
YOLO系列,标签平滑—— 分类问题中错误标注的一种解决方法
转载:https://blog.csdn.net/qq_38253797/article/details/116228065
【trick 1】Label Smoothing(标签平滑)—— 分类问题中错误标注的一种解决方法
目录
一、提出背景
二、Label Smoothing 原理
三、Label Smoothing 在YOLO中的应用
label smoothing是一种在 分类/检测 问题中,防止过拟合的方法。
一、提出背景
交叉熵(Cross-Entropy)损失函数是分类模型中的一种非常重要的目标函数。在二分类问题中,交叉熵损失函数的形式如下:

如果分类准确,交叉熵损失函数的结果是0(即上式中p和y一致的情况),否则交叉熵为无穷大。也就是说交叉熵对分类正确给的是最大激励。
不太理解交叉熵(Cross-Entropy)损失函数的可以看看我的另一篇关于交叉熵损失函数的博文: 交叉熵损失函数.
对于标注数据来说,这个时候我们认为其标注结果是准确的(不然这个结果就没意义了)。但实际上,有一些标注数据并不一定是准确的。那么这时候,使用交叉熵损失函数作为目标函数并不一定是最优的。
也可以这么理解: 在分类任务中,我们通常对类别标签的编码使用[0,1,2,…]这种形式。在深度学习中,通常在全连接层的最后一层,加入一个softmax来计算输入数据属于每个类别的概率,并把概率最高的作为这个类别的输入,然后使用交叉熵作为损失函数。这会导致模型对正确分类的情况奖励最大,错误分类惩罚最大。如果训练数据能覆盖所有情况,或者是完全正确,那么这种方式没有问题。但事实上,这不可能。所以这种方式可能会带来泛化能力差的问题,即过拟合。
用下面的 label smoothing 可以缓解这个问题。
二、Label Smoothing 原理
原理: 假设我们的分类只有两个,一个是猫一个不是猫,分别用1和0表示。Label Smoothing的工作原理是对原来的[0 1]这种标注做一个改动,假设我们给定Label Smoothing的平滑参数为0.1:
[ 0 , 1 ] × ( 1 − 0.1 ) + 0.1 / 2 = [ 0.05 , 0.95 ] [0,1]×(1−0.1)+0.1/2=[0.05,0.95]
[0,1]×(1−0.1)+0.1/2=[0.05,0.95]
可以看到,原来的[0,1]标签成了[ 0.05 , 0.95 ] 了,那么就是说,原来分类准确的时候,p = 1 ,不准确为p = 0。假设为Label Smoothing的平滑参数为ϵ \epsilon,现在变成了: 分类准确的时候 p = 1 − 0.5 ∗ ϵ , 分类不准确时 p = 0.5 ∗ ϵ ,也就是说对分类准确做了一点惩罚。
这实际上是一种正则化策略,减少了真实样本标签的类别在计算损失函数时的权重,最终起到抑制过拟合的效果。
下图为使用Label Smoothing的概率分布图:
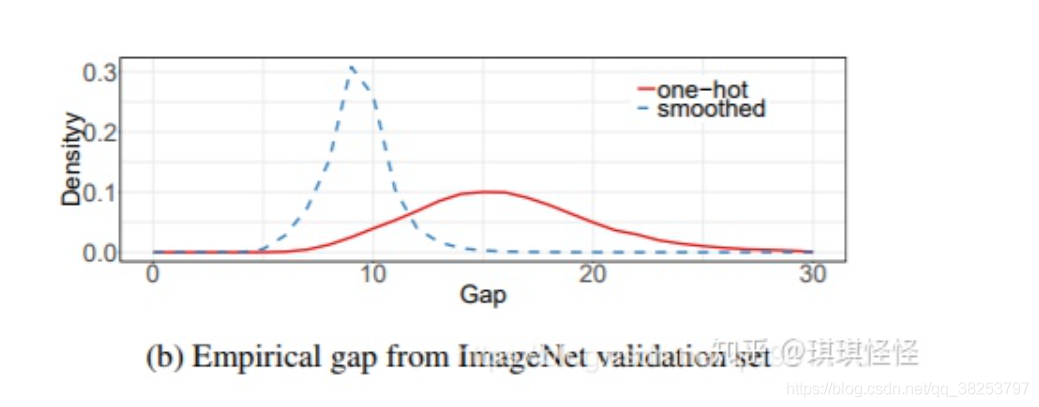
三、Label Smoothing 在YOLO中的应用
# # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
# # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441 def smooth_BCE(eps=0.1): # eps 平滑系数 [0, 1] => [0.95, 0.05] # return positive, negative label smoothing BCE targets # positive label= y_true * (1.0 - label_smoothing) + 0.5 * label_smoothing # y_true=1 label_smoothing=eps=0.1 return 1.0 - 0.5 * eps, 0.5 * eps
————————————————
版权声明:本文为CSDN博主「满船清梦压星河HK」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_38253797/article/details/116228065
posted on 2022-12-20 10:12 Sanny.Liu-CV&&ML 阅读(1134) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号