
【集合】3.Set与Map
1. Set基本介绍
- Set接口是Collection接口的子接口。
- Set集合中元素时无序的(添加和取出顺序不一致,LinkedHashSet、TreeSet除外),没有索引。
- 不允许添加重复元素,最多包含一个null。
2. 常用方法
常用方法和Collection接口一样。
3. HashSet源码分析
3.1 HashSet介绍
-
HashSet实际上是HashMap。HashMap底层是[数组 + 链表 + 红黑树]。
-
HashSet的元素存在HashMap的Key中,Value中存放的是一个Object对象。
// Dummy value to associate with an Object in the backing Map private static final Object PRESENT = new Object(); -
HashSet不保证元素时有序的,取决于hash后,再确定索引的结果。
3.2 源码分析
3.2.1 构造方法
构造HashSet对象时,底层构造了一个HashMap对象。
public HashSet() {
map = new HashMap<>();
}
调用无参构造创建HashMap时,加载因子(loadFactor)默认为0.75。加载因子决定了何时扩容,如0.75含义是当元素超过了数组大小的3/4时就扩容。
final float loadFactor;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
3.2.2 添加及扩容机制
-
第一次添加时,table数组扩容到16,临界值(threshold)是16*加载因子(loadFactor 0.75)=12。
float ft = (float)newCap * loadFactor; -
添加一个元素时,先得到hash值,以hash值作为数组的索引定位到存储的位置。
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } // 计算hash static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } -
找到存储数据表table,看这个索引位置是否已经存放元素。
-
如果没有,直接加入。
-
如果有,调用equals比较。如果相同,就放弃添加,跳到下一个元素。如果不相同,则添加到最后。
-
在Java8中,如果一条链表的元素个数达到TREEIFY_THRESHOLD(默认8),并且table大小>=MIN_TREEIFY_CAPACITY(默认64),就会进行树化,转为红黑树。
static final int TREEIFY_THRESHOLD = 8; static final int MIN_TREEIFY_CAPACITY = 64; // 添加 final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; // 定义辅助变量 // table是HashMap的一个数组,类型是Node[] // 如果table为空或者大小为0则说明是第一次扩容 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // 根据hash值计算key应该存放到table表的哪个索引位置, // 并将这个位置的对象赋值给p,判断p是否为null if ((p = tab[i = (n - 1) & hash]) == null) // p为null说明没有存放元素,创建一个新的Node存放到该位置 tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; // 辅助变量 // 如果当前索引位置对应的链表的第一个元素和准备添加的key的hash值一样, // 并且满足两个条件之一: // (1)准备加入的key和p指向Node节点的key是同一个对象 // (2)准备加入的key不为空,但和p指向Node节点的key相同 // 就不能加入 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // 再判断p是不是一颗红黑树,如果是就调用putTreeVal进行添加 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { // 依次和该链表的每一个元素比较后,都不相同,则加入到该链表的最后 for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); // 把元素加入到链表后立即判断该链表是否达到8个节点, // 达到就调用treeifyBin()对当前链表进行树化,转成红黑树 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } // 如果有相同情况,直接break if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; } // 树化 final void treeifyBin(Node<K,V>[] tab, int hash) { int n, index; Node<K,V> e; // 如果table大小没有达到64只会扩容,达到64后才会树化 if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); else if ((e = tab[index = (n - 1) & hash]) != null) { TreeNode<K,V> hd = null, tl = null; do { TreeNode<K,V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null); if ((tab[index] = hd) != null) hd.treeify(tab); } } -
table表是以2倍方式扩容。
// 该语句在源码中位于resize方法的一个if条件中 newCap = oldCap << 1; // ... Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab;
4. LinkedHashSet源码分析
4.1 LinkHashSet介绍
- LinkedHashSet是HashSet的子类。
- LinkedHashSet底层是一个LinkedHashMap,Map底层又维护了[数组 + 双向链表]。
- LinkedHashSet根据元素的hashCode值类决定元素的存储位置,同时使用链表维护元素的次序,这使得元素看起来是以插入顺序保存的。
- LinkedHashSet不允许添加重复元素。
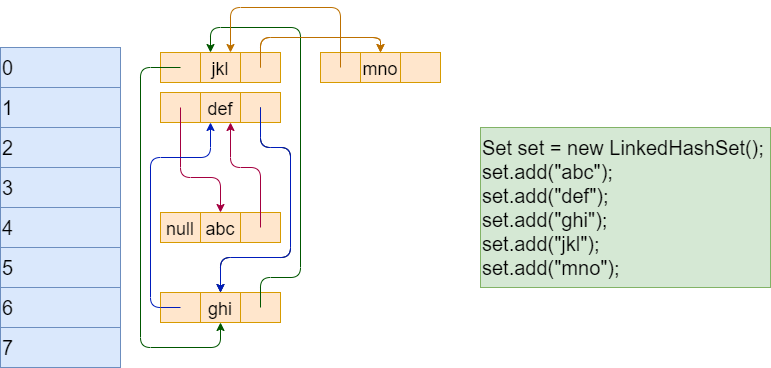
4.2 源码分析
4.2.1 构造方法
构建LinkedHashSet对象时,底层构造了一个LinkedHashMap对象。
public LinkedHashSet() {
super(16, .75f, true);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
4.2.2 添加机制
LinkedHashMap继承了HashMap,仅仅是把newNode方法重写。新建一个节点并把这个节点挂在链表尾部。
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
5. TreeSet源码分析
5.1 TreeSet介绍
- TreeSet底层是一个TreeMap。
- TreeMap可以指定规则对元素进行排序。
- 使用TreeSet是存储的元素必须实现Comparable接口,或者创建TreeSet时传入一个Comparator构造器对象。
5.2 源码分析
5.2.1构造方法
创建TreeSet对象时,底层创建了一个TreeMap对象。
public TreeSet() {
this(new TreeMap<E,Object>());
}
创建TreeSet对象时,可以指定一个Comparator比较器对象,添加元素时按照指定规则排序。
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
private final Comparator<? super K> comparator;
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
5.2.2 添加机制
-
调用add方法添加,底层调用了map的put方法,以待加元素作为key,Object对象作为value存入map中
private static final Object PRESENT = new Object(); public boolean add(E e) { return m.put(e, PRESENT)==null; } -
TreeMap的put方法在添加元素时,会判断comparator字段是否为空也就是在创建对象时有没有传入一个比较器,如果有就使用传入的比较器对元素进行排序,如果没有则使用元素实现的Comparable接口。
public V put(K key, V value) { Entry<K,V> t = root; if (t == null) { compare(key, key); // type (and possibly null) check root = new Entry<>(key, value, null); size = 1; modCount++; return null; } int cmp; Entry<K,V> parent; // 如果含有比较器对象Comparator就是用比较器对象比较 // 如果没有就使用元素实现的Comparable接口 Comparator<? super K> cpr = comparator; if (cpr != null) { do { parent = t; cmp = cpr.compare(key, t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } else { if (key == null) throw new NullPointerException(); @SuppressWarnings("unchecked") Comparable<? super K> k = (Comparable<? super K>) key; do { parent = t; cmp = k.compareTo(t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } Entry<K,V> e = new Entry<>(key, value, parent); if (cmp < 0) parent.left = e; else parent.right = e; fixAfterInsertion(e); size++; modCount++; return null; } -
如果既没有传入比较器Comparator,元素也没有实现Comparable接口,添加元素时会抛出ClassCastException类转换异常。
java.lang.ClassCastException: Demo$1A cannot be cast to java.lang.Comparable at java.util.TreeMap.compare(TreeMap.java:1294) at java.util.TreeMap.put(TreeMap.java:538) at java.util.TreeSet.add(TreeSet.java:255)
6. 集合实现类的选择
在开发中,选择什么集合实现类,主要取决于业务操作特点,然后根据集合实现类特性进行选择。
- 先判断存储的类型,是一组对象(单列)还是一组键值对(双列)。
- 一组对象(单列):Collection接口
- 允许重复:List
- 增删多:LinkedList,底层维护了一个双向链表。
- 改查多:ArrayList,底层维护了一个Object类型的可变数组。
- 不允许重复:Set
- 无序:HashSet,底层是HashMap,维护了一个哈希表(数组+链表+红黑树)。
- 排序:TreeSet,底层是TreeMap,使用Comparator或Comparable进行比较排序。
- 插入和取出的顺序一致:LinkedHashSet,底层维护了数组+双向链表。
- 允许重复:List
- 一组键值对(双列):Map接口
- 键无序:HashMap,底层是哈希表,JDK7是[数组+链表],JDK8是[数组+链表+红黑树]。
- 键排序:TreeMap。
- 键插入和取出顺序一致:LinkedHashMap。
- 读取文件:Properties

 浙公网安备 33010602011771号
浙公网安备 33010602011771号