
【CV源码解析】Yolov3-Darknet版本计算mAP、loss/iou曲线
前言
VOC中的xml文件


<annotation>
<folder>VOC2012</folder> //文件名
<filename>2007_000346.jpg</filename>
<source> //文件来源
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
</source>
<size> //文件大小(宽度、高度、通道数)
<width>500</width>
<height>375</height>
<depth>3</depth>
</size>
<segmented>1</segmented> //是否用于分割
<object> //检测物体说明
<name>bottle</name> //所检测到的物体
<pose>Unspecified</pose> //拍摄角度(未详细说明)
<truncated>0</truncated> //是否被截断(0代表未被截断)
<difficult>0</difficult> //目标是否难以识别(0代表容易识别)
<bndbox> //左下和右上坐标
<xmin>124</xmin>
<ymin>107</ymin>
<xmax>230</xmax>
<ymax>343</ymax>
</bndbox>
</object>
<object> //所检测的另一物体
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>137</xmin>
<ymin>78</ymin>
<xmax>497</xmax>
<ymax>375</ymax>
</bndbox>
</object>
<object>
<name>person</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>89</xmin>
<ymin>202</ymin>
<xmax>129</xmax>
<ymax>247</ymax>
</bndbox>
</object>
<object>
<name>person</name>
<pose>Frontal</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>72</xmin>
<ymin>209</ymin>
<xmax>111</xmax>
<ymax>259</ymax>
</bndbox>
</object>
</annotation>
其中
<segmented>1</segmented> //是否用于分割
<object> //检测物体说明
<name>bottle</name> //所检测到的物体
<pose>Unspecified</pose> //拍摄角度(未详细说明)
<truncated>0</truncated> //是否被截断(0代表未被截断)
<difficult>0</difficult> //目标是否难以识别(0代表容易识别)
<bndbox> //左下和右上坐标
<xmin>124</xmin>
<ymin>107</ymin>
<xmax>230</xmax>
<ymax>343</ymax>
</bndbox>
difficult代表是否难以识别,0表示易识别,1表示难识别。通常读取时略过这类;
定制数据集计算mAP,需要根据数据集的属性,改写代码;
计算过程:
1) 选择一个类,做ap计算;
2) 对所有图片,该类box的检测,按照预测得分(所有置信度)从大到小排序;
3) 按照这个顺序,计算累计tp, fp, 进而计算累计precision, recall;
4) 然后按照0, 0.1, 0.2 ... 0.9 1.0 ,这11各点,10个区间,得到折线图,然后得到11个顶点,进而计算这11个顶点的平均值,就得到了,这个类的ap;
5) 对所有类,计算ap, 然后对这些ap加和,除以类别数,得到mAP;
比如,所有测试集中计算某类别的AP,有m个gt,n个预测框(置信度+bbox),若:
1)预测框与真实框的IOU大于IOU_T(=0.5,即AP50),则这个样本为真正例TP += 1;
2)如果小于阈值,则没框上的标签框导致 FN += 1,框错的预测框导致FP += 1;
3)准确度是TP/(TP+FP),即正确预测/总预测正例;召回率是TP/nPOS,即正确预测/总真实正例;
在这基础上,使用置信度Score划拉预测框的个数,计算PR曲线上的点,根据曲线下的面积算AP值。
从官方那边抠出来的AP计算代码,代码内部分为voc2007之前的11点计算方法和voc2007之后的方法,目前都已经采用voc2007之后的计算方法。
import os import numpy as np # imagesetfile = "../tflu/valid.txt" # annopath = "" # imgfile = open(imagesetfile, 'r') # lines = imgfile.readlines() # imagename = lines[0].strip() # print(imagename) # imagenames = [x.strip() for x in lines] # # annopath = '{}.xml' # # annopath.format(imagename) # # # parse_tflu_anno # annoname = imagename.replace('images', 'labels') # annoname = annoname.replace('png', 'txt') # annofile = open(annoname, 'r') # annolines = annofile.readlines() # annoline = annolines[0].strip().split(' ') # clas = tuple(map(int, annoline[0])) # bbox = tuple(map(float, annoline[1:])) # det img_w = 1280 img_h = 720 # tfl_label = {'circle_green':0, 'circle_red':1, 'circle_yellow':2, 'circle_off':3, 'left_green':4, 'left_red':5, 'left_yellow':6, 'left_off':7, 'nomotor_green':8, 'nomotor_red':9, 'nomotor_yellow':10, 'nomotor_off':11} tfl_label = ['circle_green', 'circle_red', 'circle_yellow', 'circle_off', 'left_green', 'left_red', 'left_yellow', 'left_off', 'nomotor_green', 'nomotor_red', 'nomotor_yellow', 'nomotor_off'] def parse_tflu(filename): """ Parse a TFL u txt file anno bbox: xc, yc, w, h """ objects = [] annofile = open(filename, 'r') annolines = annofile.readlines() for i, annoline in enumerate(annolines): obj_struct = {} annoline = annoline.strip().split(' ') obj_struct['name'] = tfl_label[tuple(map(int, annoline[0]))[0]] bbox = tuple(map(float, annoline[1:])) # (xc, yc, w, h) ---> (xmin, ymin, xmax, ymax) xmin = (bbox[0] - bbox[2]*0.5) * img_w xmax = (bbox[0] + bbox[2]*0.5) * img_w ymin = (bbox[1] - bbox[3]*0.5) * img_h ymax = (bbox[1] + bbox[3]*0.5) * img_h if xmin < 0: xmin = 0 if ymin < 0: ymin = 0 if xmax > img_w-1: xmax = img_w-1 if ymax > img_h-1: ymax = img_h-1 obj_struct['bbox'] = [int(xmin), int(ymin), int(xmax), int(ymax)] obj_struct['difficult'] = 0 # 0-easy, 1-difficult objects.append(obj_struct) return objects def voc_ap(rec, prec, use_07_metric=False): """ ap = voc_ap(rec, prec, [use_07_metric]) Compute VOC AP given precision and recall. If use_07_metric is true, uses the VOC 07 11 point method (default:False). """ if use_07_metric: # 11 point metric ap = 0. for t in np.arange(0., 1.1, 0.1): if np.sum(rec >= t) == 0: p = 0 else: p = np.max(prec[rec >= t]) ap = ap + p / 11. else: # correct AP calculation # first append sentinel values at the end mrec = np.concatenate(([0.], rec, [1.])) mpre = np.concatenate(([0.], prec, [0.])) # compute the precision envelope for i in range(mpre.size - 1, 0, -1): mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i]) # to calculate area under PR curve, look for points # where X axis (recall) changes value i = np.where(mrec[1:] != mrec[:-1])[0] # and sum (\Delta recall) * prec ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) return ap def tfl_eval(detpath, annopath, datasetfile, classname, ovthresh, use_07_metric=False): print('tfl eval of class: ', classname) imgfile = open(datasetfile, 'r') imglines = imgfile.readlines() imagenames = [x.strip() for x in imglines] # load annots recs = {} for i, filename in enumerate(imagenames): imagename = filename.split('/')[-1].split('.')[-2] annofile = filename.replace('images', 'labels') annofile = annofile.replace('png', 'txt') recs[imagename] = parse_tflu(annofile) # extra gt object for this class class_recs = {} npos = 0 for i, filename in enumerate(imagenames): imagename = filename.split('/')[-1].split('.')[-2] R = [obj for obj in recs[imagename] if obj['name'] == classname] # print('R: ', R) bbox = np.array([x['bbox'] for x in R]) difficult = np.array([x['difficult'] for x in R]).astype(np.bool) det = [False] * len(R) npos = npos + sum(~difficult) # print('det: {} \t bbox: {}'.format(det, bbox)) class_recs[imagename] = {'bbox': bbox, 'difficult': difficult, 'det': det} # read dets detfile = detpath.format(classname) # print('detfile: ', detfile) with open(detfile, 'r') as f: lines = f.readlines() splitlines = [x.strip().split(' ') for x in lines] print('det image len: ', len(splitlines)) if len(splitlines)==0: return 0, 0, 0 image_ids = [x[0] for x in splitlines] confidence = np.array([float(x[1]) for x in splitlines]) BB = np.array([[float(z) for z in x[2:]] for x in splitlines]) # sort by confidence sorted_ind = np.argsort(-confidence) sorted_scores = np.sort(-confidence) BB = BB[sorted_ind, :] image_ids = [image_ids[x] for x in sorted_ind] # go down dets and mark TPs and FPs nd = len(image_ids) tp = np.zeros(nd) fp = np.zeros(nd) for d in range(nd): R = class_recs[image_ids[d]] bb = BB[d, :].astype(float) ovmax = -np.inf BBGT = R['bbox'].astype(float) # print('BBGT: ', len(BBGT)) if BBGT.size > 0: # compute overlaps # intersection ixmin = np.maximum(BBGT[:, 0], bb[0]) iymin = np.maximum(BBGT[:, 1], bb[1]) ixmax = np.minimum(BBGT[:, 2], bb[2]) iymax = np.minimum(BBGT[:, 3], bb[3]) iw = np.maximum(ixmax - ixmin + 1., 0.) ih = np.maximum(iymax - iymin + 1., 0.) inters = iw * ih # union uni = ((bb[2] - bb[0] + 1.) * (bb[3] - bb[1] + 1.) + (BBGT[:, 2] - BBGT[:, 0] + 1.) * (BBGT[:, 3] - BBGT[:, 1] + 1.) - inters) overlaps = inters / uni # print('inters: {} \t uni: {} \n'.format(inters, uni)) ovmax = np.max(overlaps) jmax = np.argmax(overlaps) # print('name: {} \n ---overlaps: {} \t ovmax: {} \t jmax: {}\n'.format(image_ids[d], overlaps, ovmax, jmax)) if ovmax > ovthresh: if not R['difficult'][jmax]: if not R['det'][jmax]: tp[d] = 1. R['det'][jmax] = 1 else: fp[d] = 1. else: fp[d] = 1. # compute precision recall # print('before npos: {}\t fp: {}\t, tp: {}'.format(npos, fp, tp)) fp = np.cumsum(fp) tp = np.cumsum(tp) # print('npos: {}\t fp: {}\t, tp: {}'.format(npos, fp, tp)) if npos>0: rec = tp / float(npos) else: print('********************************************classname: ', classname) return 0, 0, 0 # avoid divide by zero in case the first detection matches a difficult # ground truth prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps) ap = voc_ap(rec, prec, use_07_metric) return rec, prec, ap if __name__ == "__main__": path = os.getcwd() # single class detpath = os.path.join(path, '..', 'results/{}.txt') annopath = os.path.join(path, '..', 'tflu/valid.txt') datasetfile = os.path.join(path, '..', 'tflu/valid.txt') thresh = 0.5 classname = 'circle_green' use_07_metric = True recall, precision, ap = tfl_eval(detpath, annopath, datasetfile, classname, thresh, use_07_metric) # print('use_07_metric: {}\tclassname: {}\t recall:{}\t precision: {}\t ap: {}\t'.format(use_07_metric, classname, recall, precision, ap)) # multi class resultspath = os.path.join(path, '..', 'results') subfiles = os.listdir(resultspath) mAP = [] for i in range(len(subfiles)): classname = subfiles[i].split('.txt')[0] recall, precision, ap = tfl_eval(detpath, annopath, datasetfile, classname, thresh, use_07_metric) # print('classname: {}\t recall:{}\t precision: {}\t ap: {}\t'.format(classname, recall, precision, ap)) mAP.append(ap) mAP = tuple(mAP) print('AP: {}\nmAP: {}'.format(mAP, float(sum(mAP)/len(mAP)))) print('***************FalseFalse**************************************************') use_07_metric = False recall, precision, ap = tfl_eval(detpath, annopath, datasetfile, classname, thresh, use_07_metric) # print('use_07_metric: {}\tclassname: {}\t recall:{}\t precision: {}\t ap: {}\t'.format(use_07_metric, classname, recall, precision, ap)) # multi class resultspath = os.path.join(path, '..', 'results') subfiles = os.listdir(resultspath) mAP = [] for i in range(len(subfiles)): classname = subfiles[i].split('.txt')[0] recall, precision, ap = tfl_eval(detpath, annopath, datasetfile, classname, thresh, use_07_metric) # print('classname: {}\t recall:{}\t precision: {}\t ap: {}\t'.format(classname, recall, precision, ap)) mAP.append(ap) mAP = tuple(mAP) print('AP: {}\nmAP: {}'.format(mAP, float(sum(mAP)/len(mAP))))
对红绿灯的颜色进行评估
import os import numpy as np # imagesetfile = "../tflu/valid.txt" # annopath = "" # imgfile = open(imagesetfile, 'r') # lines = imgfile.readlines() # imagename = lines[0].strip() # print(imagename) # imagenames = [x.strip() for x in lines] # # annopath = '{}.xml' # # annopath.format(imagename) # # # parse_tflu_anno # annoname = imagename.replace('images', 'labels') # annoname = annoname.replace('png', 'txt') # annofile = open(annoname, 'r') # annolines = annofile.readlines() # annoline = annolines[0].strip().split(' ') # clas = tuple(map(int, annoline[0])) # bbox = tuple(map(float, annoline[1:])) # det img_w = 1280 img_h = 720 # tfl_label = {'circle_green':0, 'circle_red':1, 'circle_yellow':2, 'circle_off':3, 'left_green':4, 'left_red':5, 'left_yellow':6, 'left_off':7, 'nomotor_green':8, 'nomotor_red':9, 'nomotor_yellow':10, 'nomotor_off':11} tfl_label = ['circle_green', 'circle_red', 'circle_yellow', 'circle_off', 'left_green', 'left_red', 'left_yellow', 'left_off', 'nomotor_green', 'nomotor_red', 'nomotor_yellow', 'nomotor_off'] def parse_tflu(filename): """ Parse a TFL u txt file anno bbox: xc, yc, w, h """ objects = [] annofile = open(filename, 'r') annolines = annofile.readlines() for i, annoline in enumerate(annolines): obj_struct = {} annoline = annoline.strip().split(' ') obj_struct['name'] = tfl_label[tuple(map(int, annoline[0]))[0]] bbox = tuple(map(float, annoline[1:])) # (xc, yc, w, h) ---> (xmin, ymin, xmax, ymax) xmin = (bbox[0] - bbox[2]*0.5) * img_w xmax = (bbox[0] + bbox[2]*0.5) * img_w ymin = (bbox[1] - bbox[3]*0.5) * img_h ymax = (bbox[1] + bbox[3]*0.5) * img_h if xmin < 0: xmin = 0 if ymin < 0: ymin = 0 if xmax > img_w-1: xmax = img_w-1 if ymax > img_h-1: ymax = img_h-1 obj_struct['bbox'] = [int(xmin), int(ymin), int(xmax), int(ymax)] obj_struct['difficult'] = 0 # 0-easy, 1-difficult objects.append(obj_struct) return objects def voc_ap(rec, prec, use_07_metric=False): """ ap = voc_ap(rec, prec, [use_07_metric]) Compute VOC AP given precision and recall. If use_07_metric is true, uses the VOC 07 11 point method (default:False). """ if use_07_metric: # 11 point metric ap = 0. for t in np.arange(0., 1.1, 0.1): if np.sum(rec >= t) == 0: p = 0 else: p = np.max(prec[rec >= t]) ap = ap + p / 11. else: # correct AP calculation # first append sentinel values at the end mrec = np.concatenate(([0.], rec, [1.])) mpre = np.concatenate(([0.], prec, [0.])) # compute the precision envelope for i in range(mpre.size - 1, 0, -1): mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i]) # to calculate area under PR curve, look for points # where X axis (recall) changes value i = np.where(mrec[1:] != mrec[:-1])[0] # and sum (\Delta recall) * prec ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) return ap def tfl_eval(detpath, annopath, datasetfile, classname, ovthresh, use_07_metric=False): # print('tfl eval of class: ', classname) imgfile = open(datasetfile, 'r') imglines = imgfile.readlines() imagenames = [x.strip() for x in imglines] # load annots recs = {} for i, filename in enumerate(imagenames): imagename = filename.split('/')[-1].split('.')[-2] annofile = filename.replace('images', 'labels') annofile = annofile.replace('png', 'txt') recs[imagename] = parse_tfluisee(annofile) # extra gt object for this class class_recs = {} npos = 0 if classname=='red': subname = ['circle_red', 'left_red', 'nomotor_red'] elif classname=='green': subname = ['circle_green', 'left_green', 'nomotor_green'] elif classname=='yellow': subname = ['circle_yellow', 'left_yellow', 'nomotor_yellow'] for i, filename in enumerate(imagenames): imagename = filename.split('/')[-1].split('.')[-2] R = [obj for obj in recs[imagename] if obj['name'] in subname] # print('R: ', R) bbox = np.array([x['bbox'] for x in R]) difficult = np.array([x['difficult'] for x in R]).astype(np.bool) det = [False] * len(R) npos = npos + sum(~difficult) # print('det: {} \t bbox: {}'.format(det, bbox)) class_recs[imagename] = {'bbox': bbox, 'difficult': difficult, 'det': det} # read dets splitlines = [] for i in range(len(subname)): detfile = detpath.format(subname[i]) # print('detfile: ', detfile) with open(detfile, 'r') as f: lines = f.readlines() splitlines += [x.strip().split(' ') for x in lines] # print('det image len: ', len(splitlines)) # print('det image len all**********************: ', len(splitlines)) if len(splitlines)==0: return 0, 0, 0 image_ids = [x[0] for x in splitlines] confidence = np.array([float(x[1]) for x in splitlines]) BB = np.array([[float(z) for z in x[2:]] for x in splitlines]) # sort by confidence sorted_ind = np.argsort(-confidence) sorted_scores = np.sort(-confidence) BB = BB[sorted_ind, :] image_ids = [image_ids[x] for x in sorted_ind] # go down dets and mark TPs and FPs nd = len(image_ids) tp = np.zeros(nd) fp = np.zeros(nd) for d in range(nd): R = class_recs[image_ids[d]] bb = BB[d, :].astype(float) ovmax = -np.inf BBGT = R['bbox'].astype(float) # print('BBGT: ', len(BBGT)) if BBGT.size > 0: # compute overlaps # intersection ixmin = np.maximum(BBGT[:, 0], bb[0]) iymin = np.maximum(BBGT[:, 1], bb[1]) ixmax = np.minimum(BBGT[:, 2], bb[2]) iymax = np.minimum(BBGT[:, 3], bb[3]) iw = np.maximum(ixmax - ixmin + 1., 0.) ih = np.maximum(iymax - iymin + 1., 0.) inters = iw * ih # union uni = ((bb[2] - bb[0] + 1.) * (bb[3] - bb[1] + 1.) + (BBGT[:, 2] - BBGT[:, 0] + 1.) * (BBGT[:, 3] - BBGT[:, 1] + 1.) - inters) overlaps = inters / uni # print('inters: {} \t uni: {} \n'.format(inters, uni)) ovmax = np.max(overlaps) jmax = np.argmax(overlaps) # print('name: {} \n ---overlaps: {} \t ovmax: {} \t jmax: {}\n'.format(image_ids[d], overlaps, ovmax, jmax)) if ovmax > ovthresh: if not R['difficult'][jmax]: if not R['det'][jmax]: tp[d] = 1. R['det'][jmax] = 1 else: fp[d] = 1. else: fp[d] = 1. # compute precision recall # print('before npos: {}\t fp: {}\t, tp: {}'.format(npos, fp, tp)) fp = np.cumsum(fp) tp = np.cumsum(tp) # print('npos: {}\t fp: {}\t, tp: {}'.format(npos, fp, tp)) if npos>0: rec = tp / float(npos) else: # print('********************************************classname: ', classname) return 0, 0, 0 # avoid divide by zero in case the first detection matches a difficult # ground truth prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps) ap = voc_ap(rec, prec, use_07_metric) return rec, prec, ap if __name__ == "__main__": path = os.getcwd() # single class detpath = os.path.join(path, '..', 'results/{}.txt') annopath = os.path.join(path, '..', 'tflu/valid.txt') datasetfile = os.path.join(path, '..', 'tflu/valid.txt') thresh = 0.45 classname = 'red' use_07_metric = True print('thresh: {}\t use_07_metric: {}'.format(thresh, use_07_metric)) recall, precision, ap = tfl_eval(detpath, annopath, datasetfile, classname, thresh, use_07_metric) # print('use_07_metric: {}\tclassname: {}\t recall:{}\t precision: {}\t ap: {}\t'.format(use_07_metric, classname, recall, precision, ap)) # multi class resultspath = os.path.join(path, '..', 'results') subfiles = os.listdir(resultspath) mAP = [] color = ['red', 'green', 'yellow'] for i in range(len(color)): # classname = subfiles[i].split('.txt')[0] classname = color[i] recall, precision, ap = tfl_eval(detpath, annopath, datasetfile, classname, thresh, use_07_metric) # print('classname: {}\t recall:{}\t precision: {}\t ap: {}\t'.format(classname, recall, precision, ap)) mAP.append(ap) mAP = tuple(mAP) print('AP: {}\nmAP: {}'.format(mAP, float(sum(mAP)/len(mAP)))) # use_07_metric = False # print('thresh: {}\t use_07_metric: {}'.format(thresh, use_07_metric)) # recall, precision, ap = tfl_eval(detpath, annopath, datasetfile, classname, thresh, use_07_metric) # # print('use_07_metric: {}\tclassname: {}\t recall:{}\t precision: {}\t ap: {}\t'.format(use_07_metric, classname, recall, precision, ap)) # # # multi class # resultspath = os.path.join(path, '..', 'results') # subfiles = os.listdir(resultspath) # mAP = [] # for i in range(len(subfiles)): # classname = subfiles[i].split('.txt')[0] # recall, precision, ap = tfl_eval(detpath, annopath, datasetfile, classname, thresh, use_07_metric) # # print('classname: {}\t recall:{}\t precision: {}\t ap: {}\t'.format(classname, recall, precision, ap)) # mAP.append(ap) # mAP = tuple(mAP) # print('AP: {}\nmAP: {}'.format(mAP, float(sum(mAP)/len(mAP))))
需要更改类别相关的代码;
Interplolated AP(Pascal Voc 2008 的AP计算方式)
Area under curve
COCO mAP
update20220804 生成loss-iter曲线
./darknet detector train cfg/voc.data cfg/yolo-voc.cfg | tee training.log
python drawcurve.py training.log 0
drawcurve.py
# https://www.jianshu.com/p/7ae10c8f7d77/
# yolov3-tiny-lisa
# Learning Rate: 0.001, Momentum: 0.9, Decay: 0.0005
# Resizing
# 320
# Loaded: 0.000268 seconds
# Region 16 Avg IOU: 0.000000, Class: 0.724076, Obj: 0.605353, No Obj: 0.447358, .5R: 0.000000, .75R: 0.000000, count: 8
# Region 23 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.499357, .5R: -nan, .75R: -nan, count: 0
# 1: 223.108368, 223.108368 avg, 0.000000 rate, 0.100259 seconds, 1 images
# Loaded: 0.000114 seconds
import argparse
import sys
import matplotlib.pyplot as plt
def main(argv):
parser = argparse.ArgumentParser()
parser.add_argument("log_file", help = "path to log file" )
parser.add_argument( "option", help = "0 -> loss vs iter" )
args = parser.parse_args()
f = open(args.log_file)
lines = [line.rstrip("\n") for line in f.readlines()]
# skip the first 3 lines
lines = lines[3:]
numbers = {'1','2','3','4','5','6','7','8','9','0'}
iters = []
loss = []
for line in lines:
# print("line[0]: {}\t{}\t{}\n".format(line[0], len(line), line))
if line[0] in numbers:
args = line.split(" ")
# print("len: {}\t {}\n".format(len(args), args))
if len(args) >3:
# print("iters: {}\t loss: {}\n".format(args[0][:-1], args[2]))
iters.append(int(args[0][:-1]))
loss.append(float(args[2]))
plt.plot(iters,loss)
plt.xlabel('iters')
plt.ylabel('loss')
plt.grid()
plt.show()
if __name__ == "__main__":
main(sys.argv)
update20220810 生成iou/loss曲线
drawlog.py
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import logging
logging.basicConfig(
level=logging.DEBUG,
format='%(asctime)s %(levelname)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S'
)
logger = logging.getLogger(__name__)
class Yolov3LogVisualization:
def __init__(self, log_path, result_dir):
self.log_path = log_path
self.result_dir = result_dir
def extract_log(self, save_log_path, key_word):
with open(self.log_path, 'r') as f:
with open(save_log_path, 'w') as train_log:
next_skip = False
for line in f:
if next_skip:
next_skip = False
continue
# 去除多gpu的同步log
if 'Syncing' in line:
continue
# 去除除零错误的log
if 'nan' in line:
continue
if 'Saving weights to' in line:
next_skip = True
continue
if key_word in line:
train_log.write(line)
f.close()
train_log.close()
def parse_loss_log(self, log_path, line_num=2000):
# 用于设置忽略前多少步,上千几百的太大了,所以从几一下开始。
result = pd.read_csv(log_path,skiprows=[x for x in range(line_num) if (x<1500)],
error_bad_lines=False, names=['loss', 'avg', 'rate', 'seconds', 'images'])
result['loss'] = result['loss'].str.split(' ').str.get(1)
result['avg'] = result['avg'].str.split(' ').str.get(1)
result['rate'] = result['rate'].str.split(' ').str.get(1)
result['seconds'] = result['seconds'].str.split(' ').str.get(1)
result['images'] = result['images'].str.split(' ').str.get(1)
result['loss'] = pd.to_numeric(result['loss'])
result['avg'] = pd.to_numeric(result['avg'])
result['rate'] = pd.to_numeric(result['rate'])
result['seconds'] = pd.to_numeric(result['seconds'])
result['images'] = pd.to_numeric(result['images'])
return result
def gene_loss_pic(self, pd_loss):
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(pd_loss['avg'].values, label='avg_loss')
ax.legend(loc='best')
ax.set_title('The loss curves')
ax.set_xlabel('batches')
fig.savefig(self.result_dir + '/avg_loss')
logger.info('save iou loss done')
def loss_pic(self):
train_log_loss_path = os.path.join(self.result_dir, 'train_log_loss.txt')
self.extract_log(train_log_loss_path, 'images')
pd_loss = self.parse_loss_log(train_log_loss_path)
self.gene_loss_pic(pd_loss)
def parse_iou_log(self, log_path, line_num=2000):
result = pd.read_csv(log_path, skiprows=[x for x in range(line_num) if (x % 10 == 0 or x % 10 == 9)],
error_bad_lines=False,
names=['Region Avg IOU', 'Class', 'Obj', 'No Obj', 'Avg Recall', 'count'])
result['Region Avg IOU'] = result['Region Avg IOU'].str.split(': ').str.get(1)
result['Class'] = result['Class'].str.split(': ').str.get(1)
result['Obj'] = result['Obj'].str.split(': ').str.get(1)
result['No Obj'] = result['No Obj'].str.split(': ').str.get(1)
result['Avg Recall'] = result['Avg Recall'].str.split(': ').str.get(1)
result['count'] = result['count'].str.split(': ').str.get(1)
result['Region Avg IOU'] = pd.to_numeric(result['Region Avg IOU'])
result['Class'] = pd.to_numeric(result['Class'])
result['Obj'] = pd.to_numeric(result['Obj'])
result['No Obj'] = pd.to_numeric(result['No Obj'])
result['Avg Recall'] = pd.to_numeric(result['Avg Recall'])
result['count'] = pd.to_numeric(result['count'])
return result
def gene_iou_pic(self, pd_loss):
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(pd_loss['Region Avg IOU'].values, label='Region Avg IOU')
# ax.plot(result['Class'].values,label='Class')
# ax.plot(result['Obj'].values,label='Obj')
# ax.plot(result['No Obj'].values,label='No Obj')
# ax.plot(result['Avg Recall'].values,label='Avg Recall')
# ax.plot(result['count'].values,label='count')
ax.legend(loc='best')
ax.set_title('The Region Avg IOU curves')
ax.set_xlabel('batches')
fig.savefig(self.result_dir + '/region_avg_iou')
logger.info('save iou pic done')
def iou_pic(self):
train_log_loss_path = os.path.join(self.result_dir, 'train_log_iou.txt')
self.extract_log(train_log_loss_path, 'IOU')
pd_loss = self.parse_iou_log(train_log_loss_path)
self.gene_iou_pic(pd_loss)
if __name__ == '__main__':
log_path = '../train_tfl0808.txt'
result_dir = '../log_analysis'
logVis = Yolov3LogVisualization(log_path, result_dir)
logVis.loss_pic()
logVis.iou_pic()
结果如下:
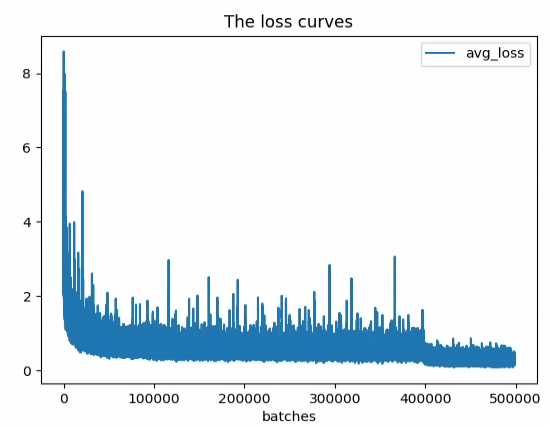
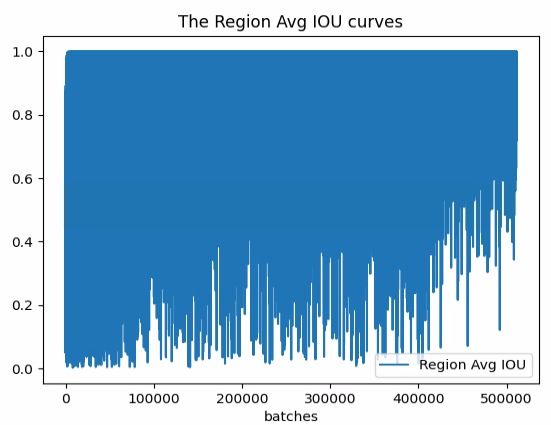
如图所示,avg_loss一直在下降,avg_iou也在逐渐接近于1.
参考
2. 深度学习中的AP和mAP总结;
4. 目标检测中的AP,mAP;
5. voc_eval;
7. Ubuntu16.04下实现darknet-yolov3训练自己的数据(含loss图、mAP计算);
完
心正意诚,做自己该做的事情,做自己喜欢做的事情,安静做一枚有思想的技术媛。
版权声明,转载请注明出处:https://www.cnblogs.com/happyamyhope/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号