基本概念
1.基本概念
hive是由facebook开源用于解决海量结构化日志的数据统计
hive是基于Hadoop得一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类sql查询功能
本质:将HQL转化为mapreduce程序
(1)hive处理的数据存储在HDFS
(2)hive分析数据的底层的默认实现是Mapreduce
(3)执行程序运行在Yarn上
2.自定义函数
(1)UDF(user-defined-function)
一进一出
(2)UDAF(user-defined Aggregation function)
聚集函数:多进一出,类似于count
(3)UDTF(user-defined generating function)
一进多出
3.优缺点
优点:
(1)类sql语法,避免写mapreduce,简单上手
(2)处理大数据
(3)支持自定义函数
(4)执行延迟比较高,适用于对实时性要求不高的场合,数据分析
缺点:
(1)hive的hql表达能力不足:
迭代算法无法表达
数据挖掘不擅长
(2)效率低
mapreduce不能智能化
调优困难
4.架构原理
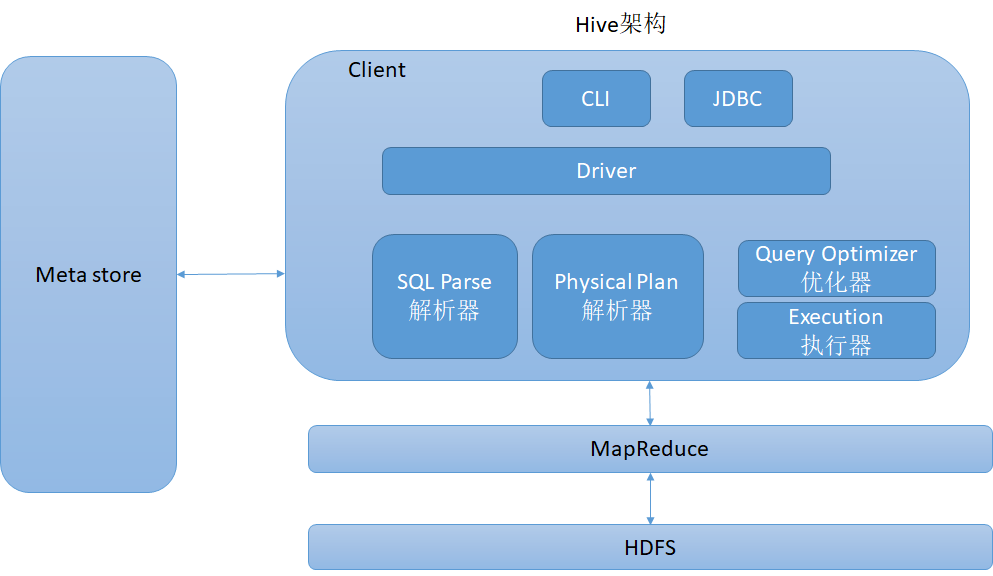
(1)用户接口:Client
CLI(hive shell),JDBC/ODBC(java访问hive),WEBUI(浏览器访问hive)
(2)元数据:MetaStore
元数据包括:表名,表所属的数据库(默认default),拥有者,字段,表类型(是否外部表),数据所在目录
默认存储在Derby数据库中,推荐使用Mysql存储
(3)HADOOP
常用HDFS进行存储,mapreduce进行计算
(4)驱动器:Driver
解析器,编译器,优化器,执行器
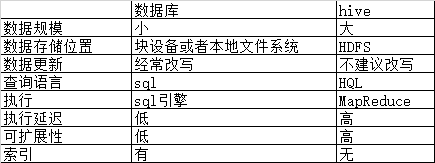
5.数据库比较
posted on 2020-12-02 18:43 happygril3 阅读(95) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号