HBase的Memstore-schema-rowkey设计原则
schema设计原则
前提条件
Configuration config = HBaseConfiguration.create();
HBaseAdmin admin = new HBaseAdmin(config);
String table = "Test";
admin.disableTable(table); // 将表下线
HColumnDescriptor f1 = ...;
admin.addColumn(table, f1); // 增加新的列簇
HColumnDescriptor f2 = ...;
admin.modifyColumn(table, f2); // 修改列簇
HColumnDescriptor f3 = ...;
admin.modifyColumn(table, f3); // 修改列簇
admin.enableTable(table);更新
当表或者列簇改变时(包括:编码方式、压力格式、block大小等等),都将会在下次major compaction时或者StoreFile重写时生效。
表模式设计经验
- 地域最大的阈值取值建议在8GB到50GB之间,不宜过小或过大。
- 单个cell不超过10MB,如果超过10MB,请使用mob,若再大可以直接存在HDFS中,在HBase内存储HDFS地址。
- 列簇数量不建议过多,一般1个即可,不建议超过3个。
- 列簇名应尽量简短,因为存储时每个value都包含列簇名(忽略前缀编码,prefix encoding)。
- 对于时序场景,建议rowkey设计为设备ID加上时间,如果采用“时间+设备ID”的方案会导致如下:
- 同一时间点的数据落入同一个地域,导致热点。
- 较早数据随着时间推移、数据过期会留下大量的空地域,带来不必要的开销。
列簇数量
- 现在HBase并不能很好的处理两个或者三个以上的列簇,所以尽量让列簇数量少一些。
- 目前, flush和compaction操作是针对一个地域。所以当一个列簇操作大量数据的时候会引发一个flush。邻近的列簇也有进行flush操作,尽管它们没有操作多少数据。
- compaction操作现在是根据一个列簇下的全部文件的数量触发的,而不是根据文件大小触发的。
- 当很多的列簇在flush和compaction时,会造成很多没用的I/O负载。
说明 减少没用的I/O负载需要将flush和compaction操作只针对一个列簇。
- 尽量在模式中只针对一个列簇操作。将使用率相近的列归为一列簇,这样每次访问时就只用访问一个列簇,提高效率。
列簇基数
如果一个表存在多个列簇,要注意列簇之间基数(如行数)相差不要太大。例如:列簇A有100万行,列簇B有10亿行,按照行键切分后,列簇A可能被分散到很多地域(及RegionServer),这导致扫描列簇A十分低效。
版本数量
行的版本的数量是HColumnDescriptor设置的,每个列簇可以单独设置,默认是3。这个设置是很重要的,因为HBase不会覆盖一个值,只会在值的后面进行追加描述,用时间戳来区分。过早的版本会在执行major compaction时删除,这些在HBase数据模型有描述。这个版本的值可以根据具体的应用增加或减少。不推荐将版本最大值设到一个很高的水平(100或更多),除非历史数据很重要,因为这会导致存储文件变得极大。
最小版本数
和行的最大版本数一样,最小版本数也是通过HColumnDescriptor在每个列簇中设置的。最小版本数缺省值是0,表示该特性禁用。 最小版本数参数和存活时间一起使用,允许配置如“保存最后T秒有价值数据,最多N个版本,但最少约M个版本”(M是最小版本数,M<N)。该参数仅在存活时间对列簇启用,且必须小于行版本数。
支持数据类型
HBase通过Put和Result支持bytes-in/bytes-out接口,所以任何可被转为字节数组的东西可以作为值存入。输入可以是字符串、数字、复杂对象、甚至图像,它们能转为字节。
存在值的实际长度限制,例如:保存10-50MB对象到HBase对查询来说太长,搜索邮件列表获取本话题的对话。HBase的所有行都遵循HBase数据模型包括版本化。设计时需考虑到以上限制以及列簇的块大小。
存活时间
列簇可以设置TTL秒数,HBase在超时后将自动删除数据,HBase里面TTL时间时区是UTC。
存储文件仅包含有过期的行(expired rows),它们可通过minor compaction删除。将hbase.store.delete.expired.storefile设置为false,可禁用此功能;将最小版本数设置成非0值也可达到同样的效果。
- Cell TTLs的数量级是毫秒而不是秒。
- 一个Cell TTL不能超出ColumnFamily TTLs设置的有效时间。
Rowkey设计
HBase的RowKey设计可以说是使用HBase最为重要的事情,直接影响到HBase的性能,常见的RowKey的设计问题及对应访问。
RowKey的行由行键按字典顺序排序,这样的设计优化了扫描,允许存储相关的行或者那些将被一起读的邻近的行。然而,设计不好的行键是导致 hotspotting 的常见原因。当大量的客户端流量( traffic )被定向在集群上的一个或几个节点时,就会发生 hotspotting。这些流量可能代表着读、写或其他操作。流量超过了承载该地域的单个机器所能负荷的量,这就会导致性能下降并有可能造成地域的不可用。在同一 RegionServer 上的其他地域也可能会受到其不良影响,因为主机无法提供服务所请求的负载。设计使集群能被充分均匀地使用的数据访问模式是至关重要的。
为了防止在写操作时出现hotspotting,设计行键时应该使得数据尽量同时往多个地域上写,而避免只向一个地域写,除非那些行真的有必要写在一个地域里。
下面介绍了集中常用的避免hotspotting的技巧,它们各有优劣。
Salting
Salting 从某种程度上看与加密无关,它指的是将随机数放在行键的起始处。进一步说,salting给每一行键随机指定了一个前缀来让它与其他行键有着不同的排序。所有可能前缀的数量对应于要分散数据的地域的数量。如果有几个“hot”的行键模式,而这些模式在其他更均匀分布的行里反复出现,salting就能到帮助。下面的例子说明了salting能在多个RegionServer间分散负载,同时也说明了它在读操作时候的负面影响。
假设行键的列表如下,表按照每个字母对应一个地域来分割。前缀‘a’是一个地域,‘b’就是另一个地域。在这张表中,所有以‘f’开头的行都属于同一个地域。这个例子关注的行和键如下:
foo0001
foo0002
foo0003
foo0004现在,假设想将它们分散到不同的地域上,就需要用到四种不同的salts :a,b,c,d。在这种情况下,每种字母前缀都对应着不同的一个地域。用上这些salts后,便有了下面这样的行键。由于现在想把它们分到四个独立的区域,理论上吞吐量会是之前写到同一地域的情况的吞吐量的四倍。
a-foo0003
b-foo0001
c-foo0004
d-foo0002如果想新增一行,新增的一行会被随机指定四个可能的salt值中的一个,并放在某条已存在的行的旁边。
a-foo0003
b-foo0001
c-foo0003
c-foo0004
d-foo0002由于前缀的指派是随机的,因而如果想要按照字典顺序找到这些行,则需要做更多的工作。从这个角度上看,salting增加了写操作的吞吐量,却也增大了读操作的开销。
Hashing
可用一个单向的 hash 散列来取代随机指派前缀。这样能使一个给定的行在“salted”时有相同的前缀,从某种程度上说,这在分散了RegionServer间的负载的同时,也允许在读操作时能够预测。确定性hash( deterministic hash )能让客户端重建完整的行键,以及像正常的一样用Get操作重新获得想要的行。
考虑和上述salting一样的情景,现在可以用单向hash来得到行键foo0003,并可预测得‘a’这个前缀。然后为了重新获得这一行,需要先知道它的键。可以进一步优化这一方法,如使得将特定的键对总是在相同的地域。
Reversing the Key(反转键)
第三种预防hotspotting的方法是反转一段固定长度或者可数的键,来让最常改变的部分(最低显著位, the least significant digit )在第一位,这样有效地打乱了行键,但是却牺牲了行排序的属性。
单调递增行键/时序数据
在一个集群中,一个导入数据的进程锁住不动,所有的client都在等待一个地域(因而也就是一个单个节点),过了一会后,变成了下一个地域。 如果使用了单调递增或者时序的key便会造成这样的问题。使用了顺序的key会将本没有顺序的数据变得有顺序,把负载压在一台机器上。所以要尽量避免时间戳或者序列(比如1, 2, 3)这样的行键。
如果需要导入时间顺序的文件(如log)到HBase中,可以学习OpenTSDB的做法。它有一个页面来描述它的HBase模式。OpenTSDB的Key的格式是[metric_type][event_timestamp],乍一看,这似乎违背了不能将timestamp做key的建议,但是它并没有将timestamp作为key的一个关键位置,有成百上千的metric_type就足够将压力分散到各个地域了。因此,尽管有着连续的数据输入流,Put操作依旧能被分散在表中的各个地域中。
简化行和列
在HBase中,值是作为一个单元保存在系统的中的,要定位一个单元,需要行,列名和时间戳。通常情况下,如果行和列的名字要是太大(甚至比value的大小还要大)的话,可能会遇到一些有趣的情况。在HBase的存储文件(storefiles)中,有一个索引用来方便值的随机访问,但是访问一个单元的坐标要是太大的话,会占用很大的内存,这个索引会被用尽。要想解决这个问题,可以设置一个更大的块大小,也可以使用更小的行和列名 。压缩也能得到更大指数。
大部分时候,细微的低效不会影响很大。但不幸的是,在这里却不能忽略。无论是列族、属性和行键都会在数据中重复上亿次。
列族
尽量使列族名小,最好一个字符。(如:f 表示)
属性
详细属性名(比如myVeryImportantAttribute)易读,最好还是用短属性名(比如via)保存到HBase。
行键长度
让行键短到可读即可,这样对获取数据有帮助(比如Get vs. Scan)。短键对访问数据无用,并不比长键对get或scan更好。设计行键需要权衡。
字节模式
long类型有8字节,8字节内可以保存无符号数字到18446744073709551615。 如果用字符串保存,假设一个字节一个字符,需要将近3倍的字节数。
示例代码如下所示。
// long
//
long l = 1234567890L;
byte[] lb = Bytes.toBytes(l);
System.out.println("long bytes length: " + lb.length); // returns 8
String s = String.valueOf(l);
byte[] sb = Bytes.toBytes(s);
System.out.println("long as string length: " + sb.length); // returns 10
// hash
//
MessageDigest md = MessageDigest.getInstance("MD5");
byte[] digest = md.digest(Bytes.toBytes(s));
System.out.println("md5 digest bytes length: " + digest.length); // returns 16
String sDigest = new String(digest);
byte[] sbDigest = Bytes.toBytes(sDigest);
System.out.println("md5 digest as string length: " + sbDigest.length); // returns 26不幸的是,用二进制表示会使数据在代码之外难以阅读。下例便是当需要增加一个值时会看到的Shell。
hbase(main):001:0> incr 't', 'r', 'f:q', 1
COUNTER VALUE = 1
hbase(main):002:0> get 't', 'r'
COLUMN CELL
f:q timestamp=1369163040570, value=\x00\x00\x00\x00\x00\x00\x00\x01
1 row(s) in 0.0310 seconds这个Shell尽力在打印一个字符串,但在这种情况下,它决定只将进制打印出来。当在地域名内行键会发生相同的情况。如果知道储存的是什么,那自是没问题,但当任意数据都可能被放到相同单元的时候,这将会变得难以阅读。这是最需要权衡之处。
倒序时间戳
一个数据库处理的通常问题是找到最近版本的值。采用倒序时间戳作为键的一部分可以对此特定情况有很大帮助。该技术包含追加(Long.MAX_VALUE - timestamp)到key的后面,如[key][reverse_timestamp] 。
表内[key]的最近的值可以用[key]进行Scan,找到并获取第一个记录。由于HBase行键是排序的,该键排在任何比它老的行键的前面,所以是第一个。
该技术可以用于代替版本数,其目的是保存所有版本到“永远”(或一段很长时间) 。同时,采用同样的Scan技术,可以很快获取其他版本。
行键和列族
行键在列族范围内。所以同样的行键可以在同一个表的每个列族中存在而不会冲突。
行键不可改
行键不能改变。唯一可以“改变”的方式是删除然后再插入。这是一个常问问题,所以要注意开始就要让行键正确(且/或在插入很多数据之前)。
行键和地域split的关系
如果已经 pre-split(预裂)了表,接下来关键要了解行键是如何在地域边界分布的。为了说明为什么这很重要,可考虑用可显示的16位字符作为键的关键位置(比如“0000000000000000” to “ffffffffffffffff”)这个例子。通过Bytes.split来分割键的范围(这是当用 Admin.createTable(byte[] startKey, byte[] endKey, numRegions)创建地域时的一种拆分手段),这样会分得10个地域。
48 48 48 48 48 48 48 48 48 48 48 48 48 48 48 48 // 0
54 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 // 6
61 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -68 // =
68 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -126 // D
75 75 75 75 75 75 75 75 75 75 75 75 75 75 75 72 // K
82 18 18 18 18 18 18 18 18 18 18 18 18 18 18 14 // R
88 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -44 // X
95 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -102 // _
102 102 102 102 102 102 102 102 102 102 102 102 102 102 102 102 // f但问题在于,数据将会堆放在前两个地域以及最后一个地域,这样就会导致某几个地域由于数据分布不均匀而特别忙。为了理解其中缘由,需要考虑ASCII Table的结构。根据ASCII表,“0”是第48号,“f”是102号;但58到96号是个巨大的间隙,考虑到在这里仅[0-9]和[a-f]这些值是有意义的,因而这个区间里的值不会出现在键空间( keyspace ),进而中间区域的地域将永远不会用到。为了pre-split这个例子中的键空间,需要自定义拆分。
教程1:预裂表( pre-splitting tables ) 是个很好的实践,但pre-split时要注意使得所有的地域都能在键空间中找到对应。尽管例子中解决的问题是关于16位键的键空间,但其他任何空间也是同样的道理。
教程2:16位键(通常用到可显示的数据中)尽管通常不可取,但只要所有的地域都能在键空间找到对应,它依旧能和预裂表配合使用。
以下代码说明如何16位键预分区。
public static boolean createTable(Admin admin, HTableDescriptor table, byte[][] splits)
throws IOException {
try {
admin.createTable( table, splits );
return true;
} catch (TableExistsException e) {
logger.info("table " + table.getNameAsString() + " already exists");
// the table already exists...
return false;
}
}
public static byte[][] getHexSplits(String startKey, String endKey, int numRegions) {
byte[][] splits = new byte[numRegions-1][];
BigInteger lowestKey = new BigInteger(startKey, 16);
BigInteger highestKey = new BigInteger(endKey, 16);
BigInteger range = highestKey.subtract(lowestKey);
BigInteger regionIncrement = range.divide(BigInteger.valueOf(numRegions));
lowestKey = lowestKey.add(regionIncrement);
for(int i=0; i < numRegions-1;i++) {
BigInteger key = lowestKey.add(regionIncrement.multiply(BigInteger.valueOf(i)));
byte[] b = String.format("%016x", key).getBytes();
splits[i] = b;
}
return splits;
}HBase ROWKEY
访问hbase table中的行,只有三种方式:
1 通过单个row key访问
2 通过row key的range
3 全表扫描
Hadoop Sequence File
文中可能涉及到的API:
Hadoop/HDFS:http://hadoop.apache.org/common/docs/current/api/
HBase: http://hbase.apache.org/apidocs/index.html?overview-summary.html
Begin!
HBase的查询实现只提供两种方式:
1、按指定RowKey获取唯一一条记录,get方法(org.apache.hadoop.hbase.client.Get)
2、按指定的条件获取一批记录,scan方法(org.apache.hadoop.hbase.client.Scan)
实现条件查询功能使用的就是scan方式,scan在使用时有以下几点值得注意:
1、scan可以通过setCaching与setBatch方法提高速度(以空间换时间);
2、scan可以通过setStartRow与setEndRow来限定范围。范围越小,性能越高。
通过巧妙的RowKey设计使我们批量获取记录集合中的元素挨在一起(应该在同一个Region下),可以在遍历结果时获得很好的性能。
3、scan可以通过setFilter方法添加过滤器,这也是分页、多条件查询的基础。
下面举个形象的例子:
我们在表中存储的是文件信息,每个文件有5个属性:文件id(long,全局唯一)、创建时间(long)、文件名(String)、分类名(String)、所有者(User)。
我们可以输入的查询条件:文件创建时间区间(比如从20120901到20120914期间创建的文件),文件名(“中国好声音”),分类(“综艺”),所有者(“浙江卫视”)。
假设当前我们一共有如下文件:
内容列表 ID CreateTime Name Category UserID 1 2 3 4 5 6 7 8 9 10| 20120902 | 中国好声音第1期 | 综艺 | 1 |
| 20120904 | 中国好声音第2期 | 综艺 | 1 |
| 20120906 | 中国好声音外卡赛 | 综艺 | 1 |
| 20120908 | 中国好声音第3期 | 综艺 | 1 |
| 20120910 | 中国好声音第4期 | 综艺 | 1 |
| 20120912 | 中国好声音选手采访 | 综艺花絮 | 2 |
| 20120914 | 中国好声音第5期 | 综艺 | 1 |
| 20120916 | 中国好声音录制花絮 | 综艺花絮 | 2 |
| 20120918 | 张玮独家专访 | 花絮 | 3 |
| 20120920 | 加多宝凉茶广告 | 综艺广告 | 4 |
这里UserID应该对应另一张User表,暂不列出。我们只需知道UserID的含义:
1代表 浙江卫视; 2代表 好声音剧组; 3代表 XX微博; 4代表 赞助商。
调用查询接口的时候将上述5个条件同时输入find(20120901,20121001,"中国好声音","综艺","浙江卫视")。
此时我们应该得到记录应该有第1、2、3、4、5、7条。第6条由于不属于“浙江卫视”应该不被选中。
我们在设计RowKey时可以这样做:采用UserID + CreateTime + FileID组成rowKey,这样既能满足多条件查询,又能有很快的查询速度。
需要注意以下几点:
1、每条记录的RowKey,每个字段都需要填充到相同长度。假如预期我们最多有10万量级的用户,则userID应该统一填充至6位,如000001,000002...
2、结尾添加全局唯一的FileID的用意也是使每个文件对应的记录全局唯一。避免当UserID与CreateTime相同时的两个不同文件记录相互覆盖。
按照这种RowKey存储上述文件记录,在HBase表中是下面的结构:
rowKey(userID 6 + time 8 + fileID 6) name category ....
00000120120902000001
00000120120904000002
00000120120906000003
00000120120908000004
00000120120910000005
00000120120914000007
00000220120912000006
00000220120916000008
00000320120918000009
00000420120920000010
怎样用这张表?
在建立一个scan对象后,我们setStartRow(00000120120901),setEndRow(00000120120914)。
这样,scan时只扫描userID=1的数据,且时间范围限定在这个指定的时间段内,满足了按用户以及按时间范围对结果的筛选。并且由于记录集中存储,性能很好。
然后使用SingleColumnValueFilter(org.apache.hadoop.hbase.filter.SingleColumnValueFilter),共4个,分别约束name的上下限,与category的上下限。满足按同时按文件名以及分类名的前缀匹配。
(注意:使用SingleColumnValueFilter会影响查询性能,在真正处理海量数据时会消耗很大的资源,且需要较长的时间。
在后续的博文中我将多举几种应用场景下rowKey的,可以满足简单条件下海量数据瞬时返回的查询功能)
如果需要分页还可以再加一个PageFilter限制返回记录的个数。
以上,我们完成了高性能的支持多条件查询的HBase表结构设计。
MemStore是HBase非常重要的组成部分,深入理解MemStore的运行机制、工作原理、相关配置,对HBase集群管理以及性能调优有非常重要的帮助。
HBase Memstore
首先通过简单介绍HBase的读写过程来理解一下MemStore到底是什么,在何处发挥作用,如何使用到以及为什么要用MemStore。
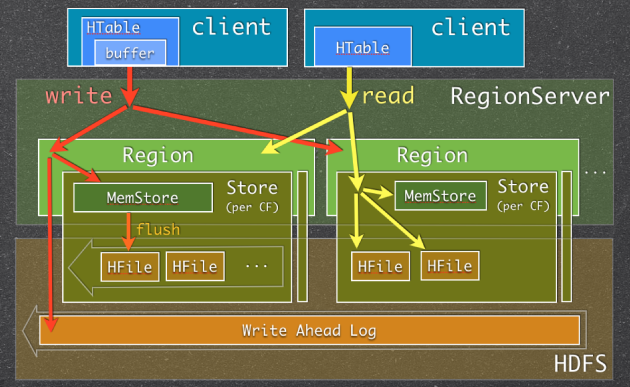
图一:Memstore Usage in HBase Read/Write Paths
当RegionServer(RS)收到写请求的时候(write request),RS会将请求转至相应的Region。每一个Region都存储着一些列(a set of rows)。根据其列族的不同,将这些列数据存储在相应的列族中(Column Family,简写CF)。不同的CFs中的数据存储在各自的HStore中,HStore由一个Memstore及一系列HFile组成。Memstore位于RS的主内存中,而HFiles被写入到HDFS中。当RS处理写请求的时候,数据首先写入到Memstore,然后当到达一定的阀值的时候,Memstore中的数据会被刷到HFile中。
用到Memstore最主要的原因是:存储在HDFS上的数据需要按照row key 排序。而HDFS本身被设计为顺序读写(sequential reads/writes),不允许修改。这样的话,HBase就不能够高效的写数据,因为要写入到HBase的数据不会被排序,这也就意味着没有为将来的检索优化。为了解决这个问题,HBase将最近接收到的数据缓存在内存中(in Memstore),在持久化到HDFS之前完成排序,然后再快速的顺序写入HDFS。需要注意的一点是实际的HFile中,不仅仅只是简单地排序的列数据的列表,详见Apache HBase I/O – HFile。
除了解决“无序”问题外,Memstore还有一些其他的好处,例如:
- 作为一个内存级缓存,缓存最近增加数据。一种显而易见的场合是,新插入数据总是比老数据频繁使用。
- 在持久化写入之前,在内存中对Rows/Cells可以做某些优化。比如,当数据的version被设为1的时候,对于某些CF的一些数据,Memstore缓存了数个对该Cell的更新,在写入HFile的时候,仅需要保存一个最新的版本就好了,其他的都可以直接抛弃。
有一点需要特别注意:每一次Memstore的flush,会为每一个CF创建一个新的HFile。 在读方面相对来说就会简单一些:HBase首先检查请求的数据是否在Memstore,不在的话就到HFile中查找,最终返回merged的一个结果给用户。
HBase Memstore关注要点
迫于以下几个原因,HBase用户或者管理员需要关注Memstore并且要熟悉它是如何被使用的:
- Memstore有许多配置可以调整以取得好的性能和避免一些问题。HBase不会根据用户自己的使用模式来调整这些配置,你需要自己来调整。
- 频繁的Memstore flush会严重影响HBase集群读性能,并有可能带来一些额外的负载。
- Memstore flush的方式有可能影响你的HBase schema设计
接下来详细讨论一下这些要点:
Configuring Memstore Flushes
对Memstore Flush来说,主要有两组配置项:
- 决定Flush触发时机
- 决定Flush何时触发并且在Flush时候更新被阻断(block)
第一组是关于触发“普通”flush,这类flush发生时,并不影响并行的写请求。该类型flush的配置项有:
- hbase.hregion.memstore.flush.size
|
1
2
3
4
5
6
7
8
9
|
<property> <name>hbase.hregion.memstore.flush.size</name> <value>134217728</value> <description> Memstore will be flushed to disk if size of the memstore exceeds this number of bytes. Value is checked by a thread that runs every hbase.server.thread.wakefrequency. </description></property> |
- base.regionserver.global.memstore.lowerLimit
|
1
2
3
4
5
6
7
8
9
10
|
<property> <name>hbase.regionserver.global.memstore.lowerLimit</name> <value>0.35</value> <description>Maximum size of all memstores in a region server before flushes are forced. Defaults to 35% of heap. This value equal to hbase.regionserver.global.memstore.upperLimit causes the minimum possible flushing to occur when updates are blocked due to memstore limiting. </description></property> |
需要注意的是第一个设置是每个Memstore的大小,当你设置该配置项时,你需要考虑一下每台RS承载的region总量。可能一开始你设置的该值比较小,后来随着region增多,那么就有可能因为第二个设置原因Memstore的flush触发会变早许多。
第二组设置主要是出于安全考虑:有时候集群的“写负载”非常高,写入量一直超过flush的量,这时,我们就希望memstore不要超过一定的安全设置。在这种情况下,写操作就要被阻止(blocked)一直到memstore恢复到一个“可管理”(manageable)的大小。该类型flush配置项有:
- hbase.regionserver.global.memstore.upperLimit
|
1
2
3
4
5
6
7
8
9
|
<property> <name>hbase.regionserver.global.memstore.upperLimit</name> <value>0.4</value> <description>Maximum size of all memstores in a region server before new updates are blocked and flushes are forced. Defaults to 40% of heap. Updates are blocked and flushes are forced until size of all memstores in a region server hits hbase.regionserver.global.memstore.lowerLimit. </description></property> |
- hbase.hregion.memstore.block.multiplier
|
1
2
3
4
5
6
7
8
9
10
11
12
|
<property> <name>hbase.hregion.memstore.block.multiplier</name> <value>2</value> <description> Block updates if memstore has hbase.hregion.block.memstore time hbase.hregion.flush.size bytes. Useful preventing runaway memstore during spikes in update traffic. Without an upper-bound, memstore fills such that when it flushes the resultant flush files take a long time to compact or split, or worse, we OOME. </description></property> |
某个节点“写阻塞”对该节点来说影响很大,但是对于整个集群的影响更大。HBase设计为:每个Region仅属于一个RS但是“写负载”是均匀分布于整个集群(所有Region上)。有一个如此“慢”的节点,将会使得整个集群都会变慢(最明显的是反映在速度上)。
提示:严重关切Memstore的大小和Memstore Flush Queue的大小。理想情况下,Memstore的大小不应该达到hbase.regionserver.global.memstore.upperLimit的设置,Memstore Flush Queue 的size不能持续增长。
频繁的Memstore Flushes
要避免“写阻塞”,貌似让Flush操作尽量的早于达到触发“写操作”的阈值为宜。但是,这将导致频繁的Flush操作,而由此带来的后果便是读性能下降以及额外的负载。
每次的Memstore Flush都会为每个CF创建一个HFile。频繁的Flush就会创建大量的HFile。这样HBase在检索的时候,就不得不读取大量的HFile,读性能会受很大影响。
为预防打开过多HFile及避免读性能恶化,HBase有专门的HFile合并处理(HFile Compaction Process)。HBase会周期性的合并数个小HFile为一个大的HFile。明显的,有Memstore Flush产生的HFile越多,集群系统就要做更多的合并操作(额外负载)。更糟糕的是:Compaction处理是跟集群上的其他请求并行进行的。当HBase不能够跟上Compaction的时候(同样有阈值设置项),会在RS上出现“写阻塞”。像上面说到的,这是最最不希望的。
提示:严重关切RS上Compaction Queue 的size。要在其引起问题前,阻止其持续增大。
想了解更多HFile 创建和合并,可参看 Visualizing HBase Flushes And Compactions。
理想情况下,在不超过hbase.regionserver.global.memstore.upperLimit的情况下,Memstore应该尽可能多的使用内存(配置给Memstore部分的,而不是真个Heap的)。下图展示了一张“较好”的情况:
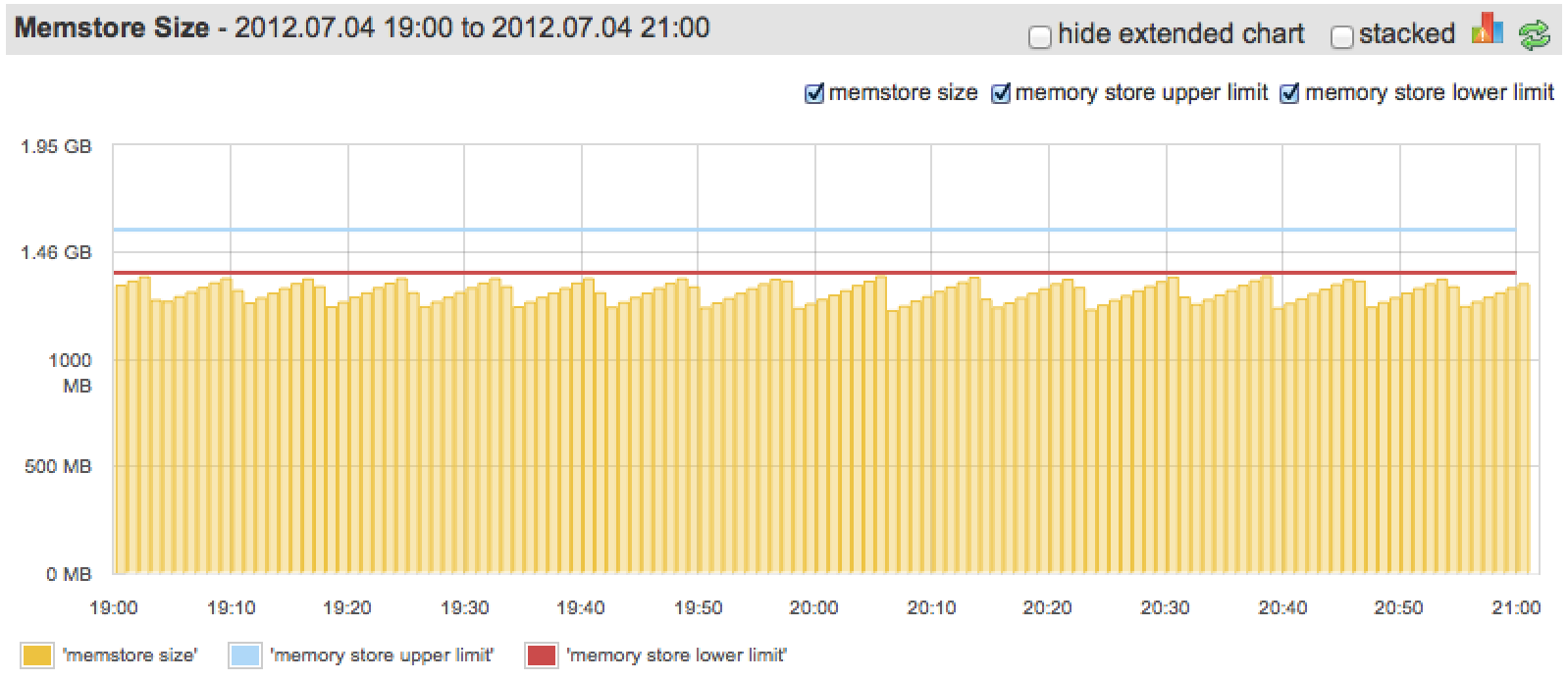
“Somewhat”, because we could configure lower limit to be closer to upper, since we barely ever go over it.
说是“较好”,是因为我们可以将“Lower limit”配置的更接近于“Upper limit”,我们几乎很少有超过它。
Multiple Column Families & Memstore Flush
每次Memstore Flush,会为每个CF都创建一个新的HFile。这样,不同CF中数据量的不均衡将会导致产生过多HFile:当其中一个CF的Memstore达到阈值flush时,所有其他CF的也会被flush。如上所述,太频繁的flush以及过多的HFile将会影响集群性能。
提示:很多情况下,一个CF是最好的设计。
HLog (WAL) Size & Memstore Flush
第一张HBase Read/Write path图中,你可能已经注意到当数据被写入时会默认先写入Write-ahead Log(WAL)。WAL中包含了所有已经写入Memstore但还未Flush到HFile的更改(edits)。在Memstore中数据还没有持久化,当RegionSever宕掉的时候,可以使用WAL恢复数据。
当WAL(在HBase中成为HLog)变得很大的时候,在恢复的时候就需要很长的时间。因此,对WAL的大小也有一些限制,当达到这些限制的时候,就会触发Memstore的flush。Memstore flush会使WAL 减少,因为数据持久化之后(写入到HFile),就没有必要在WAL中再保存这些修改。有两个属性可以配置:
- hbase.regionserver.hlog.blocksize
- hbase.regionserver.maxlogs
你可能已经发现,WAL的最大值由hbase.regionserver.maxlogs * hbase.regionserver.hlog.blocksize (2GB by default)决定。一旦达到这个值,Memstore flush就会被触发。所以,当你增加Memstore的大小以及调整其他的Memstore的设置项时,你也需要去调整HLog的配置项。否则,WAL的大小限制可能会首先被触发,因而,你将利用不到其他专门为Memstore而设计的优化。抛开这些不说,通过WAL限制来触发Memstore的flush并非最佳方式,这样做可能会会一次flush很多Region,尽管“写数据”是很好的分布于整个集群,进而很有可能会引发flush“大风暴”。
提示:最好将hbase.regionserver.hlog.blocksize * hbase.regionserver.maxlogs 设置为稍微大于hbase.regionserver.global.memstore.lowerLimit * HBASE_HEAPSIZE.
Compression & Memstore Flush
HBase建议压缩存储在HDFS上的数据(比如HFiles)。除了节省硬盘空间,同样也会显著地减少硬盘和网络IO。使用压缩,当Memstore flush并将数据写入HDFS时候,数据会被压缩。压缩不会减慢多少flush的处理过程,却会大大减少以上所述问题,例如因为Memstore变大(超过 upper limit)而引起的“写阻塞”等等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号