
graphx简介
1. GraphX的框架
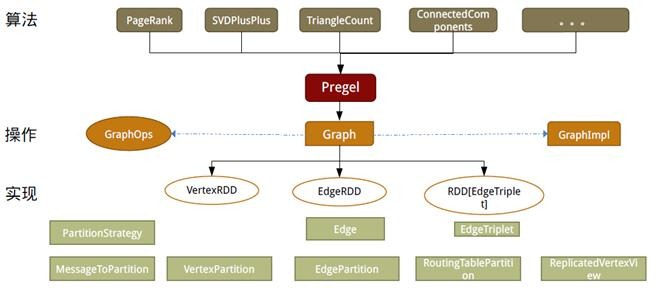
1.1图存储模式
边分割(Edge-Cut):
每个顶点都存储一次,但有的边会被打断分到两台机器上。
优点:节省存储空间;
缺点:对图进行基于边的计算时,对于一条两个顶点被分到不同机器上的边来说,要跨机器通信传输数据,内网通信流量大。
点分割(Vertex-Cut)
每条边只存储一次,都只会出现在一台机器上。
优点:减少内网通信量。
缺点:邻居多的点会被复制到多台机器上,增加了存储开销,同时会引发数据同步问题。
1.2GraphX存储模式
Graphx借鉴PowerGraph,使用的是Vertex-Cut(点分割)方式存储图,用三个RDD存储图数据信息:
VertexTable(id, data):id为Vertex id,data为Edge data
EdgeTable(pid, src, dst, data):pid为Partion id,src为原定点id,dst为目的顶点id
RoutingTable(id, pid):id为Vertex id,pid为Partion id

1.3图计算模式
目前基于图的并行计算框架已经有很多,比如来自Google的Pregel、来自Apache开源的图计算框架Giraph/HAMA以及最为著名的GraphLab,其中Pregel、HAMA和Giraph都是非常类似的,都是基于BSP(Bulk Synchronous Parallell)模式。
BulkSynchronous Parallell,即整体同步并行,它将计算分成一系列的超步(superstep)的迭代(iteration)。从纵向上看,它是一个串行模式,而从横向上看,它是一个并行的模式,每两个superstep之间设置一个栅栏(barrier),即整体同步点,确定所有并行的计算都完成后再启动下一轮superstep。
2. 图例演示
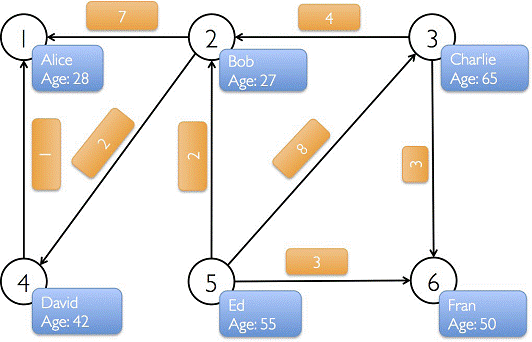

package graphx import org.apache.log4j.{Level,Logger} import org.apache.spark.{SparkConf,SparkContext} import org.apache.spark.graphx._ import org.apache.spark.rdd.RDD object test01 { def main(args:Array[String]){ //屏蔽日志 Logger.getLogger("org.apache.spark").setLevel(Level.WARN) Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF) //设置运行环境 val conf: SparkConf = new SparkConf().setAppName("my graphx").setMaster("local") val sc = new SparkContext(conf) //TODO 构造vertextArray和edgeArray //顶点的数据类型 VD:(String,Int) val vertexArray = Array( (1L, ("Alice", 28)), (2L, ("Bob", 27)), (3L, ("Charlie", 65)), (4L, ("David", 42)), (5L, ("Ed", 55)), (6L, ("Fran", 50)) ) //边的数据类型ED:(Int) val edgeArray = Array( Edge(2L, 1L, 7), Edge(2L, 4L, 2), Edge(3L, 2L, 4), Edge(3L, 6L, 3), Edge(4L, 1L, 1), Edge(5L, 2L, 2), Edge(5L, 3L, 8), Edge(5L, 6L, 3) ) //TODO 构造vertextRDD和edgeRDD val vertextRDD: RDD[(VertexId, (String, PartitionID))] = sc.makeRDD(vertexArray) val edgeRDD: RDD[Edge[PartitionID]] = sc.makeRDD(edgeArray) //TODO 构造graph val graph:Graph[(String,Int),Int] = Graph(vertextRDD,edgeRDD)
posted on 2020-10-27 14:50 happygril3 阅读(718) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号