Java语言中容易搞错的细节
java switch语句支持的类型
Incompatible types. Found: 'long', required: 'char, byte, short, int, Character, Byte, Short, Integer, String, or an enum'
这是switch接收long 参数的编译报错,从提示可以看出,switch只支持“char, byte, short, int, Character, Byte, Short, Integer, String, or an enum”
finalize是干嘛的?调用了就能表示对象被回收了吗?
finalize 是在 java.lang.Object 里定义的方法,也就是说每一个对象都有这么个方法,这个方法在 gc 启动,表示该对象可能被回收。
一个对象的 finalize 方法只会被调用一次,finalize 被调用不一定会立即回收该对象,所以有可能调用 finalize 后,该对象又不需要被回收了,然后到了真正要被回收的时候,因为前面调用过一次,所以不会再次调用 finalize 了,进而产生问题,因此不推荐使用 finalize 方法。
==和 equals 的区别
本质上,== 是运算符,而equals是方法,二者根本没有可比性;
不过从逻辑上,二者又相似之处; == 比较的是两个对象地址是否相等,也就是是否是同一个对象;equals默认实现和== 一致,但是如果子类override了此方法,则多数情况下就是指内容是否相等。
hashCode()的默认值是什么?为什么重写equals也必须重写hashCode
对象的内存地址 通过hash 函数转化后得到的一个整数。
逻辑上来说,相等的对象,hashCode一定相等;如果重写了equals,两个不同的对象内容相等,我们认为相等,equals返回true,但原始的hashCode却是不等的,逻辑错误。
String str1 = new String("abc")和 String str2 = "abc" 和 区别?
- 相同点:均会在常量池中查找是否有"abc"这个字符串,如果有,则都直接使用;如果没有则创建新的。
- 不同点:
String str2 = "abc" 在常量池无"abc"时创建对象,并将引用赋值给str2;
new String("abc") 会额外堆中创建一个新的对象"abc".
java 的异常体系
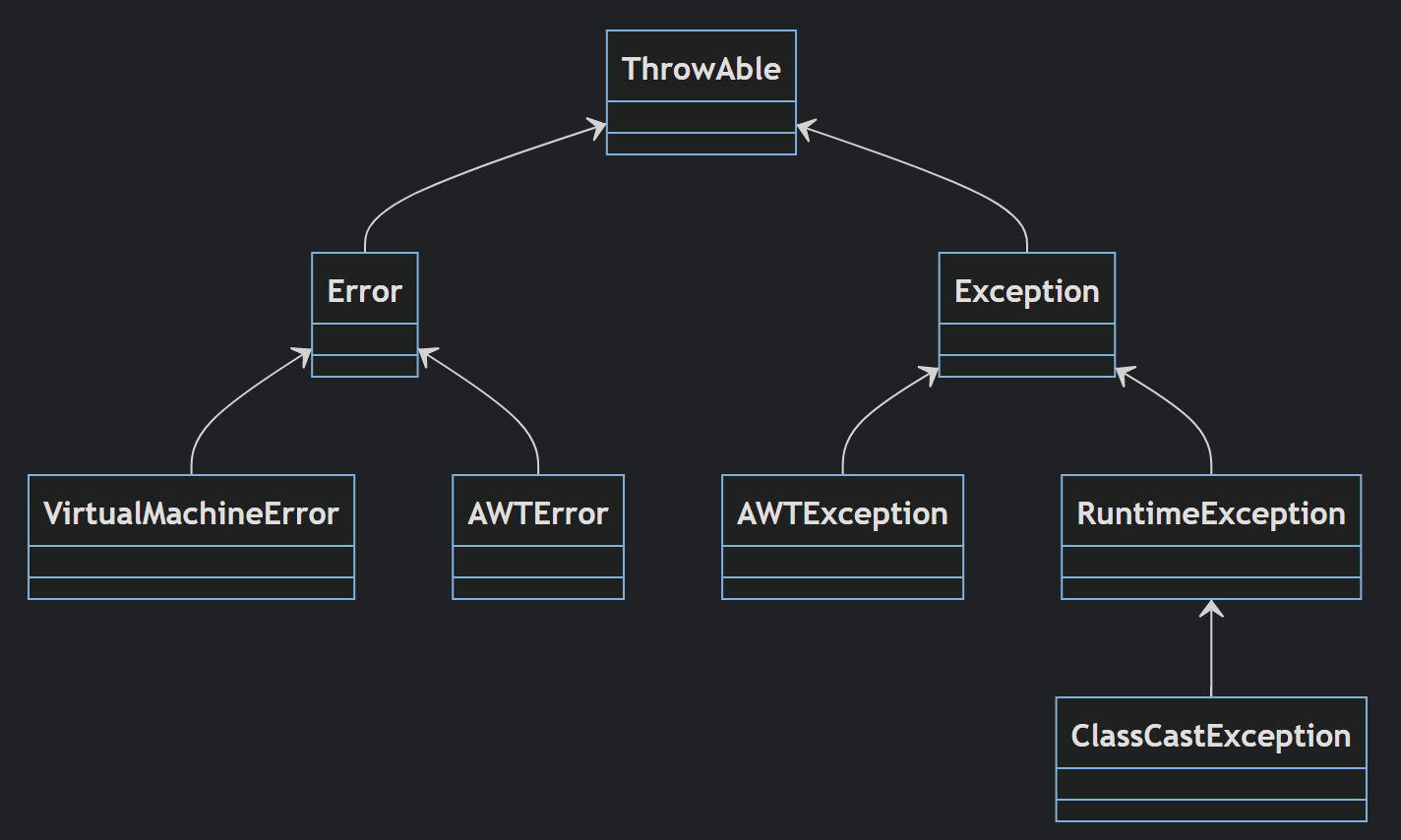
整体来说,Java的异常基类为Throwable,总的分为两类: Error和Exception。
Exception 是程序逻辑错误引起的异常,JVM自己抛的;
而Error是JVM内部的错误,是进程的异常,java程序没法处理。
java try catch 能够捕获异步跨线程的异常吗?
举个例子
点击查看代码
public static void test() {
try {
Logger.i("run outside: " + Thread.currentThread().getId());
new Thread(()->{
Logger.i("run in child: " + Thread.currentThread().getId());
throw new RuntimeException("this is from child");
}).start();
} catch (Exception e){
Logger.i("run in catch: " + Thread.currentThread().getId());
e.printStackTrace();
}
}
run in child: 16
Exception in thread "Thread-0" java.lang.RuntimeException: this is from child
at com.company.exception.TryCatchAsyncThreadExp.lambda$test$0(TryCatchAsyncThreadExp.java:13)
at java.base/java.lang.Thread.run(Thread.java:831)
finally 经典题目
public static int test1() {
try {
return 2;
} finally {
return 3;
}
}
// test1 输出 3
//------------------------------
private static int innerTryFinally() {
try {
return 1;
} catch (Exception e) {
return 2;
} finally {
System.out.print("3");
}
}
// innerTryFinally 先输出3,再返回1
//-----------------------------------------------------
public static int test2() {
int i = 0;
try {
i = 2;
return i;
} finally {
i = 3;
}
}
// test2 返回2, 可能有人会问了,finally不是会把i改掉吗?
//但是,再返回之前,返回值是i的一个副本,所以还是 返回2
先输出3,再返回1.
因为finally 会在return之前执行。
函数式接口和lambda表达式
所谓的函数式接口是指只有一个虚拟方法的接口,只有函数式接口才能使用lambda表达式替代,
public class LambdaTest {
public static void test() {
// 也可以(int a, int b)-> {}
IFun fun = (a, b)-> {
Logger.i(" this is a fun parms: " + a +", " + b);
};
fun.show(3, 4);
}
/**
* 只有一个虚拟方法的接口,被称为函数式接口
* 典型的使用就是lambda表达式
*/
@FunctionalInterface
interface IFun {
void show(int a, int b);
// 可以有非虚拟方法
default void test(){
}
}
}
好处是让代码更加简洁了。这一点个人感觉参考了C++
c的函数指针也是类似思想,提高了程序设计的扩展性。
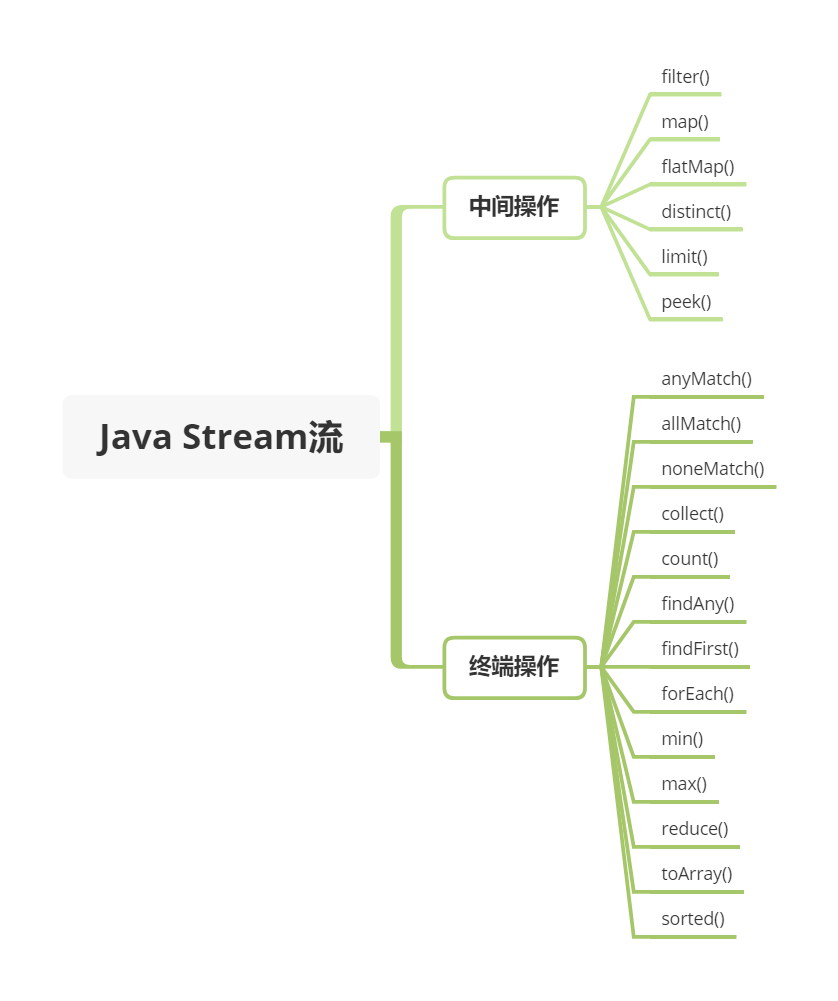
stream 的使用
常用于集合的处理,详情自己百度
集合类的关系
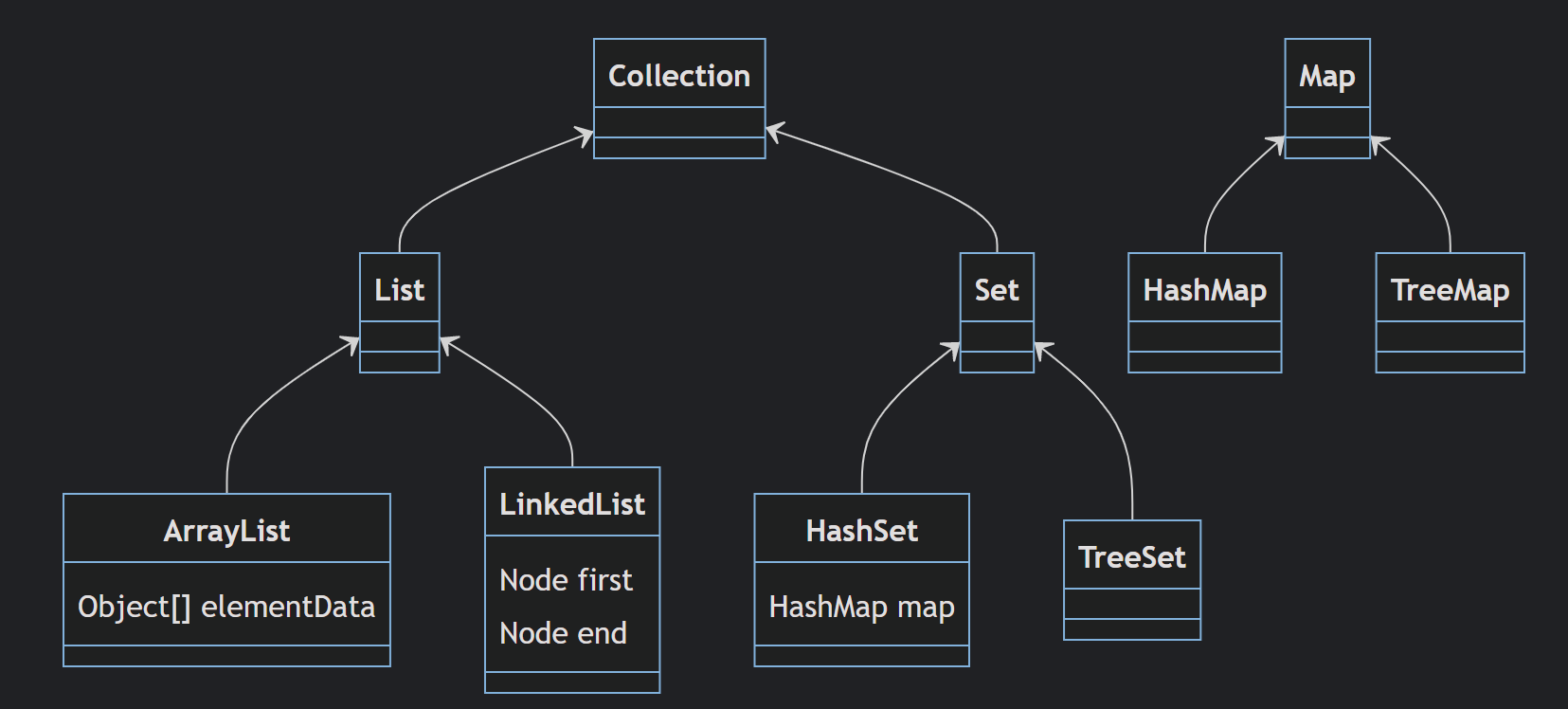
有意思的是HashSet的实现,其实是对HashMap的特殊封装,更多细节自己看源码。
-
List 是线性表这一数据结构 的抽象,其具体实现分为 数组和链表,本质区别是元素在内存中的相对关系,而由于存储上的差异,导致查、增、删等操作在两类实现上的性能差异较大。
-
Set 对应数学中的集合,特点是元素不重复。
-
Map 可以理解为字典,根据一个key,查找对应的value。key不能重复
-
ArrayList的扩容: 如果新增一个元素就超限了,就新创建一个当前容量*1.5大小的数组,并将旧的数据copy到新数组,释放老数组。
ArrayList不能直接序列化?ArrayList怎么序列化?
由于ArrayList的数组空间总有未被使用的部分,如果直接序列化,会很浪费,实际上也是没必要的,所以ArrayList 使用了transient关键字修饰 transient Object[] elementData;
让被修饰的成员不被序列化。
那么要如何序列化ArrayList的元素呢?
可以使用ObjectOutputStream和ObjectInputStream来进行序列化和反序列化,不过二者需要配合起来。
比如先write size,再循环stream.writeObject(elementData[i]);
fast-fail 和safe fail
- fast-fail, 位于java.util中的集合类
在用迭代器遍历一个集合对象时,如果线程A遍历过程中,线程B对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。 - safe-fail,位于java.util.concurrent中
采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。
不会触发Concurrent Modification Exception。
代表类:CopyOnWriteArrayList,ConcurrentHashMap
HashMap
HashMap的底层实现原理: 数组 + 链表 + 红黑树。
其实就是一个数组: transient Node<K,V>[] table; 元素为Node,而Node 有一个next成员,从而可以形成一个链表,链表按照一定规则又可以形成二叉树,这都是数据结构中的知识点,与具体语言无关。
所谓的Hash,是指插入数据时,会先对key进行hash计算,得到hashTable数组中的下标,如果正好此位置空缺,则直接插入;如果冲突则在该点后面形成链表,如果链表数大于等于8,则该链表转换为红黑树进行存储,提高访问效率。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
.......
}
下面是插入元素的实现代码。
点击查看代码
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
LinkedHashMap的有序性
LinkedHashMap维护了一个双向链表,有头尾节点,同时 LinkedHashMap 节点 Entry 内部除了继承 HashMap 的 Node 属性,还有 before 和 after 用于标识前置节点和后置节点。
在遍历的时候,就是根据head和tail这两个成员变量表示的两条双向链表实现 顺序访问的
点击查看keysToArray 和valuesToArray代码
@Override
final <T> T[] keysToArray(T[] a) {
Object[] r = a;
int idx = 0;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) {
r[idx++] = e.key;
}
return a;
}
@Override
final <T> T[] valuesToArray(T[] a) {
Object[] r = a;
int idx = 0;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) {
r[idx++] = e.value;
}
return a;
}
点击查看afterNodeAccess代码
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号