

Django-haystack对接elasticsearch
如果直接在Django项目直接编写代码作为ElasticSearch的客户端,比较复杂,所以借助第三方包Haystack来对接ELasticSearch的客户端。而且使用了Haystack后,以后你换其他的全文搜索服务器时,也不用修改Django项目已经写好的代码。
elasticsearch工作原理
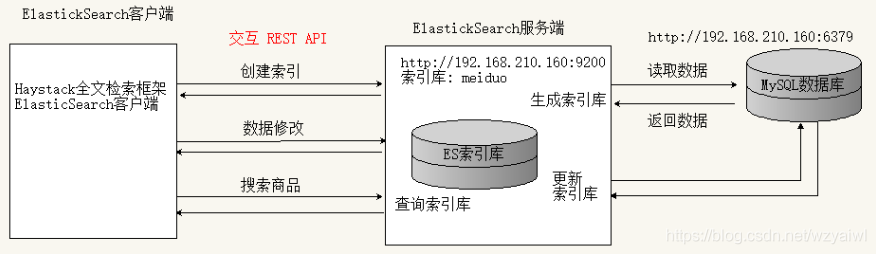
前期准备
- 安装elasticsearch,参考https://blog.csdn.net/wzyaiwl/article/details/89713055
- 安装django-haystack,pip install django-haystack
- 安装elasticsearch,pip install elasticsearch
项目配置
在settings配置如下:
#注册app INSTALLED_APPS = [ 'haystack', ] ELASTICSEARCH_DSL = { 'default': { 'hosts': '127.0.0.1:8002' }, } #配置haystack全文检索框架 HAYSTACK_CONNECTIONS = { 'default': { 'ENGINE': 'haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine', 'URL': 'http://127.0.0.1:8002/', # 此处为elasticsearch运行的服务器ip地址,端口号默认为9200 'INDEX_NAME': 'dj_pre_class', # 指定elasticsearch建立的索引库的名称 }, } # 设置每页显示的数据量 HAYSTACK_SEARCH_RESULTS_PER_PAGE = 5 # 当数据库改变时,会自动更新索引 HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
构建索引
1、在app下新建一个search_indexes.py文件,在这个文件下写索引类。这个索引类的目的是指明哪些字段用来构造索引,哪些字段用来查询返回。以下面代码为例:
from haystack import indexes from .models import News class NewsIndex(indexes.SearchIndex, indexes.Indexable): # text表示被查询的字段,用户搜索的是这些字段的值,具体被索引的字段写在另一个文件里。 text = indexes.CharField(document=True, use_template=True) id = indexes.IntegerField(model_attr='id') title = indexes.CharField(model_attr='title') digest = indexes.CharField(model_attr='digest') content = indexes.CharField(model_attr='content') image_url = indexes.CharField(model_attr='image_url') # comments = indexes.IntegerField(model_attr='comments') def get_model(self): """返回建立索引的模型类 """ return News def index_queryset(self, using=None): """返回要建立索引的数据查询集 """ return self.get_model().objects.filter(is_delete=False, tag_id=1)
- 类名必须为需要检索的Model_name+Index
- 每个索引里面必须有且只能有一个字段为 document=True,这代表haystack 和搜索引擎将使用此字段的内容作为索引进行检索(primary field)。其他的字段只是附属的属性,方便调用,并不作为检索数据。
- 如果使用一个字段设置了
document=True,则一般约定此字段名为text,这是在SearchIndex类里面一贯的命名,以防止后台混乱,当然名字你也可以随便改,不过不建议改。 haystack提供了use_template=True在text字段,这样就允许我们使用数据模板去建立搜索引擎索引的文件,说得通俗点就是索引里面需要存放一些什么东西- text字段用于构造索引,只不过具体构造索引的值写在另一个文件内。
- id、title、digest、content、image_url用于以索引查询到的返回内容。
- get_model方法用于指明建立索引的对应模型。
- index_queryset方法用于返回建立索引的数据查询集。
2、构造具体索引值
在template\search\indexes\app_name\model_name_text.txt下构造索引值,这个路径是固定的。如果不按照这个路径的话,就在text字段内使用template_name 参数,指定模板文件。
-
{{ object.title }}
-
{{ object.digest }}
-
{{ object.content }}
上述代码说明用字段title、digest、content来作为索引的方向。
3、生成索引
到项目目录下,执行代码python manage.py rebuild_index即可。
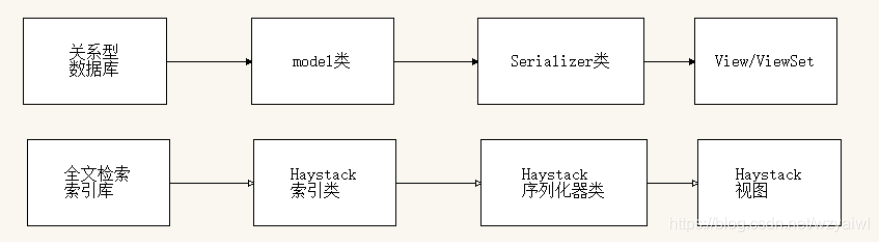
构建视图
1、到view文件内构造对应搜索功能的视图
导包from haystack.views import SearchView as _SearchView。
class SearchView(_SearchView): # 模版文件 template = 'news/search.html' # 重写响应方式,如果请求参数q为空,返回模型News的热门新闻数据,否则根据参数q搜索相关数据 def create_response(self): kw = self.request.GET.get('q', '') if not kw: # 如果没有索引值,就全部搜索出来 show_all = True hot_news = models.HotNews.objects.select_related('news').only('news__title', 'news__image_url', 'news__id').filter(is_delete=False).order_by('priority', '-news__clicks') paginator = Paginator(hot_news, settings.HAYSTACK_SEARCH_RESULTS_PER_PAGE) try: page = paginator.page(int(self.request.GET.get('page', 1))) except PageNotAnInteger: # 如果参数page的数据类型不是整型,则返回第一页数据 page = paginator.page(1) except EmptyPage: # 用户访问的页数大于实际页数,则返回最后一页的数据 page = paginator.page(paginator.num_pages) return render(self.request, self.template, locals()) else: show_all = False qs = super(SearchView, self).create_response() return qs
2、配置对应路由
几点补述
- haystack 默认是有几个变量的,这几个变量存在context 的,最终前端接受的数据都在context字典里,所以如果我们定义自己的变量的话,也需要加载context里,即通过重写extra_context方法。
- query 是我们搜索的关键字,form 一般不用,我们可以自己用表单的get提交方式模拟,但是表单的id必须是q。可以打断点,在self.query中查看我们的搜索关键字。
- create_response 方法可以自定义我们的响应体,里面帮我们实现了分页功能,我们可以在settings中设置分页的数量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号