

filebeat 教程
--------------------------------------------------------------------
beats是轻量级的日志收集处理工具,Beats占用资源少
- Packetbeat: 网络数据(收集网络流量数据)
- Metricbeat: 指标 (收集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
- Filebeat: 文件(收集日志文件数据)
- Winlogbeat: windows事件日志(收集 Windows 事件日志数据)
- Auditbeat:审计数据 (收集审计日志)
- Heartbeat:运行时间监控 (收集系统运行时的数据)
---------------------------------------------------------------
1. filebeat安装
#rpm安装方式
https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.5-x86_64.rpm
rpm -ivh filebeat-7.17.5-x86_64.rpm
systemctl enable filebeat --now
#二进制包安装方式
1.下载
mkdir -p /data/tools/filebeat/ && cd /data/tools/filebeat/
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.5-linux-x86_64.tar.gz
tar -xvf filebeat-7.17.5-linux-x86_64.tar.gz
--------------这里第二部和第三步先不操作,案例部分和2,3冲突--------------------------------
2.使用systemctl管理filebeat服务
cat > /usr/lib/systemd/system/filebeat.service <<EOF
[Unit]
Description=es
After=network.target
[Service]
Type=simple
ExecStart=/data/tools/filebeat/filebeat-7.17.5-linux-x86_64/filebeat -c /data/tools/filebeat/filebeat-7.17.5-linux-x86_64/filebeat.yml
User=filebeat
LimitNOFILE=131070
[Install]
WantedBy=multi-user.target
EOF
3.重新加载systemctl,启动filebeat
systemctl daemon-reload
systemctl enable filebeat --now
2. filbeat案例
2.1. input插件之stdin:案例
https://www.elastic.co/guide/en/beats/filebeat/7.17/index.html
-------------------------------------------------------------------------------
1. filbeat的input插件之stdin案例
(1)创建工作目录
cd /data/tools/filebeat/filebeat-7.17.5-linux-x86_64
mkdir config
(2)编写配置文件
[root@elk1]# cat >> config/01-stdin-to-console.yaml <<EOF
# 配置filebeat的输入端
filebeat.inputs:
# 指定输入端的类型为标准输入
- type: stdin
# 指定filebeat的输出端为console
output.console:
# 表示输出的内容以漂亮的格式显示
pretty: true
EOF
(3)启动filebeat的实例
filebeat -e -c config/01-stdin-to-console.yaml
(4) 测试输入输出
输入: 232323231
输出:
{
........
"message": "232323231",
.....
}
2.2. input插件之tcp:案例
]# cat >> config/02-tcp-to-console.yaml <<EOF
# 配置filebeat的输入端
filebeat.inputs:
# 指定输入端的类型为tcp
- type: tcp
# 定义tcp监听的主机和端口
host: 0.0.0.0:8888
# 指定filebeat的输出端为console
output.console:
# 表示输出的内容以漂亮的格式显示
pretty: true
EOF
(3)启动filebeat的实例
./filebeat -e -c config/02-tcp-to-console.yaml
(4) 测试输入输出
输入: echo "1111"|nc 10.0.0.101 8888
输出:
{
......
"message": "1111",
.....
}
2.3. input的通用字段案例:
input的通用字段案例:
filebeat input插件的通用字段(common options):
- enabled:
是否启用该组件,有true和false,默认值为true。当设置为false时,表示该input组件不会被加载执行!
- tags:
给每条数据添加一个tags标签列表。
- fields
给数据添加字段。
- fields_under_root
该值默认值为false,将自定义的字段放在一个"fields"的字段中。若设置为true,则将fields的KEY放在顶级字段中。
- processors:
定义处理器,对源数据进行简单的处理。
参考链接:
https://www.elastic.co/guide/en/beats/filebeat/7.17/defining-processors.html
2.4. 综合案例:
5 综合案例:
[root@elk]# cat >> config/03-input_common_options-to-console.yaml <<EOF
filebeat.inputs:
- type: log
paths:
- /tmp/logtest/*.log
- /tmp/logtest/*/*.json
- /tmp/logtest/**/*.exe
# 是否启用该类型,默认值为true。
enabled: false
- type: tcp
enabled: true
host: "0.0.0.0:8888"
# 给数据打标签,会在顶级字段多出来多个标签
tags: ["2024","new","happy"]
# 给数据添加KEY-VALUE类型的字段,默认是放在"fields"中的
fields:
school: qinghua
class: "5-4"
classroom: "032"
ip: 219.141.136.10
port: 13306
# 若设置为true时,则将fields添加的自定义字段放在顶级字段中,默认值为false。
fields_under_root: true
# 定义处理器,过滤指定的数据
processors:
# 删除消息是以linux开头的事件(event)
- drop_event:
when:
regexp:
message: "^linux"
# 消息包含error内容事件(event)就可以删除自定义字段或者tags。无法删除内置的字段.
- drop_fields:
when:
contains:
message: "error"
fields: ["class","tags"]
ignore_missing: false
# 修改字段的名称
- rename:
fields:
# 源字段
- from: "school"
# 目标字段
to: "学校"
- from: "log"
to: "日志"
# 转换数据,将字段的类型转换对应的数据类型,并存放在指定的字段中,本案例将其放在"tom"字段中
- convert:
fields:
- {from: "ip", to: "tom.ip", type: "ip"}
- {from: "port", to: "tom.port", type: "integer"}
# 指定filebeat的输出端为console
output.console:
# 表示输出的内容以漂亮的格式显示
pretty: true
EOF
2.5. input插件之log(log插件在7.16版本后弃用)
2.5.1. input插件之log:采集常规数据
# filbeat的input插件之log案例(log插件在7.16版本后弃用)
(1)编写配置文件
[root@elk1]# cat >> config/04-log-to-console.yaml <<EOF
filebeat.inputs:
# 指定输入类型是log
- type: log
# 指定文件路径
paths:
# 一个*,只匹配logtest单层目录下面的以log结尾的文件
- /tmp/logtest/*.log
# 两个*,可以递归匹配logtest下面所有层级的以json结尾的文件
- /tmp/logtest/**/*.json
# 指定filebeat的输出端为console
output.console:
# 表示输出的内容以漂亮的格式显示
pretty: true
EOF
(2)启动filebeat实例
[root@elk1]# ./filebeat -e -c config/04-log-to-console.yaml
(3)测试数据
]# tree /tmp/logtest/
/tmp/logtest/
├── 1
│ ├── 1.json
│ └── 1.log
├── 1.json
└── 1.log
/tmp/logtest/*.log 收集/tmp/logtest/1.log, 不收集/tmp/logtest/1/1.log
/tmp/logtest/**/*.json 收集/tmp/logtest/1.json /tmp/logtest/1/1.json
2.5.2. input插件之log:采集json数据,指定数据采集,排除指定数据采集
6 包含指定数据采集,排除指定数据采集及json格式数据采集案例
[root@elk]# cat config/05-log-to-console.yaml
filebeat.inputs:
- type: log
paths:
- /tmp/logtest/*
# 排除以log结尾的文件
exclude_files: ['\.log$']
# 只采集包含指定信息的数据
# include_lines: ['linux']
# 只要包含特定的数据就不采集该事件(event)
# exclude_lines: ['^linux']
# 将message字段的json数据格式进行解析,并将解析的结果放在顶级字段中
json.keys_under_root: true
# 如果解析json格式失败,则会将错误信息添加为一个"error"字段输出
json.add_error_key: true
# 指定filebeat的输出端为console
output.console:
# 表示输出的内容以漂亮的格式显示
pretty: true
2.5.3. input插件之log:采集nginx原生格式日志
7 使用filebeat采集nginx日志
(1)搭建nginx环境
1.1 添加yum源
cat > /etc/yum.repos.d/nginx.repo <<'EOF'
[nginx-stable]
name=nginx stable repo
baseurl=http://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=1
enabled=1
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
[nginx-mainline]
baseurl=http://nginx.org/packages/mainline/centos/$releasever/$basearch/
gpgcheck=1
enabled=0
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
EOF
1.2 安装nginx
yum -y install nginx
systemctl start nginx
(2)使用filebeat采集nginx日志
[root@elk1 filebeat-7.17.5-linux-x86_64]# cat >> config/06-log_nginx-to-console.yaml <<EOF
filebeat.inputs:
- type: log
paths:
- /var/log/nginx/access.log*
output.console:
# 表示输出的内容以漂亮的格式显示
pretty: true
EOF
[root@elk1 filebeat-7.17.5-linux-x86_64]# ./filebeat -e -c config/06-log_nginx-to-console.yaml
2.5.4. input插件之log:采集nginx的json格式日志
7 使用filebeat采集nginx的json格式日志
(1)修改nginx的配置文件
# vim /etc/nginx/nginx.conf
...
# log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
# access_log /var/log/nginx/access.log main;
log_format nginx_json '{"@timestamp":"$time_iso8601",'
'"host":"$server_addr",'
'"clientip":"$remote_addr",'
'"SendBytes":$body_bytes_sent,'
'"responsetime":$request_time,'
'"upstreamtime":"$upstream_response_time",'
'"upstreamhost":"$upstream_addr",'
'"http_host":"$host",'
'"uri":"$uri",'
'"domain":"$host",'
'"xff":"$http_x_forwarded_for",'
'"referer":"$http_referer",'
'"tcp_xff":"$proxy_protocol_addr",'
'"http_user_agent":"$http_user_agent",'
'"status":"$status"}';
access_log /var/log/nginx/access.log nginx_json;
(2)热加载nginx
systemctl reload nginx
> /var/log/nginx/access.log
(3)测试访问nginx
curl http://10.0.0.101/
(4)filebeat采集nginx的json格式日志
[root@elk1 filebeat-7.17.5-linux-x86_64]# cat > config/07-log_nginx_json-to-console.yaml <<EOF
filebeat.inputs:
- type: log
paths:
- /var/log/nginx/access.log*
json.keys_under_root: true
json.add_error_key: true
output.console:
# 表示输出的内容以漂亮的格式显示
pretty: true
EOF
(5)启动filebeat实例
[root@elk1 filebeat-7.17.5-linux-x86_64]# ./filebeat -e -c config/07-log_nginx_json-to-console.yaml
2.5.5. input插件之log:采集tomcat访问日志json格式
8 使用filebeat采集tomcat访问日志:
(1)安装tomcat
1.1 下载tomcat软件包
mkdir -p /data/tools/tomcat/ && cd /data/tools/tomcat/
wget https://mirrors.tuna.tsinghua.edu.cn/apache/tomcat/tomcat-9/v9.0.91/bin/apache-tomcat-9.0.91.tar.gz
1.2 解压软件包
tar xf apache-tomcat-9.0.91.tar.gz
(2)修改tomcat的配置文件
cd /data/tools/tomcat/apache-tomcat-9.0.91/conf
cp server.xml{,.bak}
vim server.xml
...(切换到行尾修改,大概是在133-149之间)
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="tomcat_access_log" suffix=".txt"
pattern="{"clientip":"%h","ClientUser":"%l","authenticated":"%u","AccessTime":"%t","request":"%r","status":"%s","SendBytes":"%b","Query?string":"%q","partner":"%{Referer}i","http_user_agent":"%{User-Agent}i"}"/>
(3)配置环境变量并启动tomcat服务
[root@elk1]# cat > /etc/profile.d/tomcat.sh <<'EOF'
#!/bin/bash
export TOMCAT_HOME=/data/tools/tomcat/apache-tomcat-9.0.91/
export PATH=$PATH:$TOMCAT_HOME/bin
EOF
[root@elk]# source /etc/profile.d/tomcat.sh
[root@elk]# catalina.sh start
(4)使用filebeat采集tomcat日志
[root@elk1 filebeat-7.17.5-linux-x86_64]# cat > config/08-log_tomcat-to-console.yaml <<EOF
filebeat.inputs:
- type: log
paths:
- /data/tools/tomcat/apache-tomcat-9.0.91/logs/tomcat_access_log*.txt
json.keys_under_root: true
json.add_error_key: true
output.console:
# 表示输出的内容以漂亮的格式显示
pretty: true
EOF
[root@elk103.oldboyedu.com filebeat-7.17.5-linux-x86_64]#
(5)启动filebeat实例
[root@elk1 filebeat-7.17.5-linux-x86_64]# ./filebeat -e -c config/08-log_tomcat-to-console.yaml
2.5.6. input插件之log: 采集-tomcat的启动日志中错误日志,多行匹配案例
https://www.elastic.co/guide/en/beats/filebeat/7.17/multiline-examples.html
9 采集tomcat的错误日志多行匹配案例
[root@elk1 filebeat-7.17.5-linux-x86_64]# cat > config/09-log-tomcat_error-to-es.yaml <<EOF
filebeat.inputs:
- type: log
paths:
- /data/tools/tomcat/apache-tomcat-9.0.91/logs/catalina*
multiline.type: pattern
multiline.pattern: '^\d{2}'
multiline.negate: true
multiline.match: after
# 指定输出端为ES集群
output.elasticsearch:
hosts: ["http://10.0.0.101:9200","http://10.0.0.102:9200","http://10.0.0.103:9200"]
EOF
#参数解释:
negate英语翻译是取反
multiline.negate: false|true, flase表匹配,true表示不匹配
multiline.match:before|after
用法说明:
1.当multiline.negate为false时:
multiline.match为after 表示 【匹配的行】 会被放到 上一个【不匹配的行】 【后】,形成一行
multiline.match为before 表示 【匹配的行】 会被放到 下一个【不匹配的行】 【前】,形成一行
2.当multiline.negate为true时:
multiline.match为after 表示 【不匹配的行】 会被放到 上一个【匹配的行】 【后】,形成一行
multiline.match为before 表示 【不匹配的行】 会被放到 下一个【匹配的行】 【前】,形成一行
#启动filebeat
[root@elk1 filebeat-7.17.5-linux-x86_64]# ./filebeat -e -c config/09-log-tomcat_error-to-es.yaml
2.6. input插件之filestream(替代log插件)
2.6.1. input插件之filestream: output到console
11 filebeat的input类型之filestream实战案例:
[root@elk1 filebeat-7.17.5-linux-x86_64]# ]# cat config/11-filestream-to-console.yaml
filebeat.inputs:
# 指定类型为filestream,在7.16版本中已经弃用log类型
- type: filestream
enabled: false
paths:
- /tmp/logtest/1.log
parsers:
#配置解析多行模式
- multiline:
type: pattern
pattern: '^\['
negate: true
match: after
- type: filestream
enabled: true
paths:
- /tmp/logtest/student.log
# 配置解析
parsers:
# 配置json格式解析
- ndjson:
# 将错误消息记录到error字段中
add_error_key: true
# 如果解析的json格式字段和filebeat内置的顶级字段冲突,则覆盖,默认是不覆盖的。
overwrite_keys: true
# 将message解析的字段放入一个自定义的字段下。若不指定该字段,则默认解析的键值对会在顶级字段.
target: "student"
output.console:
pretty: true
EOF
[root@elk1 filebeat-7.17.5-linux-x86_64]# ./filebeat -e -c config/11-filestream-to-console.yaml
2.6.2. input插件之filestream,output到logstash
#input插件之filestream-收集ningx日志,output的logstash插件发送到logstash
[root@elk1filebeat-7.17.5-linux-x86_64]# cat > config/15-filestream-nginx-to-logstash.yaml <<EOF
filebeat.inputs:
# 指定类型为filestream,在7.16版本中已经弃用log类型
- type: filestream
enabled: true
paths:
- /var/log/nginx/access.log*
# 配置解析
parsers:
# 配置json格式解析
- ndjson:
# 将错误消息记录到error字段中
add_error_key: true
# 如果解析的json格式字段和filebeat内置的顶级字段冲突,则覆盖,默认是不覆盖的。
overwrite_keys: true
# 将数据输出到logstash中
output.logstash:
# 指定logstash的主机和端口
hosts: ["10.0.0.101:8888"]
EOF
[root@elk103.oldboyedu.com filebeat-7.17.5-linux-x86_64]#
[root@elk103.oldboyedu.com filebeat-7.17.5-linux-x86_64]# ./filebeat -e -c config/15-filestream-nginx-to-logstash.yaml
2.7. input插件之container: 采集docker日志
10 使用filebeat采集docker日志
(1)安装docker
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
sed -i 's+download.docker.com+mirrors.aliyun.com/docker-ce+' /etc/yum.repos.d/docker-ce.repo
yum makecache fast
yum -y install docker-ce docker-compose
(2)配置docker的镜像加速,启动服务
[root@elk1]# cat > /etc/docker/daemon.json <<EOF
{
"registry-mirrors": ["https://2k3sfxf3.mirror.aliyuncs.com"]
}
EOF
[root@elk1 ~]# systemctl enable --now docker
(3)下载nginx镜像
docker run -dp 88:80 --name mynginx --restart always nginx:alpine
docker run -dp 89:8080 --name mytomcat --restart always tomcat:jre8-alpine
(4)使用filebeat采集容器日志
方式一:(此方法从[7.2.0]版本开始已弃用)
[root@elk1 filebeat-7.17.5-linux-x86_64]# cat >config/10-docker-to-console.yaml <<EOF
filebeat.inputs:
# 指定输入类型为docker类型
- type: docker
# 指定容器的ID
containers.ids:
- '*'
output.console:
pretty: true
EOF
方式二:(推荐使用)
[root@elk1 filebeat-7.17.5-linux-x86_64]# cat >config/10-docker-to-console.yaml <<EOF
filebeat.inputs:
- type: container
paths:
- '/var/lib/docker/containers/*/*.log'
output.console:
pretty: true
EOF
(5)启动filebeat实例
[root@elk1 filebeat-7.17.5-linux-x86_64]# ./filebeat -e -c config/10-docker-to-console.yaml
2.8. output插件之file-将数据写入到本地文件案例
12 将数据写入到本地文件案例
[root@elk1 filebeat-7.17.5-linux-x86_64]# cat > config/12-stdin-to-file.yaml <<EOF
filebeat.inputs:
- type: stdin
# 指定输出的类型为本地文件
output.file:
# 指定文件存储的路径
path: "/tmp/tom/"
# 指定文件的名称
filename: stdin.log
EOF
[root@elk1 filebeat-7.17.5-linux-x86_64]# ./filebeat -e -c config/12-stdin-to-file.yaml
2.9. output插件之elasticsearch:写入数据到ES集群
13 写入数据到ES集群
[root@elk1 filebeat-7.17.5-linux-x86_64]# cat > config/13-filestream-to-es.yaml <<EOF
filebeat.inputs:
- type: filestream
enabled: true
paths:
- /tmp/logtest/shopping.json
parsers:
- ndjson:
add_error_key: true
overwrite_keys: true
output.elasticsearch:
# 指定ES集群地址
hosts:
- "http://10.0.0.101:9200"
- "http://10.0.0.102:9200"
- "http://10.0.0.103:9200"
# 指定索引
index: "shopping-%{+yyyy.MM.dd}"
#连接es的用户名密码
username: "filebeat-user"
password: "123456"
# 禁用索引声明管理周期,若不禁用则自动忽略自定义索引名称
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "shopping"
# 指定索引模板的匹配模式
setup.template.pattern: "shopping-*"
# 是否覆盖原有的索引模板
setup.template.overwrite: true
# 设置索引模板
setup.template.settings:
# 指定分片数量为8
index.number_of_shards: 8
# 指定副本数量为0
index.number_of_replicas: 0
EOF
[root@elk1 filebeat-7.17.5-linux-x86_64]# ./filebeat -e -c config/13-filestream-to-es.yaml
2.10. output插件之elasticsearch:将多个数据源写入到ES集群不同索引
14 将多个数据源写入到ES集群不同索引
[root@elk1 filebeat-7.17.5-linux-x86_64]# cat > config/14-filestream-indices-to-es.yaml <<EOF
filebeat.inputs:
- type: filestream
enabled: true
tags: "docker"
paths:
- /tmp/logtest/docker.json
parsers:
- ndjson:
add_error_key: true
overwrite_keys: true
- type: filestream
enabled: true
tags: "linux"
paths:
- /tmp/logtest/linux.log
parsers:
#配置解析多行模式
- multiline:
type: pattern
pattern: '^\['
negate: true
match: after
output.elasticsearch:
hosts:
- "http://10.0.0.101:9200"
- "http://10.0.0.102:9200"
- "http://10.0.0.103:9200"
#连接es的用户名密码
username: "filebeat-user"
password: "123456"
indices:
- index: "tom-docker-%{+yyyy.MM.dd}"
when.contains:
tags: "docker"
- index: "tom-linux-%{+yyyy.MM.dd}"
when.contains:
tags: "linux"
setup.ilm.enabled: false
setup.template.name: "tom"
setup.template.pattern: "tom-*"
setup.template.overwrite: true
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 0
EOF
[root@elk1 filebeat-7.17.5-linux-x86_64]# filebeat -e -c config/14-filestream-indices-to-es.yaml
2.11. output插件之kafka
filebeat将数据写入到Kafka实战:
[root@elk101 filebeat-7.17.5-linux-x86_64]# cat > config/17-stdin-to-kafka.yaml <<EOF
filebeat.inputs:
- type: stdin
# 将数据输出到kafka
output.kafka:
# 指定kafka主机列表
hosts:
- 10.0.0.101:9092
- 10.0.0.102:9092
- 10.0.0.103:9092
# 指定kafka的topic
topic: "topic-1"
EOF
[root@elk101 filebeat-7.17.5-linux-x86_64]# ./filebeat -e -c config/17-stdin-to-kafka.yaml
3. config.inputs插件:包含多个子配置文件
filebeat.config.inputs:
enabled: true
#指定子配置文件的路径
path: configs/*.yaml
#是否实时重载,配置文件变化时,不需要重启filebeat
reload.enabled: true
#实时重载扫描间隔时间
reload.period: 10s
]# cat filebeat.yml
filebeat.config.inputs:
enabled: true
#指定子配置文件的路径
path: configs/*.yaml
#是否实时重载,配置文件变化时,不需要重启filebeat
reload.enabled: true
#实时重载扫描间隔时间
reload.period: 10s
[root@elk1 filebeat-7.17.5-linux-x86_64]# tree config/
config/
├── 01-stdin-to-console.yaml
├── 02-tcp-to-console.yaml
├── 04-log-to-console.yaml
————————————————
轻量级的日志采集组件 Filebeat 讲解与实战操作
一、概述
Filebeat是一个轻量级的日志数据收集工具,属于Elastic公司的Elastic Stack(ELK Stack)生态系统的一部分。它的主要功能是从各种来源收集日志数据,将数据发送到Elasticsearch、Logstash或其他目标,以便进行搜索、分析和可视化。
以下是Filebeat的主要概述和特点:
-
轻量级:Filebeat是一个轻量级的代理,对系统资源的消耗非常低。它设计用于高性能和低延迟,可以在各种环境中运行,包括服务器、容器和虚拟机。
-
多源收集:Filebeat支持从各种来源收集数据,包括日志文件、系统日志、Docker容器日志、Windows事件日志等。它具有多个输入模块,可以轻松配置用于不同数据源的数据收集。
-
模块化:Filebeat采用模块化的方式组织配置,每个输入类型都可以作为一个模块,易于扩展和配置。这使得添加新的数据源和日志格式变得更加简单。
-
自动发现:Filebeat支持自动发现服务,可以在容器化环境中自动识别新的容器和服务,并开始收集其日志数据。
-
安全性:Filebeat支持安全传输,可以使用TLS/SSL加密协议将数据安全地传输到目标。它还支持基于令牌的身份验证。
-
数据处理:Filebeat可以对数据进行简单的处理,如字段分割、字段重命名和数据过滤,以确保数据适合进一步处理和分析。
-
目标输出:Filebeat可以将数据发送到多个目标,最常见的是将数据发送到Elasticsearch,以便进行全文搜索和分析。此外,还可以将数据发送到Logstash、Kafka等目标。
-
实时性:Filebeat可以以实时方式收集和传输数据,确保日志数据及时可用于分析和可视化。
-
监控和管理:Filebeat具有自身的监控功能,可以监视自身的状态和性能,并与Elasticsearch、Kibana等工具集成,用于管理和监控数据收集。
工作的流程图如下:
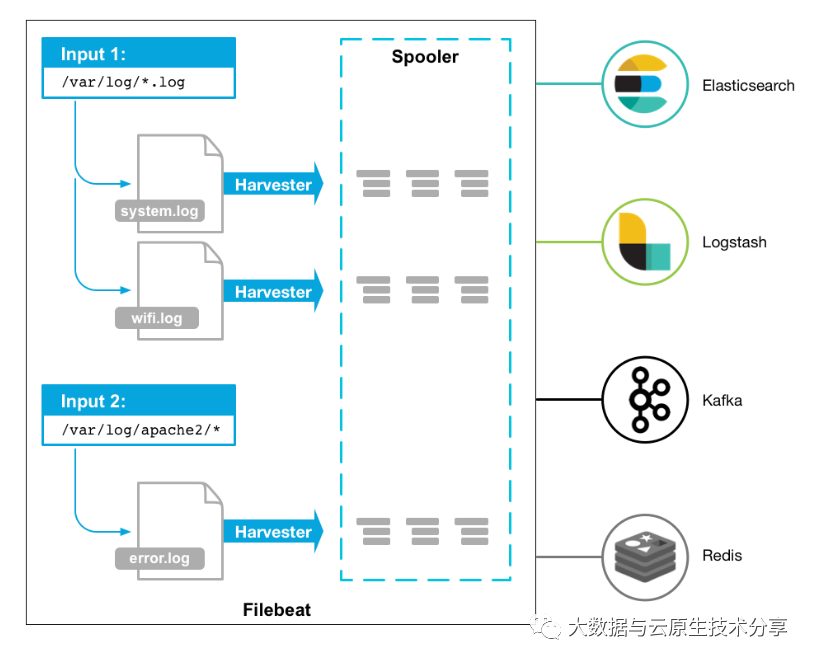
Filebeat的采集原理的主要步骤
-
数据源检测:
-
Filebeat首先配置要监视的数据源,这可以是日志文件、系统日志、Docker容器日志、Windows事件日志等。Filebeat可以通过输入模块配置来定义数据源。
-
-
数据收集:
-
一旦数据源被定义,Filebeat会定期轮询这些数据源,检查是否有新的数据产生。
-
如果有新数据,Filebeat将读取数据并将其发送到后续处理阶段。
-
-
数据处理:
-
Filebeat可以对采集到的数据进行一些简单的处理,例如字段分割、字段重命名、数据解析等。这有助于确保数据格式适合进一步的处理和分析。
-
-
数据传输:
-
采集到的数据将被传输到一个或多个目标位置,通常是Elasticsearch、Logstash或Kafka等。
-
Filebeat可以配置多个输出目标,以便将数据复制到多个地方以增加冗余或分发数据。
-
-
安全性和可靠性:
-
Filebeat支持安全传输,可以使用TLS/SSL协议对数据进行加密。
它还具有数据重试机制,以确保数据能够成功传输到目标位置。
-
-
数据目的地:
-
数据被传输到目标位置后,可以被进一步处理、索引和分析。目标位置通常是Elasticsearch,用于全文搜索和分析,或者是Logstash用于进一步的数据处理和转换,也可以是Kafka等其他消息队列。
-
-
实时性和监控:
-
Filebeat可以以实时方式监视数据源,确保新数据能够快速传输和处理。
-
Filebeat还可以与监控工具集成,以监控其自身的性能和状态,并将这些数据发送到监控系统中。
-
总的来说,Filebeat采集原理是通过轮询监视数据源,将新数据采集并发送到目标位置,同时确保数据的安全传输和可靠性。它提供了一种高效且灵活的方式来处理各种类型的日志和事件数据,以便进行后续的分析和可视化。
二、Kafka 安装
为了快速部署,这里选择通过docker-compose部署,可以参考我这篇文章:【中间件】通过 docker-compose 快速部署 Kafka 保姆级教程
# 先安装 zookeeper
git clone https://gitee.com/hadoop-bigdata/docker-compose-zookeeper.git
cd docker-compose-zookeeper
docker-compose -f docker-compose.yaml up -d
# 安装kafka
git clone https://gitee.com/hadoop-bigdata/docker-compose-kafka.git
cd docker-compose-kafka
docker-compose -f docker-compose.yaml up -d
如果仅仅只是为测试也可以部署一个单机kafka
官方下载地址:http://kafka.apache.org/downloads
### 1、下载kafka
wget https://downloads.apache.org/kafka/3.4.1/kafka_2.12-3.4.1.tgz --no-check-certificate
### 2、解压
tar -xf kafka_2.12-3.4.1.tgz
### 3、配置环境变量
# ~/.bashrc添加如下内容:
export PATH=$PATH:/opt/docker-compose-kafka/images/kafka_2.12-3.4.1/bin
### 4、配置zookeeper 新版Kafka已内置了ZooKeeper,如果没有其它大数据组件需要使用ZooKeeper的话,直接用内置的会更方便维护。
# vi kafka_2.12-3.4.1/config/zookeeper.properties
#注释掉
#maxClientCnxns=0
#设置连接参数,添加如下配置
#为zk的基本时间单元,毫秒
tickTime=2000
#Leader-Follower初始通信时限 tickTime*10
initLimit=10
#Leader-Follower同步通信时限 tickTime*5
syncLimit=5
#设置broker Id的服务地址
#hadoop-node1对应于前面在hosts里面配置的主机映射,0是broker.id, 2888是数据同步和消息传递端口,3888是选举端口
server.0=local-168-182-110:2888:3888
### 5、配置kafka
# vi kafka_2.12-3.4.1/config/server.properties
#添加以下内容:
broker.id=0
listeners=PLAINTEXT://local-168-182-110:9092
# 上面容器的zookeeper
zookeeper.connect=local-168-182-110:2181
# topic不存在的,kafka就会创建该topic。
#auto.create.topics.enable=true
### 6、启动服务
./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
./bin/kafka-server-start.sh -daemon config/server.properties
### 7、测试验证
#创建topic
kafka-topics.sh --bootstrap-server local-168-182-110:9092 --create --topic topic1 --partitions 8 --replication-factor 1
#列出所有topic
kafka-topics.sh --bootstrap-server local-168-182-110:9092 --list
#列出所有topic的信息
kafka-topics.sh --bootstrap-server local-168-182-110:9092 --describe
#列出指定topic的信息
kafka-topics.sh --bootstrap-server local-168-182-110:9092 --describe --topic topic1
#生产者(消息发送程序)
kafka-console-producer.sh --broker-list local-168-182-110:9092 --topic topic1
#消费者(消息接收程序)
kafka-console-consumer.sh --bootstrap-server local-168-182-110:9092 --topic topic1
三、Filebeat 安装
1)下载 Filebeat
官网地址:https://www.elastic.co/cn/downloads/past-releases#filebeat
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.6.2-linux-x86_64.tar.gz
tar -xf filebeat-7.6.2-linux-x86_64.tar.gz
2)Filebeat 配置参数讲解
Filebeat的配置文件通常是YAML格式,包含各种配置参数,用于定义数据源、输出目标、数据处理和其他选项。以下是一些常见的Filebeat配置参数及其含义:
-
filebeat.inputs:指定要监视的数据源。可以配置多个输入,每个输入定义一个数据源。每个输入包括以下参数:-
type:数据源的类型,例如日志文件、系统日志、Docker日志等。 -
paths:要监视的文件路径或者使用通配符指定多个文件。 -
enabled:是否启用该输入。
-
示例:
filebeat.inputs:
- type: log
paths:
- /var/log/*.log
- type: docker
enabled: true
-
filebeat.modules:定义要加载的模块,每个模块用于解析特定类型的日志或事件数据。每个模块包括以下参数:-
module:模块名称。 -
enabled:是否启用模块。 -
var:自定义模块变量。
-
示例:
filebeat.modules:
- module: apache
access:
enabled: true
error:
enabled: true
-
output.elasticsearch:指定将数据发送到Elasticsearch的配置参数,包括Elasticsearch主机、索引名称等。-
hosts:Elasticsearch主机列表。
-
index:索引名称模板。
-
username和password:用于身份验证的用户名和密码。
-
pipeline:用于数据预处理的Ingest节点管道。
-
示例:
output.elasticsearch:
hosts: ["localhost:9200"]
index: "filebeat-%{[agent.version]}-%{+yyyy.MM.dd}"
username: "your_username"
password: "your_password"
-
output.logstash:指定将数据发送到Logstash的配置参数,包括Logstash主机和端口等。-
hosts:Logstash主机列表。 -
index:索引名称模板。 -
ssl:是否使用SSL/TLS加密传输数据。
-
示例:
output.logstash:
hosts: ["localhost:5044"]
index: "filebeat-%{[agent.version]}-%{+yyyy.MM.dd}"
ssl.enabled: true
-
processors:定义对数据的预处理步骤,包括字段分割、重命名、添加字段等。-
add_fields:添加字段到事件数据。
-
decode_json_fields:解码JSON格式的字段。
-
drop_fields:删除指定字段。
-
rename:重命名字段。
-
示例:
processors:
- add_fields:
target: "my_field"
value: "my_value"
- drop_fields:
fields: ["field1", "field2"]
-
filebeat.registry.path:指定Filebeat用于跟踪已经读取的文件和位置信息的注册文件的路径。 -
filebeat.autodiscover:自动发现数据源,特别是用于容器化环境,配置自动检测新容器的策略。 -
logging.level:指定Filebeat的日志级别,可选项包括info、debug、warning等。
这些是 Filebeat 的一些常见配置参数,具体的配置取决于您的使用场景和需求。您可以根据需要自定义配置文件,以满足您的数据采集和处理需求。详细的配置文档可以在Filebeat官方文档中找到。
3)filebeat.prospectors 推送kafka完整配置
这里主要用到几个核心字段:filebeat.prospectors、processors、output.kafka
1、filebeat.prospectors
filebeat.prospectors:用于定义要监视的数据源和采集规则。每个 prospector 包含一个或多个输入规则,它们指定要监视的文件或数据源以及如何采集和解析数据。
以下是一个示例 filebeat.prospectors 部分的配置:
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/*.log
exclude_files:
- "*.gz"
multiline.pattern: '^\['
multiline.negate: false
multiline.match: after
tags: ["tag1", "tag2"]
tail_files: true
fields:
app: myapp
env: production
在上述示例中,我们定义了一个 filebeat.prospectors 包含一个 type: log 的 prospector,下面是各个字段的解释:
-
type(必需):数据源的类型。在示例中,类型是 log,表示监视普通文本日志文件。Filebeat支持多种类型,如log、stdin、tcp、udp等。 -
enabled:是否启用此prospector。如果设置为 true,则启用,否则禁用。默认为 true。 -
paths(必需):要监视的文件或文件模式,可以使用通配符指定多个文件。在示例中,Filebeat将监视 /var/log/ 目录下的所有以 .log 结尾的文件。 -
exclude_files:要排除的文件或文件模式列表。这里排除了所有以 .gz 结尾的文件。可选字段。 -
multiline.pattern:多行日志的起始模式。如果您的日志事件跨越多行,此选项可用于合并多行日志事件。例如,设置为 'pattern' 将根据以 'pattern' 开头的行来合并事件。 -
multiline.negate:是否取反多行日志模式。如果设置为 true,则表示匹配不包含多行日志模式的行。可选字段,默认为 false。 -
multiline.match:多行匹配模式,可以是 before(与上一行合并)或 after(与下一行合并)。如果设置为 before,则当前行与上一行合并为一个事件;如果设置为 after,则当前行与下一行合并为一个事件。可选字段,默认为after。 -
tags:为采集的事件添加标签,以便后续的数据处理。标签是一个字符串数组,可以包含多个标签。在示例中,事件将被标记为 "tag1" 和 "tag2"。可选字段。 -
tail_files:用于控制Filebeat是否应该跟踪正在写入的文件(tail文件)。当tail_files设置为true时,Filebeat将监视正在被写入的文件,即使它们还没有完成。这对于实时监视日志文件非常有用,因为它允许Filebeat立即处理新的日志行。默认情况下,tail_files是启用的,因此只有在特殊情况下才需要显式设置为 false。 -
fields:为事件添加自定义字段。这是一个键值对,允许您添加额外的信息到事件中。在示例中,事件将包含 "app" 字段和 "env" 字段,分别设置为 "myapp" 和 "production"。可选字段。
这些字段允许您配置Filebeat以满足特定的数据源和采集需求。您可以根据需要定义多个 prospector 来监视不同类型的数据源,每个 prospector 可以包含不同的参数。通过灵活配置 filebeat.prospectors,Filebeat可以适应各种日志和数据采集场景。
2、processors
processors 是Filebeat配置中的一个部分,用于定义在事件传输到输出目标之前对事件数据进行预处理的操作。您可以使用 processors 来修改事件数据、添加字段、删除字段,以及执行其他自定义操作。以下是一些常见的 processors 配置示例和说明:
-
添加字段(Add Fields):
可以使用 add_fields 处理器将自定义字段添加到事件中,以丰富事件的信息。例如,将应用程序名称和环境添加到事件中:
processors:
- add_fields:
fields:
app: myapp
env: production
-
删除字段(Drop Fields):
使用 drop_fields 处理器可以删除事件中的指定字段。以下示例删除名为 "sensitive_data" 的字段:
processors:
- drop_fields:
fields: ["sensitive_data"]
-
解码 JSON 字段(Decode JSON Fields):
如果事件中包含JSON格式的字段,您可以使用 decode_json_fields 处理器将其解码为结构化数据。以下示例将名为 "json_data" 的字段解码为结构化数据:
processors:
- decode_json_fields:
fields: ["json_data"]
target: ""
-
字段重命名(Rename Fields):
可以使用 rename 处理器重命名事件中的字段。例如,将 "old_field" 重命名为 "new_field":
processors:
- rename:
fields:
- from: old_field
to: new_field
-
条件处理(Conditional Processing):
使用 if 条件可以根据事件的特定字段或属性来选择是否应用某个处理器。以下示例根据事件中的 "log_level" 字段,仅在 "error" 日志级别时添加 "error" 标签:
processors:
- add_tags:
tags: ["error"]
when:
equals:
log_level: "error"
-
多个处理器(Multiple Processors):
您可以配置多个处理器,它们将按照顺序依次应用于事件数据。例如,您可以先添加字段,然后删除字段,最后重命名字段。
processors 部分允许您对事件数据进行复杂的处理和转换,以适应特定的需求。您可以根据需要组合不同的处理器来执行多个操作,以确保事件数据在传输到输出目标之前满足您的要求。
3、output.kafka
output.kafka 是Filebeat配置文件中的一个部分,用于配置将事件数据发送到Kafka消息队列的相关设置。以下是 output.kafka 部分的常见参数及其解释:
output.kafka:
hosts: ["kafka-broker1:9092", "kafka-broker2:9092"]
topic: "my-log-topic"
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
以下是各个参数的详细解释:
-
hosts(必需):Kafka broker 的地址和端口列表。在示例中,我们指定了两个Kafka broker:kafka-broker1:9092 和 kafka-broker2:9092。Filebeat将使用这些地址来连接到Kafka集群。 -
topic(必需):要发送事件到的Kafka主题(topic)的名称。在示例中,主题名称为 "my-log-topic"。Filebeat将会将事件发送到这个主题。 -
partition.round_robin:事件分区策略的配置。这里的配置是将事件平均分布到所有分区,不仅仅是可达的分区。reachable_only设置为 false,表示即使分区不可达也会发送数据。如果设置为true,则只会发送到可达的分区。 -
required_acks:Kafka的确认机制。指定要等待的确认数,1 表示只需要得到一个分区的确认就认为消息已经成功发送。更高的值表示更多的确认。通常,1 是常见的设置,因为它具有较低的延迟。 -
compression:数据的压缩方式。在示例中,数据被gzip压缩。这有助于减小传输数据的大小,降低网络带宽的使用。 -
max_message_bytes:Kafka消息的最大字节数。如果事件的大小超过此限制,Filebeat会将事件拆分为多个消息。
以上是常见的 output.kafka 参数,您可以根据您的Kafka集群配置和需求来调整这些参数。确保配置正确的Kafka主题和分区策略以满足您的数据传输需求。同时,要确保Filebeat服务器可以连接到指定的Kafka broker地址。
以下是一个完整的Filebeat配置文件示例,其中包括了 filebeat.prospectors、processors 和 output.kafka 的配置部分,以用于从日志文件采集数据并将其发送到Kafka消息队列:
4)filebeat.inputs 与 filebeat.prospectors区别
Filebeat 从 7.x 版本开始引入了新的配置方式 filebeat.inputs,以提供更灵活的输入配置选项,同时保留了向后兼容性。以下是 filebeat.inputs 和 filebeat.prospectors 之间的主要区别:
-
filebeat.inputs:-
filebeat.inputs 是较新版本的配置方式,用于定义输入配置。
-
允许您以更灵活的方式配置不同类型的输入。您可以在配置文件中定义多个独立的输入块,每个块用于配置不同类型的输入。
-
每个输入块可以包含多个字段,用于定制不同输入类型的配置,如 type、enabled、paths、multiline 等。
-
使配置更具可读性,因为每个输入类型都有自己的配置块。
-
示例:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/app/*.log
- type: syslog
enabled: true
port: 514
protocol.udp: true
-
filebeat.prospectors:-
filebeat.prospectors是旧版配置方式,用于定义输入配置。 -
所有的输入类型(如日志文件、系统日志、stdin 等)都需要放在同一个部分中。
-
需要在同一个配置块中定义不同输入类型的路径等细节。
-
旧版配置方式,不如
filebeat.inputs配置方式那么灵活和可读性好。
-
以下是一些常见的 type 值以及它们的含义:
-
log(常用):用于监视和收集文本日志文件,例如应用程序日志。
- type: log
paths:
- /var/log/*.log
-
stdin:用于从标准输入(stdin)收集数据。
- type: stdin
-
syslog:用于收集系统日志数据,通常是通过UDP或TCP协议从远程或本地syslog服务器接收。
- type: syslog
port: 514
protocol.udp: true
-
filestream:用于收集 Windows 上的文件日志数据。
- type: filestream
enabled: true
-
httpjson:用于通过 HTTP 请求从 JSON API 收集数据。
- type: httpjson
enabled: true
urls:
- http://example.com/api/data
-
tcp 和 udp:用于通过 TCP 或 UDP 协议收集网络数据。
- type: tcp
enabled: true
host: "localhost"
port: 12345
- type: udp
enabled: true
host: "localhost"
port: 12345
总的来说,filebeat.inputs 提供了更灵活的方式来配置不同类型的输入,更容易组织和管理配置。如果您使用的是较新版本的 Filebeat,推荐使用 filebeat.inputs 配置方式。但对于向后兼容性,旧版的 filebeat.prospectors 仍然可以使用。
5)filebeat.yml 配置
filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
multiline.pattern: '^\['
multiline.negate: false
multiline.match: after
tail_files: true
fields:
app: myapp
env: production
topicname: my-log-topic
- type: log
enabled: true
paths:
- /var/log/messages
multiline.pattern: '^\['
multiline.negate: false
multiline.match: after
tail_files: true
fields:
app: myapp
env: production
topicname: my-log-topic
processors:
- add_fields:
fields:
app: myapp
env: production
- drop_fields:
fields: ["sensitive_data"]
output.kafka:
hosts: ["local-168-182-110:9092"]
#topic: "my-log-topic"
# 这里也可以应用上面filebeat.prospectors.fields的值
topic: '%{[fields][topicname]}'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
6)启动 Filebeat 服务
nohup ./filebeat -e -c filebeat.yml >/dev/null 2>&1 &
# -e 将启动信息输出到屏幕上
# filebeat本身运行的日志默认位置${install_path}/logs/filebeat
要修改filebeat的日子路径,可以添加一下内容在filebeat.yml配置文件:
#logging.level :debug 日志级别
path.logs: /var/log/
使用 systemctl 启动 filebeat
# vi /usr/lib/systemd/system/filebeat.service
[Unit]
Description=filebeat server daemon
Documentation=/opt/filebeat-7.6.2-linux-x86_64/filebeat -help
Wants=network-online.target
After=network-online.target
[Service]
User=root
Group=root
Environment="BEAT_CONFIG_OPTS=-c /opt/filebeat-7.6.2-linux-x86_64/filebeat.yml"
ExecStart=/opt/filebeat-7.6.2-linux-x86_64/filebeat $BEAT_CONFIG_OPTS
Restart=always
[Install]
WantedBy=multi-user.target
【温馨提示】记得更换自己的
filebeat目录。
systemctl 启动 filebeat 服务
#刷新一下配置文件
systemctl daemon-reload
# 启动
systemctl start filebeat
# 查看状态
systemctl status filebeat
# 查看进程
ps -ef|grep filebeat
# 查看日志
vi logs/filebeat
7)检测日志是否已经采集到 kafka
# 设置环境变量
export KAFKA_HOME=/opt/docker-compose-kafka/images/kafka_2.12-3.4.1
# 查看topic列表
${KAFKA_HOME}/bin/kafka-topics.sh --bootstrap-server local-168-182-110:9092 --list
# 查看topic列表详情
${KAFKA_HOME}/bin/kafka-topics.sh --bootstrap-server local-168-182-110:9092 --describe
# 指定topic
${KAFKA_HOME}/bin/kafka-topics.sh --bootstrap-server local-168-182-110:9092 --describe --topic my-log-topic
# 查看kafka数据
${KAFKA_HOME}/bin/kafka-console-consumer.sh --topic my-log-topic --bootstrap-server local-168-182-110:9092
#上述命令会连接到指定的Kafka集群并打印my_topic主题上的所有消息。如果要查看特定数量的最新消息,则应将“--from-beginning”添加到命令中。
# 在较高版本的 Kafka 中(例如 Kafka 2.4.x 和更高版本),消费者默认需要明确指定要消费的分区。
#以下是查看特定最新消息数量的示例:
${KAFKA_HOME}/bin/kafka-console-consumer.sh --topic my-log-topic --bootstrap-server local-168-182-110:9092 --from-beginning --max-messages 10 --partition 0
# 查看kafka数据量,在较高版本的 Kafka 中(例如 Kafka 2.4.x 和更高版本),消费者默认需要明确指定要消费的分区。
${KAFKA_HOME}/bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list local-168-182-110:9092 --topic my-log-topic --time -1
# 消费数据查看数据,这里指定一个分区
${KAFKA_HOME}/bin/kafka-console-consumer.sh --bootstrap-server local-168-182-110:9092 --topic my-log-topic --partition 0 --offset 100
# 也可以通过消费组消费,可以不指定分区
${KAFKA_HOME}/bin/kafka-console-consumer.sh --topic my-log-topic --bootstrap-server local-168-182-110:9092 --from-beginning --group my-group
 浙公网安备 33010602011771号
浙公网安备 33010602011771号