霍夫曼编码 & 基于区域增长的图像分割算法
图像处理与机器视觉第三次作业
task1、霍夫曼编码。
对给定图像lena.bmp进行霍夫曼编码,在word中贴出代码,以及编码的码字结果、编码的平均长度、压缩比值。
1.1 实验结果

1.2 实现步骤如下
- 读取图像并将其转换为灰度图像;
- 计算图像总像素数N和每个灰度级的频率freq;
- 计算每个灰度级的概率prob;
- 使用matlab自带的函数huffmandict生成霍夫曼编码字典dict;
- 对图像进行霍夫曼编码,得到编码后的码字code;
- 计算编码后的码字长度len;
- 计算编码后的平均长度avg_len;
- 计算压缩比值ratio,其中8表示原图每个像素使用8位二进制表示;
- 显示结果。
1.3 代码
% 读取图像
img = imread('lena.bmp');
% 转换为灰度图像
img = im2gray(img);
% 获取图像的大小
[m,n] = size(img);
% 计算图像的总像素数
N = m*n;
% 计算图像的每个灰度级的频率
freq = zeros(1,256);
for i = 1:m
for j = 1:n
freq(img(i,j)+1) = freq(img(i,j)+1) + 1;
end
end
% 计算图像的每个灰度级的概率
prob = freq / N;
% 使用matlab自带的函数生成霍夫曼编码字典
dict = huffmandict(0:255,prob);
% 对图像进行霍夫曼编码
code = huffmanenco(img(:),dict);
% 计算编码后的码字长度
len = length(code);
% 计算编码后的平均长度
avg_len = len / N;
% 计算压缩比值
ratio = 8 / avg_len;
% 显示结果
disp('编码后的码字长度为:');
disp(len);
disp('编码后的平均长度为:');
disp(avg_len);
disp('压缩比值为:');
disp(ratio);
task2、基于区域增长的图像分割算法
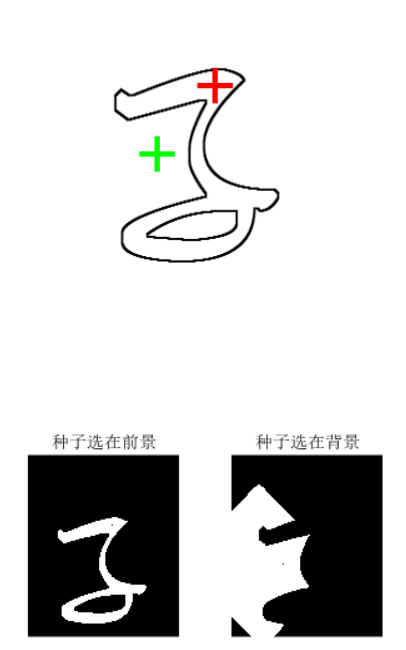
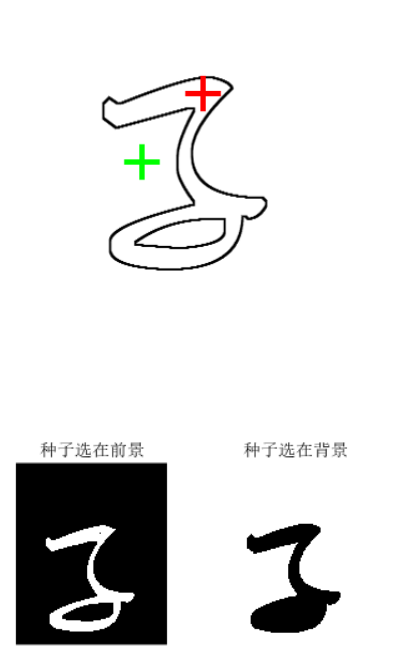
2.1 实验结果
| 中间结果图 | 结果图 |
|---|---|
 |
 |
2.2 实现步骤
- 读取图像并转化为灰度图像。
I = imread('regiongrowing.bmp');
I = im2gray(I);
- 在图像上选择两个种子点,作为两个区域的起始点。
figure; imshow(I, []);
[x1, y1] = ginput(1);
hold on; plot(x1, y1, 'r+', 'MarkerSize', 20, 'LineWidth', 3);
[x2, y2] = ginput(1);
plot(x2, y2, 'g+', 'MarkerSize', 20, 'LineWidth', 3);
- 对两个种子点进行区域增长,将同一区域内的像素标记为1,不属于该区域的像素标记为0。
reg_maxdist = 10;
J1 = regiongrowing(I, round(y1), round(x1), reg_maxdist);
J2 = regiongrowing(I, round(y2), round(x2), reg_maxdist);
- 将两个区域的标记结果保存为图像文件,便于进行结果分析。
imwrite(J1, 'regiongrowing1.bmp');
imwrite(J2, 'regiongrowing2.bmp');
- 绘制两个区域的标记结果。
figure;
subplot(121); imshow(J1, []); title('Seed1');
subplot(122); imshow(J2, []); title('Seed2');
- 实现区域增长算法的具体细节。该算法基于队列,将种子点从队尾放入队列,按照广度优先的顺序,从队首取出元素。遍历图像中与当前像素距离小于阈值且未被访问过的像素,标定为同一区域内的像素,将其加入队列。
function J = regiongrowing(I, seed_row, seed_col, thresh)
- 此处定义了一个名为 regiongrowing() 的函数,它接收四个参数:输入图像 I、种子点的行坐标 seed_row、种子点的列坐标 seed_col,以及区域增长的最大距离 thresh。
J = zeros(size(I));
visited = zeros(size(I));
queue = zeros(10000, 2);
queue_len = 0;
- 这四行代码初始化了输出图像 J、访问标志矩阵 visited、队列 queue,以及队列长度 queue_len。其中,J 和 visited 的大小与输入图像 I 相同,而 queue 的大小为 10000×2,表示队列最多可以存储 10000 个二维坐标。queue_len 初始值为 0,表示队列为空。
queue_len = queue_len + 1;
queue(queue_len, :) = [seed_row, seed_col];
visited(seed_row, seed_col) = 1;
- 首先将队列长度加一,并将种子点 (seed_row, seed_col) 加入队列。由于种子点已经被访问过,所以在访问标志矩阵 visited 中将其标记为 1。
while queue_len > 0
current_pixel = queue(queue_len, :);
queue_len = queue_len - 1;
row = current_pixel(1);
col = current_pixel(2);
-
接下来进入 while 循环。只要队列不为空,就一直执行循环。每次循环从队尾取出一个元素,并将队列长度减一。这里的队列是先进先出(FIFO)的,因此每次取出的元素是距离种子点最远的像素。
-
然后将取出的像素的行坐标和列坐标分别保存到 row 和 col 变量中。
if (row > 1 && visited(row-1, col) == 0 && abs(I(row, col) - I(row-1, col)) <= thresh)
queue_len = queue_len + 1;
queue(queue_len, :) = [row-1, col];
visited(row-1, col) = 1;
J(row-1, col) = 1;
end
if (col > 1 && visited(row, col-1) == 0 && abs(I(row, col) - I(row, col-1)) <= thresh)
queue_len = queue_len + 1;
queue(queue_len, :) = [row, col-1];
visited(row, col-1) = 1;
J(row, col-1) = 1;
end
if (row < size(I,1) && visited(row+1, col) == 0 && abs(I(row, col) - I(row+1, col)) <= thresh)
queue_len = queue_len + 1;
queue(queue_len, :) = [row+1, col];
visited(row+1, col) = 1;
J(row+1, col) = 1;
end
if (col < size(I,2) && visited(row, col+1) == 0 && abs(I(row, col) - I(row, col+1)) <= thresh)
queue_len = queue_len + 1;
queue(queue_len, :) = [row, col+1];
visited(row, col+1) = 1;
J(row, col+1) = 1;
end
-
接下来对当前像素的四个相邻像素进行遍历。只有满足以下三个条件的像素才标记为同一区域内的像素:
- 距离种子点的距离小于等于阈值 thresh;
- 该像素未被访问过;
- 当前像素与相邻像素的灰度值差不超过阈值 thresh。
-
如果这些条件都满足,就将相邻像素的坐标加入队列,并在访问标志矩阵 visited 中标记为访问过;同时,在输出图像 J 中将其对应位置的像素标记为 1。
end
- 最后结束 while 循环。
end
- 最后结束函数的定义。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号