第一次个人编程作业
简单的论文查重
Part one 作业地址与Github链接
| 项目 | 内容 |
|---|---|
| 作业地址 | 第一次个人编程作业 |
| Github链接 | 点击查看详细代码 |
Part two 计算模块接口的设计与实现过程
整体程序流程图
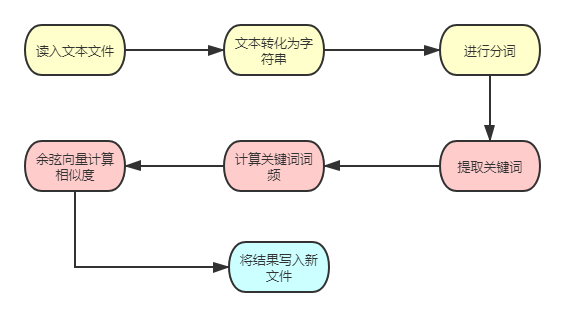
算法思想介绍
1.分词:给定一段语句,进行结巴分词,得到有效的特征向量,如下:
今天是星期天,天气晴,今天晚上我要去看电影=['今天','是','星期天','天气','晴','今天','晚上','我','要','去','看电影']
今天是周天,天气晴朗,我晚上要去看电影 =['今天','是','周天','天气','晴朗','我',晚上',',要','去','看电影']
2.提取关键词,将关键词进行量化,用数据表示关键词出现的位置,列出句子当中出现的关键词,将语句1和语句2放在一个Set中,得到:
Set={'看电影','星期天','周天','今天', '天气','晴', '晴朗', '晚上', '我', '要', '去', '是'}
再将上述Set的词汇进行排序,key为Set中的词,value为Set中词出现的位置,如下:
{'看电影':0,'今天':1,'星期天':2,'周天':3, '天气':4,'晴':5, '晴朗':6, '晚上':7, '我':8, '要':9, '去':10, '是':11}
3.利用OneHot编码算法,计算每个关键词出现的次数,可以得知关键词词频,如Onehot对句子1与句子2进行编码后得到的结果如下:
['今天','是','星期天','天气','晴','今天','晚上','我','要','去','看电影']= [1, 2, 1, 0, 1, 1, 0, 1, 1, 1, 1]
['今天','是','周天','天气','晴朗','我',晚上',',要','去','看电影']= [1, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1]
4.余弦相似度算法:一个向量空间中两个向量夹角间的余弦值作为衡量两个个体之间差异的大小,余弦值接近1,夹角趋于0,表明两个向量越相似,余弦值接近于0,夹角趋于90度,表明两个向量越不相似。
余弦函数在三角形中的计算公式为:
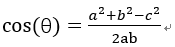
在直角坐标系中,向量a和向量b在直角坐标中的长度为向量a和向量b之间的距离我们用向量c表示,将a,b,c带入三角函数的公式中得到如下的公式:
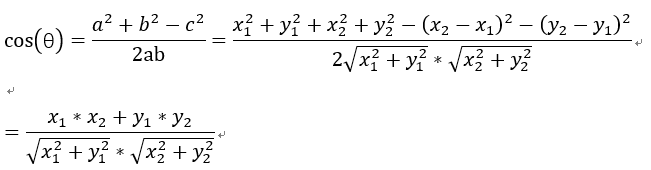
这是二维空间中余弦函数的公式,多维空间余弦函数的公式就是:
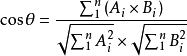
Part three PSP表格
| PSP2.1 | *Personal Software Process Stages* | *预估耗时(分钟)* | *实际耗时(分钟)* |
|---|---|---|---|
| Planning | 计划 | 40 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 50 |
| Development | 开发 | 440 | 480 |
| · Analysis | · 需求分析 (包括学习新技术) | 430 | 480 |
| · Design Spec | · 生成设计文档 | 30 | 40 |
| · Design Review | · 设计复审 | 50 | 50 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 70 | 80 |
| · Design | · 具体设计 | 50 | 60 |
| · Coding | · 具体编码 | 160 | 340 |
| · Code Review | · 代码复审 | 40 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 40 | 50 |
| Reporting | 报告 | 100 | 120 |
| · Test Repor | · 测试报告 | 40 | 50 |
| · Size Measurement | · 计算工作量 | 20 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 40 | 40 |
| · 合计 | 1610 | 1960 |
Part four 计算机接口部分的性能改善
1.结巴分词
先去除特殊符号对断句的影响,再利用结巴分词语句拆分
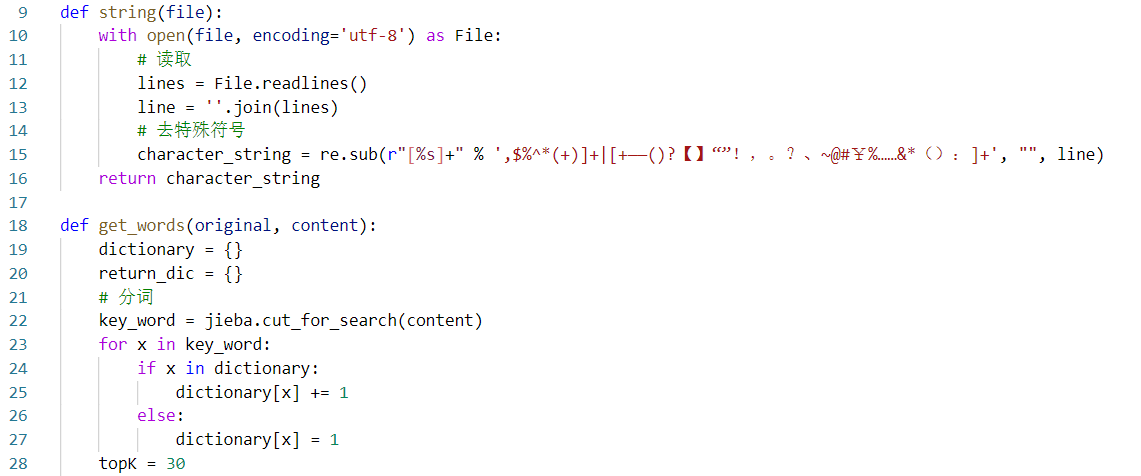
2.关键词词频
计算出关键词在语句当中出现的次数,计算出各个关键词的词频

3.余弦相似度的计算
利用余弦相似度计算文章的重合率
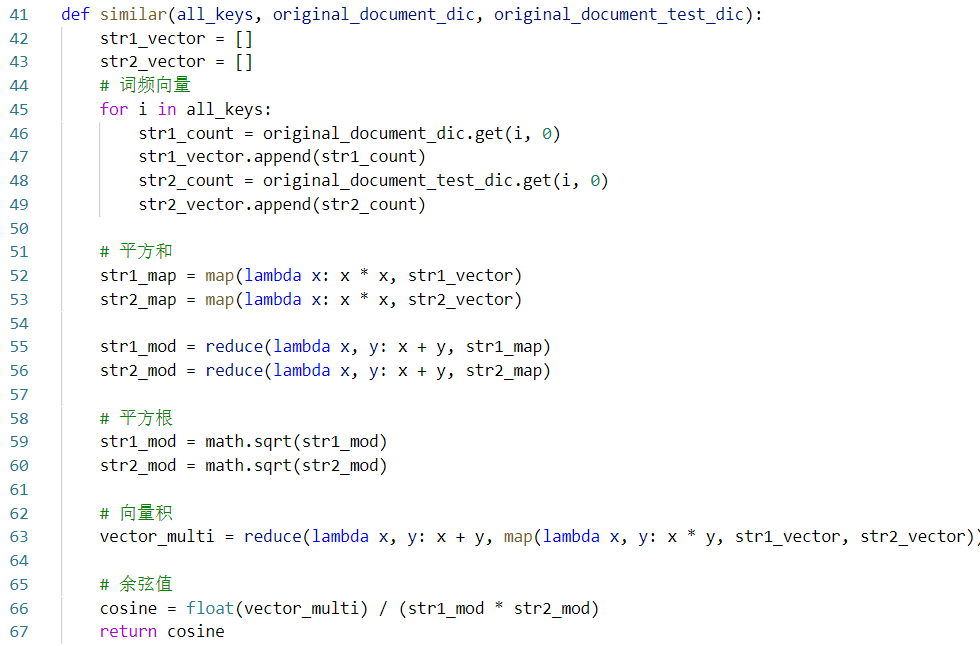
4.测试代码
输入原文件的路径,与其他需要查重的文件进行相似度对比
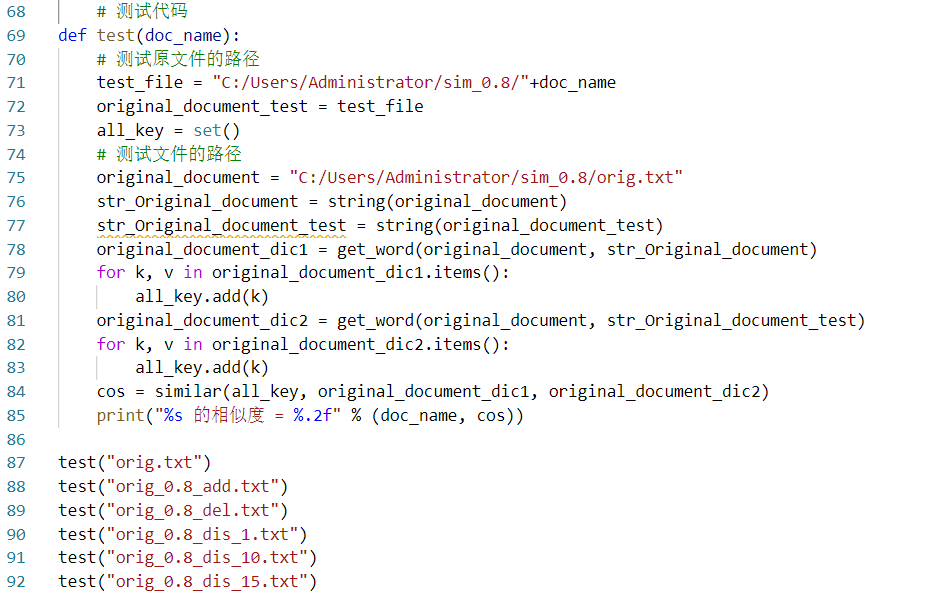
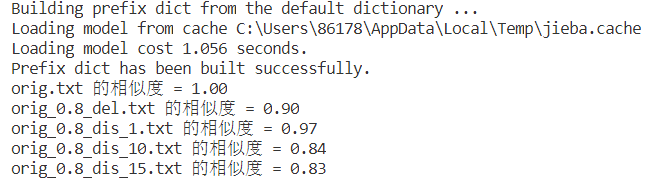
5.测试结果展示
原文件与各测试查重的文件余弦相似度如下图所示:
6.代码覆盖率
利用pycharm进行代码覆盖率分析

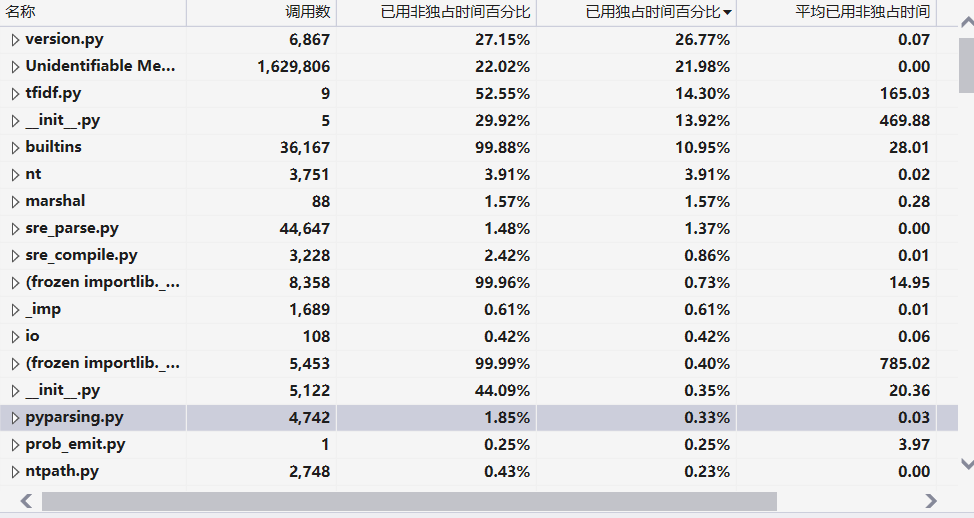
7.性能分析
利用VS进行性能分析
数据展示

调用关系树

消耗最大
Part five 异常部分说明
写了一个简单的异常测试,如果文件里面没有内容,则输出为空文件,如下:

Part six.总结
一开始看到题目的时候完全没有头绪,后来不断的查阅网络资料,也借鉴参考了有些同学提交的作业后,慢慢有了思路,从基于余弦定理的文本相似度,倒推到关键词的词频计算,再到关键词量化,参考了好几个大的网站资料,这无不在体现出我知识量存储不够,掌握技能不全。通过这次作业,我也感觉我学习到了许多,了解到许多以前完全没有接触的模块,加深了对代码的理解,但相信在不断的练习下,总会慢慢掌握并且熟练运行这些功能。
Part seven.参考文献
1.详解Onehot编码 https://www.cnblogs.com/shuaishuaidefeizhu/p/11269257.html
2.余弦相似度公式以及推导 https://blog.csdn.net/smile_shujie/article/details/89516305
3.相似度算法之余弦相似度 https://blog.csdn.net/zz_dd_yy/article/details/51926305
4.结巴分词 https://www.cnblogs.com/palace/p/9599443.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号