

一次 OOM 的问题
背景:
最近在做服务作业的时候,突然发现机器的 dump 文件在暴增,1小时的执行下来,应用 _dump.log.* 文件达到了惊人的 20 个,其中每个dump 文件都是900mb 的文件,还在不断增多,还有一个 应用_dump.log 的文件也达到了 900mb ,所以赶紧紧急 kill 掉该 机器,分析问题。
解决:
1. 重现场景
因为该业务是在封测环境进行,所以这里我找了台连接封测 DB 和 封测配置中心的机器作为测试环境。
2. 查看 TOP

在任务的执行过程中,属于cpu 密集型的,趋于正常状态

3.查看 jvm gc 情况
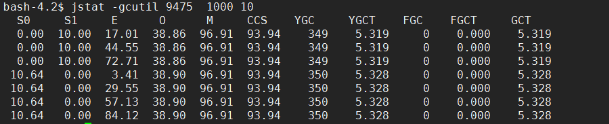
目前来看是正常的。
4.在任务结束后查看

从图可以看出 YGCT/YGC = 0.012 还是ok 的。
FGCT/FGC = 0.39 还不错 都没有超过 1秒。
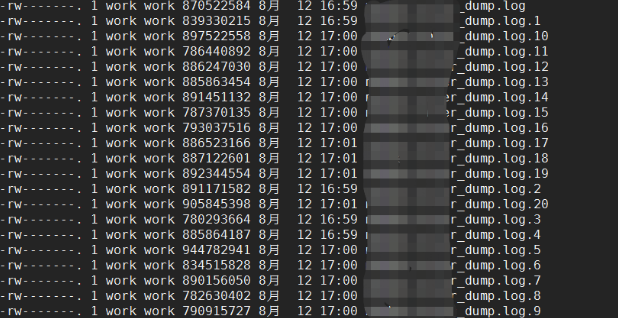
5.查看dump 文件
在任务执行的时候 dump 还正常,但是在任务结束后,出现了 这么多 dump 文件,明显出现了问题,初步怀疑是 OOM 异常,所以这里我把 某个dump 文件拉下来进行分析。
6.分析 dump
使用 jdk 自带的 jvisualvm 进行分析

从图中 我们可以看出 char[] 竟然达到了惊人的占比 80.8%的文件大小,我们继续看
可以看出前面几个实例的占用空间很大,达到了602m。而这个 dump 文件总共才 800m 找到原因了,我们就来看代码
(注,打码的部分是输出的 log 日志,可以从这里找到相关提示)
7.查看代码

其中上面的提示是这行报出的,而这个 tuple2 则是我们的一个 fork / join 计算结果得出。

在 这个计算中,List
这个 List
本来没有什么的,但是因为我们之前的 封测机器多了几台实例,然后我们把这个实例的 -Xmx -Xms 都调整成了 1000m。所以会导致了 OOM。
8. 解决
找到了问题后,我们就可以解决他了,一方面,代码中我们返回更加有用的信息,另一方面就是申请新机器,然后把 -Xmx -Xms 调大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号