
模型压缩-Learning Efficient Convolutional Networks through Network Slimming
Zhuang Liu主页:https://liuzhuang13.github.io/
Learning Efficient Convolutional Networks through Network Slimming: https://arxiv.org/pdf/1708.06519.pdf
后续出了:Rethinking the Value of Network Pruning (Pytorch) (ICLR 2019),https://github.com/Eric-mingjie/rethinking-network-pruning/
转载:https://zhuanlan.zhihu.com/p/39761855 https://blog.csdn.net/u011995719/article/details/78788336
核心思想(利用BN放缩因子来修剪Channel)
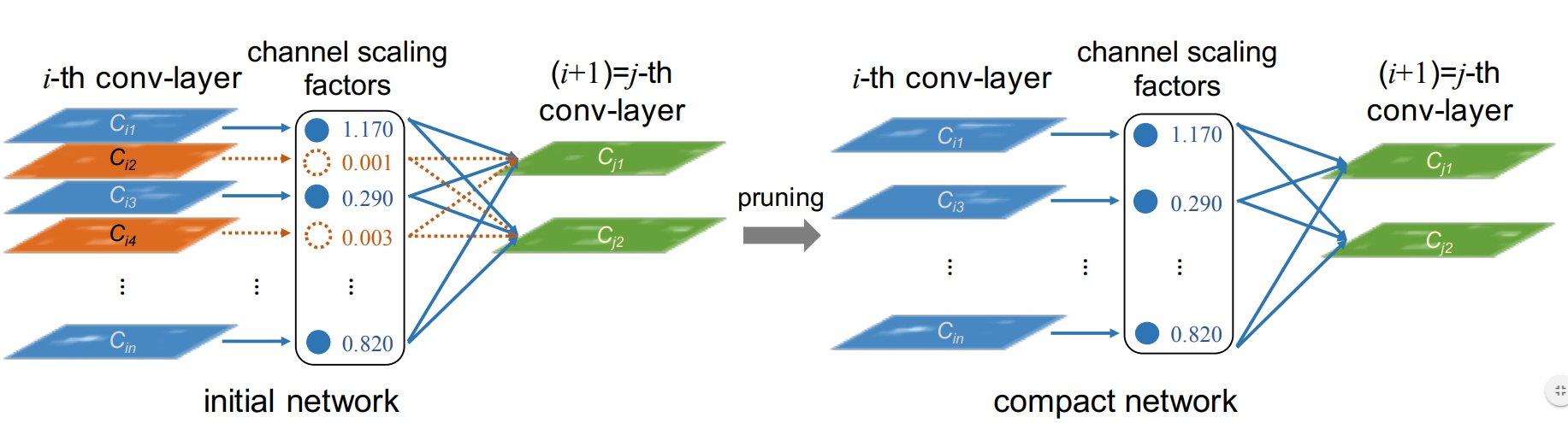
将预训练好的网络删减掉一些Channel(再fine-tuning),让模型参数减少的同时,还能让准确率维持不变(或精度损失很少)。
那问题来了:
- 1)那它是以什么准则来删减Channel?
- 2)总体训练步骤是什么?
- 3)效果如何?优缺点是?
- 4)类似相关工作有哪些?
论文方法从BN中得到启发。我们回顾下BN:其中 表示mini-batch B中某feature map的均值,scale
和 shift
都是通过反向传播训练更新。
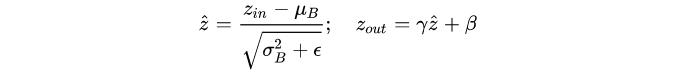
这么看来,可以直接用 来评估channel的重要程度。
的数越小,说明该channel的信息越不重要,也就可以删减掉该Channel。虽然可以通过删减
值接近零的channel,但是一般情况下,
值靠近0的channel还是属于少数。于是作者采用smooth-L1 惩罚
,来让
值倾向于0。那么网络的损失函数就可设计为:
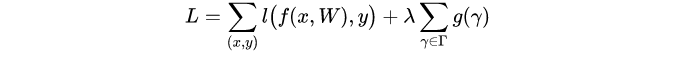
其中 是训练的输入和目标,
是可训练的权重,
是引导稀疏的惩罚函数,
作为这两项的调整。 文中选择
,当然也可以采用Smooth_L1方法在零点为光滑曲线。
Tips:
a) 论文中提到Smooth-L1时,引用的是:2007_Fast optimization methods for l1 regularization: A comparative study and two new approaches.
b) 而2015_Fast R-CNN 提出了 Smooth-L1 公式为:
c) 作者源码采用的不是Fast R-CNN提出的SmoothL1. 可以看下 论文提供的源码. https://github.com/Eric-mingjie/rethinking-network-pruning/
接下来我们看看训练过程(非常简明的步骤):

- 第一步:初始化网络;
- 第二步:加入Channel稀疏惩罚项,训练网络;
- 第三步:通过固定阈值来删减channel,如删减70%的channel;
- 第四步:Fine-tune。由于删减channel后精度会下降,故再训练去微调网络;
- 第五步:可以再跳到第二步,实现多次精简网络;
- 第六步:得到精简后的网络。
具体操作细节:
γ通常取 1e-4或者1e-5,具体情况具体分析,
γ得出后,应该怎么剪,γ多小才算小? 这里采用与类似PCA里的能量占比差不多,将当前层的γ全都加起来,然后按从大到小的顺序排列,选取较大的那一部分,通常选取70%左右(具体情况具体分析)。
λ的选取对γ的影响如图所示:
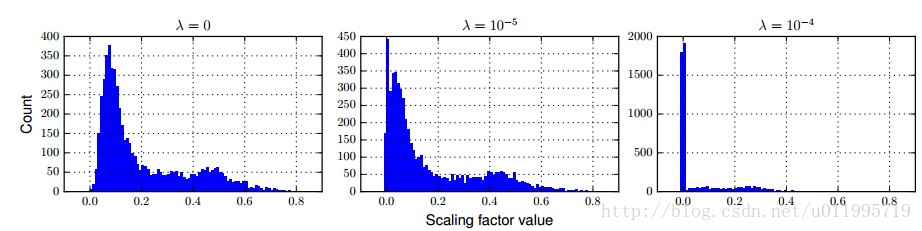
λ为0的时候,目标函数不会对γ进行惩罚,λ等于1e-5时,可以发现,γ=0.0+的有450多个,整体都向0靠近。当λ=1e-4时,对γ有了更大的稀疏约束了,可以看到有接近2000个γ是在0.0x附近。
剪枝百分比: 剪得越多,模型越小;剪得太多,精度损失。这是矛盾的,所以作者做了实验对比,看看剪多少合适。实验发现,当剪枝超过80%,精度会下降。

具体实验请阅读原文,其中涉及了vgg,resnet-164(pre-actionvation),densenet-40。效果都很好,不仅压缩模型大小,提升运算速度,还能提升分类准确率。
对剪枝的程度没有先验知识的指导。论文是把所有通道的γ 值做了排序,选择砍掉一定比例的γ,但是这个比例会因为具体的模型、具体的任务而变化很大。在我的项目中,剪枝3轮,每轮剪枝20%,对精度无影响;如果每轮剪枝30%,对精度有很大影响。也就是说不能自动的将模型压缩到最紧凑,二是靠“试”。
本人已经基于此方法在MobileNetV2-ssdlite上验证成功,精度不减的情况下,模型压缩50%左右,速度能够提升近1倍,代码即将开源。
posted on 2019-08-01 20:23 Sanny.Liu-CV&&ML 阅读(735) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号