
Adaptive Training Sample Selection (ATSS)
转载:https://zhuanlan.zhihu.com/p/120652249
《Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection》这篇论文最近挺火,CVPR2020的oral
原文链接:https://arxiv.org/abs/1912.02424
造成anchor-free和anchor-based检测方法性能差异的原因究竟是什么呢?作者通过严格的实验发现,如何定义正负训练样本是原因所在,而不是回归的状态或anchor的数量。进而,作者提出了一种自适应训练样本的选择方法(Adaptive Training Sample Selection, ATSS ),训练时根据目标的统计特性自适应地挑选正、负样本。作者将主要贡献概括为以下四点:
1. 说明anchor-free和anchor-based检测器之间的本质区别是如何定义正负训练样本;
2. 提出了一种自适应的训练样本选择方法,根据对象的统计特性自动选择正负训练样本;
3. 说明在图像上每个位置平铺多个anchor来检测目标是无用的操作;
4. 在不增加任何额外开销的情况下,在MS-COCO上实现最先进的性能
Related Work
anchor-free的检测器消除了有关于anchor的超参数,同时实现了与anchor-based检测器相似的性能,就泛化性能而言可能更具潜力。Center-based method其实与Anchor-based Detector很相似,不过是将预设样本由anchor boxes变成了points。以RetinaNet和FCOS作例,它们两者存在三点主要差别:(1)每个位置平铺的anchor数量:RetinaNet在每个位置平铺多个anchor,而FCOS在每个位置平铺一个anchor point;(2)正负样本的定义方式:RetinaNet借助IoU区分正负样本,而FCOS利用空间和幅度限制选择正负样本;(3)回归起始状态:RetinaNet从anchor box回归边界框,而FCOS由anchor point定位边界框。作者通过实验分别考察这三点,最终发现(2)是问题核心所在,(1)和(3)无关痛痒。
Difference Analysis of Anchor-based and Anchor-free Detection
以RetinaNet和FCOS作例,作者首先评估差别(2)、(3)。在RetinaNet中,每个位置仅平铺一个正方形的锚框(因为FCOS在每个位置仅平铺一个anchor point),尺寸为8*S(S是下采样总倍数),作者将这个模型称为RetinaNet (#A=1)。作者全部实验均在MS COCO上完成,实验细节循常例,感兴趣的读者可以查阅论文3.1节。
RetinaNet (#A=1)在MS COCO minival subset上实现32.5%AP,FCOS实现37.8%AP。仔细分析发现,FCOS的性能提升可能来自以下几点:添加GN、使用GIoU回归损失函数、限制gt box的正样本数量、在回归分支加入中心性信息、为每个层级特征金字塔添加可训练标量。其实这些tricks也可以用在anchor-based detectors中,为了消除不一致性、更公平的分析,作者这么做了,实验结果如下:
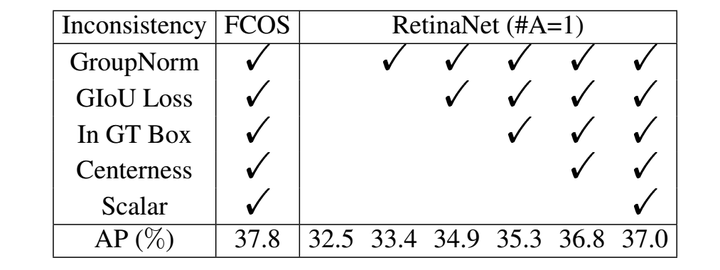
加入上述tricks,RetinaNet (#A=1)的AP提升到37.0%,虽然和FCOS的37.8%还有0.8%的差距,但由于消除了所有的不相关差别,接下来可以公平地探索两者之间的本质区别。到如今,the anchor-based RetinaNet (#A=1) 和 the anchor-free FCOS之间仅存在两点差异:一个是关于分类子任务,即定义正样本和负样本的方法(2);另一个是关于回归子任务,即从锚框还是锚点开始回归(3)。
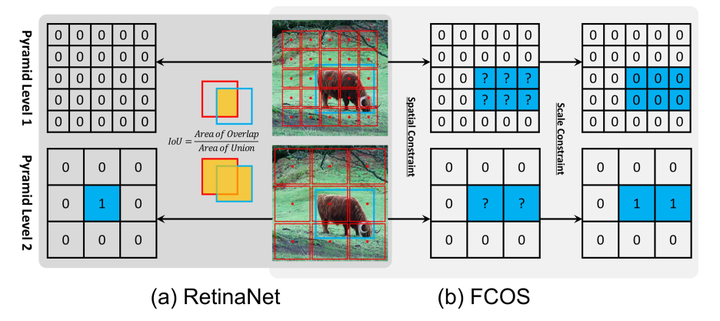
如上图所示。RetinaNet借助IoU将anchor boxes划分为正、负样本。如果anchor box和gt box的IoU大于阈值 则视为正样本,如果小于阈值
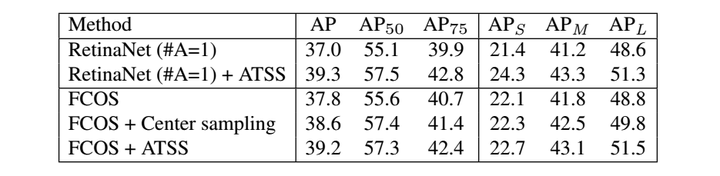
则视为负样本,否则忽略。FCOS利用空间和幅度限制选择正负样本。所有gt box内部的点都作为候选正样本点,然后根据为每个金字塔层级定义的幅度范围从候选对象中选择最终的正样本点,未被选择的点均是负样本点。这两种不同的选择策略会产生不同的正负样本。实验结果如下表,在RetinaNet (#A=1)将IoU策略替换为spatial and scale constraint策略,AP由37.0%提高到37.8%;在FCOS将spatial and scale constraint策略替换为IoU策略,AP由37.8%降低到36.9%。这些结果表明,正样本和负样本的定义是anchor-based和anchor-free检测器的本质区别。
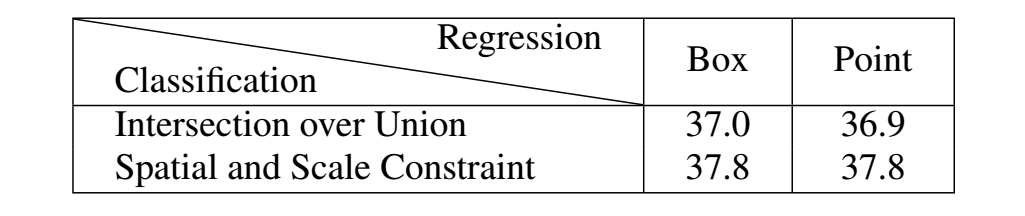
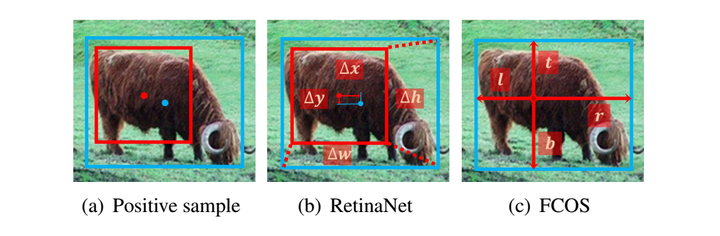
如下图所示。RetinaNe回归anchor box与object box之间的四个偏移量,而FCOS回归anchor point到object box四条边之间的距离。也就是说,RetinaNet从anchor box回归边界框,而FCOS由anchor point定位边界框。实验结果如上表,当RetinaNet和FCOS采用相同的样本选择策略得到一致的正、负样本时,无论是从anchor point还是anchor box开始回归,最终的表现都没有明显的差异(即37:0% vs 36:9% 和 37:8% vs 37:8%)。这些结果表明回归开始状态是一个不相关的区别。
Adaptive Training Sample Selection(ATSS)
训练目标检测模型时,我们首先会定义正、负样本来进行分类,然后使用正样本来进行回归。先前的样本选择策略都有敏感的超参数,比如IoU的阈值、幅度限制的具体范围,不同的超参数设置导致不同的选择结果,而且这两种样本选择策略基于古板的准则。作者提出一种自适应的正负样本选择方法,简称为ATSS,它根据目标的统计数据自适应地选择正、负样本,几乎没有超参数。ATSS流程如Algorithm 1所示。对于每个gt box ,在每个层级的金字塔上挑选
个anchor boxes(它们的中心点与
的中心点间的L2距离最小)组成候选正样本,假设共有
个金字塔层级,则会挑选出
个候选正样本。之后,计算这些候选正样本与
之间的IoU
,并计算
的均值
和标准差
,设置IoU阈值为
。最后,从候选正样本中挑选IoU大于等于
并且样本中心点落在gt box
中的样本作为最终的正样本。其余为负样本。如果一个anchor被分配给多个gt box,那么将选择IoU最高的一个。

ATSS的设计考虑到了以下几个方面:
- 基于anchor box和object box的中心距离挑选候选正样本;
- 使用均值和标准差的和作为IoU阈值;
- 限制正样本的中心点必须在目标框内;
- 在不同目标之间维持公平性(几乎不受目标尺寸、宽高比、位置的影响);
- 几乎没有额外超参数(唯一的超参数
是鲁棒的,所以可以认为ATSS是almost hyperparameter-free)。
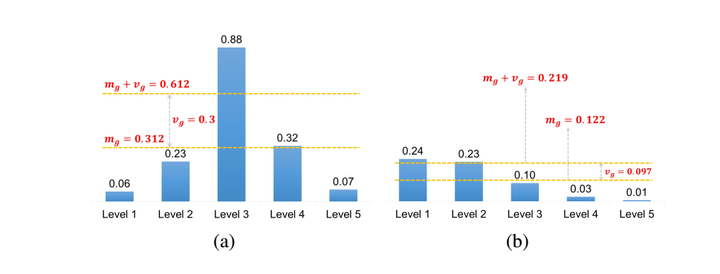
上述第二点的优势由下图反映。均值是一个相对稳定的量,高的均值意味着高质量的候选框。标准差判定某层级是否适合与当前目标的检测。下图(a)中,均值+标准差指出level3更适合当前目标的预测,同理在下图(b)中,均值+标准差指出level1和level2都适合当前目标的预测。以均值和标准差之和作为IoU阈值,可以根据对象的统计特征,自适应地从适当的金字塔层级中为每个目标选择足够的正样本。
实验验证ATSS的效果,如下表。ATSS带来的性能提升是明显的。
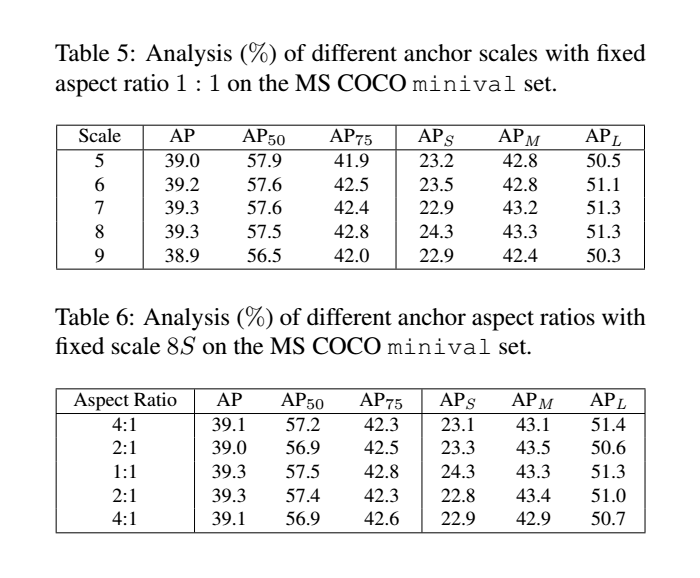
关于超参数 的选择:其在3-19之间变化,实验结果如下表。可以看到,
在7-17之间是鲁棒的,
太小时(e.g., 3)候选样本点太少,统计特性不稳定,
太大时(e.g., 19)候选样本点太多,包含太多低质量的候选样本。结果说明ATSS对不同的
具有较强的鲁棒性。

另外,作者还进行了anchor size的相关实验,实验结果如下表。在之前的实验中,每个位置平铺一个8S的方形anchor(S表示总下采样步长)。作者换用不同幅度[5;6;7;8;9]的方形anchor进行试验,性能稳定。此外,作者还进行了不同长宽比的anchor试验,性能依旧稳定。结果说明ATSS对不同的anchor的设置具有较强的鲁棒性。
作者在MS COCO test-dev set上与大量检测模型进行比较,感兴趣的读者可以参见论文。ATSS的最终性能如下表。
 指标分别为:AP AP50 AP75 APs APm APl
指标分别为:AP AP50 AP75 APs APm APl
Discussion
之前我们提到,以RetinaNet和FCOS作例,它们两者存在三点主要差别,在“anchor-free和anchor-based检测模型差异分析”中作者评估了差别(2)、(3),在这里作者讨论差别(1)。
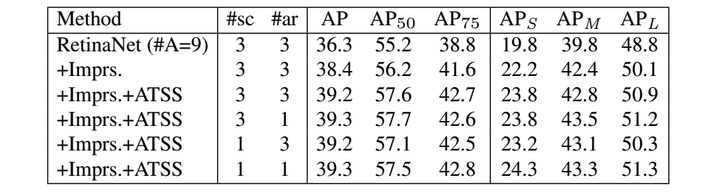
原始的RetinaNet在每个位置平铺9个anchors(3 scales × 3 aspect ratios),实现了36.3%的AP,辅之以之前提到的tricks,AP提高到38.4%。不加入ATSS时,RetinaNet (#A=9) 比RetinaNet (#A=1)性能更好一些(i.e., 38.4% vs 37.0%),这说明传统的基于IoU的样本选择策略里,增加anchor的数量是有效的。使用ATSS之后,RetinaNet (#A=9) 的AP进一步提升0.8%。值得注意的是,当作者将anchor的尺度或长宽比从3更改为1时,结果几乎不变。换言之,只要正确选择正样本,无论在每个位置平铺多少anchor,结果都是相同的。在ATSS下,每个位置使用多个anchor是无用的操作。
Conclusion
在这项工作中,作者指出一阶anchor-based 和 center-based anchor-free检测器的本质区别实际上是正、负训练样本的定义。在目标检测训练过程中如何选择正、负样本是关键。受此启发,作者深入研究了这一基本问题,提出了自适应训练样本选择方法,根据对象的统计特性自动划分正、负训练样本,从而弥合了anchor-based 和 center-based anchor-free检测模型之间的性能差距。作者还讨论了每个位置平铺多个anchor的必要性,并表明使用ATSS时,这是一个无用的操作。在MS-COCO上的大量实验表明,ATSS可以在不增加额外开销的情况下实现SOTA的性能。
posted on 2020-11-23 23:10 Sanny.Liu-CV&&ML 阅读(400) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号