0或者255 两个数字不能用,一般最后一位0表达的是网段,255代表广播地址
#网段 : 网段的作用,主要用来划分同一区域里的某些机器是否能够互相通信。在一个网段里可以不同过因特网,直接对话
判别的依据:如果IP地址和子网掩码相与得到的值相同就是同一网段
#内网 : 以下地址为预留地址,永远不会被当做公网ip来分配
192.168.0.0 - 192.168.255.255
172.16.0.0 - 172.31.255.255
10.0.0.0 - 10.255.255.255
#外网 :
在任何地方都可以访问的就是外网(排除防火墙的因素)
#子网掩码:区分网段和主机
255.255.255.0 / 255.255.0.0 / 255.0.0.0
ip1:192.168.10.12 ip2:192.168.1.16
#端口:"端口"是英文port的意译,是具体某个程序与外界通讯的出口。 取值范围:0~65535
使用时至少8000以上 访问地址加端口:192.168.2.1:8000
#局域网:在同一区域内由多台计算机互联形成通讯。【具有可重复的内网ip】
#广域网:在不同区域内有多台计算机互联形成通讯。【具有唯一的公网ip】
#交换机:对同一网段的不同机器之间进行数据转发的设备 [每一台机器和交换机相连,形成通信]
#路由器:对不同网段的不同机器之间进行数据转发的设备 [每一个局域网和路由器相连,形成通信]
#arp协议:每台主机都有arp缓存表 ,主要作用通过ip找mac的一个协议规则
【实现方式:通过交换机一次广播,一次单播找到的】
130)osi七层模型
人们按照分工不同把互联网协议从逻辑上划分了层级: osi4层,osi5层,osi7层 三类模型

131)局域网模型
局域网内,各个主机的通讯

132)广域网模型
广域网内,各个主机的通讯

133)端口
"""端口:具体某个程序与外界通讯的出口 取值范围:0~65535 """
192.168.2.1:8000 访问这个世界上任何一个电脑里的任何一个软件
自定义端口时,最好命名8000以上的端口号
https://blog.csdn.net/l_smalltiger/article/details/81951824
20 : FTP文件传输协议(默认数据口)
21 : FTP文件传输协议(控制)
22 : SSH远程登录协议
25 : SMTP服务器所开放的端口,用于发送邮件
80 : http用于网页浏览,木马Executor开放此端口
443: 基于TLS/SSL的网页浏览端口,能提供加密和通过安全端口传输的另一种HTTP => HTTPS
3306:MySQL开放此端口
134)交换机与路由器 , 发送数据包流程
交换机: 从下到上拆2层,拆到数据链路层
路由器: 从下到上拆3层,拆到网络层(得到对应的网段)
arp协议: 通过ip -> mac
rarp协议: 通过mac -> ip
"""arp协议整体是通过: 一次广播 + 一次单播 实现"""
# arp协议的完整过程:
电脑a发现目标主机没有mac,先发送arp广播包,把mac标记成全F的广播地址
交换机接受到arp的广播包,进行从下到上拆包,拆2层,拆到数据链路层看到全F广播地址,开始广播
把这个广播包发送给每一台主机
每台主机得到广播包后,都开始拆包,如果该数据包找寻的主机不是自己,自动舍弃
路由器得到arp广播包后,从下到上拆包,拆3层,拆到网络层,得到网段信息
通过路由器的对照信息表,找到网段对应的网关(接口)
对应网关的这台交换机得到arp广播包后,从下到上拆包,拆2层,发现全F广播地址进行广播
数据库主机收到广播包后,依次从下到上拆包,发现自己是目标要找的那台主机,
把自己的ip->mac对照信息封装,变成arp响应包,发送给对应的交换机
交换机得到arp响应包之后,依次进行单播,返回给最终的原主机
在回来的过程中,所有得到过相应arp广播包的主机都会自动更新自己的arp解析表,方便下次使用
135)TCP/UDP协议
# tcp
TCP(Transmission Control Protocol)一种面向连接的、可靠的、传输层通信协议(比如:打电话)
优点:可靠,稳定,传输完整稳定,不限制数据大小
缺点:慢,效率低,占用系统资源高,一发一收都需要对方确认
应用:Web浏览器,电子邮件,文件传输,大量数据传输的场景
# udp
UDP(User Datagram Protocol)一种无连接的,不可靠的传输层通信协议(比如:发短信)
优点:速度快,可以多人同时聊天,耗费资源少,不需要建立连接
缺点:不稳定,不能保证每次数据都能接收到
应用:IP电话,实时视频会议,聊天软件,少量数据传输的场景
# TCP 三次握手
客户端发送一个请求消息,与服务端建立连接
服务端接受这个请求,发出响应消息,回应客户端,也要与客户端a建立连接(看下客户端是否同意)
客户端接受服务端的响应消息之后,发送回复消息(表达同意,到此客户端与服务端建立连接成功)
# TCP 发送数据
每次发送一次数据,都会对应一个回执消息,如果发送方没有接受到回执消息,那么该数据包在发送一次;
# TCP 四次挥手
客户端向服务端发送一个断开连接请求(代表客户端没有数据给服务端)
服务端接受请求,发出响应
等到服务端所有数据发送完毕之后
服务端向客户端发送断开连接请求
客户端接受请求,发出响应
等到2msl,msl(最大报文段生存时间)这么长时间之后
客户端与服务端彻底断开连接
136)TCP下的socket使用
服务器文件
# ### socket 服务端
'''
一发一收一一对应,否则会导致数据异常
send 发送 recv 接受
'''
import socket
# 1. 创建一个socket对象
sk = socket.socket()
# 一个端口绑定多个程序(仅在测试时使用)
sk.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
# 2.在网络中注册该主机(绑定对应得ip和端口号)
'''默认本地ip : '127.0.0.1' => localhost'''
sk.bind(('127.0.0.1',9000))
# 3. 开启监听
sk.listen()
# 4. 三次握手获取连接主机得 对象和ip地址
conn,addr = sk.accept()
# 5. 收发数据得逻辑
res = conn.recv(1024)
print(res.decode()) # 今天学习网络编程
conn.send('好好学习天天向上'.encode())
# 6. 四次护手
conn.close()
# 7. 退还端口
sk.close()
客户端文件
# ### 客户端
import socket
# 1.创建一个socket对象
sk = socket.socket()
# 2. 与服务器建立连接
sk.connect(('127.0.0.1',9000))
# 3. 收发数据得逻辑
'''发送的数据类型是二进制字节流 '''
'''b开头的字符串是二进制字节流格式,要求字符串类型必须是ascii'''
sk.send('今天学习网络编程'.encode())
res = sk.recv(1024)
print(res.decode())
# 4. 关闭连接
sk.close()
137)UDP下的socket使用
服务端文件
# ### udp协议 服务端
import socket
# 1.创建udp对象
'''
默认创建协议都是udp
type=socket.SOCK_DGRAM 固定写法创建udp协议
'''
sk = socket.socket(type=socket.SOCK_DGRAM)
# 2. 在网络中注册该主机(绑定ip和端口号)
sk.bind(('127.0.0.1',9000))
# 3. 收发数据的逻辑
'''udp协议下,默认第一次只能接收数据(没有三次握手,不清楚对方的ip和端口号)'''
# 接收数据
msg,addr = sk.recvfrom(1024)
print(msg.decode()) # 你好吗
print(addr) # ('127.0.0.1', 41948)
# 发送数据
sk.sendto('其实我还好'.encode(),addr)
# 4. 关闭连接
sk.close()
客户端文件
# ### udp协议 客户端
import socket
# 1. 创建udp对象
sk = socket.socket(type=socket.SOCK_DGRAM)
# 2. 收发数据的逻辑
# 发送数据
sk.sendto('你好吗'.encode(),('127.0.0.1',9000))
#接收数据
msg,addr = sk.recvfrom(1024)
print(msg.decode()) # 其实我还好
print(addr) # ('127.0.0.1',9000)
# 3. 关闭连接
sk.close()
138)struct模块使用
import struct
'''
pack 打包
把任意长度数字转换成具有固定4个字节长度的字节流
unpack 解包
把4个字节长度的值恢复成原来的数字,返回元组
'''
# pack打包
# i => int 要转换的当前类型是整形
'''范围: -21亿~21亿左右 控制在1.8G以内'''
res = struct.pack('i',1324654)
print(res,len(res)) # b'n6\x14\x00' 4
res = struct.pack('i',3)
print(res,len(res)) # b'\x03\x00\x00\x00' 4
# unpack解包
# i => int 把对应的数据转换成整形
tup = struct.unpack('i',res)
print(tup) # (3,)
139)黏包现象
'''
黏包现象:
(1)发送端,数据小,时间间隔短,造成黏包
(2)接收端,没有及时接收数据,可能把多次发送的数据当成一条截取
'''
'''
解决黏包场景:
应用场景在实时通讯时,需要阅读此次发的消息是什么
不需要解决黏包场景:
下载或者上传文件的时候,最后要把包都融合在一起,黏包无所谓
'''
服务端文件
# ### udp协议 服务端
import socket
import struct
# 1. 创建一个socket对象
sk = socket.socket()
# 一个端口绑定多个程序(仅在测试时使用)
sk.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
# 2.在网络中注册该主机(绑定对应得ip和端口号)
'''默认本地ip : '127.0.0.1' => localhost'''
sk.bind(('127.0.0.1',9000))
# 3. 开启监听
sk.listen()
# 4. 三次握手获取连接主机得 对象和ip地址
conn,addr = sk.accept()
# 5. 收发数据得逻辑
strvar = input('[服务端]请输入您要发送的数据')
msg = strvar.encode()
res = struct.pack('i',len(msg))
# 第一次发送数据 (数据长度)
conn.send(res)
# 第二次发送数据 (真实数据 )
conn.send(msg)
# 第三次发送数据 (真实数据)
conn.send('kajsldk阿萨大'.encode())
# 6. 四次护手
conn.close()
# 7. 退还端口
sk.close()
客户端文件
# ### udp协议 客户端
import struct
import socket
# 1. 创建udp对象
sk = socket.socket()
# 2. 与服务器建立连接
sk.connect(('127.0.0.1',9000))
# 3. 收发数据得逻辑
#第一次接收数据(数据长度)
num = sk.recv(4) # 传输的struct打包后 字节长度都是4
tup = struct.unpack('i',num) # 将struct传输的数据解包
print(tup[0])
# 第二次接收数据(真实数据)
res = sk.recv(tup[0]) # 将边界固定
print(res.decode())
# 第三次接收数据(真实数据)
res = sk.recv(1024)
print(res.decode())
# 4. 关闭连接
sk.close()
140)socketserver 解决tcp下的并发操作
'''socketserver的提出,是为了允许在tcp协议下进行并发操作'''
服务器端
# ### 服务端
'''socketserver的提出,是为了允许在tcp协议下进行并发操作'''
import socketserver
class Myserver(socketserver.BaseRequestHandler):
def handle(self):
'''
print(self.request) 获取传输对象 和 Ip地址
print(self.client_address) 获取 Ip地址
<socket.socket fd=4, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 9000), raddr=('127.0.0.1', 52090)>
('127.0.0.1', 52090)
'''
conn = self.request # 获取传输对象 和 Ip地址
while True:
# 接收数据
res = conn.recv(1024)
res2 = res.decode()
print(res2)
# 发送数据
conn.send( res2.upper().encode() )
# ThreadingTCPServer(ip端口号, 自定义的类)
server = socketserver.ThreadingTCPServer(('127.0.0.1',9000),Myserver)
# 调用内部相关函数
server.serve_forever()
客户端
# ### 客户端
import socket
sk = socket.socket()
sk.connect(('127.0.0.1',9000))
# 处理收发数据逻辑
while True:
sk.send(b'kjhsdf')
res = sk.recv(1024)
print(res.decode())
sk.close()
141)hashlib模块(加密和校验)
'''
hashlib模块的加密原则是单项不可逆的
md5算法: 可以把字符串变成具有固定长度的32位十六进制字符串
'''
md5算法(要比shal算法好一些)**
import hashlib
# 1.基本语法
hs = hashlib.md5()
# 2.把要加密的数据更新到对象中 [update => 把字节流更新到对象之后,进行加密 ]
hs.update('111222'.encode())
# 3.获取十六进制的字符串
print(hs.hexdigest()) # 00b7691d86d96aebd21dd9e138f90840
# 加盐(加key,加一个关键字)相当于二次加密提高复杂度
hs = hashlib.md5('wawayu_'.encode())
hs.update('111222'.encode())
res = hs.hexdigest()
print(res)
shal系列算法(位数虽然多,私密性一般)
import hashlib
import random
'''无论是加盐 还是 加密密码 都需要数据类型为二进制字节流'''
# hs = hashlib.shal() # 结果是具有固定长度40位的十六进制字符串
hs = hashlib.sha512('WAWAyu_'.encode()) # 结果是具有固定长度128位的十六进制字符串
hs.update('sha系列算法'.encode())
res = hs.hexdigest()
'''
58fb85c60d4b818a35bfab988d4429a7fddeb36c2ddd84cffb4bd2b222c4f30da69d414e32d77c00a3f307a066330da6e8009d67fa9639f7e76fb65bbfdc6920 128
'''
print(res,len(res))
hmac加密算法(md5应用比较广泛 不如hmac算法私密)
import hmac
import os
key = b'xdogaa_'
msg = b'111222'
# new(盐(字节流),密码(字节流))
hm = hmac.new(key,msg)
res = hm.hexdigest()
'''
15dc06239edec46d34b185f8b8791cb6 32
'''
print(res,len(res))
# 动态加盐
'''
os.urandom(位数) 返回随机的二进制字节流
'''
res = os.urandom(10)
print(res,len(res))# b's\xc7Y\x96\x06sy\x91\xff\x05' 10
key = os.urandom(64)
msg = b'112233'
hm = hmac.new(key,msg)
res = hm.hexdigest()
print(res,len(res))# 89bb06251cc65cfc12fa2c7ab9374045 32
142)文件校验(利用md5算法)
- 小文件校验
import hashlib
def check(filename):
with open(filename,mode='rb') as fp:
result = fp.read()
hs = hashlib.md5(result)
return hs.hexdigest()
res1 = check('client.py')
res2 = check('server.py')
print(res1 == res2)
- update 使用
'''update 可以分批次进行加密 等价于同一个MD5对象 每一次的update(相当于不断追加 加密)'''
# update的使用
import hashlib
def check(filename):
with open(filename,mode='rb') as fp:
result = fp.read()
hs = hashlib.md5(result)
return hs.hexdigest()
res1 = check('client.py')
res2 = check('server.py')
print(res1 == res2)
starvar = '今天星期六,明天星期天'
hs = hashlib.md5()
hs.update(starvar.encode())
res1 = hs.hexdigest()
print(res1) # 0a82f7ac8643de52b67b2c9f5a2468a2
starvar2 = '今天星期天,明天星期一'
hs.update(starvar2.encode())
res2 = hs.hexdigest()
print(res2) # 2ce705bcd1a83c8034b517cb735f4766
starvar3 = '今天星期六,明天星期天今天星期天,明天星期一'
hs2 = hashlib.md5()
hs2.update(starvar3.encode())
res3 = hs2.hexdigest()
print(res3) # 2ce705bcd1a83c8034b517cb735f4766
-
大文件校验
-
方式一
import hashlib def check(filename): hs = hashlib.md5() with open(filename,mode='rb') as fp: while True: # fp.read(5) 表示每次最多读取5个字节 少于5个也会进行读取 if fp.read(5): hs.update(fp.read(5)) else: break res1 = check('client.py') res2 = check('server.py') print(res1 == res2) -
方式二
import hashlib import os def check(filename): hs = hashlib.md5() filesize = os.path.getsize(filename) with open(filename,mode='rb') as fp: while filesize: # 一次最多读取60个字节 少于60有多少读取多啊少 content = fp.read(60) # 文件的字节总数 每次减少 fp.read(60)实际读取的字节个数 等于0时退出循环 filesize -= len(content) hs.update(content) return hs.hexdigest() res1 = check('client.py') res2 = check('server.py') print(res1 == res2)
-
143)服务端的合法性校验
# ### 服务端
import socketserver
import hmac
import os
class Myserver(socketserver.BaseRequestHandler):
secret_key = '小兔儿乖乖,把门开开'
def shouquan(self):
# 获取传输对象 和 Ip地址
conn = self.request
# 随机生成32位二进制字节流
msg = os.urandom(32)
# 把字节流发送给客户端
conn.send(msg)
# 服务端自己先进行数据校验
hm = hmac.new(self.secret_key.encode(), msg)
ser_res = hm.hexdigest()
# 服务端接收客户端发送的数据结果进行比对
cli_res = conn.recv(1024).decode()
# 相同返回True 反之亦然
return True if ser_res == cli_res else False
def handle(self):
if self.shouquan():
self.request.send('True'.encode())
else:
self.request.send('False'.encode())
server = socketserver.ThreadingTCPServer(('127.0.0.1',9001),Myserver)
# 开启端口重复使用模式
socketserver.TCPServer.allow_reuse_address = True
# 调用内部相关函数
server.serve_forever()
# ### 客户端
import socket
import hmac
import os
sk = socket.socket()
sk.connect(('127.0.0.1',9001))
# 授权函数
def shouquan(secret_key):
# 接收服务器发送过来的随机二进制字节流
msg = sk.recv(32)
# hmac.new中的两个参数都是字节流
hm = hmac.new(secret_key.encode(),msg)
# 获取生成的加密固定长度32位的字符串
cli_res = hm.hexdigest()
# 把计算结果发送给服务端进行校验
sk.send(cli_res.encode())
# 接收数据
return sk.recv(1024).decode()
# 处理收发逻辑
secret_key = '小兔儿乖乖,把门开开'
res = shouquan(secret_key)
if res == 'True':
print('服务器校验成功')
else:
print('服务器校验失败')
sk.close()
144)TCP登录
# ### 服务端
import socketserver
import hashlib
import json
class Myserver(socketserver.BaseRequestHandler):
# 判断是否找到数据
sign = False
# md5加密 密码
def get_md5_pwd(self,admin,pwd):
hs = hashlib.md5(admin.encode())# 加盐
hs.update(pwd.encode())# 加密pwd
return hs.hexdigest()# 获取加密结果
# 授权函数
def auth(self):
# 接收客户端数据
res = self.request.recv(1024)
# 序列化字符串得到字典
dic = json.loads(res.decode())
# 将客户端的账号密码和数据库中进行校验
with open('account_pwd.txt',mode='r',encoding='utf-8') as fp:
for i in fp:
acount,pwd = i.strip().split(':')
if dic['account'] == acount and self.get_md5_pwd(dic['account'],dic['password']) == pwd:
msg = {'code':1,'msg':'登录成功'}
# 将字典序列化成字符串
result = json.dumps(msg).encode()
self.request.send(result)
self.sign = True
break
if self.sign == False:
msg = {'code': 0, 'msg': '登录失败'}
# 将字典序列化成字符串
result = json.dumps(msg).encode()
self.request.send(result)
def handle(self):
self.auth()
server = socketserver.ThreadingTCPServer(('127.0.0.1',9000),Myserver)
# 开启端口重复使用模式
socketserver.TCPServer.allow_reuse_address = True
# 调用内部相关函数
server.serve_forever()
# ### 客户端
import socket
import hashlib
import json
sk = socket.socket()
sk.connect(('127.0.0.1',9000))
# 处理收发逻辑
account = input('请输入账号')
pwd = input('请输入密码')
dic = {'account':account,'password':pwd}
# 将字典序列化成字符串
msg = json.dumps(dic)
# 向服务端发送数据
sk.send(msg.encode())
# 接收服务端数据
res = sk.recv(1024)
# 序列化字符串得到字典
data = json.loads(res.decode())
print(data['msg'])
sk.close()
145)进程语法
并发进程 : 一个cpu执行多个程序(单核)
**并行进程 : 多个cpu同时执行不同程序(双核或以上基本配置4核) **
# ### 进程 process
import os
'''
# ps -aux 查看进程号
# ps -aux | grep 2860 过滤查找 这个程序
# 强制杀死进程
kill -9 进程号
'''
# 获取当前进程号
res = os.getpid()
print(res)
# 获取当前进程的父进程
res1 = os.getppid()
print(res1)
-
进程的使用(默认下谁快执行谁)
-
(1)
# ### 进程 process import os from multiprocessing import Process def func(): # 1.子进程id:6833,2.父进程id:6830 print('1.子进程id:{},2.父进程id:{}'.format(os.getpid(),os.getppid())) if __name__ == '__main__': # 创建子进程,返回进程对象 p = Process(target=func) # 调用子进程 p.start() # 3.主进程id:6830,4.父进程id:6607 print('3.主进程id:{},4.父进程id:{}'.format(os.getpid(),os.getppid())) -
(2)创建带有参数的进程
# ### 进程 process import os,time from multiprocessing import Process # 创建带有参数的进程 def func(n): time.sleep(1) for i in range(1,n+1): print('1.子进程id:{},2.父进程id:{}'.format(os.getpid(),os.getppid())) if __name__ == '__main__': n = 6 # target = 指定任务 args = 参数元组 必须加逗号 p = Process(target=func, args=(n,)) p.start() for i in range(1,n+1): print('*' * i) -
进程之间的数据彼此隔离
# ### 进程 process import os,time from multiprocessing import Process total = 100 def func(): global total total += 1 print(total,'子进程') #101 if __name__ == '__main__': p = Process(target=func) p.start() time.sleep(1) print(total,'主进程') # 100 -
多个进程之间的异步性(每次执行顺序由cpu决定)
''' 1.多个进程之间时异步的并发程序,因为cpu调度策略问题,不一定先执行哪一个任务 默认来看,主进程执行速度稍快于子进程,因为子进程创建时,需要分配空间资源可能会阻塞 组赛态,cpu会立刻切换任务,以让程序整的速度效率最大化 2.默认主进程要等待所有的子进程执行结束之后,再统一关闭程序,释放资源 若不等待,子进程有可能不停的在系统的后台占用cpu和内存资源形成僵尸进程 为了方便进程的管理,主进程默认等待子进程 ''' # ### 进程 process import os,time from multiprocessing import Process total = 100 def func(i): print('1.子进程id:{},2.父进程id:{}'.format(os.getpid(),os.getppid()),i) if __name__ == '__main__': for i in range(1,11): p = Process(target=func,args=(i,)) p.start() print('主进程结束...',os.getpid())
join的基本使用(同步子父进程)
- (1)
'''必须等待当前的这个子进程执行结束之后,再去执行下面的代码,用来同步子父进程''' from multiprocessing import Process def func(): print('1.领导在吗,找你有点事') if __name__ == '__main__': p = Process(target=func) p.start() p.join() print('2.我想把工资涨到6万')- (2)多进程场景中的join
# ### 进程 process from multiprocessing import Process def func(i): print('发送第一封邮件{}: 我的亲亲领导,你在么'.format(i)) if __name__ == '__main__': lst = [] for i in range(1,11): p = Process(target=func,args=(i,)) p.start() # 如果join 写在此处会导致程序变成同步 lst.append(p) # 把所有的进程对象都放在列表中,统一使用.join进行管理 for i in lst: i.join() print('发送第二封邮件: 我想说,工资可以给我涨到6万') -
146)使用自定义进程类,创建过程
- 基本语法
'''必须使用run方法 不能改名字'''
from multiprocessing import Process
import os
class MyProcess(Process):
def run(self):
print('1.子进程id:{},2.父进程id:{}'.format(os.getpid(),os.getppid()))
if __name__ == '__main__':
p = MyProcess()
p.start()
- 带有参数的自定义进程类
from multiprocessing import Process
import os
class Myprocess(Process):
def __init__(self,name):
# 手动调用一下父类的构造方法,完成系统成员的初始化
super().__init__()
self.name = name
def run(self):
print('1.子进程id:{},2.父进程id:{}'.format(os.getpid(),os.getppid()))
print(self.name)
if __name__ == '__main__':
p = Myprocess('我是参数')
p.start()
147)守护进程
'''
守护进程守护的是主进程,当主进程所有代码执行完毕之后,立刻强制杀死守护进程
'''
- 基本语法
from multiprocessing import Process
def func():
print('start... 当前的子进程')
print('end... 当前的子进程')
if __name__ == '__main__':
p = Process(target=func)
# 在进程开启之前,设置守护进程
p.daemon = True
p.start()
print('主进程执行结束 ....') # 只执行主进程 子进程不会执行
- 多个子进程的守护场景
'''
默认主进程等待所有非守护进程,也就是子进程执行结束之后,再关闭程序,释放资源
守护进程只要在主进程代码执行结束时,就会自动关闭
'''
# p2守护进程执行与否取绝于cpu 一旦执行了主进程的代码 会立即终止掉 p2守护进程
from multiprocessing import Process
import time
def func1():
print('start... func1当前的子进程')
print('end... func1当前的子进程')
def func2():
count = 1
while True:
print('*' * count)
time.sleep(1)
count += 1
if __name__ == '__main__':
p1 = Process(target=func1)
p2 = Process(target=func2)
# 把p2这个进程变成守护进程
p2.daemon = True
p1.start()
p2.start()
print('主进程执行结束 ....')
- 守护进程用途:监控报活
from multiprocessing import Process
import time
def alive():
while True:
print('3号服务器向总监控服务器发送报活信息: i am ok~')
time.sleep(1)
def func():
while True:
try:
print('3号服务器负责抗住3万用户量的并发访问')
time.sleep(3)
# 主动排除执行错误的异常,触发except分支
raise RuntimeError
except:
print('3号服务器扛不住了..快来修理我..')
break
if __name__ == '__main__':
p1 = Process(target=alive)
p2 = Process(target=func)
# p1开启守护进程
p1.daemon = True
p1.start()
p2.start()
# 必须等待p2这个子进程执行完毕之后,再放行主进程下面的代码
# 下面主进程代码执行结束,立刻杀死守护进程,失去了报活功能
p2.join()
print('主进程执行结束 ....')
148)lock互斥锁
from multiprocessing import Process,Lock
'''
上锁和解锁是一对,连续上锁不解锁是死锁,只有在解锁的状态下,其他进程才有机会上锁
连续两个上锁挨在一起会形成死锁
'''
# 创建一把锁
lock = Lock()
# 上锁
lock.acquire()
lock.acquire()
print('我在尿尿,你在等待,厕所进行时')
# 解锁
lock.release()
lock.release()
- 模拟360抢票
from multiprocessing import Process,Lock
import time,random,json
# 1.读写数据库当中的票数
def wr_info(sign,dic = None):
if sign == 'r':
with open('account_pwd.txt',mode='r',encoding='utf-8') as fp:
dic = json.load(fp)
return dic
elif sign == 'w':
with open('account_pwd.txt',mode='w',encoding='utf-8') as fp:
json.dump(dic,fp)
# 2.执行抢票的方法
def get_ticket(person):
# 先获取数据库中实际票数
dic = wr_info('r')
# 模拟网络延迟
time.sleep(random.uniform(0.1,0.7))
# 判断票数
if dic['acount'] > 0:
print('{}抢到票了'.format(person))
# 抢到票后,让当前票数减1
dic['acount'] -= 1
# 更新存入数据库中
wr_info('w',dic)
else:
print('{}没有抢到票哦'.format(person))
# 3.对抢票和读写票数做一个统一的调用
def main(person,lock):
# 查看剩余票数
dic = wr_info('r')
print('{}查看票数剩余:{}'.format(person,dic['acount']))
# 上锁
lock.acquire()
# 开始抢票
get_ticket(person)
# 解锁
lock.release()
if __name__ == '__main__':
lock = Lock()
lst = ['张无敌','李四','赵六','西瓜皮','校长','草鞋']
for i in lst:
p = Process(target=main,args=(i,lock,))
p.start()
149)Semaphore信号量(上多把锁)
'''
总结: Semaphore 可以设置上锁的数量,同一时间上多把锁
创建进程时,是异步并发,执行任务时,是同步程序
'''
# ### Semaphore 本质上就是锁,只不过是多个进程上多把锁,可以控制上锁的数量
'''Semaphore = lock + 数量 '''
from multiprocessing import Semaphore,Process
import time,random
'''
# 同一时间允许多个进程上5把锁
sem = Semaphore(5)
# 上锁
sem.acquire()
print('执行操作...')
# 解锁
sem.release()
'''
def sing_ktv(person,sem):
# 上锁
sem.acquire()
print('{}进入了唱吧ktv,正在唱歌~'.format(person))
# 唱一段时间
time.sleep(random.randrange(4,8))
print('{}离开了唱吧ktv,唱完了...'.format(person))
# 解锁
sem.release()
if __name__ == '__main__':
# 上五把锁
sem = Semaphore(5)
lst = ['赵凤勇','沈思雨','赵万里','张宇','假摔先','孙杰龙','陈璐','鱼于汉','王一博','小站']
for i in lst:
p = Process(target=sing_ktv,args=(i,sem))
p.start()
150)事件(Event)
'''
阻塞事件:
e = Event()生成事件对象e
e.wait()动态给程序加阻塞,程序当中是否加阻塞完全取绝于该对象中的is_set() 默认为False
e.is_set()如果是True 不加阻塞
e.is_set()如果是False 加阻塞
控制这个属性的值
set()方法 将这个属性的值改为True
clear()方法 将这个属性的值改为False
is_set()方法 判断当前的属性是否为True (默认是False)
'''
# 1
from multiprocessing import Event,Process
e = Event()
# 判断内部成员属性死否是False
print(e.is_set()) # False
# 如果是False加阻塞
e.wait()
print('代码执行中')
# 2
from multiprocessing import Event,Process
e = Event()
# 将这个属性的值改为True
e.set()
# 如果内部成员属性是否是True 代码程序不阻塞
e.wait()
print('代码执行中...') # 代码执行中...
# 3
from multiprocessing import Event,Process
e = Event()
# 将这个属性的值改为True
e.set()
# 如果内部成员属性是否是True 代码程序不阻塞
e.wait()
print('代码执行中...') # 代码执行中...
# 将这个属性的值改为False
e.clear()
e.wait()
print('代码执行中....2') # 代码阻塞,不会执行
# 4
e = Event()
# 表示最多等待三秒
e.wait(3)
print('代码执行中... 3') # '代码执行中... 3'
红绿灯切换
from multiprocessing import Event,Process
import time,random
# 红绿灯切换
def traffic_light(e):
print('红灯亮')
while True:
if e.is_set():
# 绿灯状态 -> 切红灯
time.sleep(1)
print('红灯亮')
# True -> False
e.clear()
else:
# 红灯状态 -> 切绿灯
time.sleep(1)
print('绿灯亮')
# False -> True
e.set()
# 车的状态
def car(e,i):
# 判断是否是红灯,如果是加上wait阻塞
if not e.is_set():
print('car{} 在等待 ...'.format(i))
e.wait()
# 否则不是,代表绿灯通行
print('car{} 通行了 ...'.format(i))
if __name__ == '__main__':
e = Event()
# 创建交通灯
p1 = Process(target=traffic_light,args=(e,))
p1.start()
# 创建小车进程
for i in range(1,21):
time.sleep(random.randrange(2))
p2 = Process(target=car,args=(e,i))
p2.start()
151)进程队列
from multiprocessing import Queue,Process
import queue
'''顺序: 先进先出,后进后出'''
# 创建进程队列
q = Queue()
# put() 存放
q.put(1)
q.put(2)
q.put(3)
# get() 获取
'''在获取不到任何数据时,会出现阻塞'''
print(q.get()) # 1
print(q.get()) # 2
print(q.get()) # 3
print(q.get()) # 会出现阻塞
from multiprocessing import Queue,Process
import queue
'''顺序: 先进先出,后进后出'''
# 创建进程队列
q = Queue()
# put() 存放
q.put(1)
q.put(2)
q.put(3)
# get_nowait() 拿不到数据报异常
'''window效果正常 linux不兼容'''
try:
print(q.get_nowait()) # 1
print(q.get_nowait()) # 2
print(q.get_nowait()) # 3
print(q.get_nowait())
except queue.Empty:
pass
from multiprocessing import Queue,Process
import queue
'''顺序: 先进先出,后进后出'''
# 当前队列最大长度为3(元素个数最多3个)
'''在指定队列长度的情况下,如果塞入过多的数据,会导致阻塞'''
# q = Queue(3)
# q.put(1)
# q.put(2)
# q.put(3)
# q.put(3)
'''使用put_nowait 在队列已满的情况下,塞入数据会直接报错'''
q2 =Queue(3)
try:
q2.put_nowait(111)
q2.put_nowait(222)
q2.put_nowait(333)
q2.put_nowait(444)
except:
pass
进程间的通信tpc
from multiprocessing import Queue,Process
import queue
def func(q):
# 2.子进程获取主进程存放的数据
res = q.get()
print(res) # 娃娃鱼
# 3.子进程中存放数据
q.put('威震天')
if __name__ == '__main__':
q = Queue()
p = Process(target=func,args=(q,))
p.start()
# 1. 主进程存放数据
q.put('娃娃鱼')
# 为了等待子进程把数据存放队列后,主进程再获取数据
p.join()
# 4. 主进程获取子进程存放的数据
print(q.get()) # 威震天
152)生产者消费模型
'''
# 爬虫案例
1号进程专责抓取其他多个网站中相关的关键字信息,正则匹配到队列中(mysql)
2号进程负责把队列内存中的内容拿取出来,将经过修饰后的内容布局到自己的网站中
1号进程可以理解成生产者
2号进程可以理解成消费者
从程序上来看
生产者负责存储数据(put)
消费者负责获取数据(get)
生产者和消费者比较理想的模型
是生产数据的速度 和 消费数据的速度 相对一致
'''
from multiprocessing import Queue,Process
import time,random
# 消费者模型
def consumer(q,name):
while True:
# 获取队列中的数据
food = q.get()
# 如果 food is None 代表没有更多的数据可以消费了
if food is None:
break
time.sleep(random.uniform(0.1, 1))
print('{}吃了{}'.format(name,food))
# 生产者模型
def producer(q,name,food):
for i in range(1,5):
time.sleep(random.uniform(0.1,1))
# 展示生产的数据
print('{}生产了{}'.format(name,food+str(i)))
# 存储生产的数据到队列中
q.put(food + str(i))
if __name__ == '__main__':
q = Queue()
p1 = Process(target=consumer,args=(q,'赵万里'))
p2 = Process(target=producer,args=(q,'赵沈阳','香蕉'))
p1.start()
p2.start()
p2.join()
q.put(None) # 香蕉1 香蕉2 香蕉3 香蕉4 None 取出一个少一个
JoinableQueue队列改写
'''
put 存放
get 获取
task_done 计算器属性值 -1
join 配合 task_done来使用 阻塞
put 一次数据,队列的内置计数器属性值+1
get 一次数据,必须通过task_done让队列的内置计数器属性值 -1
join: 会根据队列计数器的属性值来判断是否阻塞或者放行
队列计数器属性 等于 0 代码不阻塞放行
队列计数器属性 不等 0 代码阻塞
'''
from multiprocessing import JoinableQueue
jq = JoinableQueue()
jq.put('赵万里') # +1
jq.put('赵沈阳') # +1
print(jq.get())
print(jq.get())
# print(jq.get()) 阻塞
jq.task_done() # -1
jq.task_done() # -1
jq.join()
print('代码执行结束 ...')
改写
from multiprocessing import JoinableQueue,Process
import time,random
# 消费者模型
def consumer(q,name):
while True:
# 获取队列中的数据
food = q.get()
time.sleep(random.uniform(0.1, 1))
print('{}吃了{}'.format(name,food))
# 让队列的内置计数器属性 -1
q.task_done()
# 生产者模型
def producer(q,name,food):
for i in range(1,5):
time.sleep(random.uniform(0.1,1))
# 展示生产的数据
print('{}生产了{}'.format(name,food+str(i)))
# 存储生产的数据到队列中
q.put(food + str(i))
if __name__ == '__main__':
q = JoinableQueue()
p1 = Process(target=consumer,args=(q,'赵万里'))
p2 = Process(target=producer,args=(q,'赵沈阳','香蕉'))
# 开启守护 主进程执行结束 立即抹杀掉p1子进程
p1.daemon = True
p1.start()
p2.start()
# 开启等待 必须子继承p2执行结束后才执行主进程
p2.join()
# 必须等待队列中的所有数据全部消费完毕,再放行 计数器为 0 才会执行 35行代码
q.join()
print('代码执行结束 ...')
153)Manager( list 列表 , dict 字典) 进程之间共享数据
from multiprocessing import Process,Manager,Lock
def mywork(data,lock):
lock.acquire()
data[0] += 1
lock.release()
if __name__ == '__main__':
lst = []
lock = Lock()
# 创建共享数据对象
# m = Manager()
# data = m.dict({'count':5000})
# print(data,type(data))
# 创建共享列表
m = Manager()
data = m.list([100,200,300])
print(data, type(data))
for i in range(10):
p = Process(target=mywork,args=(data,lock))
p.start()
lst.append(p)
for i in lst:
i.join()
print(data) # [110, 200, 300]
154)线程

'''
进程是资源分配的最小单元
线程是cpu执行调度的最小单元
'''
from threading import Thread
from multiprocessing import Process
import os,time,random
def func(i):
time.sleep(random.uniform(0.1,0.9))
print('当前线程号:{}'.format(os.getpid()),i)
if __name__ == '__main__':
for i in range(10):
t = Thread(target=func,args=(i,))
t.start()
print(os.getpid())
并发的多进程和多线程之间,谁的速度快(多线程更快)
from threading import Thread
from multiprocessing import Process
import os,time,random
# 多线程速度
def func(i):
time.sleep(random.uniform(0.1,0.9))
print('当前线程号:{}'.format(os.getpid()),i)
if __name__ == '__main__':
lst = []
startTime = time.time()
for i in range(10000):
t = Thread(target=func,args=(i,))
t.start()
lst.append(t)
for i in lst:
i.join()
endTime = time.time()
print('运行的时间{}'.format(endTime - startTime)) # 4秒多
# 多进程速度
# if __name__ == '__main__':
# lst = []
# startTime = time.time()
# for i in range(10000):
# p = Process(target=func,args=(i,))
# p.start()
# lst.append(p)
#
# for i in lst:
# i.join()
# endTime = time.time()
# print('运行的时间{}'.format(endTime - startTime)) 200多秒
多线程之间 数据共享
from threading import Thread
from multiprocessing import Process
import os,time,random
num = 100
lst = []
def func():
global num
num -= 1
if __name__ == '__main__':
for i in range(100):
t = Thread(target=func)
t.start()
lst.append(t)
for i in lst:
i.join()
print(num) # 0
用类定义线程
from threading import Thread
from multiprocessing import Process
import os,time,random
# 必须继承父类Thread
class MyThread(Thread):
def __init__(self,name):
super().__init__()
self.name = name
def run(self):
print('当前进程号{},name={}'.format(os.getpid(),self.name))
if __name__ == '__main__':
t = MyThread('我是线程')
t.start()
print('当前进程号{}'.format(os.getpid()))
155)线程中的相关属性
'''
线程.is_alive() 检测线程是否仍然存在
线程.setName() 设置线程名字
线程.getName() 获取线程名字
currentThread().ident 查看线程id号
enumerate() 返回目前正在运行的线程列表
activeCount() 返回目前正在运行的线程数量
'''
from threading import Thread
from multiprocessing import Process
import os,time,random
def func():
time.sleep(1)
if __name__ == '__main__':
t = Thread(target=func)
t.start()
# 检测线程是否仍然存在
print(t.is_alive()) # True
# 线程.getname() 获取线程名字
print(t.getName()) # Thread-1
# 设置线程名字
t.setName('抓API接口')
print(t.getName()) # 抓API接口
from threading import Thread,currentThread
from multiprocessing import Process
import os,time,random
def func():
# 当前子线程id号是18064,进程号12768
print('当前子线程id号是{},进程号{}'.format(currentThread().ident,os.getpid()))
if __name__ == '__main__':
t = Thread(target=func)
t.start()
# 当前主线程id号是4356,进程号12768
print('当前主线程id号是{},进程号{}'.format(currentThread().ident,os.getpid()))
from threading import Thread,currentThread,enumerate,activeCount
from multiprocessing import Process
import os,time,random
def func():
time.sleep(0.1)
if __name__ == '__main__':
for i in range(5):
t = Thread(target=func)
t.start()
# 返回目前正在运行的线程列表
lst = enumerate()
print(lst,len(lst)) # 6
# 返回当前正在运行的线程数量
print(activeCount()) # 6
156)守护线程
'''
守护线程 : 等待所有线程全部执行完毕之后,自己在终止程序,守护所有线程
'''
from threading import Thread
import time
def func1():
while True:
time.sleep(1)
print('我是函数func1')
def func2():
print('我是func2 start ...')
time.sleep(3)
print('我是func2 end...')
def func3():
print('我是func6 start ...')
time.sleep(6)
print('我是func6 end...')
if __name__ == '__main__':
t = Thread(target=func1)
t2 = Thread(target=func2)
t3 = Thread(target=func3)
t.setDaemon(True)
t.start()
t2.start()
t3.start()
print('主线程执行结束...')
157)线程的安全问题
from threading import Thread,Lock
import time
n = 0
lock = Lock()
lst = []
def func1(lock):
# with 语法自动实现上锁和解锁
with lock:
for i in range(1000000):
global n
n+=1
def func2(lock):
# with 语法自动实现上锁和解锁
with lock:
for i in range(1000000):
global n
n -= 1
if __name__ == '__main__':
startTime = time.time()
for i in range(10):
t1 = Thread(target=func1,args=(lock,))
t1.start()
t2 = Thread(target=func2, args=(lock,))
t2.start()
lst.append(t1)
lst.append(t2)
for i in lst:
i.join()
endTime = time.time()
print('程序运行时间{}'.format(endTime - startTime)) # 程序运行时间2.8699636459350586
print(n) # 0
158)同一时间对多个线程上多把锁
import random
from threading import Thread,Semaphore
import time
def func(i,sem):
with sem:
print('我在偷西瓜...我是{}号'.format(i))
time.sleep(random.uniform(3,8))
if __name__ == '__main__':
sem = Semaphore(5)
for i in range(30):
t = Thread(target=func,args=(i,sem))
t.start()
'''
创建线程是异步的, 上锁的过程会导致程序变成同步;
'''
159)互斥锁 死锁 递归锁
-
语法上的死锁
'''连续上锁不能解锁''' from threading import Thread,Semaphore,Lock,RLock import time,random lock = Lock() lock.acquire() lock.acquire() '''是两把不同的锁''' lock1 = Lock() lock2 = Lock() lock1.acquire() lock2.acquire() print('代码执行中....') lock1.release() lock2.release() -
逻辑上的死锁(用递归锁解决)
from threading import Thread,Semaphore,Lock,RLock import time,random # 递归锁 rlock = RLock() noodles_lock = kuaizi_lock = rlock def eat1(name): noodles_lock.acquire() print('{}抢到面条了 ...'.format(name)) kuaizi_lock.acquire() print('{}抢到筷子了 ...'.format(name)) print('开始享受香菇青菜面') time.sleep(0.5) kuaizi_lock.release() print('{}吃完了,满意的放下了筷子'.format(name)) noodles_lock.release() print('{}吃完了,满意的放下了碗'.format(name)) def eat2(name): kuaizi_lock.acquire() print('{}抢到筷子了 ...'.format(name)) noodles_lock.acquire() print('{}抢到面条了 ...'.format(name)) print('开始享受香菇青菜面') time.sleep(0.5) noodles_lock.release() print('{}吃完了,满意的放下了碗'.format(name)) kuaizi_lock.release() print('{}吃完了,满意的放下了筷子'.format(name)) if __name__ == '__main__': lst1 = ['赵万里','赵沈阳'] lst2 = ['王通配','赵无极'] for name in lst1: Thread(target=eat1,args=(name,)).start() for name in lst2: Thread(target=eat2,args=(name,)).start() -
尽量使用一把锁(少用嵌套锁,避免 逻辑死锁)
from threading import Thread,Semaphore,Lock,RLock import time,random lock = Lock() def eat1(name,lock): lock.acquire() print('{}抢到面条了 ...'.format(name)) print('{}抢到筷子了 ...'.format(name)) print('开始享受香菇青菜面') time.sleep(0.5) print('{}吃完了,满意的放下了筷子'.format(name)) print('{}吃完了,满意的放下了碗'.format(name)) lock.release() def eat2(name,lock): lock.acquire() print('{}抢到筷子了 ...'.format(name)) print('{}抢到面条了 ...'.format(name)) print('开始享受香菇青菜面') time.sleep(0.5) print('{}吃完了,满意的放下了碗'.format(name)) print('{}吃完了,满意的放下了筷子'.format(name)) lock.release() if __name__ == '__main__': lst1 = ['赵万里','赵沈阳'] lst2 = ['王通配','赵无极'] for name in lst1: Thread(target=eat1,args=(name,lock)).start() for name in lst2: Thread(target=eat2,args=(name,lock)).start()
160)事件Event
'''
wait : 动态加阻塞 (True => 放行 False => 阻塞)
is_set : 获取内部成员属性值是True 还是 False
set : 把False => True
clear : 把True => False
'''
-
模拟连接远程数据库
'''最多连接三次,如果连接不上,直接报错''' from threading import Thread,Event import time,random ''' wait : 动态加阻塞 (True => 放行 False => 阻塞) is_set : 获取内部成员属性值是True 还是 False set : 把False => True clear : 把True => False ''' def check(e): print('账号检测中....') # 模拟延迟的场景 timer = random.uniform(1,8) print(timer) # 如果随机大于3秒 connect线程中的e.is_set 将无法变成true time.sleep(timer) e.set() def connect(e): sign = False for i in range(1,4): # 程序阻塞1秒后执行 e.wait(1) if e.is_set(): print('数据库连接成功') sign = True break else: print('尝试连接数据库第{}次失败了 ...'.format(i)) if sign == False: raise TimeoutError if __name__ == '__main__': e = Event() t1 = Thread(target=check,args=(e,)) t1.start() t2 = Thread(target=connect, args=(e,)) t2.start()
161)线程队列
'''
put 存放 超出队列长度阻塞
get 存取 超出队列长度阻塞
put_nowait 存放 超出队列长度报错
get_nowait 获取,超出队列长度报错
'''
-
Queue
from queue import Queue '''先进先出 后进后出''' q = Queue() q.put(100) q.put(200) print(q.get()) print(q.get()) # print(q.get()) 没有更多元素获取 会造成阻塞 # print(q.get_nowait()) 没有更多元素获取 会报错 # Queue(2) => 指定队列长度 元素个数只能是2个 q2 = Queue(2) q2.put(1000) q2.put(2000) # q2.put(200) 元素已满 造成阻塞 # q2.put_nowait(1000) 没有更多空间存放元素 会报错 -
LifoQueue
from queue import LifoQueue '''先进后出 后进先出(栈的特点)''' lq = LifoQueue() lq.put(100) lq.put(200) lq.put(300) print(lq.get()) # 300 print(lq.get()) # 200 print(lq.get()) # 100 -
PriorityQueue
-
对数字排序(默认从小到大)
from queue import PriorityQueue ''' 按照优先级顺序进行排序存放(默认从小到大) 在一个优先级队列中,要放同一类型的数据,不能混合使用 ''' pq = PriorityQueue() pq.put(12) pq.put(-52) pq.put(0) pq.put(88) print(pq.get()) # -52 print(pq.get()) # 0 print(pq.get()) # 12 print(pq.get()) # 88 -
对字母进行排序(按照ascii编码)
from queue import PriorityQueue ''' 按照优先级顺序进行排序存放(默认从小到大) 在一个优先级队列中,要放同一类型的数据,不能混合使用 ''' pq = PriorityQueue() pq.put('wawayu') pq.put('zhaoqin') pq.put('xiaoyang') pq.put('xwmumutangying') print(pq.get()) # wawayu print(pq.get()) # xiaoyang print(pq.get()) # xwmumutangying print(pq.get()) # zhaoqin -
对容器进行排列(先排第一位元素,再排第二位)
from queue import PriorityQueue ''' 按照优先级顺序进行排序存放(默认从小到大) 在一个优先级队列中,要放同一类型的数据,不能混合使用 ''' pq = PriorityQueue() pq.put( (28,'wawayu') ) pq.put( (-3,'zhaoqin') ) pq.put( (68,'tianlong') ) pq.put( (-3,'jiuwei') ) print(pq.get()) # (-3,'jiuwei') print(pq.get()) # (-3,'zhaoqin') print(pq.get()) # (28,'wawayu') print(pq.get()) # (68,'tianlong')
-
162)进程池 和 线程池
(1)进程池
'''多条进程提前开辟,可促发多cpu的并行效果'''
'''默认如果一个进程短时间内可以完成更多的任务,进程池就不会使用更多的进程来辅助完成'''
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
import os,time
# # 获取逻辑处理器(执行任务时,有多少个cpu在干事)
# print(os.cpu_count()) # 4
def func(i):
print('任务执行中 ... start ... 进程号 {}'.format(os.getpid()))
time.sleep(3)
print('任务执行中 ... end ... 进程号 {}'.format(os.getpid()))
return i
if __name__ == '__main__':
lst = []
# (1)创建进程池对象 默认参数时 系统最大的逻辑处理器
p = ProcessPoolExecutor()
# (2)异步提交任务 submit(任务,参数1,参数2 ...)
for i in range(10):
obj = p.submit(func,i)
lst.append(obj)
# (3)获取当前任务的返回值
for i in lst:
print(i.result(),'====获取返回值结果====')
# (4) shutdown 等待所有进程池里的进程执行完毕后,再放行
p.shutdown()
print("进程池结束 ...")
(2)线程池
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
from threading import currentThread as ct
import os,time
def func(i):
print('任何执行中 ... start ...线程号{},==={}'.format( ct().ident,i ))
print('任何执行中 ... end ...线程号{},==={}'.format( ct().ident,i ))
return ct().ident
if __name__ == '__main__':
lst = []
setvar = set()
'''(1)创建线程池对象 默认参数时 系统最大的逻辑核心数 4 * 5 = 20'''
t = ThreadPoolExecutor()
'''(2)异步提交任务'''
for i in range(100):
obj = t.submit(func,i)
lst.append(obj)
'''(3)获取当前任务的返回值'''
for i in lst:
# 放入集合自动去重
setvar.add(i.result())
'''(4) shutdown 等待所有线程池里的进程执行完毕后,再放行'''
t.shutdown()
print('所有线程全部执行完毕 ...')
print(setvar,len(setvar)) # 20
(3) 线程池 map
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
from threading import currentThread as ct
from collections import Iterator,Iterable
import os,time
def func(i):
print('任何执行中 ... start ...线程号{},==={}'.format( ct().ident,i ))
return '*' * i
if __name__ == '__main__':
t = ThreadPoolExecutor()
# 返回的是迭代器
it = t.map(func,range(100))
print(isinstance(it,Iterator) ) # True
# shutdown等待所有线程池里的进程执行完毕后, 再放行
t.shutdown()
# 获取迭代器中的返回值
for i in it:
print(i)
163)回调函数
(1)进程池(进程池的回调函数由主进程执行)
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
from threading import currentThread as ct
from collections import Iterator,Iterable
import os,time,random
def func1(i):
time.sleep(random.uniform(0.1,0.8))
print('进程任务执行中 ... start ...进程号{}'.format(os.getpid()),i)
print('进程任务执行中 ... end ...进程号{}'.format(os.getpid()))
return i
def call_back1(obj):
print('回调函数的进程号{}'.format(os.getpid())) # 回调函数的进程号13236
print(obj.result())
if __name__ == '__main__':
p = ProcessPoolExecutor()
for i in range(10):
obj = p.submit(func1,i)
# 进程池的回调函数由主进程执行
obj.add_done_callback(call_back1)
p.shutdown()
print('主进程结束 ...进程号{}'.format(os.getpid())) # 主进程结束 ...进程号13236
(2) 线程池(线程池的回调函数由子线程执行)
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
from threading import currentThread as ct
from collections import Iterator,Iterable
import os,time,random
def func1(i):
time.sleep(random.uniform(0.1,0.8))
print('线程任务执行中 ... start ...进程号{}'.format(ct().ident),i)
print('线程任务执行中 ... end ...进程号{}'.format(ct().ident))
return i
def call_back1(obj):
print('回调函数的线程号{}'.format(ct().ident)) # 回调函数的线程号3204
print(obj.result())
if __name__ == '__main__':
t = ThreadPoolExecutor()
for i in range(10):
obj = t.submit(func1,i)
# 线程池的回调函数由子线程执行
obj.add_done_callback(call_back1)
t.shutdown()
print('主线程结束 ...线程号{}'.format(ct().ident)) #主线程结束 ...线程号10896
164)协程
'''
进程是资源分配的最小单位
线程是程序调度的最小单位
协程是线程实现的具体方式
总结:
在进程一定的情况下,开辟多个线程
在线程一定的情况下,创建多个携程
以便提高更大的并行并发
'''
协程早期版本
from greenlet import greenlet
import time
'''switch 可以切换,但是需要手动'''
def eat():
print('eat1')
q2.switch()
time.sleep(1)
print('eat2')
def play():
print('play1')
time.sleep(1)
print('play2')
q1.switch()
q1 = greenlet(eat)
q2 = greenlet(play)
q1.switch()
协程终极版本
from gevent import monkey;monkey.patch_all()
'''引入猴子补丁,自动识别所有阻塞'''
import time
import gevent
def eat():
print('eat1')
time.sleep(1)
print('eat2')
return '吃完了'
def play():
print('play1')
time.sleep(1)
print('play2')
return '玩完了'
q1 = gevent.spawn(eat)
q2 = gevent.spawn(play)
gevent.joinall([q1,q2])
print('主线程运行结束')
print(q1.value) # '吃完了'
print(q2.value) # '玩完了'
165)Linux解决 导入第三方包失败问题
# 下载conda
1.wget https://mirrors.bfsu.edu.cn/anaconda/archive/Anaconda3-2022.10-Linux-x86_64.sh --no-check-certificate
# 安装conda
2.chmod 777 Miniconda3-latest-Linux-x86_64.sh #刚下载好的安装包没有可执行权限,所以需要先给权限
bash Miniconda3-latest-Linux-x86_64.sh #运行.sh
3.conda config --set auto_activate_base false #取消conda自动激活 然后重新打开终端
4.点击file\setting Project Interpreter

镜像地址:https://pypi.tuna.tsinghua.edu.cn/simple/

166)Linux安装mysql
第一步把mysql.deb文件放在home下的mysoft中,执行sudo dpkg -i mysql-aptconfig_0.8.12-1_all.deb



5. cd /etc cd apt sudo cp sources.list sources.listbak备份
6.sudo nano sources.list
-
ctrl+k 全部删除 然后复制以下内容 ctrl+x Y 回车
deb https://mirrors.aliyun.com/ubuntu/ xenial main deb-src https://mirrors.aliyun.com/ubuntu/ xenial main deb https://mirrors.aliyun.com/ubuntu/ xenial-updates main deb-src https://mirrors.aliyun.com/ubuntu/ xenial-updates main deb https://mirrors.aliyun.com/ubuntu/ xenial universe deb-src https://mirrors.aliyun.com/ubuntu/ xenial universe deb https://mirrors.aliyun.com/ubuntu/ xenial-updates universe deb-src https://mirrors.aliyun.com/ubuntu/ xenial-updates universe deb https://mirrors.aliyun.com/ubuntu/ xenial-security main deb-src https://mirrors.aliyun.com/ubuntu/ xenial-security main deb https://mirrors.aliyun.com/ubuntu/ xenial-security universe deb-src https://mirrors.aliyun.com/ubuntu/ xenial-security universe8.执行sudo apt-get update 会自己去找sources.list的镜像连接
-
执行sudo apt-get install mysql-server
-
输入密码123456 确认123456
-
执行 mysql -uroot -p 密码123456
-
show databases;
-
执行 grant all privileges on . to 'root'@'%' identified by '123456' with grant option;
-
执行flush privileges; 立即生效
-
执行exit
-
cd /etc/mysql/mysql.conf.d
-
sudo nano mysqld.cnf 修改bind-address = 0.0.0.0 ctrl+x y 回车
-
sudo /etc/init.d/mysql restart 重启mysql
-
输入 if config inet 地址:192.168.140.128 把地址拷贝到windows 的 navcat
![]()
-

167)windows安装mysql
1.在C盘创建MySQL5.7文件夹 把mysql.zip解压到当前文件夹
2.进入解压文件夹,创建配置文件my.ini
3.打开my.ini进行一下配置
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[mysqld]
# 设置3306端口
port = 3306
# 设置mysql的安装目录
basedir=C:\MySQL5.7\mysql-5.7.25-winx64
# 设置mysql数据库的数据的存放目录
datadir=C:\MySQL5.7\mysql-5.7.25-winx64\data
# 允许最大连接数
max_connections=200
# 服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB

5.cd\切换到C盘根目录 执行cd MySQL5.7
6.cd mysql-5.7.25-winx64
7.cd bin
8.执行,mysqld --initialize-insecure --user=mysql
9.执行 mysqld install
10.执行 net start mysql
11.修改环境变量 C:\MySQL5.7\mysql-5.7.25-winx64\bin
12.mysql -uroot -p 然后直接点击回车 不输入密码 出现mysq> 成功
13.show databases;
14.use mysql
15.show tables;
16.select * from user;
168)navcat安装
1.C盘创建文件夹nav 将文件复制进来
2.点击exe文件安装到nav文件夹 无脑下一步即可
3.把破解补丁中的简体中文64位里的(payload.bin 和 version.dll)文件复制到 navcat.exe安装根目录中
4.打开软件 新建连接 windows_mysql 不需要密码 点击连接测试
169)putty 连接 ubantu
-
执行 sudo apt-get install openssh-server
-
执行 ps -e | grep ssh
-
windows中安装 putty 在C盘创建文件夹putty 安装到这里 无脑下一步即可
-
在开始菜单找到putty 输入linux的ip


输入linux中的账号密码即可
170)windows 设置镜像源
1. pip install --upgrade pip
2. pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
171)利用协程爬取数据
'''
HTTP 状态码
200 OK
400 bad request
404 not found
'''
from gevent import monkey;monkey.patch_all()
'''引入猴子补丁,自动识别所有阻塞'''
import time
import gevent
import requests
response = requests.get('http://www.baidu.com')
# 获取状态码
print(response.status_code)
# 获取网页中的字符集编码
res = response.apparent_encoding
print(res) # utf-8
# 设置编码集,防止乱码
response.encoding = res
# 获取网页内容
res = response.text
print(res)
爬虫小案例
from gevent import monkey;
monkey.patch_all()
'''引入猴子补丁,自动识别所有阻塞'''
import time
import gevent
import requests
# response = requests.get('http://www.baidu.com')
# # 获取状态码
# print(response.status_code)
# # 获取网页中的字符集编码
# res = response.apparent_encoding
# print(res) # utf-8
# # 设置编码集,防止乱码
# response.encoding = res
# # 获取网页内容
# res = response.text
# print(res)
# 正常爬取
def get_url(url):
response = requests.get(url)
if response.status_code == 200:
pass
lis = [
'http://www.baidu.com',
'http://www.taobao.com',
'http://www.jd.com',
'http://www.4399.com',
'http://www.baidu.com',
'http://www.taobao.com',
'http://www.jd.com',
'http://www.4399.com'
]
'''
starttime = time.time()
for i in lis:
get_url(i)
endtime = time.time()
print(endtime - starttime) # 49.1947705745697
'''
# 协程爬取
li = []
starttime = time.time()
for i in lis:
g = gevent.spawn(get_url,i)
li.append(g)
gevent.joinall(li)
endtime = time.time()
print(endtime - starttime) # 4.8224873542785645
172)mysql关系型数据库
- linux命令
'''Linux中的命令'''
mysql -uroot -p # 登录指令
service mysql top # 关闭指令
service mysql start # 启动命令
service mysql restart # 重启命令
快捷键: ctrl + l 清屏
快捷键: ctrl + c 终止
快捷键: exit 退出数据库
2)windows命令
'''windows命令'''
# 查询当前登录用户
select user()
# 设置密码
set password = password('123456')
# 去除密码
set password = password('')
# 连接远程数据库
mysql -uceshi102 -p -h192.168.52.128
3)linux创建用户
### part3
vmnet8 : nat
vmnet1 : host-only
ipconfig [windows] ifconfig[Linux]
# 给具体某个ip设置一个账户连接linux
# 解读: 从192.168.52.1网关下 创建一个用户ceshi100 连接密码为123456
create user 'ceshi100'@'192.168.52.1' identified by '123456'
# 解读: 给具体192.168.52 这个网段下得所有ip设置账户
create user 'ceshi101'@'192.168.52.%' identified by '123456'
# 给所有ip下得主机设置账户
create user 'ceshi102'@'%' identified by '123456'
4)linux授予权限
USAGE 没有任何权限
# 查看具体某个ip下得用户权限
show grants for 'ceshi102'@'%';
+-----------------------------------------------+
| Grants for ceshi102@% |
+-----------------------------------------------+
| GRANT ALL PRIVILEGES ON *.* TO 'ceshi102'@'%' |
+-----------------------------------------------+
# 授权语法
grant 权限 on 数据库.表 to '用户名'%'ip地址' identified by '密码'
'''
select 查询数据得权限
insert 添加数据得权限
update 更改数据得权限
delete 删除数据得权限
* 所有
'''
# 授予查询和添加权限
grant select,insert on *.* to 'ceshi102'@'%' identified by '123456';
# 授予所有权限
grant all on *.* to 'ceshi102'@'%' identified by '123456';
# 移除删除权限
revoke drop on *.* from 'ceshi102'@'%'
# 移除所有权限
revoke all on *.* from 'ceshi102'@'%'
# 刷新权限 立刻生效
flush privileges
5)操作数据库(文件夹)
'''
'''mysql命令中 不区分大小写'''
[linux]路径
sudo find / -name db001
sudo su root 切换到最高权限账户 cd mysql
/var/lib/mysql/数据库...
[windows]路径
C:\MySQL5.7\mysql-5.7.25-winx64\data
'''
增:
# 创建数据库(文件夹)
create database db001 charset utf8;
查:
# 查看数据库
show databases;
# 查看建库语句
show create database db001;
+----------+----------------------------------------------------------------+
| Database | Create Database |
+----------+----------------------------------------------------------------+
| db001 | CREATE DATABASE `db001` /*!40100 DEFAULT CHARACTER SET utf8 */ |
+----------+----------------------------------------------------------------+
改:
alter database db001 charset gbk # 修改编码集 使用 show create database db001 查看修改得编码集
删:
# 删除数据库
drop database db001
6)操作数据表(文件)
增:
# 选择数据库
use db001
# 创建表
create table t1(id int,name char) # char 在mysql中表示字符串
# 使用建表语句新增
CREATE TABLE `t2` (
`id` int(11) DEFAULT NULL,
`name` char(1) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
查:
# 查看所有表
show tables
+-----------------+
| Tables_in_db001 |
+-----------------+
| t1 |
+-----------------+
# 查看建表语句
show create table t1
# 查看表结构
desc t1
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | char(1) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
改:
# 只能改类型
alter table t1 modify name char(5) # 修改表名为t1 字段为name 类型修改为5个字符长度得字符串
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | char(5) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
# change 改变类型 + 字段名
# 修改表名为t1 字段为name 类型修改为4个字符长度得字符串,字段名为name123
alter table t1 change name name123 char(4)
+---------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+---------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name123 | char(4) | YES | | NULL | |
+---------+---------+------+-----+---------+-------+
# 添加字段
alter table t1 add age int
+---------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+---------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name123 | char(4) | YES | | NULL | |
| age | int(11) | YES | | NULL | |
+---------+---------+------+-----+---------+-------+
# 删除字段
alter table t1 drop age
+---------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+---------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name123 | char(4) | YES | | NULL | |
+---------+---------+------+-----+---------+-------+
# 修改表名
alter table t1 rename t11111
+-----------------+
| Tables_in_db001 |
+-----------------+
| t11111 |
| t2 |
+-----------------+
删:
# 删除表
drop table t1
7)操作记录(文件内容)
增:
# 一次插入一条数据
insert into t2(id,name) values(1,'娃娃鱼')
#一次插入多条数据
insert into t2(id,name) values(1,'娃娃鱼'),(2,'赵芹'),(3,'小杨')
# 不指定具体字段,默认把字段全部插一遍
insert into t2 values(8,'wan')
| 8 | wan |
# 可以指定具体某个字段进行插入
insert into t2(name) values('张彪')
| NULL | 张彪 |
+------+-----------+
查:
# * 所有
select * from t2
+------+-----------+
| id | name |
+------+-----------+
| 1 | 娃娃鱼 |
| 1 | 娃娃鱼 |
| 2 | 赵芹 |
| 3 | 小杨 |
+------+-----------+
# 查询单个字段
select id from t2
+------+
| id |
+------+
| 1 |
| NULL |
+------+
# 查询多个字段
select id,name from t2
+------+-----------+
| id | name |
+------+-----------+
| 1 | 娃娃鱼 |
| 1 | 娃娃鱼 |
| 2 | 赵芹 |
| 3 | 小杨 |
| 8 | wan |
| NULL | 张彪 |
+------+-----------+
改:
# update 表名 set 字段=值 where 条件
update t2 set name='pyth' where id = 1
# 不加条件有风险,一改全改,一定加where
update t2 set name='网卡'
删:
# 删除得时候,必须加上where
delete from t2 where id = 1
# 删除所有数据
delete from t2
# 删除所有 (数据+重置id)
truncate table t2
8)常用数据类型
-
整型
tinyint 1个字节 有符号范围(-128~127) 无符号(0~255) 小整型值 int 4个字节 有符号范围(-21亿~21亿左右) 无符号(0~42亿) 大整型值 create table t3(id int,sex tinyint) insert into t3(id,sex) values(4000000000,127); # id超出范围,Out of range insert into t3(id,sex) values(1000000000,128); # sex超出范围,Out of range insert into t3(id,sex) values(13,127); -
浮点型(255,30)整数位最多保留225位 小数位最多保留30位
float(255,30) 单精度 double(255,30) 双精度 decimal(65,30) 金钱类型(用字符串得形式存储小数) # 整数位最多保留2位 小数位最多保留3位 create table t4(fl float(5,3),f2 double(5,3),f3 decimal(5,3)) insert into t4 values(1.7777777777,1.7777777777,1.7777777777) # 1.778 insert into t4 values(11.7777777777,11.7777777777,11.7777777777)# 11.778 insert into t4 values(111.7777777777,111.7777777777,111.7777777777)# Out of range insert into t4 values(111.7,111.7,111.7) # Out of range # float 小数位默认保留5位, double 小数位默认保留16位,decimal 默认保留整数,四舍五入 create table t6(fl float,f2 double,f3 decimal) insert into t6 values(1.7777777777777777777777777,1.7777777777777777777777777,1.7777777777777777777777777) +---------+--------------------+------+ | fl | f2 | f3 | +---------+--------------------+------+ | 1.77778 | 1.7777777777777777 | 2 | +---------+--------------------+------+ -
字符串 char(字符长度) varchar(字符长度)
char(11) 定长:固定开辟11个字符长度的空间(手机号,身份证号),开辟空间的速度上来说比较快,从数据结构上来说,需谨慎,可能存在空间浪费. max = 255 varchar(11) 变长:动态最多开辟11个字符长度的空间(评论,广告),开辟空间的速度上来说相对慢,从数据结构上来说,推荐使用,不存在空间浪费 max > 255 text 文本类型:针对于文章,论文,小说. max > varchar create table t7(c char(11), v varchar(11) , t text); insert into t7 values("11111","11111","11111"); insert into t7 values("你好啊你好啊你好啊你好","你好啊你好啊你好啊你好","你好啊你好啊你好啊你好"); # concat 可以把各个字段拼接在一起 select concat(c,"<=>",v,"<=>",t) from t7; -
char varchar (补充)
char 字符长度 255个 varchar 字符长度 21845个
-
时间类型
date YYYY-MM-DD 年月日 (节假日,纪念日) time HH:MM:SS 时分秒 (体育竞赛,记录时间) year YYYY 年份 (历史,酒的年份) datetime YYYY-MM-DD HH:MM:SS 年月日 时分秒 (上线时间,下单时间) create table t1(d date,t time,y year,dt datetime); insert into t1 values('2020-11-3','9:19:30','2020','2020-11-3 9:19:30') +------------+----------+------+---------------------+ | d | t | y | dt | +------------+----------+------+---------------------+ | 2020-11-03 | 09:19:30 | 2020 | 2020-11-03 09:19:30 | +------------+----------+------+---------------------+ # 会自动截取成对应的数据类型 insert into t1 values(now(),now(),now(),now()) +------------+----------+------+---------------------+ | d | t | y | dt | +------------+----------+------+---------------------+ | 2020-11-03 | 09:19:30 | 2020 | 2020-11-03 09:19:30 | | 2023-04-11 | 17:28:50 | 2023 | 2023-04-11 17:28:50 | +------------+----------+------+---------------------+ timestamp YYYYMMDDHHMMSS(时间戳) 自动更新时间(不需要手动写入,自动实现更新记录[用作记录修改时间]) create table t2(dt datetime,ts timestamp) insert into t2 values(20201103092530,20201103092530) +---------------------+---------------------+ | dt | ts | +---------------------+---------------------+ | 2020-11-03 09:25:30 | 2020-11-03 09:25:30 | +---------------------+---------------------+ # timestamp会自动更新时间(以当前时间戳) datetime不会自动更新 insert into t2 values(nill,null) +---------------------+---------------------+ | dt | ts | +---------------------+---------------------+ | 2020-11-03 09:25:30 | 2020-11-03 09:25:30 | | NULL | 2023-04-11 17:40:16 | +---------------------+---------------------+
9)数据库内部方法
select user()
+----------------+
| user() |
+----------------+
| root@localhost |
+----------------+
# 可以把各个字段拼接在一起
select concat()
# 查询使用的库
select database()
+------------+
| database() |
+------------+
| db001 |
+------------+
# 查询当前时间
select now()
+---------------------+
| now() |
+---------------------+
| 2023-04-11 14:24:27 |
+---------------------+
10)枚举和集合
enum 枚举 : 从列出来的数据当中选一个 (性别)
set 集合 : 从列出来的数据当中选多个 (爱好)
create table t8(
id int ,
name varchar(10) ,
sex enum("男性","兽性","人妖") ,
money float(5,3) ,
hobby set("吃肉","抽烟","喝酒","打麻将","嫖赌")
);
# 正常写法
insert into t8(id,name,sex , money , hobby) values(1,"张保障","兽性",2.6,"打麻将,吃肉,嫖赌");
# 自动去重
insert into t8(id,name,sex , money , hobby) values(1,"张保障","兽性",2.6,"打麻将,吃肉,嫖赌,嫖赌,嫖赌,嫖赌,嫖赌,嫖赌");
# 异常写法 : 不能选择除了列出来的数据之外的其他值 error 报错
insert into t8(id,name,sex , money , hobby) values(1,"张保障","人妖12",2.6,"打麻将,吃肉,嫖赌12");
173)约束
'''对编辑的数据进行类型的限制,不满足约束条件的报错'''
unsigned : 无符号
not null : 不位空
default : 默认值
unique : 唯一值 加入索引(为了提高搜索速度)
primary key : 主键
auto_increment : 自增加一
zerofill : 零填充
foreign key : 外键
- unsigned : 无符号
create table t3(id int unsigned)
insert into t3 values(-1) # ERROR
insert into t3 values(1000000000) # success
+------------+
| id |
+------------+
| 1000000000 |
+------------+
- not null : 不位空
create table t4(id int not null,name varchar(11));
insert into t4 values(1,"张宇");
+----+--------+
| id | name |
+----+--------+
| 1 | 张宇 |
+----+--------+
insert into t4 values(null,'张宇') # error
insert into t4(name) values('李四')# error
- default : 默认值
create table t5(id int not null,name varchar(11) default '张无忌')
insert into t5 value(1,null);
+----+------+
| id | name |
+----+------+
| 1 | NULL |
+----+------+
insert into t5(id) values(2)
+----+-----------+
| id | name |
+----+-----------+
| 1 | NULL |
| 2 | 张无忌 |
+----+-----------+
create table t5——2(id int not null default '1111',name varchar(11) default '张无忌')
insert into t5_2 values()
+------+-----------+
| id | name |
+------+-----------+
| 1111 | 张无忌 |
+------+-----------+
- unique : 唯一值 加入索引(为了提高搜索速度)
'''唯一 可以Null 标记成:uni'''
create table t6(id int unique,name char(10) default "赵万里")
insert into t6(id) values(1)
+----+-----------+
| id | name |
+----+-----------+
| 1 | 赵万里 |
+----+-----------+
insert into t6(id) values(1)# ERROR
insert into t6(id) valuse(null)
insert into t6(id) valuse(null)# id 变成了多个Null
- primary key : 主键 (唯一 且 不为Null)
unique not null 和 primary key 同时存在 以primary key 为主键
create table t7(id int primary key,name varchar(10) default "赵珅样")
inserr into t7(id) values(1)
inserr into t7(id) values(1) # error
inserr into t7(id) values(null) # error
- auto_increment 自增加以(一般配合 主键或者Unique使用)
create table t8(id int primary key auto_increment,name varchar(255) default "asd")
insert into t8 values(1,'张三')
insert into t8 values(null,'李四')
+----+--------+
| id | name |
+----+--------+
| 1 | 张三 |
| 2 | 李四 |
+----+--------+
# 删除数据 插入数据时id会延续之前删除的id 不会消失掉
delete from t8
# 删除数据 + 重置id
truncate table t8
- zerofill : 零填充(配合Int使用,不够5位拿0来填充)
create table t9(id int(5) zerofill)
insert into t9 values(1234567)
insert into t9 values(12)
+---------+
| id |
+---------+
| 1234567 |
| 00012 |
+---------+
- 联合唯一索引
'''unique(字段1,字段2,字段3 ...) 合在一起 该数据不能重读'''
# unique + not null
create table t1_server(id int,server_name varchar(10) not null,ip varchar(15) not null,port int not null,unique(ip,port))
insert into t1_server values(1,'阿里','192.168.11.251',3306)
+------+-------------+----------------+------+
| id | server_name | ip | port |
+------+-------------+----------------+------+
| 1 | 阿里 | 192.168.11.251 | 3306 |
+------+-------------+----------------+------+
insert into t1_server values(1,'阿里','192.168.11.251',3306)# 报错
create table t2_server(id int,server_name varchar(10) not null,ip varchar(15),port int ,unique(ip,port))
insert into t2_server values(1,'华为','192.168.11.251',3306)
+------+-------------+----------------+------+
| id | server_name | ip | port |
+------+-------------+----------------+------+
| 1 | 华为 | 192.168.11.251 | 3306 |
+------+-------------+----------------+------+
insert into t2_server values(1,'华为','192.168.11.251',3306)# 报错
insert into t2_server values(1,'华为',null,null)
insert into t2_server values(1,'华为',null,null)
insert into t2_server values(1,'华为',null,null) # 注意点 允许插入多个空值
+------+-------------+----------------+------+
| id | server_name | ip | port |
+------+-------------+----------------+------+
| 1 | 华为 | 192.168.11.251 | 3306 |
| 1 | 华为 | NULL | NULL |
| 1 | 华为 | NULL | NULL |
| 1 | 华为 | NULL | NULL |
+------+-------------+----------------+------+
- 联合唯一主键
create table t3_server(id int,serber_name varchar(10) not null,ip varchar(15),port int,primary key(ip,port))
insert into t3_server values(1,'华为','192.168.11.251',3306)
+------+-------------+----------------+------+
| id | serber_name | ip | port |
+------+-------------+----------------+------+
| 1 | 华为 | 192.168.11.251 | 3306 |
+------+-------------+----------------+------+
insert into t3_server values(1,'华为','192.168.11.251',3307)
+------+-------------+----------------+------+
| id | serber_name | ip | port |
+------+-------------+----------------+------+
| 1 | 华为 | 192.168.11.251 | 3306 |
| 1 | 华为 | 192.168.11.251 | 3307 |
+------+-------------+----------------+------+
- foreign key: 外键,把多张表通过一个关键字段联合在一起(该字段可以设置成外键,作用是可以联级更新或者联级删除)
student1:
id name age classid
1 wangtoyi 55 1
2 liuyifeng 85 1
3 wangwen 18 2
class1:
id classname
1 python32
2 python33
# 创建表 class1(被关联字段 必须添加唯一索引)
create table class1(id int primary key auto_increment,classname varchar(255))
+-----------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------+--------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| classname | varchar(255) | YES | | NULL | |
+-----------+--------------+------+-----+---------+----------------+
# 创建表 student1
create table student1(
id int primary key auto_increment,
name varchar(255),
age int,
classid int,
foreign key(classid) references class1(id)
);
+---------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(255) | YES | | NULL | |
| age | int(11) | YES | | NULL | |
| classid | int(11) | YES | MUL | NULL | |# classid = mul 表示关联外键
+---------+--------------+------+-----+---------+----------------+
# 添加数据
insert into class1 values(1,'python32');
insert into class1 values(2,'python33');
insert into class1 values(3,'python34');
+----+-----------+
| id | classname |
+----+-----------+
| 1 | python32 |
| 2 | python33 |
| 3 | python34 |
+----+-----------+
insert into student1 values(null,'wangtoyi',58,1);
insert into student1 values(null,'liuyifeng',85,1);
insert into student1 values(null,'wangwen',18,2);
+----+-----------+------+---------+
| id | name | age | classid |
+----+-----------+------+---------+
| 1 | wangtoyi | 58 | 1 |
| 2 | liuyifeng | 85 | 1 |
| 3 | wangwen | 18 | 2 |
+----+-----------+------+---------+
# 没有被关联的数据可以直接删除
delete from class1 where id = 3;
# 有关联的数据不能直接删除,要先把关联的数据删除之后再删除
delete from student1 where id = 1;
delete from student1 where id = 2;
delete from class1 where id = 1;
- 联级删除 和 联级更新
# 创建表 class2(被关联字段 必须添加唯一索引)
create table class2(id int primary key auto_increment,classname varchar(255))
+-----------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------+--------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| classname | varchar(255) | YES | | NULL | |
+-----------+--------------+------+-----+---------+----------------+
# 创建表 student2
create table student2(
id int primary key auto_increment,
name varchar(255),
age int,
classid int,
foreign key(classid) references class2(id) on delete cascade on update cascade
);
+---------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(255) | YES | | NULL | |
| age | int(11) | YES | | NULL | |
| classid | int(11) | YES | MUL | NULL | |
+---------+--------------+------+-----+---------+----------------+
# 添加数据
insert into class2 values(1,'python32');
insert into class2 values(2,'python33');
insert into class2 values(3,'python34');
+----+-----------+
| id | classname |
+----+-----------+
| 1 | python32 |
| 2 | python33 |
| 3 | python34 |
+----+-----------+
insert into student2 values(null,'wangtoyi',58,1);
insert into student2 values(null,'liuyifeng',85,1);
insert into student2 values(null,'wangwen',18,2);
+----+-----------+------+---------+
| id | name | age | classid |
+----+-----------+------+---------+
| 1 | wangtoyi | 58 | 1 |
| 2 | liuyifeng | 85 | 1 |
| 3 | wangwen | 18 | 2 |
+----+-----------+------+---------+
# 联级删除
delete from class2 where id = 3; 两张表同时删除class2中被关联的id
class2:
+----+-----------+
| id | classname |
+----+-----------+
| 1 | python32 |
| 2 | python33 |
+----+-----------+
student2:
+----+-----------+------+---------+
| id | name | age | classid |
+----+-----------+------+---------+
| 1 | wangtoyi | 58 | 1 |
| 2 | liuyifeng | 85 | 1 |
| 3 | wangwen | 18 | 2 |
+----+-----------+------+---------+
# 联级更新
update class2 set id = 100 where classname='python33';
mysql> select * from student2;
+----+-----------+------+---------+
| id | name | age | classid |
+----+-----------+------+---------+
| 1 | wangtoyi | 58 | 1 |
| 2 | liuyifeng | 85 | 1 |
| 3 | wangwen | 18 | 100 |
+----+-----------+------+---------+
mysql> select * from class2;
+-----+-----------+
| id | classname |
+-----+-----------+
| 1 | python32 |
| 100 | python33 |
+-----+-----------+
174)表与表之间的关系
(1) 一对一: id name age sex address guanlian id userid mother father ...
(2) 一对多(多对一): 班级和学生之间的关系 一个班级可以对应多个学生 反过来 多个学生对应一个班级
(3) 多对多: 一个学生可以同时学习多个学科,一个学科同时可以被多个学生学习
一本书可以被多个作者共同编写,一个作者可以写多本书
175)存储引擎 : 存储数据的一种结构方式
表级锁 : 只要有一个线程执行修改表中的相关操作,就会上锁,其他线程默认等待
行级锁 : 针对于当前表中的这条记录,这一行进行上锁,其他数据仍然可以以被其他线程修改,实现高并发,高可用
事物处理 : 执行sql语句时,必须所有的操作全部成功,才最终提交数据,有一条失败,直接回滚,恢复到先前状态
begin : 开启事务
commit : 提交数据
rollback : 回滚数据
MyISAM : 表级锁 (5.5版本之前的默认存储引擎)
InnoDB : 事物处理,行级锁,外键 (5.5版本之后的默认存储引擎)
MEMORY : 把数据放在内存中 临时缓存
BLACKHOLE : 不存储数据 写入的任何数据都不会成功
一般用于同步主从数据库(放在主数据库和从数据库之间的一台服务器)
'''
主数据库 : 增删改
从数据库 : 查询
配置: 一主一从 一主多从 多主多重
'''
create table myisaml(id int) engine=MyISAM;
.frm 表结构
.MYD 表数据
.MYI 表索引
mysql> show create table myisaml;
+---------+-------------------------------------------------------------------------------------------+
| Table | Create Table |
+---------+-------------------------------------------------------------------------------------------+
| myisaml | CREATE TABLE `myisaml` (
`id` int(11) DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8 |
+---------+-------------------------------------------------------------------------------------------+
create table innodb(id int) engine=InnoDB;
.frm 表结构
.ibd 表数据+表结构
mysql> show create table innodb;
+--------+------------------------------------------------------------------------------------------+
| Table | Create Table |
+--------+------------------------------------------------------------------------------------------+
| innodb | CREATE TABLE `innodb` (
`id` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+--------+------------------------------------------------------------------------------------------+
create table memory(id int) engine=MEMORY;cre
.frm 只有表结构 数据存放在内存中
create table blackhole(id int) engine=BLACKHOLE;
.frm 只有表结构
'''
子查询: 嵌套查询
(1) sql语句当中又嵌套了另外一条sql,用括号()进行包裹,表达一个整体
(2) 一般用于from子句,where子句... 身后,表达一个条件或者一个表
(3) 速度快慢: 单表查询 > 联表查询 > 子查询
'''
department;
+------+--------------+
| id | name |
+------+--------------+
| 200 | 技术 |
| 201 | 人力资源 |
| 202 | 销售 |
| 203 | 运营 |
+------+--------------+
employee;
+----+------------+--------+------+--------+
| id | name | sex | age | dep_id |
+----+------------+--------+------+--------+
| 1 | egon | male | 18 | 200 |
| 2 | alex | female | 48 | 201 |
| 3 | wupeiqi | male | 38 | 201 |
| 4 | yuanhao | female | 28 | 202 |
| 5 | liwenzhou | male | 18 | 200 |
| 6 | jingliyang | female | 18 | 204 |
+----+------------+--------+------+--------+
一. 找出平均年龄大于25岁以上的部门
1. 先找出平均年龄大于25岁的部门id
select dep_id from employee group by employee.dep_id having avg(age)>25;
+--------+
| dep_id |
+--------+
| 201 |
| 202 |
+--------+
2. 通过部门的Id找部门的名字
select name,id from department where id in(201,202); # 此处是手动填写的201,202
+--------------+------+
| name | id |
+--------------+------+
| 人力资源 | 201 |
| 销售 | 202 |
+--------------+------+
3. 综合拼接
select name,id from department where id in(select dep_id from employee group by employee.dep_id having avg(age)>25);
+--------------+------+
| name | id |
+--------------+------+
| 人力资源 | 201 |
| 销售 | 202 |
+--------------+------+
二.查看技术部门员工姓名
(1) 普通的where 查询
select
e.id,e.name
from
employee as e,department as d
where
e.dep_id = d.id
and
d.name = "技术"
(2) inner join
select
e.id,e.name
from
employee as e inner join department as d on e.dep_id = d.id
where
d.name = "技术"
(3)子查询
(1) 找技术部门对应的id
select id from department where name = "技术";
# (2) 通过id找员工姓名
select name from employee where dep_id = 200;
# (3) 综合拼接
select id,name from employee where dep_id = (select id from department where name = "技术");
三.查看哪个部门没员工
联表写法
select
d.id,d.name
from
department as d left join employee as e on d.id = e.dep_id
where
e.dep_id is null
1.找员工在哪些部门 (200 201 202 204)
select dep_id from employee group by dep_id
# 2.把不在该部门的员工找出来
select id from department where id not in (200,201,202,204);
# 3.综合拼接
select id,name from department where id not in (select dep_id from employee group by dep_id);
department;
+------+--------------+
| id | name |
+------+--------------+
| 200 | 技术 |
| 201 | 人力资源 |
| 202 | 销售 |
| 203 | 运营 |
+------+--------------+
employee;
+----+------------+--------+------+--------+
| id | name | sex | age | dep_id |avg(age)
+----+------------+--------+------+--------+
| 1 | egon | male | 18 | 200 | 18
| 2 | alex | female | 48 | 201 | 43
| 3 | wupeiqi | male | 38 | 201 | 43
| 4 | yuanhao | female | 28 | 202 | 28
| 5 | liwenzhou | male | 18 | 200 | 18
| 6 | jingliyang | female | 18 | 204 | 18
+----+------------+--------+------+--------+
# 四.查询大于平均年龄的员工名与年龄
# 假设已经知道了平均年龄;
select name,age from employee where age > 30;
# 计算平均年龄
select avg(age) from employee;
# 综合拼接
select name,age from employee where age > (select avg(age) from employee);
五.把大于其本部门平均年龄的员工名和姓名查出来
1.先计算本部门的平均年龄是多少
select dep_id , avg(age) from employee group by dep_id;
+--------+----------+
| dep_id | avg(age) |
+--------+----------+
| 200 | 18.0000 |
| 201 | 43.0000 |
| 202 | 28.0000 |
| 204 | 18.0000 |
+--------+----------+
2.把查询的各部门平均年龄和employee进行联表,变成一张大表,最后做单表查询
select
*
from
employee as t1 inner join (1号查询出来的数据) as t2 on t1.dep_id = t2.dep_id
3.综合拼装
select
*
from
employee as t1 inner join (select dep_id , avg(age) as avg_age from employee group by dep_id) as t2 on t1.dep_id = t2.dep_id
4.最后做一次单表查询,让age > 平均值
select
*
from
employee as t1 inner join (select dep_id , avg(age) as avg_age from employee group by dep_id) as t2 on t1.dep_id = t2.dep_id
where
age >avg_age
六.查询每个部门最新入职的那位员工 # 利用上一套数据表进行查询;
employee
+----+------------+--------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+
| id | emp_name | sex | age | hire_date | post | post_comment | salary | office | depart_id | max_date
+----+------------+--------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+
| 1 | egon | male | 18 | 2017-03-01 | 老男孩驻沙河办事处外交大使 | | 7300.33 | 401 | 1 | 2017-03-01
| 2 | alex | male | 78 | 2015-03-02 | teacher | NULL | 1000000.31 | 401 | 1 | 2015-03-02
| 3 | wupeiqi | male | 81 | 2013-03-05 | teacher | NULL | 8300.00 | 401 | 1 | 2015-03-02
| 4 | yuanhao | male | 73 | 2014-07-01 | teacher | NULL | 3500.00 | 401 | 1 | 2015-03-02
| 5 | liwenzhou | male | 28 | 2012-11-01 | teacher | NULL | 2100.00 | 401 | 1 | 2015-03-02
| 6 | jingliyang | female | 18 | 2011-02-11 | teacher | NULL | 9000.00 | 401 | 1 | 2015-03-02
| 7 | jinxin | male | 18 | 1900-03-01 | teacher | NULL | 30000.00 | 401 | 1 | 2015-03-02
| 8 | 成龙 | male | 48 | 2010-11-11 | teacher | NULL | 10000.00 | 401 | 1 | 2015-03-02
| 9 | 歪歪 | female | 48 | 2015-03-11 | sale | NULL | 3000.13 | 402 | 2 | 2017-01-27
| 10 | 丫丫 | female | 38 | 2010-11-01 | sale | NULL | 2000.35 | 402 | 2 | 2017-01-27
| 11 | 丁丁 | female | 18 | 2011-03-12 | sale | NULL | 1000.37 | 402 | 2 | 2017-01-27
| 12 | 星星 | female | 18 | 2016-05-13 | sale | NULL | 3000.29 | 402 | 2 | 2017-01-27
| 13 | 格格 | female | 28 | 2017-01-27 | sale | NULL | 4000.33 | 402 | 2 | 2017-01-27
| 14 | 张野 | male | 28 | 2016-03-11 | operation | NULL | 10000.13 | 403 | 3 | 2016-03-11
| 15 | 程咬金 | male | 18 | 1997-03-12 | operation | NULL | 20000.00 | 403 | 3 | 2016-03-11
| 16 | 程咬银 | female | 18 | 2013-03-11 | operation | NULL | 19000.00 | 403 | 3 | 2016-03-11
| 17 | 程咬铜 | male | 18 | 2015-04-11 | operation | NULL | 18000.00 | 403 | 3 | 2016-03-11
| 18 | 程咬铁 | female | 18 | 2014-05-12 | operation | NULL | 17000.00 | 403 | 3 | 2016-03-11
+----+------------+--------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+
1.找各部门的最新入职的时间
select post,max(hire_date) as max_date from employee group by post
+-----------------------------------------+------------+
| post | max_date |
+-----------------------------------------+------------+
| operation | 2016-03-11 |
| sale | 2017-01-27 |
| teacher | 2015-03-02 |
| 老男孩驻沙河办事处外交大使 | 2017-03-01 |
+-----------------------------------------+------------+
2.把子查询搜索出来的结果作为一张表和employee这个表做联表,把max_date拼接在employee这个表中,变成一张大表,最后做一次单表查询
select
*
from
employee as t1 inner join (1号数据) as t2 on t1.post = t2.post
where
t1.hire_date = t2.max_date
3.综合拼装
select
emp_name , max_date
from
employee as t1 inner join (select post,max(hire_date) as max_date from employee group by post) as t2 on t1.post = t2.post
where
t1.hire_date = t2.max_date
七.带EXISTS关键字的子查询
"""
exists 关键字 , 表达存在 , 应用在子查询中
如果内层sql , 能够查到数据, 返回True , 外层sql执行相应的sql语句
如果内层sql , 不能查到数据, 返回False , 外层sql不执行sql语句
"""
select * from employee where exists (select * from employee where id = 1);
select * from employee where exists (select * from employee where id = 100000);
"""
总结:
子查询可以单独作为临时数据,作为一张表或者一个字段,通过()进行包裹,表达一个整体;
一般用在from,where,select.子句的后面
可以通过查询出来的数据和另外的表做联表变成更大一张表,
最后做单表查询,达到目的;
"""
# 176)python 操作 mysql
- 基本语法
import pymysql
# (1) 创建连接对象 host user password database 这四个参数必写
conn = pymysql.connect(host='127.0.0.1',user='root',password='123456',database='db001',charset='utf8',port=3306)
# (2) 创建游标对象(用来操作数据库的增删改查)
cursor = conn.cursor()
print(cursor) # <pymysql.cursors.Cursor object at 0x7fb6fbd0c978>
# (3) 执行sql语句
sql = 'select * from employee'
# 执行查询语句返回的数据总条数
res = cursor.execute(sql)
print(res) # 18
# (4) 获取数据 fetchone 获取一条数据
# 返回的是元组,里面包含的是第一条的完整数据
res = cursor.fetchone()
print(res)
# (1, 'egon', 'male', 18, datetime.date(2017, 3, 1), '老男孩驻沙河办事处外交大使', None, 7300.33, 401, 1)
res = cursor.fetchone()
print(res)
# (2, 'alex', 'male', 78, datetime.date(2015, 3, 2), 'teacher', None, 1000000.31, 401, 1)
# (5) 释放游标对象
cursor.close()
# (6) 释放连接对象
conn.close()
- python创建/删除/表
import pymysql
conn = pymysql.connect(host='127.0.0.1',user='root',password='123456',database='db001',charset='utf8',port=3306)
cursor = conn.cursor()
# 1. 创建一张表
sql = '''
create table t1(
id int unsigned primary key auto_increment,
first_name varchar(255) not null,
last_name varchar(255) not null,
sex tinyint not null,
age tinyint unsigned not null,
money float
)
'''
res = cursor.execute(sql)
print(res) # 0 无意义
# 2. 查询表结构
sql = 'desc t1'
res = cursor.execute(sql)
print(res) # 6 返回的是字段的个数
res = cursor.fetchone()
print(res) # ('id', 'int(10) unsigned', 'NO', 'PRI', None, 'auto_increment')
res = cursor.fetchone()
print(res) # ('first_name', 'varchar(255)', 'NO', '', None, '')
# 3. 删除表
sql = 'drop table t1'
res = cursor.execute(sql)
print(res) # 0 无意义
cursor.close()
conn.close()
- 事务处理
'''
pymysql 默认开启事务的,所有增删改的数据必须提交,否则默认回滚rollback(保证数据安全)
'''
import pymysql
conn = pymysql.connect(host='127.0.0.1',user='root',password='123456',database='db001',charset='utf8',port=3306)
cursor = conn.cursor()
sql1 = 'begin'
sql2 = "update employee set emp_name='程咬钻石' where id = 18"
sql3 = 'commit'
res1 = cursor.execute(sql1)
res1 = cursor.execute(sql2)
res1 = cursor.execute(sql3)
cursor.close()
conn.close()
-
sql 注入攻击
(1)
import pymysql
# 1. sql攻击注入的现象
user = input('请输入您的用户名>>>') # asdasd' or 8=8 -- sdfsdfsdf 次语句会绕开检测
pwd = input('请输入您的密码>>>')
conn = pymysql.connect(host='127.0.0.1',user='root',password='123456',database='db005',charset='utf8',port=3306)
cursor = conn.cursor()
sql2 = "select * from usr_pwd where username='%s' and password='%s' " % (user,pwd)
res = cursor.execute(sql2)
print(res)
print('登录成功'if res else '登录失败')
'''
asdasd' or 8=8 -- sdfsdfsdf 次语句会绕开检测
'''
cursor.close()
conn.close()
(2)预处理机制
'''在执行sql语句之前,提前对sql语句中出现的字符进行过 滤优化,避免sql注入攻击'''
'''execute(sql,(参数1,参数2,参数3 ....))'''
'''填写 asdasd' or 8=8 -- sdfsdfsdf 尝试攻击'''
import pymysql
# 1. sql攻击注入的现象
user = input('请输入您的用户名>>>')
pwd = input('请输入您的密码>>>')
conn = pymysql.connect(host='127.0.0.1',user='root',password='123456',database='db005',charset='utf8',port=3306)
cursor = conn.cursor()
sql2 = "select * from usr_pwd where username=%s and password=%s "
res = cursor.execute(sql2,(user,pwd))
print(res)
print('登录成功'if res else '登录失败')
'''
asdasd' or 8=8 -- sdfsdfsdf 次语句会绕开检测
'''
cursor.close()
conn.close()
177)pyhton 操作mysql 数据库(增删改查)
- 增
'''
python 操作mysql增删改时,默认时开启事务的,
必须最后commit提交数据,才能发生变化
提交数据: commit
默认回滚: rollback
'''
import pymysql
conn = pymysql.connect(host='127.0.0.1',user='root',password='123456',database='db005',charset='utf8',port=3306)
# 默认获取查询结果时返回的是元组,可以设置为字典
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
sql = "insert into t1(first_name,last_name,sex,age,money) values(%s,%s,%s,%s,%s)"
# 一次插入一条数据
res = cursor.execute(sql,("孙","健",0,15,20000)) # 此时数据库新增一条数据
print(res) # 1 执行成功
# 获取最后插入这条数据的id号
print(cursor.lastrowid) # 1
# 一次插入多条
res = cursor.executemany(sql,[("余","凯",0,15,30000),("赵","芹",0,15,50000),("王","一",0,15,7000)])
print(res) # 返回插入的数据总条数 3
# 插入5条数据中的第一条数据的id
print(cursor.lastrowid)# 3
# 获取最后一个数据的Id
sql = 'select id from t1 order by id desc limit 1'
res = cursor.execute(sql)
print(res) # 1 执行成功
res = cursor.fetchone()
print(res) # {'id': 13}
conn.commit()
cursor.close()
conn.close()
- 删
import pymysql
conn =pymysql.connect(host='127.0.0.1',user='root',password='123456',database='db005',charset='utf8',port=3306)
# 默认获取查询结果时返回的是元组,可以设置为字典
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
sql = "delete from t1 where id in (%s,%s,%s)"
res = cursor.execute(sql,(1,2,3))
print(res) # 3 表示删除了3条数据
print('删除成功'if res else '删除失败')
conn.commit()
cursor.close()
conn.close()
- 改
import pymysql
conn = pymysql.connect(host='127.0.0.1',user='root',password='123456',database='db005',charset='utf8',port=3306)
# 默认获取查询结果时返回的是元组,可以设置为字典
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
sql = "update t1 set first_name = '余' where id = %s"
sql = "update t1 set first_name = '余' where id in (%s,%s,%s)"
res = cursor.execute(sql,(4,5,6))
print(res) # 3 表示修改了3条数据
print('修改成功'if res else '修改失败')
conn.commit()
cursor.close()
conn.close()
- 查
import pymysql
conn = pymysql.connect(host='127.0.0.1',user='root',password='123456',database='db005',charset='utf8',port=3306)
# 默认获取查询结果时返回的是元组,可以设置为字典
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
sql = "select * from t1"
res = cursor.execute(sql)
# 获取一条
res = cursor.fetchone()
print(res) # {'id': 4, 'first_name': '余', 'last_name': '芹', 'sex': 0, 'age': 15, 'money': 50000.0}
# 获取多条
res = cursor.fetchmany(3)
print(res)
'''
[{'id': 5, 'first_name': '余', 'last_name': '一', 'sex': 0, 'age': 15, 'money': 7000.0},
{'id': 6, 'first_name': '余', 'last_name': '健', 'sex': 0, 'age': 15, 'money': 20000.0},
{'id': 7, 'first_name': '余', 'last_name': '凯', 'sex': 0, 'age': 15, 'money': 30000.0}
]
'''
# 获取所有
res = cursor.fetchall()
print(res) # 从id 为8开始获取所有剩下的数据
conn.commit()
cursor.close()
conn.close()
- 相对滚动和绝对滚动
'''
相对滚动:
相对于上一次查询的位置往前移动(负数),或者往后移动(正数)
'''
import pymysql
conn = pymysql.connect(host='127.0.0.1',user='root',password='123456',database='db005',charset='utf8',port=3306)
# 默认获取查询结果时返回的是元组,可以设置为字典
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
sql = "select * from t1"
res = cursor.execute(sql)
# 获取一条
res = cursor.fetchone()
print(res) # {'id': 4, 'first_name': '余', 'last_name': '芹', 'sex': 0, 'age': 15, 'money': 50000.0}
# 获取多条
res = cursor.fetchmany(3)
print(res)
'''
[{'id': 5, 'first_name': '余', 'last_name': '一', 'sex': 0, 'age': 15, 'money': 7000.0},
{'id': 6, 'first_name': '余', 'last_name': '健', 'sex': 0, 'age': 15, 'money': 20000.0},
{'id': 7, 'first_name': '余', 'last_name': '凯', 'sex': 0, 'age': 15, 'money': 30000.0}
]
'''
cursor.scroll(-1,mode='relative')
res = cursor.fetchone()
print(res) # {'id': 7, 'first_name': '余', 'last_name': '凯', 'sex': 0, 'age': 15, 'money': 30000.0}
cursor.scroll(5,mode='relative')
res = cursor.fetchone()
print(res) # {'id': 13, 'first_name': '王', 'last_name': '一', 'sex': 0, 'age': 15, 'money': 7000.0}
conn.commit()
cursor.close()
conn.close()
'''
绝对滚动:
永远从数据的开头起始位置进行移动,不能向前滚
'''
import pymysql
conn = pymysql.connect(host='127.0.0.1',user='root',password='123456',database='db005',charset='utf8',port=3306)
# 默认获取查询结果时返回的是元组,可以设置为字典
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
sql = "select * from t1"
res = cursor.execute(sql)
# 获取一条
res = cursor.fetchone()
print(res) # {'id': 4, 'first_name': '余', 'last_name': '芹', 'sex': 0, 'age': 15, 'money': 50000.0}
# 获取多条
res = cursor.fetchmany(3)
print(res)
'''
[{'id': 5, 'first_name': '余', 'last_name': '一', 'sex': 0, 'age': 15, 'money': 7000.0},
{'id': 6, 'first_name': '余', 'last_name': '健', 'sex': 0, 'age': 15, 'money': 20000.0},
{'id': 7, 'first_name': '余', 'last_name': '凯', 'sex': 0, 'age': 15, 'money': 30000.0}
]
'''
# 从0开始获取第一条数据
cursor.scroll(0,mode='absolute')
res = cursor.fetchone()
print(res)# {'id': 4, 'first_name': '余', 'last_name': '芹', 'sex': 0, 'age': 15, 'money': 50000.0}
# 重头开始滚动两下获取第三个
cursor.scroll(2,mode='absolute')
res = cursor.fetchone()
print(res)# {'id': 6, 'first_name': '余', 'last_name': '健', 'sex': 0, 'age': 15, 'money': 20000.0}
conn.commit()
cursor.close()
conn.close()
178)数据库的导入和导出
- 导出数据库
1. 退出mysql
2. cmd进入C盘或者D盘根目录
3. mysqldump -uroot -p db001 > db001.sql # db001数据库名 导出整个数据库
# 导出部分表
mysqldump -uroot -p db001 表1 表2 > ceshi110.sql
- 导入数据库
1.登录到mysql之后
2.创建新的数据库
3.sourec 路径+文件 # source c:\db001.sql
179)配置linux下的编码集
1. 查看my.cnf配置文件具体位置 sudo find / -name my.cnf
/var/lib/dpkg/alternatives/my.cnf
/etc/alternatives/my.cnf
/etc/mysql/my.cnf # 选择mysql这个
2. cat 读取 文件 cat /etc/mysql/my.cnf
# 获取到两个文件 一个是修改客户端 一个是修改服务端
!includedir /etc/mysql/conf.d/ # 客户端的修改
!includedir /etc/mysql/mysql.conf.d/ # 服务端的修改
3. cd /etc/mysql/conf.d/
sudo nano my.cnf
把windows中的my.ini文件打开
复制# 设置mysql客户端默认字符集
default-character-set=utf8
4. cd /etc/mysql/mysql.conf.d/
sudo nano my.cnf
把windows中的my.ini文件打开
复制# 服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8
5. service mysql restart
登录mysql 输入 \s 查看结果
Server characterset: utf8
Db characterset: utf8
Client characterset: utf8
Conn. characterset: utf8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号