
单变量的线性回归(Linear Regression with One Variable)
模型表示
监督学习中对于每个输入数据来说,我们都给出了 “ 正确的答案 ” 。
例如我们之前讨论的房价问题,假设我们的训练集如下表所示:
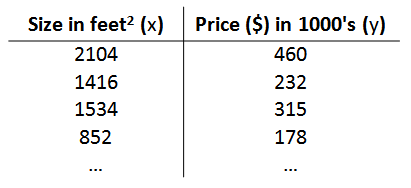
我们将描述这个回归问题的符号标记如下:
m:代表训练集中实例的数量
x:代表特征/输入变量
y:代表目标变量/输出变量
(x,y):代表训练集中的实例
(xi,yi):代表第 i 个观察实例
h:代表学习算法的解决方案或函数,也称假设(hypothesis)
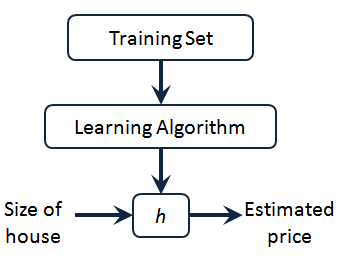
如上图所示,这就是一个监督学习算法的一个实例,h 代表一个函数/模型,根据输入的 x 值来得到 y 值,其中 y 值对应房子的价格,因此 h 是一个从 x 到 y 的函数映射。因此,我们要解决房价预测问题,我们实际上是要将训练集 “ 喂 ” 给我们的学习算法,进而学习到一个模型 h ,然后我们将要预测的房屋的尺寸作为输入变量输入给 h ,预测出该房屋价格。
那么我们该如何表达 h ?一种可能的表达方式为: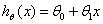 ,因为只有一个特征/输入变量,因此这样的问题叫做单变量回归问题。
,因为只有一个特征/输入变量,因此这样的问题叫做单变量回归问题。

定义好了函数的形式,接下来我们需要对我们的函数选择合适的参数,其中在房价预测这个例子中函数中的两个参数在数学意义上分别是直线的斜率和截距,我们选择的参数决定了我们得到的直线相对于训练集的准确程度,其中模型所预测的值与训练集中的实际值之间的差距(如下图蓝线)就是建模误差(modeling error)。
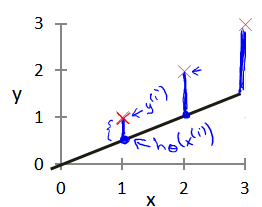 我们的目标就是选择一组能使建模误差最小的模型参数。即使得代价函数最小:
我们的目标就是选择一组能使建模误差最小的模型参数。即使得代价函数最小:
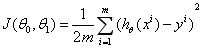
例如下图是一个等高线图,三个坐标分别为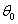 ,
,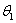 ,和
,和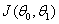
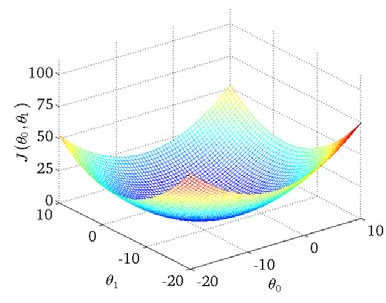
可以看出在三维空间中存在一组参数,使得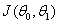 最小。
最小。

梯度下降
梯度下降是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数 得最小值。
得最小值。
其背后思想是:
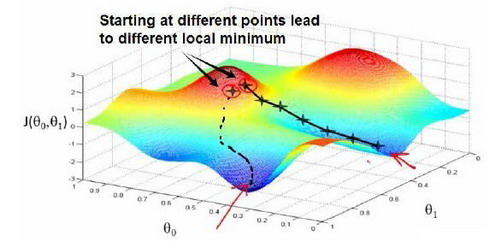
开始我们随机选择一组参数,计算代价函数,然后我们选择下一组能让梯度下降最多的参数集合,然后以此类推,知道找到一个局部的最小值点(local minimum),因为我们并没有尝试过所有的参数的组合,所以不能确定我们得到的局部最小值点是否是全局最小值点(global minimum)。选择不同的初始参数集合,可能会找到不同的局部最小值。
批量梯度下降(batch gradient descent):
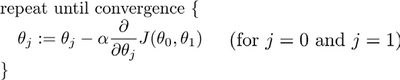
其中 a 是学习率(learning rate),它决定了我们沿着代价函数梯度下降的方向下降的步长,在批量梯度下降中,我们每一次都同时让所有的参数减去学习率乘以代价函数的导数。

在梯度下降的过程中,如果学习率太小,会导致模型收敛的很慢,如果学习率特别大,则可能导致模型无法收敛,甚至发散。
问题:如果在参数初始化的时候已经到达了局部最低点,下一步梯度下降法会怎样工作?
假设参数初始化已经在局部最低点,,结果就是局部最低点的导数将等于零,这就意味着梯度已经在局部最优,则参数相当于什么有没更新,不会改变当前梯度的 值,这也就解释了即使学习率在保持不变的情况下,梯度下降法也可以收敛到局部最低点,在接近局部最低点时,梯度下降法会自动采取更小的幅度。
线性回归算法
线性回归算法和梯度下降法比较如图:

我们对之前的线性回归问题运用梯度下降法如下:
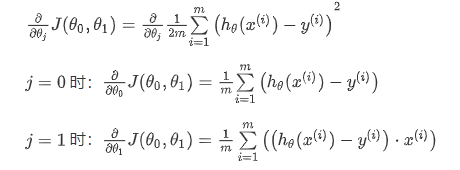
则有:
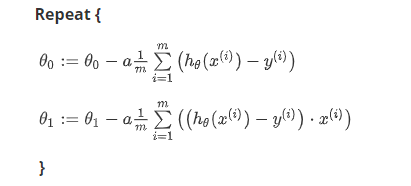
当然,除了梯度下降法还有一种计算单价函数 J 的最小值的数值解法 “ 正规方程(normal equations) ” ,它可以在不需要多步梯度下降的情况下,也能解的代价函数的最小值,但在数据量较大的情况下,梯度下降法更加适用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号