

MySQL索引以及InnoDB
二叉树
当数据是自增的时候,二叉树会跟链表没有区别
平衡二叉树
它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。这个方案很好的解决了二叉查找树退化成链表的问题,把插入,查找,删除的时间复杂度最好情况和最坏情况都维持在O(logN)。但是频繁旋转会使插入和删除牺牲掉O(logN)左右的时间,不过相对二叉查找树来说,时间上稳定了很多。、
红黑数
红黑树放弃了追求完全平衡,追求大致平衡,在与平衡二叉树的时间复杂度相差不大的情况下,保证每次插入最多只需要三次旋转就能达到平衡,实现起来也更为简单。
优点:不会出现二叉树的极端情况,当两边深度差距太大会选择,维持相对平衡
缺点:当数据量太大的时候,索引的层级会非常深,假设需要查找的数据在叶子节点,进行的I/O会过多,非常影响性能
B-Tree(平衡多路查找树)
B-Tree是为磁盘等外存储设备设计的一种平衡查找树,非叶子节点也会存储数据
系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位的,位于同一个磁盘块中的数据会被一次性读取出来,而不是需要什么取什么。
InnoDB存储引擎中有页(Page)的概念,页是其磁盘管理的最小单位。InnoDB存储引擎中默认每个页的大小为16KB,可通过参数innodb_page_size将页的大小设置为4K、8K、16K,在MySQL中可通过如下命令查看页的大小:
mysql> show variables like 'innodb_page_size';
而系统一个磁盘块的存储空间往往没有这么大,因此InnoDB每次申请磁盘空间时都会是若干地址连续磁盘块来达到页的大小16KB。InnoDB在把磁盘数据读入到磁盘时会以页为基本单位,在查询数据时如果一个页中的每条数据都能有助于定位数据记录的位置,这将会减少磁盘I/O次数,提高查询效率。
B+Tree
是B-Tree的变种,非叶子节点不存储数据,数据存储在叶子节点,同时叶子节点存储全部数据,且叶子节点相互储存左右叶子节点的地址(便于范围查找)
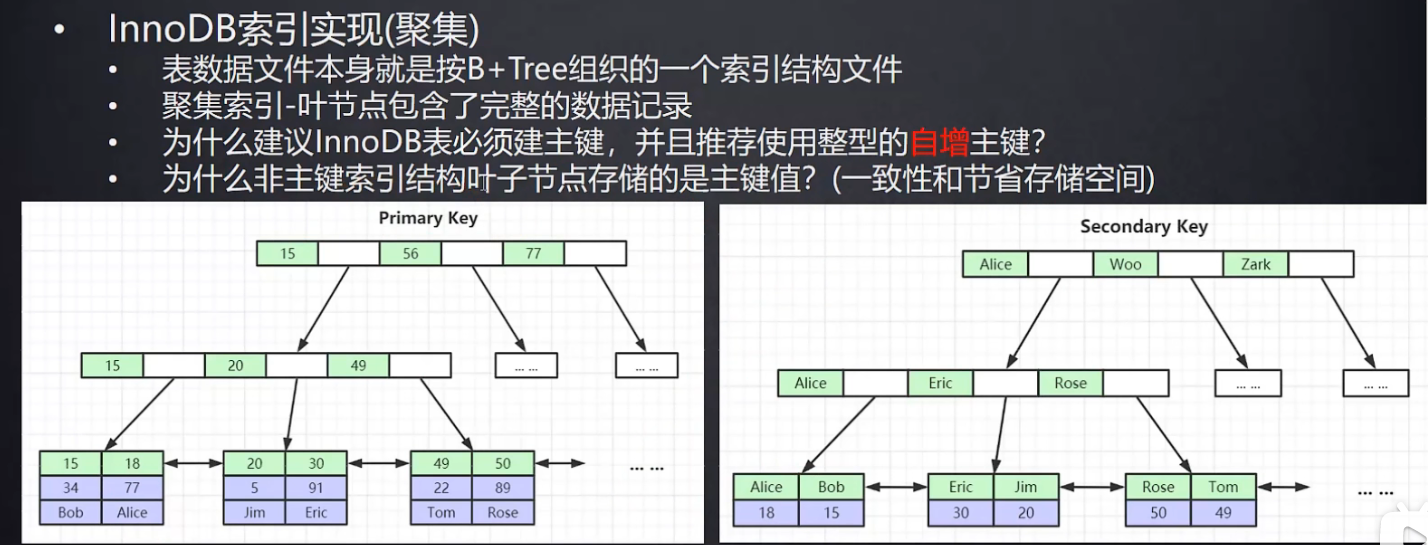
索引
需要注意的点
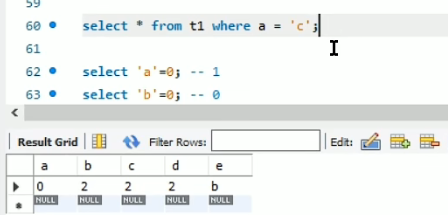
对于“=”两边类型不一致的问题,会将字符转换为“0”,如果是纯数字类的字符,直接转换为对应的数字即可
关于聚集索引和非聚集索引
聚集索引是指索引结构的叶子节点包含了数据的索引,也叫一级索引
非聚集索引的叶子节点不包含数据,而是包含该列所对应的聚集索引对应的值,所以如果需要使用到索引查询该索引字段的话,就不需要回表查询,否则会回表查询
需要注意的是,如果对字段进行了操作的话,就不会走索引了
InnoDB和MyISAM的区别
InnoDB支持事务,同时也支持外键,InnoDB的主键是聚集索引
InnoDB不保存表的具体行数,进行count(*)时,需要进行全表扫描,MyISAM专门有变量存储了表的行数
InnoDB最小的锁粒度是行级锁,MyISAM是表级锁,因此InnoDB的并发性要远远优于MyISAM
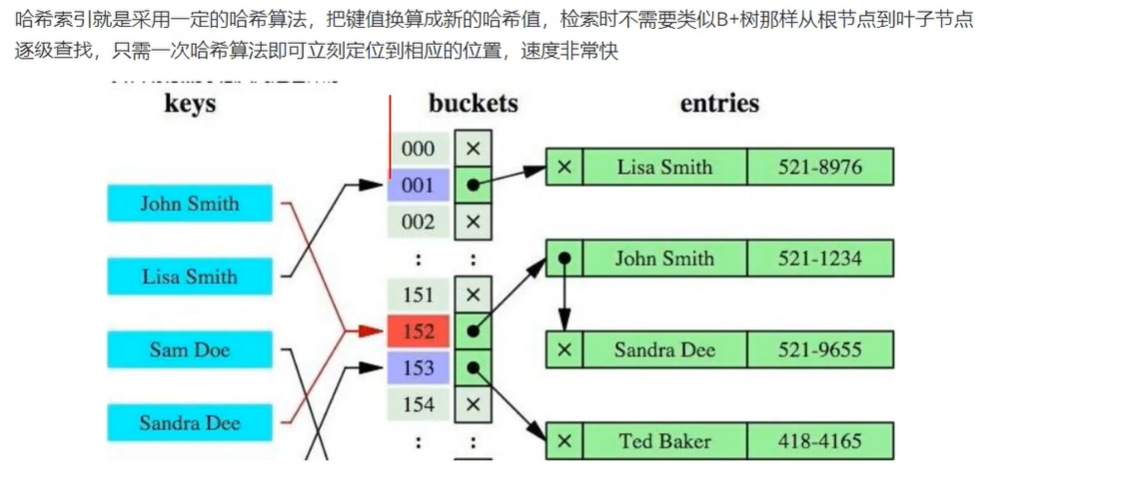
关于hash索引
如果进行等值查询的话,hash索引无疑具有绝对的优势,在不出现hash冲突的情况下,只需要进行一次计算,便可以找到数据
但因为这个特性,所以hash所以没有办法进行范围查询
关于唯一索引
指建立在Unique字段上的数据,一张表可以有多个唯一索引
唯一索引可以为空,而且出现多个空值不会冲突
关于普通索引
指建立在普通字段上的索引
关于前缀索引
指对字符类型字段的前几个字符或者对二进制类型字段的前几个bytes建立的索引,注意,不是整个字段
可以建立的类型为char,varchar,binary,varbinary的列上
可以大大减少索引占用的存储空间,也能够提升效率
但是不能做order by以及group by
.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号