
转载:从loss处理图像分割中类别极度不均衡,正负样本不均衡的状况---keras
转载:医学类图像分割的各种loss优化与对比:https://blog.csdn.net/m0_37477175/article/details/83004746 https://blog.csdn.net/wangdongwei0/article/details/84576044 *****
医学图像分割Dice loss:https://zhuanlan.zhihu.com/p/86704421 https://www.aiuai.cn/aifarm1159.html
前言
最近在做小目标图像分割任务(医疗方向),往往一幅图像中只有一个或者两个目标,而且目标的像素比例比较小,使网络训练较为困难,一般可能有三种的解决方式:
选择合适的loss function,对网络进行合理的优化,关注较小的目标。
改变网络结构,使用attention机制(类别判断作为辅助)。
与2的根本原理一致,类属attention,即:先检测目标区域,裁剪之后进行分割训练。
通过使用设计合理的loss function,相比于另两种方式更加简单易行,能够保留图像所有信息的情况下进行网络优化,达到对小目标精确分割的目的。
场景
- 使用U-Net作为基准网络。
- 实现使用keras
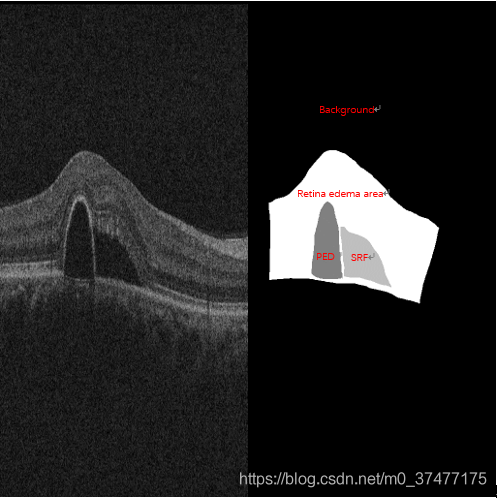
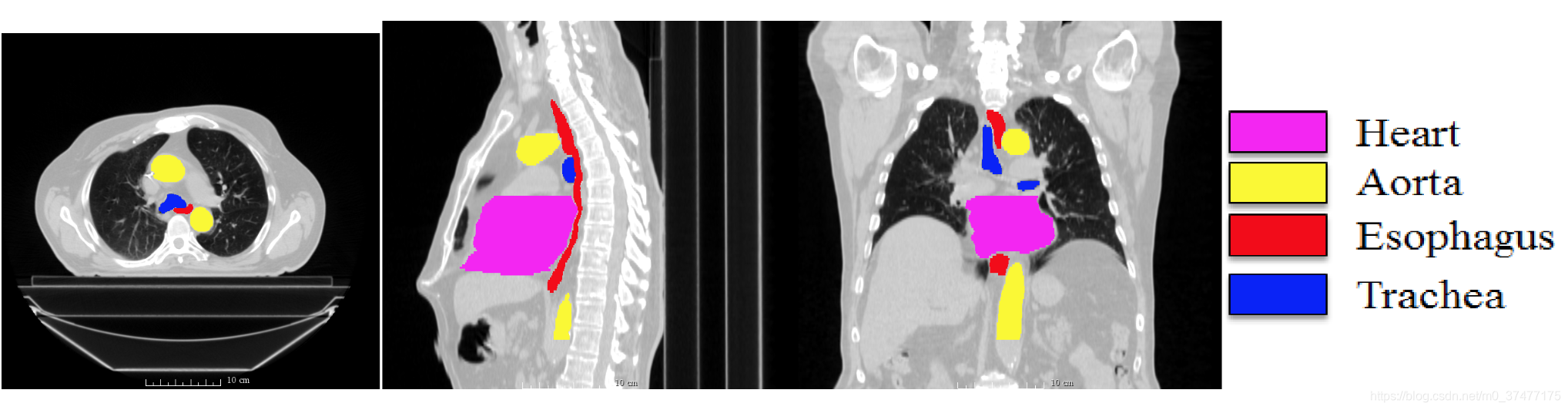
- 小目标图像分割场景,如下图举例。
AI Challenger眼底水肿病变区域自动分割,背景占据了很大的一部分![在这里插入图片描述]()
segthor医疗影像器官分割![在这里插入图片描述]()
loss function

log loss其实就是TensorFlow中的 tf.losses.sigmoid_cross_entropy 或者Keras的 keras.losses.binary_crossentropy(y_true, y_pred)
其中: ,
乍看上去难以理解loss函数的意义,也就是说不明白为什么这个函数可以当做损失函数。
其实我们可以对上面的公式进行拆分:
第一行:当y=1 ,为前景时,越大就与y越接近,即预测越准确,loss越小;
第二行:当y=0 ,为背景时,越小就与y越接近,即预测越准确,loss越小;
最终的loss是y=0和y=1两种类别的loss相加,这种方法有一个明显缺点,当正样本数量远远小于负样本的数量时,即y=0的数量远大于y=1的数量,loss函数中y=0的成分就会占据主导,使得模型严重偏向背景。
所以对于背景远远大于目标的分割任务,Log loss效果非常不好。

三、Focal Loss
大名鼎鼎的focal loss,先看它是如何改进的:注意下面这个可不是完整的Focal Loss
其中gamma>0
在Focal Loss中,它更关心难分类样本,不太关心易分类样本,比如:
若 gamma = 2,
对于正类样本来说,如果预测结果为0.97那么肯定是易分类的样本,所以就会很小;
对于正类样本来说,如果预测结果为0.3的肯定是难分类的样本,所以就会很大;
对于负类样本来说,如果预测结果为0.8那么肯定是难分类的样本,就会很大;
对于负类样本来说,如果预测结果为0.1那么肯定是易分类的样本,就会很小。
另外,Focal Loss还引入了平衡因子alpha,用来平衡正负样本本身的比例不均,完整的Focal Loss如下:

alpha取值范围0~1,当alpha>0.5时,可以相对增加y=1所占的比例。实现正负样本的平衡。
虽然何凯明的试验中,lambda为2是最优的,但是不代表这个参数适合其他样本,在应用中还需要根据实际情况调整这两个参数。
下面是lambda对应的loss下降曲线情况:
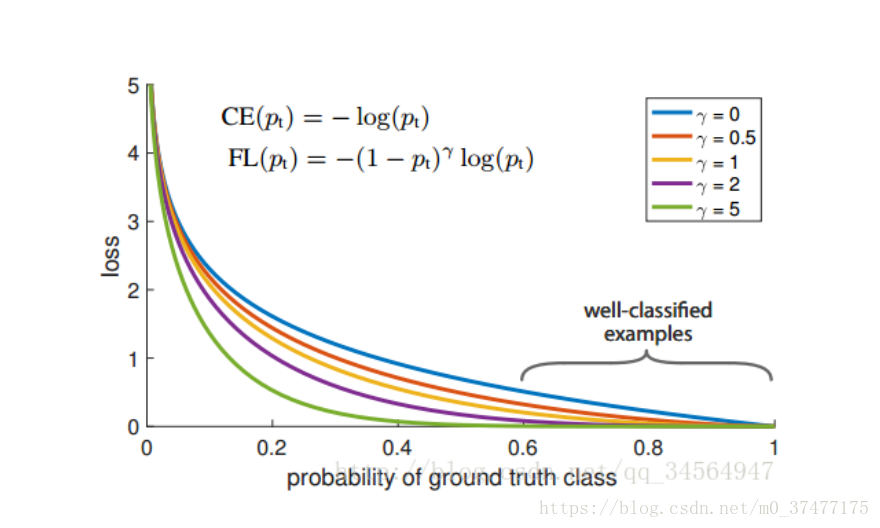
对比binary_crossentropy要好很多。目前在图像分割上只是适应于二分类。
代码:https://github.com/mkocabas/focal-loss-keras
from keras import backend as K
'''
Compatible with tensorflow backend
'''
def focal_loss(gamma=2., alpha=.25):
def focal_loss_fixed(y_true, y_pred):
pt_1 = tf.where(tf.equal(y_true, 1), y_pred, tf.ones_like(y_pred))
pt_0 = tf.where(tf.equal(y_true, 0), y_pred, tf.zeros_like(y_pred))
return -K.sum(alpha * K.pow(1. - pt_1, gamma) * K.log(pt_1))-K.sum((1-alpha) * K.pow( pt_0, gamma) * K.log(1. - pt_0))
return focal_loss_fixed
使用方法:model_prn.compile(optimizer=optimizer, loss=[focal_loss(alpha=.25, gamma=2)])
-K.mean(alpha * K.pow(1. - pt_1, gamma) * K.log(pt_1)) - K.mean((1 - alpha) * K.pow(pt_0, gamma) * K.log(1. - pt_0))

上面的loss也是一个用于学习目标的loss,一个用于屏蔽背景的loss。当为前景时,r 为1,主要时看第二项有助于模型倾loss向于目标学习,当真实区域为背景时,r 为0,主要看第三项有助于模型对背景目标的屏蔽。因为使用的是交并比,所有和目标大小关系不打,能够重点关注的即使目标很小的区域。训练的时候,dice loss 比较适用于正负样本极度不均的情况,一般的情况下,使用 dice loss 会对反向传播造成不利的影响,容易使训练变得不稳定。
Laplace smoothing 是一个可选改动,即将分子分母全部加 1:
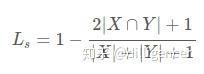
带来的好处:
(1)避免当|X|和|Y|都为0时,分子被0除的问题
(2)减少过拟合
Dice 系数计算
首先将 |X∩Y| 近似为预测图pred和label GT 之间的点乘,并将点乘的元素的结果相加:
(1)预测分割图与 GT 分割图的点乘:
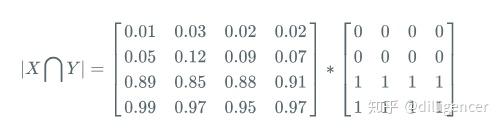
(2)逐元素相乘的结果元素的相加和:
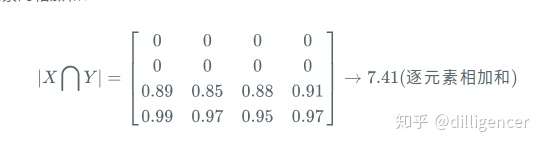
对于二分类问题,GT分割图是只有0,1两个值的,因此 |X∩Y| 可以有效的将在 Pred 分割图中未在 GT 分割图中激活的所有像素清零. 对于激活的像素,主要是惩罚低置信度的预测,较高值会得到更好的 Dice 系数.
(3)计算|X|和|Y|,这里可以采用直接元素相加,也可以采用元素平方求和的方法:
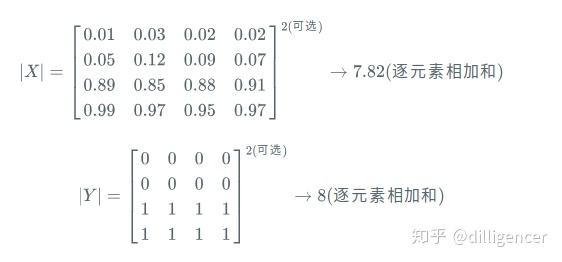
实际应用中,需要将各个loss相结合使用:
4、Focal Loss + DICE LOSS
Focal Loss 和 Dice Loss的结合需要注意把两者缩放至相同的数量级,使用-log放大Dice Loss,使用alpha缩小Focal Loss:
def mixedLoss(y_ture,y_pred,alpha):
return alpha * focal_loss(y_ture,y_pred) - K.log(diceA_loss(y_true,y_pred))
5.BCE + DICE LOSS
def bce_logdice_loss(y_true, y_pred):
return binary_crossentropy(y_true, y_pred) - K.log(1. - dice_loss(y_true, y_pred))
6、WEIGHTED BCE LOSS
相比dice loss增加了参数 weight,包含w1和w2,分别与y_pred和y_true相乘
def weighted_dice_loss(y_true, y_pred, weight):
smooth = 1.
w, m1, m2 = weight, y_true, y_pred
intersection = (m1 * m2)
score = (2. * K.sum(w * intersection) + smooth) / (K.sum(w * m1) + K.sum(w * m2) + smooth)
loss = 1. - K.sum(score)
return loss
7、WEIGHTED BCE DICE LOSS
def weighted_bce_dice_loss(y_true, y_pred):
y_true = K.cast(y_true, 'float32')
y_pred = K.cast(y_pred, 'float32')
# if we want to get same size of output, kernel size must be odd
averaged_mask = K.pool2d(
y_true, pool_size=(50, 50), strides=(1, 1), padding='same', pool_mode='avg')
weight = K.ones_like(averaged_mask)
w0 = K.sum(weight)
weight = 5. * K.exp(-5. * K.abs(averaged_mask - 0.5))
w1 = K.sum(weight)
weight *= (w0 / w1)
loss = weighted_bce_loss(y_true, y_pred, weight) + dice_loss(y_true, y_pred)
8、 Mean IOU
mean IOU字面理解就是平均的IOU,不过计算时需要设置多个阈值(0.5, 1.0, 0.05),是指在阈值范围内分别计算IOU,取均值。
def mean_iou(y_true, y_pred):
prec = []
for t in np.arange(0.5, 1.0, 0.05):
y_pred_ = tf.to_int32(y_pred > t)
score, up_opt = tf.metrics.mean_iou(y_true, y_pred_, 2)
K.get_session().run(tf.local_variables_initializer())
with tf.control_dependencies([up_opt]):
score = tf.identity(score)
prec.append(score)
return K.mean(K.stack(prec), axis=0)
补充:
一般在分割模型中我们有时会用intersection over union去衡量模型的表现,按照IOU的定义,比如对predicted instance和actual instance的IOU大于0.5算一个positive,在这个基础上再做一些F1,F2之类其他的更宏观的metric。
所以如果能优化IOU就能提高分数啦,那么怎么优化呢?
一般直接使用BCE去训练,但是优化BCE并不等于优化IOU,可以参考 http://cn.arxiv.org/pdf/1705.08790v2,直观上来说一个minibatch中的没有pixel的权重其实是不一样的。两张图片,一张正样本有1000个pixels,另一张只有4个,那么第二张1个pixel带来的IOU得损失就能顶的上第一张中250pixel的损失。
如果直接使用IOU作为Loss Function,也不是最好的,因为训练过程是不稳定的。一个模型从坏到好,我们希望监督它的loss的过渡是平滑的。
所以推荐使用Lovasz-Softmax loss,效果不错,github上有源码
posted on 2020-07-01 00:54 Sanny.Liu-CV&&ML 阅读(3512) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号